HQL-DDL����
�ο�:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
DDL(data definition language): ��Ҫ��������CREATE��ALTER��DROP�ȡ�
DDL��Ҫ�����ڶ��塢�����ݿ����Ľṹ �� �������͡�
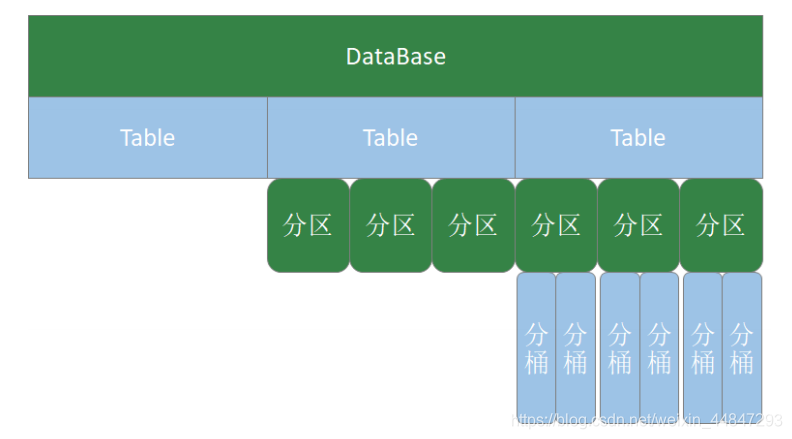
�� 1 �� ���ݿ����
Hive��һ��Ĭ�ϵ����ݿ�default,�ڲ���HQLʱ,�������ȷ��ָ��Ҫʹ���ĸ���,��ʹ��Ĭ�����ݿ�;
Hive�����ݿ����������������ִ�Сд;
���ֲ���ʹ�����ֿ�ͷ;
����ʹ�ùؼ���,������ʹ���������;
�������ݿ��
CREATE [REMOTE] (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
-- IF NOT EXISTS ��������ڴ���
-- COMMENT ������ע��
-- LOCATION ָ���洢·��
-- MANAGEDLOCATION �����
-- �������ݿ�,��HDFS�ϴ洢·��Ϊ /user/hive/warehouse/*.db
hive (default)> create database mydb;
hive (default)> dfs -ls /user/hive/warehouse;
-- �������ݿ��Ѿ�����ʱ����,ʹ�� if not exists �����жϡ���д����
hive (default)> create database if not exists mydb;
-- �������ݿ⡣���ӱ�ע,ָ�����ݿ��ڴ��λ��
hive (default)> create database if not exists mydb2
comment 'this is mydb2'
location '/user/hive/mydb2.db';
�鿴���ݿ�
-- �鿴�������ݿ�
show database;
-- �鿴���ݿ���Ϣ
desc database mydb2;
-- ��һ����ϸ��Ϣչʾ
desc database extended mydb2;
describe database extended mydb2;
ʹ�����ݿ�
USE database_name;
USE DEFAULT;
-- �鿴��ǰʹ�õ����ݿ�
SELECT current_database();
ɾ�����ݿ�
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
-- ɾ��һ�������ݿ�
drop database databasename;
-- ������ݿⲻΪ��,ʹ�� cascade ǿ��ɾ��
drop database databasename cascade;
�����ݿ�
-- �����ݿ����
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0)
--
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later)
ALTER (DATABASE|SCHEMA) database_name SET MANAGEDLOCATION hdfs_path; -- (Note: Hive 4.0.0 and later)
�� 2 �� �����
create [external] table [IF NOT EXISTS] table_name
[(colName colType [comment 'comment'], ...)]
[comment table_comment]
[partitioned by (colName colType [comment col_comment], ...)]
[clustered BY (colName, colName, ...)
[sorted by (col_name [ASC|DESC], ...)] into num_buckets buckets]
[row format row_format]
[stored as file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement];
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
-
CREATE TABLE:���������ƴ�����,������Ѿ��������׳��쳣����ʹ��if not exists��ܡ� -
EXTERNAL:�йؼ����Ǵ����ⲿ��,���������ڲ���(������)��ɾ���ڲ���ʱ,���ݺͱ��Ķ���ͬʱ��ɾ��;
ɾ���ⲿ��ʱ,����ɾ���˱��Ķ���,���ݱ���;
������������,��ʹ���ⲿ��;
-
comment:����ע�� -
partitioned by:�Ա������ݽ��з���,ָ�����ķ����ֶ� -
clustered by:������Ͱ��,ָ����Ͱ�ֶ� -
sorted by:��Ͱ�е�һ������������,����ʹ�� -
�洢�Ӿ�:
ROW FORMAT DELIMITED
[FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char] | SERDE serde_name
[WITH SERDEPROPERTIES (property_name=property_value,
property_name=property_value, ...)]
? ����ʱ��ָ�� SerDe �����û��ָ�� ROW FORMAT ���� ROW FORMAT DELIMITED,����ʹ�� Ĭ�ϵ� SerDe������ʱ����ҪΪ��ָ����,��ָ���е�ͬʱҲ��ָ���Զ���� SerDe��Hiveͨ�� SerDe ȷ�����ľ�����е����ݡ�
? SerDe�� Serialize/Deserilize �ļ��, hiveʹ��Serde�����ж���������뷴���л���
-
stored as SEQUENCEFILE|TEXTFILE|RCFILE:����ļ������Ǵ��ı�,����ʹ��STORED AS TEXTFILE(ȱʡ);���������Ҫѹ��,ʹ��STORED AS SEQUENCEFILE(�����������ļ�)�� -
LOCATION:����HDFS�ϵĴ��λ�� -
TBLPROPERTIES:����������� -
AS:������ԽӲ�ѯ���,��ʾ���ݺ���IJ�ѯ��������� -
LIKE:like ����,�����û��������еı��ṹ,���Dz���������
�����ĵ�
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
�� 3 �� �ڲ��� & �ⲿ��
�ڴ�������ʱ��,��ָ���������͡�������������,�ֱ����ڲ���(������)���ⲿ����
-
Ĭ�������,�����ڲ��������Ҫ�����ⲿ��,��Ҫʹ�ùؼ���
external -
��ɾ���ڲ���ʱ,���Ķ���(Ԫ����) �� ���� ͬʱ��ɾ��
-
��ɾ���ⲿ��ʱ,��ɾ�����Ķ���,���ݱ�����
-
������������,��ʹ���ⲿ��
�ڲ���
- t1.dat�ļ�����
2;zhangsan;book,TV,code;beijing:chaoyang,shagnhai:pudong
3;lishi;book,code;nanjing:jiangning,taiwan:taibei
4;wangwu;music,book;heilongjiang:haerbin
- ������ SQL
-- �����ڲ���
create table t1(
id int,
name string,
hobby array<string>,
addr map<string, string>
)
row format delimited
fields terminated by ";"
collection items terminated by ","
map keys terminated by ":";
-- ��ʾ���Ķ���,��ʾ����Ϣ����
desc t1;
-- ��ʾ���Ķ���,��ʾ����Ϣ��,��ʽ�Ѻ�
desc formatted t1;
-- ��������
load data local inpath '/home/hadoop/data/t1.dat' into table t1;
-- ��ѯ����
select * from t1;
-- ��ѯ�����ļ�
dfs -ls /user/hive/warehouse/mydb.db/t1;
-- ɾ��������������ͬʱ��ɾ��
drop table t1;
-- �ٴβ�ѯ�����ļ�,�Ѿ���ɾ��
�ⲿ��
-- �����ⲿ��
create external table t2(
id int,
name string,
hobby array<string>,
addr map<string, string>
)
row format delimited
fields terminated by ";"
collection items terminated by ","
map keys terminated by ":";
-- ��ʾ���Ķ���
desc formatted t2;
-- ��������
load data local inpath '/home/hadoop/data/t1.dat' into table t2;
-- ��ѯ����
select * from t2;
-- ɾ��������ɾ����,Ŀ¼��Ȼ����
drop table t2;
-- �ٴβ�ѯ�����ļ�,��Ȼ����
�ڲ������ⲿ����ת��
-- �����ڲ���,��������,����������ļ��ͱ��Ķ���
create table t1(
id int,
name string,
hobby array<string>,
addr map<string, string>
)
row format delimited
fields terminated by ";"
collection items terminated by ","
map keys terminated by ":";
load data local inpath '/home/hadoop/data/t1.dat' into table t1;
dfs -ls /user/hive/warehouse/mydb.db/t1;
desc formatted t1;
-- �ڲ���ת�ⲿ��
alter table t1 set tblproperties('EXTERNAL'='TRUE');
-- ��ѯ����Ϣ,�Ƿ�ת���ɹ�
desc formatted t1;
-- �ⲿ��ת�ڲ�����EXTERNAL ��д,false �����ִ�С
alter table t1 set tblproperties('EXTERNAL'='FALSE');
-- ��ѯ����Ϣ,�Ƿ�ת���ɹ�
desc formatted t1;
��
-
����ʱ:
- �����ָ��
external�ؼ���,���������ڲ���; - ָ��
external�ؼ���,���������ⲿ��;
- �����ָ��
-
ɾ��ʱ
- ɾ���ⲿ��ʱ,��ɾ�����Ķ���,�������ݲ���Ӱ��
- ɾ���ڲ���ʱ,�������ݺͶ���ͬʱ��ɾ��
-
�ⲿ����ʹ�ó���
- �뱣������ʱʹ�á����������ⲿ��
�� 4 �� ������
Hive��ִ�в�ѯʱ,һ���ɨ�������������ݡ����ڱ�����������,ȫ��ɨ������ʱ�䳤��Ч�ʵ͡�
����ʱ��,��ѯֻ��Ҫɨ����е�һ�������ݼ���,Hive�����˷������ĸ���,���������ݴ洢�ڲ�ͬ����Ŀ¼��,ÿһ����Ŀ¼��Ӧһ��������ֻ��ѯ���ַ�������ʱ,�ɱ���ȫ��ɨ��,��߲�ѯЧ�ʡ�
��ʵ����,ͨ������ʱ�䡢��������Ϣ���з�����
���������������ݼ���
-- ������
create table if not exists t3(
id int,
name string,
hobby array<string>,
addr map<String,string>
)
partitioned by (dt string)
row format delimited
fields terminated by ';'
collection items terminated by ','
map keys terminated by ':';
-- �������ݡ�
load data local inpath "/home/hadoop/data/t1.dat" into table t3 partition(dt="2020-06-01");
load data local inpath "/home/hadoop/data/t1.dat" into table t3partition(dt="2020-06-02");
��ע:�����ֶβ��DZ����Ѿ����ڵ�����,���Խ������ֶο���α��
�鿴����
show partitions t3;
������������������
-- ����һ������,����������
alter table t3 add partition(dt='2020-06-03');
-- ���Ӷ������,����������
alter table t3 add partition(dt='2020-06-05') partition(dt='2020-06-06');
-- ���Ӷ��������������
hdfs dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2020-06-01 /user/hive/warehouse/mydb.db/t3/dt=2020-06-07
hdfs dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2020-06-01 /user/hive/warehouse/mydb.db/t3/dt=2020-06-08
-- ���Ӷ����������������
alter table t3 add
partition(dt='2020-06-07') location '/user/hive/warehouse/mydb.db/t3/dt=2020-06-07'
partition(dt='2020-06-08') location '/user/hive/warehouse/mydb.db/t3/dt=2020-06-08';
-- ��ѯ����
select * from t3;
�ķ�����hdfs·��
alter table t3 partition(dt='2020-06-01')
set location '/user/hive/warehouse/t3/dt=2020-06-03';
ɾ������
-- ����ɾ��һ����������,�ö��Ÿ���
alter table t3 drop partition(dt='2020-06-03');
alter table t3 drop partition(dt='2020-06-03'), partition(dt='2020-06-04');
�� 5 �� ��Ͱ��
�������ķ������߱�������������,�������ܸ�ϸ���ȵĻ�������,����Ҫʹ�÷�Ͱ���������ݻ��ֳɸ�ϸ�����ȡ������ݰ���ָ�����ֶν��зֳɶ��Ͱ��ȥ,�������ݰ����ֶν��л���,���ݰ����ֶλ��ֵ�����ļ�����ȥ����Ͱ��ԭ��:
-
MR��:
key.hashCode % reductTask -
Hive��:
��Ͱ�ֶ�.hashCode % ��Ͱ����
-- ��������
1 java 90
1 c 78
1 python 91
1 hadoop 80
2 java 75
2 c 76
2 python 80
2 hadoop 93
3 java 98
3 c 74
3 python 89
3 hadoop 91
5 java 93
6 c 76
7 python 87
8 hadoop 88
-- ������Ͱ��
create table course(
id int,
name string,
score int
)
clustered by (id) into 3 buckets
row format delimited
fields terminated by "\t";
-- ������ͨ��
create table course_common(
id int,
name string,
score int
)
row format delimited
fields terminated by "\t";
-- ��ͨ����������
load data local inpath '/home/hadoop/data/course.dat' into table course_common;
-- ͨ�� insert ... select ... ��Ͱ����������
insert into table course select * from course_common;
-- �۲��Ͱ���ݡ����ݰ���:(�����ֶ�.hashCode) % (��Ͱ��) ���з���
desc formatted course;
��ע:
-
��Ͱ����:
��Ͱ�ֶ�.hashCode % ��Ͱ�� -
��Ͱ����������ʱ,ʹ��
insert... select ...��ʽ���� -
����������˵Ҫʹ�÷�������Ҫ����
hive.enforce.bucketing=true,����Hive1.x ��ǰ�İ汾;Hive 2.x ��,ɾ���˸ò���,ʼ�տ��Է�Ͱ;
�� 6 �� �ı� & ɾ����
-- �ı�����
rename alter table course_common
rename to course_common1;
-- ��������change column
alter table course_common1
change column id cid int;
-- ���ֶ����͡�change column
alter table course_common1
change column cid cid string;
-- The following columns have types incompatible with the existing columns in their respective positions
-- ���ֶ���������ʱ,Ҫ������������ת����Ҫ����int����תΪstring,���� string����תΪint
-- �����ֶΡ�add columns
alter table course_common1
add columns (common string);
-- ɾ���ֶ�:replace columns
-- �������ֻ����Ԫ������ɾ�����ֶ�,��û�иĶ� hdfs�ϵ������ļ�
alter table course_common1 replace columns(
id string,
cname string,
score int
);
-- ɾ����
drop table course_common1;
HQL DDL������:
- ��Ҫ����:���ݿ⡢��
- ���ķ���:
- �ڲ���:ɾ����ʱ,ͬʱɾ��Ԫ���ݺͱ�����
- �ⲿ��:ɾ����ʱ,��ɾ��Ԫ����,������������;����������ʹ���ⲿ��
- ������:���շ����ֶν����е����ݷ����ڲ�ͬ��Ŀ¼��,���SQL��ѯ������
- ��Ͱ��:���շ�Ͱ�ֶ�,���������ݷֿ��� ��Ͱ�ֶ�.hashCode % ��Ͱ����
- ��Ҫ����:
create��alter��drop
HQL-���ݲ���
�� 1 �� ���ݵ���
װ������(load)
�����:
LOAD DATA [LOCAL] INPATH 'filepath'
[OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
-
LOCAL:LOAD DATA LOCAL�� �ӱ����ļ�ϵͳ�������ݵ�Hive���С������ļ��´����Hive��ָ����λ��LOAD DATA�� ��HDFS�������ݵ�Hive���С�HDFS�ļ��ƶ���Hive��ָ����λ��
-
INPATH:�������ݵ�·�� -
OVERWRITE:���DZ�����������;�����ʾ������ -
PARTITION:�����ݼ��ص�ָ���ķ���
������:
-- ������
CREATE TABLE tabA (
id int,
name string,
area string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' ;
-- �����ļ�(~/data/sourceA.txt):
1,fish1,SZ
2,fish2,SH
3,fish3,HZ
4,fish4,QD
5,fish5,SR
-- �����ļ���
HDFS hdfs dfs -put sourceA.txt data/
װ������:
-- ���ر����ļ���hive(tabA)
LOAD DATA LOCAL INPATH '/home/hadoop/data/sourceA.txt' INTO TABLE tabA;
-- ��鱾���ļ� ����
-- ����hdfs�ļ���hive(tabA)
LOAD DATA INPATH 'data/sourceA.txt' INTO TABLE tabA;
-- ���HDFS�ļ�,�Ѿ���ת��
-- �������ݸ��DZ�����������
LOAD DATA INPATH 'data/sourceA.txt' OVERWRITE INTO TABLE tabA;
-- ������ʱ ��������
hdfs dfs -mkdir /user/hive/tabB hdfs dfs -put sourceA.txt /user/hive/tabB
CREATE TABLE tabB (
id INT,
name string,
area string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
Location '/user/hive/tabB';
��������(insert)
-- ����������
CREATE TABLE tabC (
id INT,
name string,
area string
)partitioned by (month string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
-- ��������
insert into table tabC
partition(month='202001')
values (5, 'wangwu', 'BJ'), (4, 'lishi', 'SH'), (3, 'zhangsan', 'TJ');
-- �����ѯ�Ľ������
insert into table tabC partition(month='202002')
select
id,
name,
area
from tabC where month='202001';
-- ���(�����)����ģʽ
from tabC
insert overwrite table tabC partition(month='202003')
select id, name, area where month='202002'
insert overwrite table tabC partition(month='202004')
select id, name, area where month='202002';
-- select ����дfrom ��sqlǰ�Ѿ�д��
����������������(as select)
-- ���ݲ�ѯ���������
create table if not exists tabD as
select * from tabC;
-- ������� tabD ���Ƿ�����
ʹ��import��������
import table student2 partition(month='201709') from '/user/hive/warehouse/export/student';
�� 2 �� ���ݵ���
-- ����ѯ�������������
-- ֻ�� overwrite û�� into �����ǵ�������
-- local directory Ϊ���� linux�����ļ�·��
-- ������û��ָ�����ݷָ���ʽ,�����ļ��ڷָ�ΪhiveĬ�� `^A`����ʹ�� cat -A ����鿴
insert overwrite local directory '/home/hadoop/data/tabC'
select * from tabC;
-- ����ѯ�����ʽ�����������
insert overwrite local directory '/home/hadoop/data/tabC2'
row format delimited
fields terminated by ' '
select * from tabC;
-- ����ѯ���������HDFS
-- û�� local ����hdfs��·��
insert overwrite directory '/user/hadoop/data/tabC3'
row format delimited
fields terminated by ' '
select * from tabC;
-- dfs ��������ݵ����ء�������ִ�������ļ��Ŀ���
dfs -get /user/hive/warehouse/mydb.db/tabc/month=202001 /home/hadoop/data/tabC4
-- hive ��������ݵ����ء�ִ�в�ѯ����ѯ����ض����ļ�
-- ʹ�� hive -e ������hqlҪ���� ���� ,����Ĭ�ϲ�ѯ default ��
hive -e "select * from mydb.tabC" > a.log
-- export �������ݵ� HDFS�¡�ʹ��export��������ʱ,�����������б���Ԫ������Ϣ `_metadata`�ļ�
export table tabC to '/user/hadoop/data/tabC4';
-- export ����������,����ʹ�� import ����뵽 Hive ����
-- ʹ�� like tname�����ı��ṹ��ԭ��һ�¡�
-- create ... as select ... �ṹ���ܲ�һ��
create table tabE like tabc;
-- �鿴���ṹ
desc tabE;
import table tabE from ''/user/hadoop/data/tabC4';
�������
-- �ضϱ�,������ݡ�(ע��:���ܲ��� �ڲ��� )
truncate table tabE;
-- ������䱨��,�ⲿ�� ����ִ�� truncate ����
alter table tabC set tblproperties("EXTERNAL"="TRUE");
truncate table tabC;
��:
���ݵ���: load data / insert / create table .... as select ..... / import table
���ݵ���: insert overwrite ... diretory ... / hdfs dfs -get / hive -e "select ..." >
a.log / export table ��
Hive�����ݵ����뵼��������ʹ����������:Sqoop(������)��DataX(����)��;
HQL-DQL����ص㡿
DQL �C Data Query Language ���ݲ�ѯ����
select�:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]]
[LIMIT [offset,] rows]
sql�����дע������:
-
SQL���Դ�Сд������
-
SQL������дһ��(��SQL)Ҳ����д����(����SQL)
-
�ؼ��ֲ�����д,Ҳ���ܷ���
-
���Ӿ�һ��Ҫ����
-
ʹ��������ʽ,���SQL���Ŀɶ���(��Ҫ)
������,��������
-- �������� /home/hadoop/data/emp.dat
7369,SMITH,CLERK,7902,2010-12-17,800,,20
7499,ALLEN,SALESMAN,7698,2011-02-20,1600,300,30
7521,WARD,SALESMAN,7698,2011-02-22,1250,500,30
7566,JONES,MANAGER,7839,2011-04-02,2975,,20
7654,MARTIN,SALESMAN,7698,2011-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,2011-05-01,2850,,30
7782,CLARK,MANAGER,7839,2011-06-09,2450,,10
7788,SCOTT,ANALYST,7566,2017-07-13,3000,,20
7839,KING,PRESIDENT,,2011-11-07,5000,,10
7844,TURNER,SALESMAN,7698,2011-09-08,1500,0,30
7876,ADAMS,CLERK,7788,2017-07-13,1100,,20
7900,JAMES,CLERK,7698,2011-12-03,950,,30
7902,FORD,ANALYST,7566,2011-12-03,3000,,20
7934,MILLER,CLERK,7782,2012-01-23,1300,,10
-- ��������������
CREATE TABLE emp (
empno int,
ename string,
job string,
mgr int,
hiredate DATE,
sal int,
comm int,
deptno int
)row format delimited fields terminated by ",";
-- ��������
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.dat'
INTO TABLE emp;
�� 1 �� ������ѯ
-- ʡ��from�Ӿ�IJ�ѯ
select 8*888 ;
select current_date ;
-- ʹ���б��� as��ʡ��
select 8*888 product;
select current_date as currdate;
-- ȫ����ѯ
select * from emp;
-- ѡ���ض��в�ѯ
select ename, sal, comm from emp;
-- ʹ�ú���
select count(*) from emp;
-- count(colname) ���ֶν���count,��ͳ��NULL
select sum(sal) from emp;
select max(sal) from emp;
select min(sal) from emp;
select avg(sal) from emp;
-- ʹ��limit�Ӿ����Ʒ��ص�����
select * from emp limit 3;
�� 2 �� where �Ӿ�
WHERE�Ӿ����FROM�Ӿ�,ʹ��WHERE�Ӿ�,���˲���������������;
where �Ӿ��в���ʹ���еı���;
select * from emp where sal > 2000;
where�Ӿ��л��漰���϶�ıȽ����� �� ������;
�Ƚ������
�ٷ��ĵ�:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
| �Ƚ������ | ���� |
|---|---|
=��==��<=> | ���� |
| <>��!= | ������ |
| <��<=�� >��>= | ���ڵ��ڡ�С�ڵ��� |
| is [not] null | ���A����NULL,��TRUE,��֮����FALSE��ʹ��NOT�ؼ��ֽ���෴�� |
| in(value1,value2, ��) | ƥ���б��е�ֵ |
| LIKE | ���������ʽ,Ҳ��ͨ���ģʽ����x%�� ��ʾ��������ĸ ��x�� ��ͷ;��%x����ʾ��������ĸ��x����β;��%x%����ʾ��������ĸ��x��,����λ���ַ�������λ�á�ʹ��NOT�ؼ��ֽ���෴��% ����ƥ����������ַ�(������ַ�);_ ����ƥ��һ���ַ��� |
| [NOT] BETWEEN �� AND �� | ��Χ���ж�,ʹ��NOT�ؼ��ֽ���෴�� |
| RLIKE��REGEXP | ����java���������ʽ,ƥ�䷵��TRUE,��֮����FALSE��ƥ��ʹ�õ���JDK�е��������ʽ�ӿ�ʵ�ֵ�,��Ϊ����Ҳ�������еĹ�������,�������ʽ����������ַ���A��ƥ��,������ֻ�������ַ���ƥ�䡣 |
��ע:ͨ�������NULL��������,����ֵΪNULL;NULL<=>NULL�Ľ��Ϊtrue
�������
������������Ϥ��:and��or��not
-- �Ƚ������,null��������
select null=null;
select null==null;
select null<=>null;
-- ʹ�� is null �п�
select * from emp where comm is null;
-- ʹ�� in
select * from emp where deptno in (20, 30);
-- ʹ�� between ... and ...
select * from emp where sal between 1000 and 2000;
-- ʹ�� like
select ename, sal from emp where ename like '%L%';
-- ʹ�� rlike���������ʽ,������A��S��ͷ
select ename, sal from emp where ename rlike '^(A|S).*';
�� 3 �� group by�Ӿ�
GROUP BY���ͨ������麯��һ��ʹ��,����һ�������ж����ݽ��з���,��ÿ������оۺϲ�����
-- ����emp��ÿ�����ŵ�ƽ������
select deptno, avg(sal)
from emp
group by deptno;
-- ����empÿ��������ÿ����λ�����нˮ
select deptno, job, max(sal)
from emp
group by deptno, job;
- where�Ӿ���Ա��е����ݷ�������;having��Բ�ѯ���(�����Ժ�Ľ��)��������
- where�Ӿ䲻���з��麯��;having�Ӿ�����з��麯��
- havingֻ����group by����ͳ��֮��
-- ��ÿ�����ŵ�ƽ��нˮ����2000�IJ���
select deptno, avg(sal)
from emp
group by deptno
having avg(sal) > 2000;
�� 4 �� ������
Hive֧��ͨ����SQL JOIN��䡣Ĭ�������,��֧�ֵ�ֵ����,��֧�ַǵ�ֵ���ӡ�
JOIN ����о�����ʹ�ñ��ı�����ʹ�ñ������Լ�SQL���ı�д,ʹ�ñ���ǰ�������SQL�Ľ���Ч�ʡ�
���Ӳ�ѯ������Ϊ������:�����Ӻ�������,�������ӿɽ�һ��ϸ��Ϊ��������:
1. ������: [inner] join
2. ������ (outer join)
- �������ӡ� left [outer] join,���������ȫ����ʾ
- �������ӡ� right [outer] join,�ұ�������ȫ����ʾ
- ȫ�����ӡ� full [outer] join,���ű������ݶ���ʾ
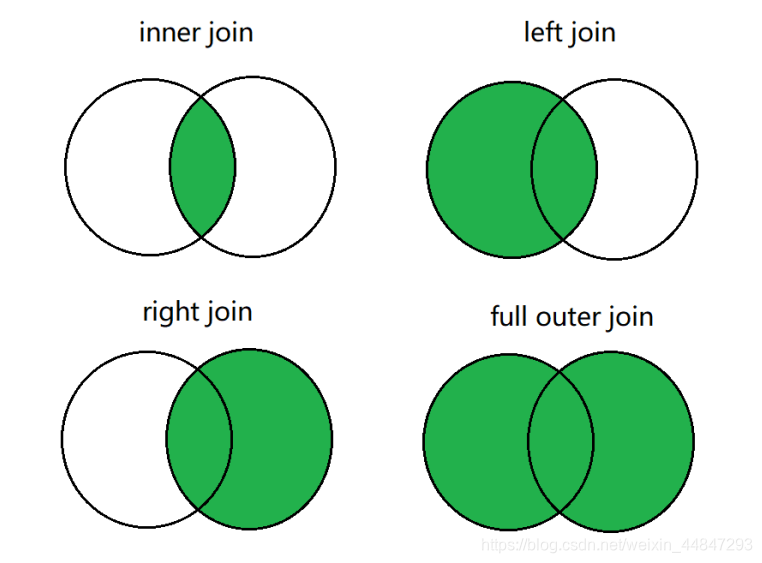
������ʾ:
-- ������
-- u1.txt����:
1,a
2,b
3,c
4,d
5,e
6,f
-- u2.txt����:
4,d
5,e
6,f
7,g
8,h
9,i
create table if not exists u1(
id int,
name string)
row format delimited fields terminated by ',';
create table if not exists u2(
id int,
name string)
row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/data/u1.txt' into table u1;
load data local inpath '/home/hadoop/data/u2.txt' into table u2;
-- ������
select * from u1 join u2 on u1.id = u2.id;
-- ��������
select * from u1 left join u2 on u1.id = u2.id;
-- ��������
select * from u1 right join u2 on u1.id = u2.id;
-- ȫ������
select * from u1 full join u2 on u1.id = u2.id;
�������
���� n�ű�,������Ҫ n-1 ����������������:�������ű�,������Ҫ��������������
������Ӳ�ѯ,��ѯ��ʦ��Ӧ�Ŀγ�,�Լ���Ӧ�ķ���,��Ӧ��ѧ��:
select *
from techer t
left join course c on t.t_id = c.t_id
left join score s on s.c_id = c.c_id
left join student stu on s.s_id = stu.s_id;
Hive���ǰ��մ����ҵ�˳��ִ��,Hive���ÿ�� JOIN ���Ӷ�������һ��MapReduce ����
����������л���������һ�� MapReduce job �Ա� t �ͱ� c �������Ӳ���;Ȼ��������һ�� MapReduce job ����һ�� MapReduce job ������ͱ� s �������Ӳ���;Ȼ���ټ���ֱ��ȫ������;
�ѿ�����
��������������������ѿ�����:
-
û����������
-
����������Ч
-
���������������
�����A��B�ֱ���M��N������,��ѿ������Ľ������ M*N ������;ȱʡ������hive��֧�ֵѿ���������;
set hive.strict.checks.cartesian.product=false;
select * from u1, u2;
�� 5 �� �����Ӿ䡾�ص㡿
ȫ������(order by)
order by �Ӿ������select���Ľ�β;
order by�Ӿ�����յĽ����������;
Ĭ��ʹ������(ASC);����ʹ��DESC,�����ֶ���֮���ʾ����;
ORDER BYִ��ȫ������,ֻ��һ��reduce;
-- ��ͨ����
select * from emp order by deptno;
-- ����������
select empno, ename, job, mgr, sal + nvl(comm, 0) salcomm, deptno
from emp
order by salcomm desc;
-- ��������
select empno, ename, job, mgr, sal + nvl(comm, 0) salcomm, deptno
from emp
order by deptno, salcomm desc;
-- �����ֶ�Ҫ������select�Ӿ��С����������ִ��(��Ϊselect�Ӿ���ȱ�� deptno):
select empno, ename, job, mgr, sal + nvl(comm, 0) salcomm
from emp
order by deptno, salcomm desc;
ÿ��MR�ڲ�����(sort by)
���ڴ��ģ���ݶ���order byЧ�ʵ�;
�ںܶ�ҵ��,���Dz�����Ҫȫ�����������,��ʱ����ʹ��sort by;
sort byΪÿ��reduce����һ�������ļ�,��reduce�ڲ���������,�õ��ֲ�����Ľ��;
-- ����reduce����
set mapreduce.job.reduces=2;
-- ���չ��ʽ���鿴Ա����Ϣ
select * from emp sort by sal desc;
-- ����ѯ������뵽�ļ���(���չ��ʽ���)��������������ļ�,ÿ���ļ��ڲ����ݰ� ���ʽ�������
insert overwrite local directory '/home/hadoop/output/sortsal'
select * from emp sort by sal desc;
��������(distribute by)
distribute by ���ض����з��͵��ض���reducer��,���ں�̵ľۺ� �� �������;
distribute by ������MR�еķ�������,���Խ��sort by����,ʹ������������;
distribute by Ҫд��sort by֮ǰ;
-- ����2��reducer task;�Ȱ� deptno ����,�ڷ����ڰ� sal+comm ����
set mapreduce.job.reduces=2;
-- �����������ļ�,�۲�������
insert overwrite local directory '/home/hadoop/output/distBy'
select empno, ename, job, deptno, sal + nvl(comm, 0) salcomm
from emp
distribute by deptno
sort by salcomm desc;
-- ������,���ݱ��ֵ���ͳһ��,�����������Ľ��
-- �����ݷֵ�3������,ÿ��������������
set mapreduce.job.reduces=3;
insert overwrite local directory '/home/hadoop/output/distBy1'
select empno, ename, job, deptno, sal + nvl(comm, 0) salcomm
from emp
distribute by deptno
sort by salcomm desc;
Cluster By
��distribute by �� sort by��ͬһ���ֶ�ʱ,��ʹ��cluster by���;
cluster by ֻ��������,����ָ���������;
-- ����ǵȼ۵�
select * from emp distribute by deptno sort by deptno;
select * from emp cluster by deptno;
������:
-
order by��ִ��ȫ������,Ч�ʵ͡���������������
-
sort by��ʹ���ݾֲ�����(��reduce�ڲ�����)
-
distribute by������ָ�������������ݷ���,����sort by����,ʹ���ݾֲ�����
-
cluster by����distribute by �� sort by��ͬһ���ֶ�ʱ,��ʹ��cluster by���
����
Hive���ú���:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inFunctions
�� 1 �� ϵͳ���ú���
�鿴ϵͳ����
-- �鿴ϵͳ�Դ�����
show functions;
-- ��ʾ�Դ��������÷�
desc function upper;
desc function extended upper;
���ں�������Ҫ��
-- ��ǰǰ����
select current_date;
select unix_timestamp();
-- ����ʹ��current_timestamp,��û�����Ŷ�����
select current_timestamp();
-- ʱ���ת����
select from_unixtime(1505456567);
select from_unixtime(1505456567, 'yyyyMMdd');
select from_unixtime(1505456567, 'yyyy-MM-dd HH:mm:ss');
-- ����תʱ���
select unix_timestamp('2019-09-15 14:23:00');
-- ����ʱ���
select datediff('2020-04-18','2019-11-21');
select datediff('2019-11-21', '2020-04-18');
-- ��ѯ���µڼ���
select dayofmonth(current_date);
-- ������ĩ:
select last_day(current_date);
-- ���µ�1��:
select date_sub(current_date, dayofmonth(current_date)-1)
-- �¸��µ�1��:
select add_months(date_sub(current_date,
dayofmonth(current_date)-1), 1)
-- �ַ���תʱ��(�ַ�������Ϊ:yyyy-MM-dd��ʽ)
select to_date('2020-01-01');
select to_date('2020-01-01 12:12:12');
-- ���ڡ�ʱ������ַ�������ʽ�������ʱ���ʽ
select date_format(current_timestamp(), 'yyyy-MM-dd HH:mm:ss');
select date_format(current_date(), 'yyyyMMdd');
select date_format('2020-06-01', 'yyyy-MM-dd HH:mm:ss');
-- ����emp����,ÿ���˵Ĺ���
select *, round(datediff(current_date, hiredate)/365,1) workingyears from emp;
�ַ�������
-- תСд��lower
select lower("HELLO WORLD");
-- ת��д��upper
select lower(ename), ename from emp;
-- ���ַ������ȡ�length
select length(ename), ename from emp;
-- �ַ���ƴ�ӡ� concat / ||
select empno || " " ||ename idname from emp;
select concat(empno, " " ,ename) idname from emp;
-- ָ���ָ�����concat_ws(separator, [string | array(string)]+)
SELECT concat_ws('.', 'www', array('lagou', 'com'));
select concat_ws(" ", ename, job) from emp;
-- ���Ӵ���substr
SELECT substr('www.lagou.com', 5);
SELECT substr('www.lagou.com', -5);
SELECT substr('www.lagou.com', 5, 5);
-- �ַ����з֡�split,ע�� '.' Ҫת��
select split("www.lagou.com", "\\.");
���ֺ���
-- �������롣round
select round(314.15926);
select round(314.15926, 2);
select round(314.15926, -2);
-- ����ȡ����ceil
select ceil(3.1415926);
-- ����ȡ����floor
select floor(3.1415926);
-- ������ѧ��������:����ֵ��ƽ�����������������㡢���������
������������Ҫ��
-- if (boolean testCondition, T valueTrue, T valueFalseOrNull)
select sal, if (sal<1500, 1, if (sal < 3000, 2, 3)) from emp;
-- CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
-- ��emp����Ա�����ʵȼ�����:0-1500��1500-3000��3000����
select sal, if (sal<=1500, 1, if (sal <= 3000, 2, 3)) from emp;
-- CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
-- ���������� case when ��ֱ��
select sal, case when sal<=1500 then 1
when sal<=3000 then 2
else 3 end sallevel
from emp;
-- �������ȼ�
select ename, deptno,
case deptno when 10 then 'accounting'
when 20 then 'research'
when 30 then 'sales'
else 'unknown' end deptname
from emp;
select ename, deptno,
case when deptno=10 then 'accounting'
when deptno=20 then 'research'
when deptno=30 then 'sales'
else 'unknown' end deptname
from emp;
-- COALESCE(T v1, T v2, ...)�����ز����еĵ�һ���ǿ�ֵ;�������ֵ��Ϊ NULL,��ô����NULL
select sal, coalesce(comm, 0) from emp;
-- isnull(a) isnotnull(a)
select * from emp where isnull(comm);
select * from emp where isnotnull(comm);
-- nvl(T value, T default_value)
select empno, ename, job, mgr, hiredate, deptno, sal + nvl(comm,0) sumsal from emp;
-- nullif(x, y) ���Ϊ��,����Ϊa
SELECT nullif("b", "b"), nullif("b", "a");
UDTF ��������Ҫ��
UDTF : User Defined Table-Generating Functions���û���������ɺ���,һ������,���������
-- explode,ը�Ѻ���
-- ���ǽ�һ���и��ӵ� array ���� map �ṹ��ֳɶ���
select explode(array('A','B','C')) as col;
select explode(map('a', 8, 'b', 88, 'c', 888));
-- UDTF's are not supported outside the SELECT clause, nor nested in expressions
-- SELECT pageid, explode(adid_list) AS myCol... is not supported
-- SELECT explode(explode(adid_list)) AS myCol... is not supported
-- lateral view ���� �����ɺ���explode���ʹ��
-- lateral view �:
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)* fromClause: FROM baseTable (lateralView)*
-- lateral view �Ļ���ʹ��
with t1 as (
select 'OK' cola, split('www.lagou.com', '\\.') colb
)
select cola, colc
from t1
lateral view explode(colb) t2 as colc;
-- SQL
select uid, tag
from market
lateral view explode(split(tags, ",")) t2 as tag;
UDTF ����1:
-- ����(uid tags):
1 1,2,3
2 2,3
3 1,2
--��дsql,ʵ�����½��:
1 1
1 2
1 3
2 2
2 3
3 1
3 2
-- ������������
create table market(
uid int,
tags string
)
row format delimited fields terminated by '\t';
load data local inpath '/hivedata/market.txt' into table market;
UDTF ����2:
-- ������
lisi|Chinese:90,Math:80,English:70
wangwu|Chinese:88,Math:90,English:96
maliu|Chinese:99,Math:65,English:60
-- ������
create table studscore(
name string
,score map<String,string>)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';
-- ��������
load data local inpath '/home/hadoop/data/score.dat' overwrite into table studscore;
-- ����:�ҵ�ÿ��ѧԱ����óɼ�
-- ��һ��,ʹ�� explode ������map�ṹ���Ϊ����
select explode(score) as (subject, socre) from studscore;
-- ��������ȱ����ѧԱ����,����ѧԱ����������������������Ǵ���
select name, explode(score) as (subject, socre) from studscore;
-- �ڶ���:explode���� lateral view ��������,���������������һ���ܹ����� ���ֶ�
select name, subject, score1 as score from studscore
lateral view explode(score) t1 as subject, score1;
-- ������:�ҵ�ÿ��ѧԱ����óɼ�
select name, max(mark) maxscore
from (select name, subject, mark
from studscore lateral view explode(score) t1 as
subject, mark) t1
group by name;
with tmp as (
select name, subject, mark
from studscore lateral view explode(score) t1 as subject, mark
)
select name, max(mark) maxscore
from tmp
group by name;
��:
-
��һ������ת���ɶ�������,��������array��map���͵�����;
-
lateral view �� explode ����,��� UDTF �������Ӷ����е�����
�� 2 �� ���ں�������Ҫ��
���ں���������������,���ڷ���������һ�֡����ڽ�����ӱ���ͳ������Ĺ���ǿ��ĺ���,�ܶೡ������Ҫ�õ������ں������ڼ���������ij�־ۺ�ֵ,���;ۺϺ����IJ�֮ͬ����:����ÿ���鷵�ض���,���ۺϺ�������ÿ����ֻ����һ�С�
���ں���ָ���˷����������������ݴ��ڴ�С,������ݴ��ڴ�С���ܻ������еı仯���仯��
over �ؼ���
ʹ�ô��ں���֮ǰһ��ҪҪͨ��over()���п���
-- ��ѯemp�������ܺ�
select sum(sal) from emp;
-- ��ʹ�ô��ں���,�������
select ename, sal, sum(sal) salsum from emp;
-- ʹ�ô��ں���,��ѯԱ��������нˮ��нˮ�ܺ�
select ename, sal, sum(sal) over() salsum, concat(round(sal / sum(sal) over()*100, 1) || '%') ratiosal from emp;
ע��:���ں��������ÿһ�����ݵ�;���over��û�в���,Ĭ�ϵ���ȫ�������;
partition by�Ӿ�
��over�����н��з���,��ijһ�н��з���ͳ��,���ڵĴ�С���Ƿ����Ĵ�С
-- ��ѯԱ��������нˮ������нˮ�ܺ�
select ename, sal, sum(sal) over(partition by deptno) salsum from emp;
order by �Ӿ�
order by �Ӿ����������ݽ�������
-- ������order by�Ӿ�;sum:�ӷ���ĵ�һ�е���ǰ�����
select ename, sal, deptno, sum(sal) over(partition by deptno order by sal) salsum from emp;
window�Ӿ�
rows between ... and ...
���Ҫ�Դ��ڵĽ������ϸ���ȵĻ���,ʹ��window�Ӿ�,�����µļ���ѡ
��:!clear
-
unbounded preceding�����ڵ�һ������
-
n preceding�����ڵ�ǰ�е�ǰn������
-
current row����ǰ������
-
n following�����ڵ�ǰ�еĺ�n������
-
unbounded following���������һ������

-- rows between ... and ... �Ӿ�
-- �ȼۡ�����,��һ�е���ǰ�еĺ�
select ename, sal, deptno, sum(sal) over(partition by deptno order by ename) from emp;
select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between unbounded preceding and current
row
)
from emp;
-- ����,��һ�е����һ�еĺ�
select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between unbounded preceding and
unbounded following
)
from emp;
-- ����,ǰһ�� + ��ǰ�� +��һ��
select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between 1 preceding and 1 following
)
from emp;
��������
���Ǵ�1��ʼ,�����������ڷ����е�������
-
row_number()������˳�����Ӳ����ظ�;��1��2��3��4���� ��
-
RANK()�� ������Ȼ������������¿�λ;��1��2��2��4��5���� ��
-
DENSE_RANK()�� ������Ȼ��������в������¿�λ ;��1��2��2��3��4���� ��
-- row_number / rank / dense_rank
100 1 1 1
100 2 1 1
100 3 1 1
99 4 4 2
98 5 5 3
98 6 5 3
97 7 7 4
-- ������
class1 s01 100
class1 s03 100
class1 s05 100
class1 s07 99
class1 s09 98
class1 s02 98
class1 s04 97
class2 s21 100
class2 s24 99
class2 s27 99
class2 s22 98
class2 s25 98
class2 s28 97
class2 s26 96
-- ��������������
create table t2(
cname string,
sname string,
score int
) row format delimited fields terminated by '\t';
load data local inpath '/home/hadoop/data/t2.dat' into table t2;
-- ���հ༶,ʹ��3�ַ�ʽ�Գɼ���������
select cname, sname, score,
row_number() over (partition by cname order by score desc)
rank1,
rank() over (partition by cname order by score desc)
rank2,
dense_rank() over (partition by cname order by score desc)
rank3
from t2;
-- ��ÿ���༶ǰ3����ѧԱ--ǰ3���Ķ�����ʲô--����ʹ��dense_rank
select cname, sname, score, rank
from (select cname, sname, score,
dense_rank() over (partition by cname order by
score desc) rank
from t2) tmp
where rank <= 3;
�����
-
lag�����ص�ǰ�����е���һ������
-
lead�����ص�ǰ�����е���һ������
-
first_value��ȡ�����������,��ֹ����ǰ��,��һ��ֵ
-
last_value�������������,��ֹ����ǰ��,���һ��ֵ
-
ntile������������ݰ���˳���зֳ�nƬ,���ص�ǰ��Ƭֵ
-- �������� userpv.dat��cid ctime pv
cookie1,2019-04-10,1
cookie1,2019-04-11,5
cookie1,2019-04-12,7
cookie1,2019-04-13,3
cookie1,2019-04-14,2
cookie1,2019-04-15,4
cookie1,2019-04-16,4
cookie2,2019-04-10,2
cookie2,2019-04-11,3
cookie2,2019-04-12,5
cookie2,2019-04-13,6
cookie2,2019-04-14,3
cookie2,2019-04-15,9
cookie2,2019-04-16,7
-- �������
create table userpv(
cid string,
ctime date,
pv int
)
row format delimited fields terminated by ",";
-- ��������
Load data local inpath '/home/hadoop/data/userpv.dat' into table
userpv;
-- lag�����ص�ǰ�����е���һ������
-- lead����������lag����
select cid, ctime, pv,
lag(pv) over(partition by cid order by ctime) lagpv,
lead(pv) over(partition by cid order by ctime) leadpv
from userpv;
-- first_value / last_value
select cid, ctime, pv,
first_value(pv) over (partition by cid order by ctime rows
between unbounded preceding and unbounded following) as firstpv,
last_value(pv) over (partition by cid order by ctime rows
between unbounded preceding and unbounded following) as lastpv
from userpv;
-- ntile������cid���з���,ÿ�����ݷֳ�2��
select cid, ctime, pv,
ntile(2) over(partition by cid order by ctime) ntile
from userpv;
sql������
����7���¼���û�
-- ���ݡ�uid dt status(1 ������¼,0 �쳣)
1 2019-07-11 1
1 2019-07-12 1
1 2019-07-13 1
1 2019-07-14 1
1 2019-07-15 1
1 2019-07-16 1
1 2019-07-17 1
1 2019-07-18 1
2 2019-07-11 1
2 2019-07-12 1
2 2019-07-13 0
2 2019-07-14 1
2 2019-07-15 1
2 2019-07-16 0
2 2019-07-17 1
2 2019-07-18 0
3 2019-07-11 1
3 2019-07-12 1
3 2019-07-13 1
3 2019-07-14 0
3 2019-07-15 1
3 2019-07-16 1
3 2019-07-17 1
3 2019-07-18 1
-- �������
create table ulogin(
uid int,
dt date,
status int
)
row format delimited fields terminated by ' ';
-- ��������
load data local inpath '/home/hadoop/data/ulogin.dat' into table ulogin;
-- ����ֵ�����,�����г��������⡣��Ҳ��ͬһ��,�������ɰ�������˼·����
-- 1��ʹ�� row_number �����ڸ����ݱ��(rownum)
-- 2��ij��ֵ - rownum = gid,�õ����������Ϊ���������������
-- 3��������õ�gid,��Ϊ��������,�����ս��
select uid, dt,
date_sub(dt, row_number() over (partition by uid order by
dt)) gid
from ulogin
where status=1;
select uid, count(*) countlogin
from (select uid, dt,
date_sub(dt, row_number() over (partition by uid
order by dt)) gid
from ulogin
where status=1) t1
group by uid, gid
having countlogin >= 7;
��дsql���ʵ��ÿ��ǰ����,����һ������,ͬʱ���ǰ��������������ķֲ�
-- ���ݡ�sid class score
1 1901 90
2 1901 90
3 1901 83
4 1901 60
5 1902 66
6 1902 23
7 1902 99
8 1902 67
9 1902 87
-- ��������������:
class score rank lagscore
1901 90 1 0
1901 90 1 0
1901 83 2 -7
1901 60 3 -23
1902 99 1 0
1902 87 2 -12
1902 67 3 -20
-- �������
create table stu(
sno int,
class string,
score int
)row format delimited fields terminated by ' ';
-- ��������
load data local inpath '/home/hadoop/data/stu.dat' into table stu;
-- ���˼·:
-- 1������������,����һ������,������dense_rank
-- 2������һ����������,������õ�������
-- 3������ NULL
with tmp as (
select sno, class, score,
dense_rank() over (partition by class order by score desc)
as rank
from stu
)
select class, score, rank,
nvl(score - lag(score) over (partition by class order by
score desc), 0) lagscore
from tmp
where rank<=3;
�� <=> ��
-- ����:id course
1 java
1 hadoop
1 hive
1 hbase
2 java
2 hive
2 spark
2 flink
3 java
3 hadoop
3 hive
3 kafka
-- ������������
create table rowline1(
id string,
course string
)row format delimited fields terminated by ' ';
load data local inpath '/root/data/data1.dat' into table rowline1;
-- ��дsql,�õ��������(1��ʾѡ��,0��ʾδѡ��)
id java hadoop hive hbase spark flink kafka
1 1 1 1 1 0 0 0
2 1 0 1 0 1 1 0
3 1 1 1 0 0 0 1
-- ʹ��case when;group by + sum
select id,
sum(case when course="java" then 1 else 0 end) as java,
sum(case when course="hadoop" then 1 else 0 end) as hadoop,
sum(case when course="hive" then 1 else 0 end) as hive,
sum(case when course="hbase" then 1 else 0 end) as hbase,
sum(case when course="spark" then 1 else 0 end) as spark,
sum(case when course="flink" then 1 else 0 end) as flink,
sum(case when course="kafka" then 1 else 0 end) as kafka
from rowline1
group by id;
-- ���ݡ�id1 id2 flag
a b 2
a b 1
a b 3
c d 6
c d 8
c d 8
-- ��дsqlʵ�����½��
id1 id2 flag
a b 2|1|3
c d 6|8
-- ������ & ��������
create table rowline2(
id1 string,
id2 string,
flag int
) row format delimited fields terminated by ' ';
load data local inpath '/root/data/data2.dat' into table rowline2;
-- ��һ�� ��Ԫ�ؾ�£
select id1, id2, collect_set(flag) flag from rowline2 group by
id1, id2;
select id1, id2, collect_list(flag) flag from rowline2 group by
id1, id2;
select id1, id2, sort_array(collect_set(flag)) flag from rowline2
group by id1, id2;
-- �ڶ��� ��Ԫ��������һ��
select id1, id2, concat_ws("|", collect_set(flag)) flag
from rowline2
group by id1, id2;
-- ���ﱨ��,CONCAT_WS must be "string or array<string>"����һ������ת
������
select id1, id2, concat_ws("|", collect_set(cast (flag as
string))) flag
from rowline2
group by id1, id2;
-- ������ rowline3
create table rowline3 as
select id1, id2, concat_ws("|", collect_set(cast (flag as
string))) flag
from rowline2
group by id1, id2;
-- ��һ��:�����ӵ�����չ��
select explode(split(flag, "\\|")) flat from rowline3;
-- �ڶ���:lateral view ���������ֶι���
select id1, id2, newflag
from rowline3 lateral view explode(split(flag, "\\|")) t1 as
newflag;
lateralView: LATERAL VIEW udtf(expression) tableAlias AS
columnAlias (',' columnAlias)*
fromClause: FROM baseTable (lateralView)*
��:
case when + sum + group by
collect_set��collect_list��concat_ws
sort_array
explode + lateral view
�� 3 �� �Զ��庯��
�� Hive �ṩ�����ú���������ʵ�ʵ�ҵ������Ҫʱ,���Կ���ʹ���û��Զ��庯��������չ���û��Զ��庯����Ϊ��������:
-
UDF(User Defined Function)���û��Զ��庯��,һ��һ��
-
UDAF(User Defined Aggregation Function)���û��Զ���ۼ�����,���һ��;������:count/max/min
-
UDTF(User Defined Table-Generating Functions)���û��Զ�������ɺ���,һ�����;������:explode
UDF����:
-
�̳�org.apache.hadoop.hive.ql.exec.UDF
-
��Ҫʵ��evaluate����;evaluate����֧������
-
UDF����Ҫ�з�������,���Է���null,���Ƿ������Ͳ���Ϊvoid
UDF��������
-
����maven java ����,��������
-
����java��̳�UDF,ʵ��evaluate ����
-
����Ŀ����ϴ�������
-
���ӿ�����jar��
-
���ú������Զ��庯������
-
ʹ���Զ��庯��
����:��չϵͳ nvl ��������:
nvl(ename, "OK"): ename==null => ���صڶ�������nvl
(ename, "OK"): ename==null or ename=="" or ename==" " => ���صڶ�������
1������maven java ����,��������
<!-- pom.xml �ļ� -->
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.7</version>
</dependency>
</dependencies>
2������java��̳�UDF,ʵ��evaluate ����
package cn.lagou.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public class nvl extends UDF {
public Text evaluate(final Text t, final Text x) {
if (t == null || t.toString().trim().length()==0) {
return x;
}
return t;
}
}
3������Ŀ����ϴ�������
4�����ӿ�����jar��(��Hive��������)
add jar /home/hadoop/hiveudf.jar;
5��������ʱ������ָ������һ��Ҫ������·��,������������
create temporary function mynvl as "cn.lagou.hive.udf.nvl";
6��ִ�в�ѯ
-- �������ܻ���
select mynvl(comm, 0) from mydb.emp;
-- �����������
select mynvl("", "OK");
select mynvl(" ", "OK");
7���˳�Hive������,�ٽ���Hive�����С�ִ�в���6�IJ���,���ֺ���ʧЧ��
��ע:������ʱ����ÿ�ν���Hive������ʱ,������ִ���������,�ܲ�����:
add jar /home/hadoop/hiveudf.jar;
create temporary function mynvl as "cn.lagou.hive.udf.nvl";
�ɴ������ú���:
1����jar�ϴ�HDFS
hdfs dfs -put hiveudf.jar jar/
2����Hive�������д������ú���
create function mynvl1 as 'cn.lagou.hive.udf.nvl' using jar 'hdfs:/user/hadoop/jar/hiveudf.jar';
-- ��ѯ���еĺ���,���� mynvl1 ���б���
show functions;
3���˳�Hive,�ٽ���,ִ�в���
-- �������ܻ���
select mynvl(comm, 0) from mydb.emp;
-- �����������
select mynvl("", "OK");
select mynvl(" ", "OK");
4��ɾ�����ú���,�����
drop function mynvl1;
show functions;
HQL-DML����
���ݲ�������DML(Data Manipulation Language),DML��Ҫ��������ʽ:����(INSERT)��ɾ��(DELETE)������(UPDATE)��
����(transaction)��һ�鵥Ԫ������,��Щ����Ҫô��ִ��,Ҫô����ִ��,��һ�����ɷָ�Ĺ�����Ԫ��
������е��ĸ�Ҫ��:ԭ����(Atomicity)��һ����(Consistency)��������(Isolation)���־���(Durability),���ĸ�����Ҫ��ͨ����ΪACID���ԡ�
-
ԭ������һ��������һ�������ٷָ�Ĺ�����λ,�����е����в���Ҫô������,Ҫô����������
-
һ�����������һ������ָ�����ִ�в����ƻ����ݿ����ݵ������Ժ�һ����,һ��������ִ��֮ǰ��ִ��֮��,���ݿⶼ���봦��һ����״̬��
-
���������ڲ���������,������������������,һ�������ִ�в��ܱ�����������š�����ͬ������������ͬ������ʱ,ÿ�������и������������ݿռ�,��һ�������ڲ��IJ�����ʹ�õ����ݶ��������������Ǹ����,����ִ�еĸ�������֮�䲻�ܻ�����š�
-
�־���������һ���ύ,�������ݿ������ݵĸı��Ӧ���������Եġ�
�� 1 �� Hive ����
Hive��0.14�汾��ʼ֧������ �� �м�����,��ȱʡ�Dz�֧�ֵ�,��ҪһЩ���ӵ����á�Ҫ��֧���м�insert��update��delete,��Ҫ����Hive֧������
Hive���������:
- Hive�ṩ�м����ACID����
- BEGIN��COMMIT��ROLLBACK ��ʱ��֧��,���в����Զ��ύ
- Ŀǰֻ֧�� ORC ���ļ���ʽ
- Ĭ�������ǹرյ�,��Ҫ���ÿ���
- Ҫ��ʹ����������,�������Ƿ�Ͱ��
- ֻ��ʹ���ڲ���
- ���һ��������ACIDд��(INSERT��UPDATE��DELETE),�����ڱ������ñ����� : ��transactional=true��
- ����ʹ����������� org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
- Ŀǰ֧�ֿ��ռ���ĸ��롣���ǵ�һ�����ݲ�ѯʱ,���ṩһ������һ���ԵĿ���
- LOAD DATA���Ŀǰ�����������ʱ��֧��
HDFS�Dz�֧���ļ�����;���ҵ��������ӵ��ļ�,HDFS���Զ����ݵ��û��ṩһ���Եġ�Ϊ����HDFS��֧�����ݵĸ���:
- ���ͷ��������ݶ������ڻ����ļ���(base files)
- �µļ�¼����,ɾ�������������ļ���(delta files)
- һ�������������һϵ�е������ļ�
- �ڶ�ȡ��ʱ��,�������ļ�����,ɾ���ϲ�,��ظ���ѯ
�� 2 �� Hive �������ʾ��
-- ��Щ����Ҳ����������hive-site.xml��
SET hive.support.concurrency = true;
-- Hive 0.x and 1.x only
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager =
org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
-- ���������ڸ��¡���������:�ڲ�����ORC��ʽ����Ͱ�����ñ�����
create table zxz_data(
name string,
nid int,
phone string,
ntime date)
clustered by(nid) into 5 buckets
stored as orc
tblproperties('transactional'='true');
-- ������ʱ��,�������Ͱ����������
create table temp1(
name string,
nid int,
phone string,
ntime date)
row format delimited
fields terminated by ",";
-- ����
name1,1,010-83596208,2020-01-01
name2,2,027-63277201,2020-01-02
name3,3,010-83596208,2020-01-03
name4,4,010-83596208,2020-01-04
name5,5,010-83596208,2020-01-05
-- ����ʱ����������;��������м�������
load data local inpath '/home/hadoop/data/zxz_data.txt' overwrite
into table temp1;
insert into table zxz_data select * from temp1;
-- ������ݺ��ļ�
select * from zxz_data;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
-- DML ����
delete from zxz_data where nid = 3;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
insert into zxz_data values ("name3", 3, "010-83596208",
current_date); -- ��֧��
insert into zxz_data values ("name3", 3, "010-83596208", "2020-
06-01"); -- ִ��
insert into zxz_data select "name3", 3, "010-83596208",
current_date;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
insert into zxz_data values
("name6", 6, "010-83596208", "2020-06-02"),
("name7", 7, "010-83596208", "2020-06-03"),
("name8", 9, "010-83596208", "2020-06-05"),
("name9", 8, "010-83596208", "2020-06-06");
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
update zxz_data set name=concat(name, "00") where nid>3;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
-- ��Ͱ�ֶβ�����,�������䲻��ִ��
-- Updating values of bucketing columns is not supported
update zxz_data set nid = nid + 1;
