DorisDB近期发布了1.15 / 1.16 两个大版本,下面介绍一下新版本的核心功能:
CBO 优化器
执行 SQL 查询时,需要依次经过查询解析器、分析器、优化器、查询执行层和存储层。查询优化器的输入是逻辑的抽象语法树,输出是“最优的” 物理执行计划。查询越复杂,数据量越大,物理执行计划的好坏对查询性能影响越大,所以成熟的商业数据库都需要一个强大的、成熟的查询优化器。
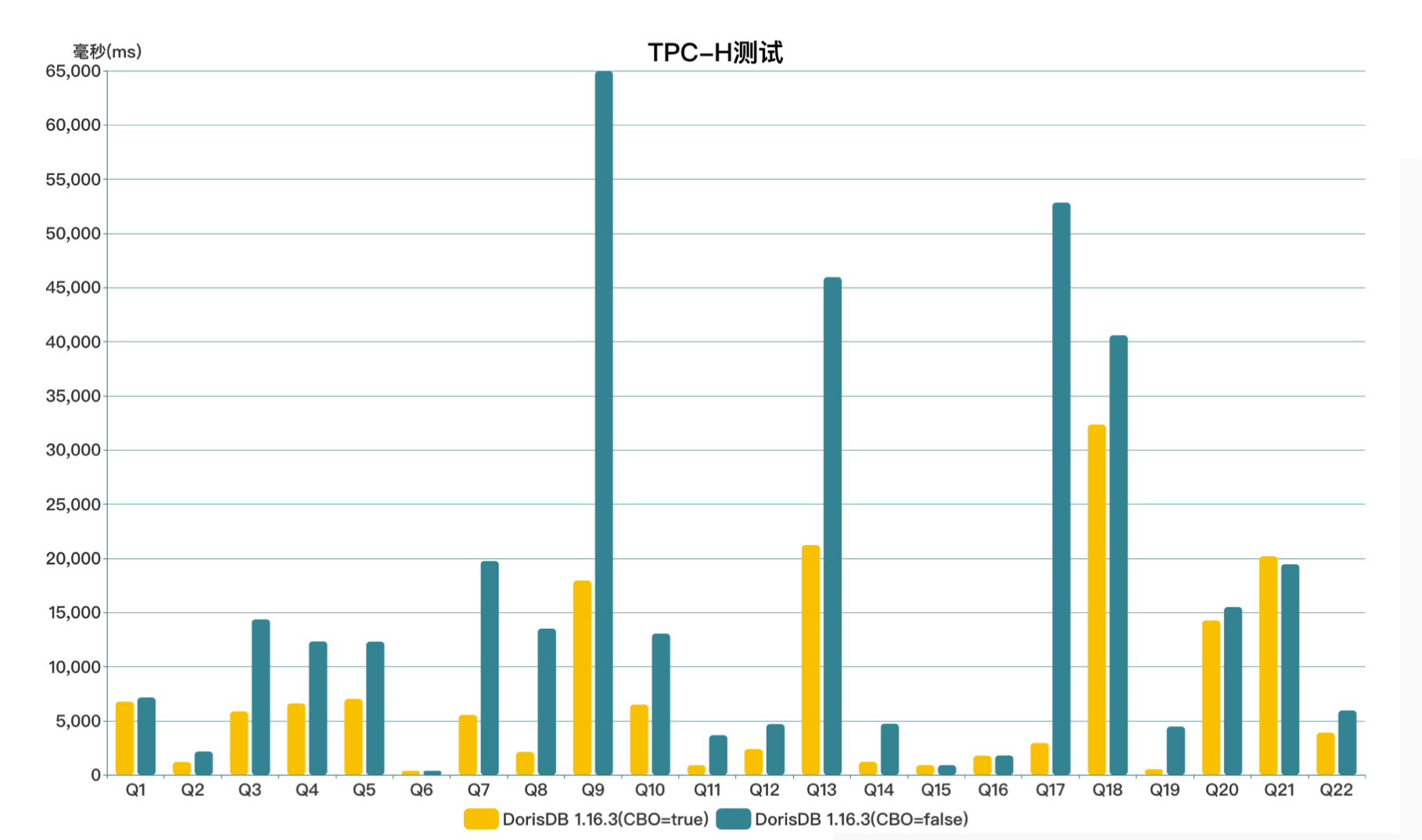
相比 DorisDB 旧的优化器:在功能上,CBO 优化器完整地支持了 TPC-DS 99条SQL,支持了更复杂的相关子查询;在性能上,CBO 优化器支持了更多的启发式优化规则,可以基于统计信息进行 Cost 估算,可以更准确地进行 Join 左右表调整、Join 多表 Reorder、Join 分布式方式选择,TPC-H 执行总时间是旧优化器的1/3,部分 TPC-DS 复杂查询有30到50倍的提升。
DorisDB CBO 优化器经过了内部上亿测试Case的测试,经过了 10 多家公司生产环境的验证(截止2021-07-12),已经可以稳定地在生产环境中应用。
欢迎大家试用:http://doc.dorisdb.com/2311684
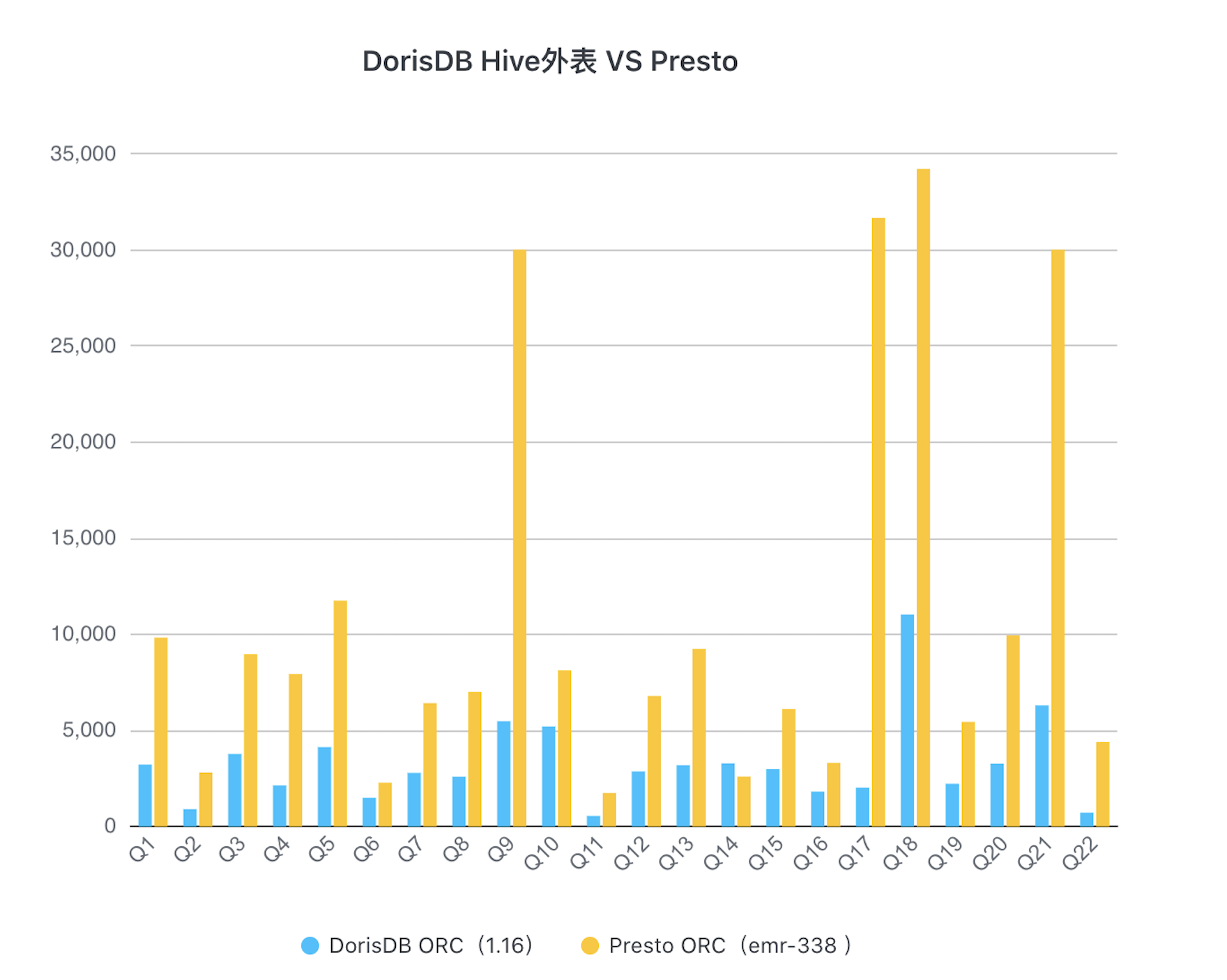
Hive外表能力增强
近两个月来,DorisDB进一步提升了联邦查询的能力,在之前Mysql和ES外表的基础上补充了Hive外表功能。目前,DorisDB已支持Parquet和ORC的文件格式,并且可以同步Hive元数据并感知到Hive metastore的元数据变更。我们进一步对比了Presto和DorisDB在同等环境下性能对比,ORC格式下DorisDB查询Hive外表的性能大约是Presto的3.35倍。
参考文档:http://doc.dorisdb.com/2146013#654_Hive_208
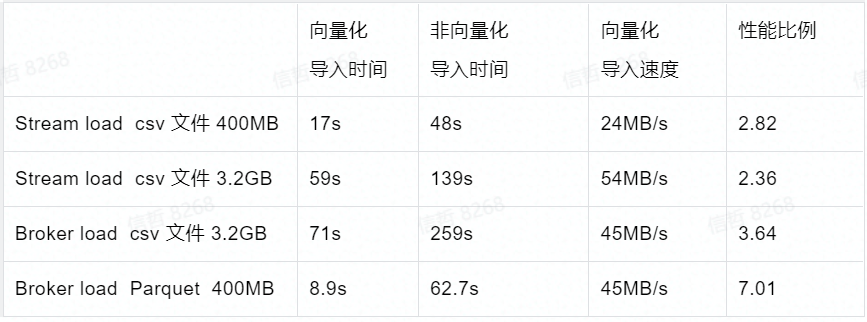
全面向量化导入
截止1.16版本,我们针对Broker Load/Routine Load/Stream Load等导入方式以及Parquet/ORC/Text/Json等数据格式,实现了全面的向量化。导入性能较DorisDB之前版本有2-7倍的提升。另外大数据量的导入稳定性也得到了加强。
在几个不同格式的数据集上,我们对比了向量化导入和非向量化导入的性能差异(以下是一组单FE,BE,Broker,单线程测试结果,增加BE和并行度以后性能还可以线性扩展):
其他优化
语法优化:
- 支持create table like语法。
- 批量分区创建语法支持。
管理功能:
-
查询黑名单,管理员可以禁止指定pattern的SQL。
-
内存使用优化,监控内存管理。
算子优化:
- Cross Join性能优化,右表较小的场景中,性能平均提升5倍以上。
导入生态:
- DataX插件DataX-DorisDB-Writer,方便各种数据源导入DorisDB。
- Stream load 支持自定义行分隔符row_delimiter。
- Routine load调度优化,可以同时调度1000个routine load任务。
更多详情可以参考论坛的Release Notes(https://forum.dorisdb.com/c/22-category/23-category/23),也欢迎大家给我们提出宝贵的意见,如有什么期待的功能可以加入交流群告诉我们。