目录
?一、Rest风格说明
Rest是一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。他主要用于客户端和服务端交互的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
1.基本Rest命令说明
| method | url地址 | 描述 |
| PUT | localhost:9200/索引名称/类型名称/文档ID | 创建文档(指定文档ID) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档ID) |
| POST | localhost:9200/索引名称/类型名称/文档ID/_update | 修改文档 |
| DELETE???????? | localhost:9200/索引名称/类型名称/文档ID | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档ID | 通过文档ID查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search???????? | 查询所有数据 |
实例:
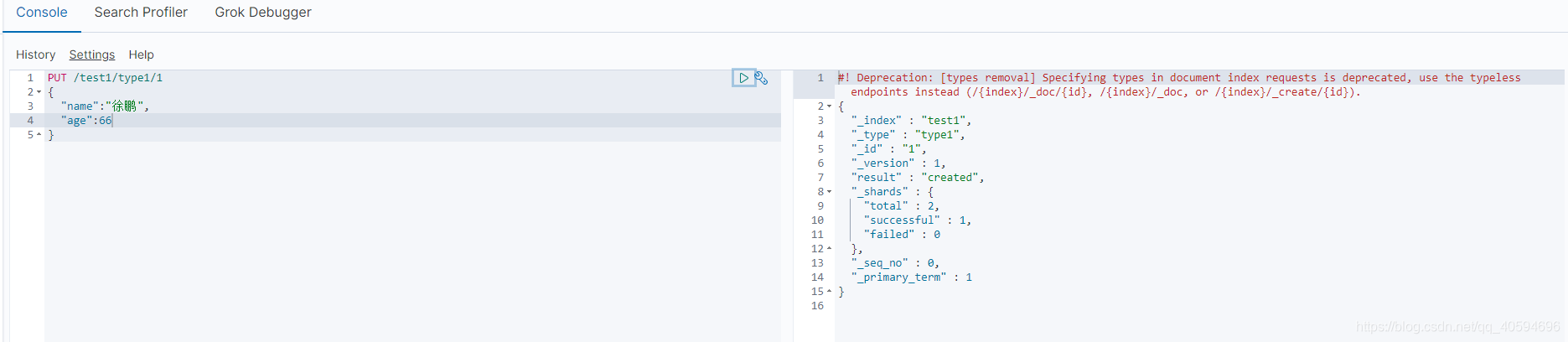
2.数据类型
- 字符串类型:text,keyword
- 数值类型:long,integer,short,byte,double,float,half float,scaled float
- 日期类型:date
- 布尔值类型:boolean
- 二进制类型:binary
二、关于索引的基本操作
1.新增
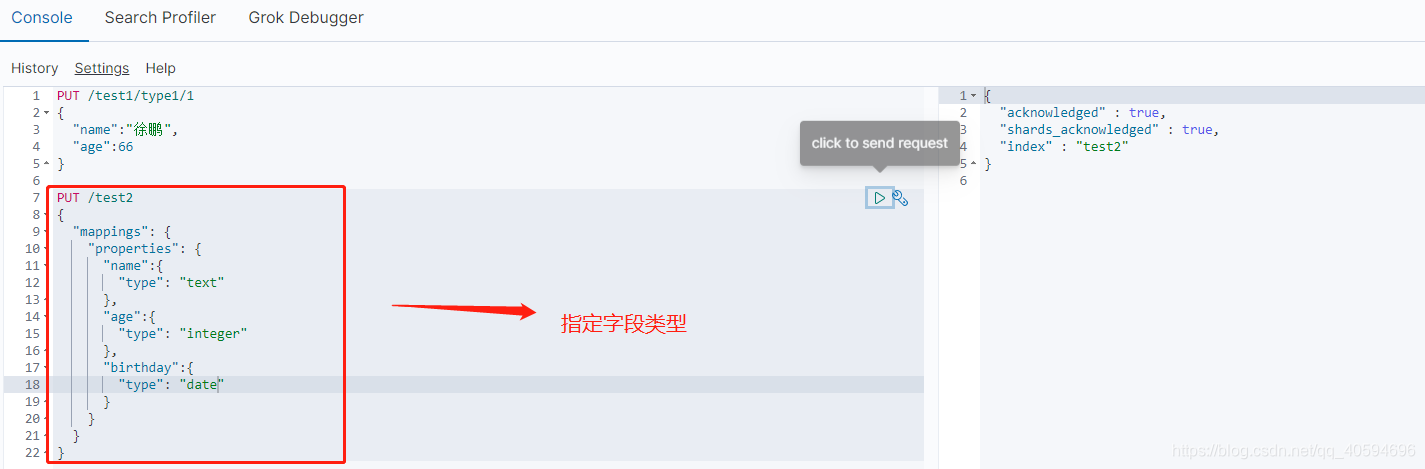
2.查看信息
GET 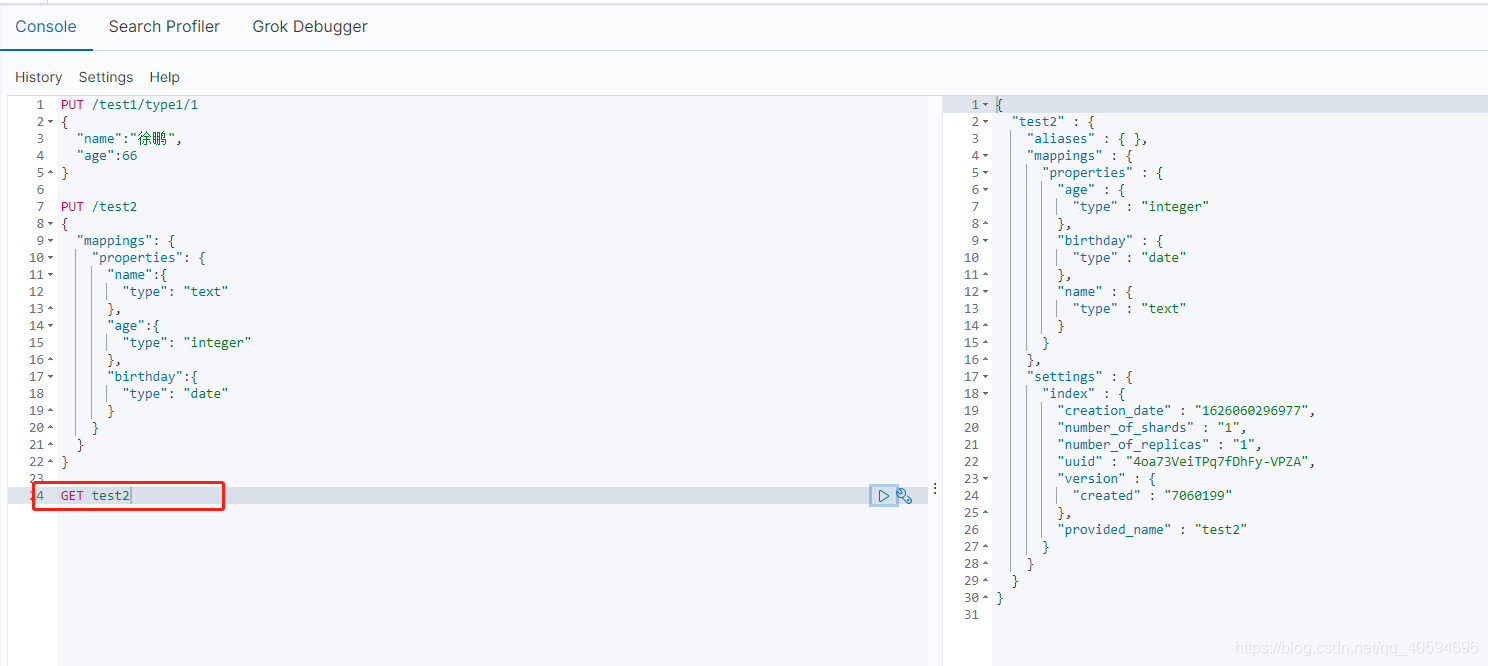
3._doc表示默认类型
type后面逐渐被弃用,我们用_doc来表示默认类型。
PUT /aa/_doc/bb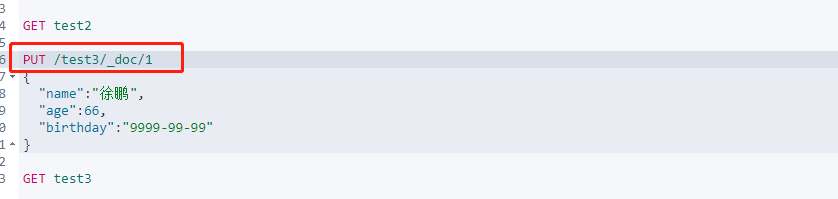
4.通过_cat获取详细信息
GET _cat/
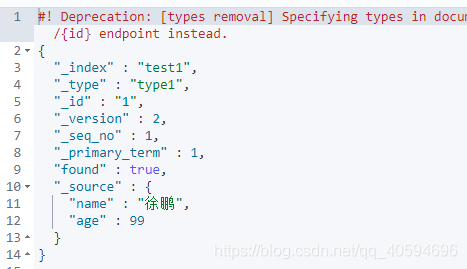
5.修改
*1)方法一
?在要修改的url后面添加_update,然后修改的内容加一层"doc",然后将自己要修改的字段放进去,就可修改指定字段,其他字段保持不变。

?
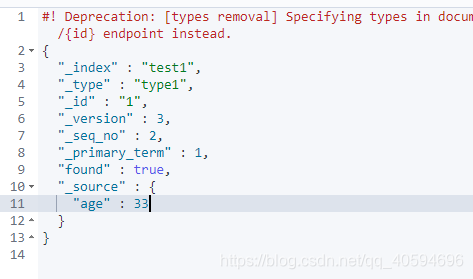
*2)方法二?
准确的说,这个不是修改,是覆盖,不推荐

?
6.删除
![]()
三、关于文档的基本操作
注意,这里的每一个操作都对应java里的一个API。
1.基本的增删改查
首先文档的基本增删改查和索引是一样的,包括PUT是新增,GET是查看,更新的两种方法也是完全一样。
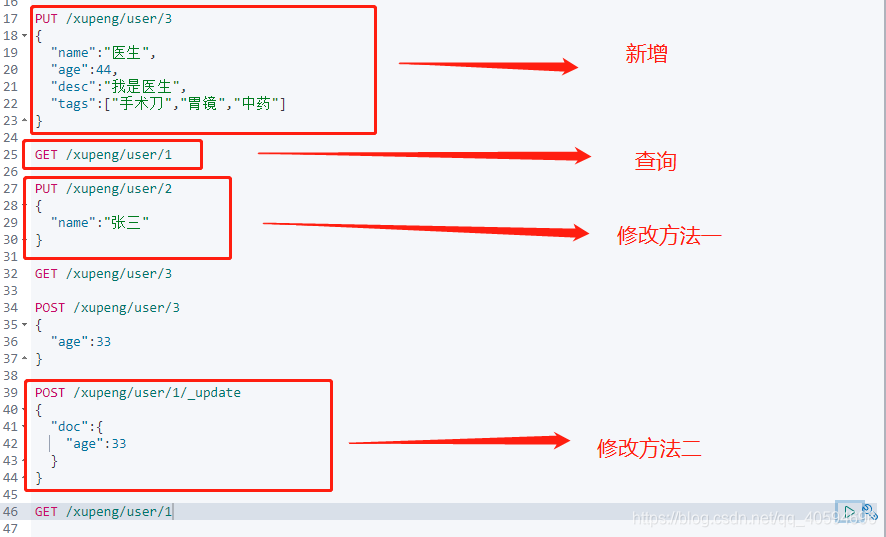
?2.根据ID查询
注意:所有的搜索都必须GET方法
![]()
3.根据内容查询
es内部会拆分你的内容,汉字会拆分成一个个的字,只要匹配上就给你查出来。
以下两种方法,写法不同,效果是一样的
(1)方法一
GET /xupeng/user/_search?q=name:鹏哥如图,因为包含鹏字,所以会被查出来,但是分数很低?
q:
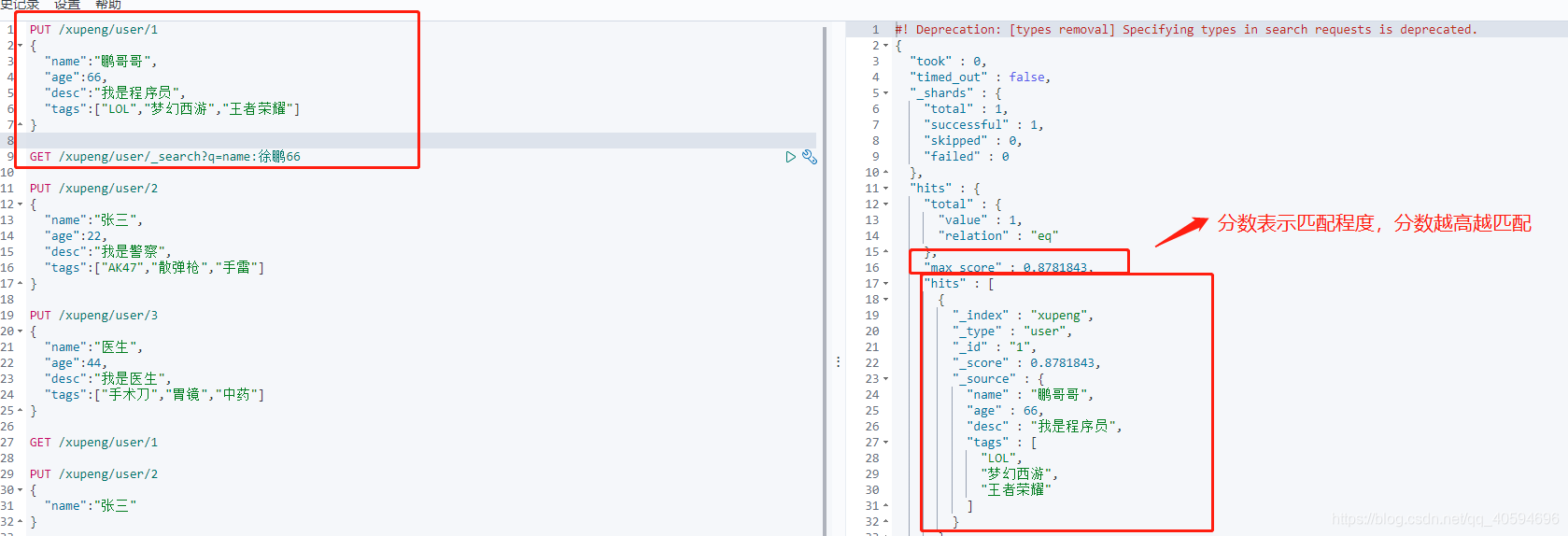
(2)方法二
GET /xupeng/user/_search
{
"query": {
"match": {
"name": "鹏哥"
}
}
}4.查询结果只显示指定字段
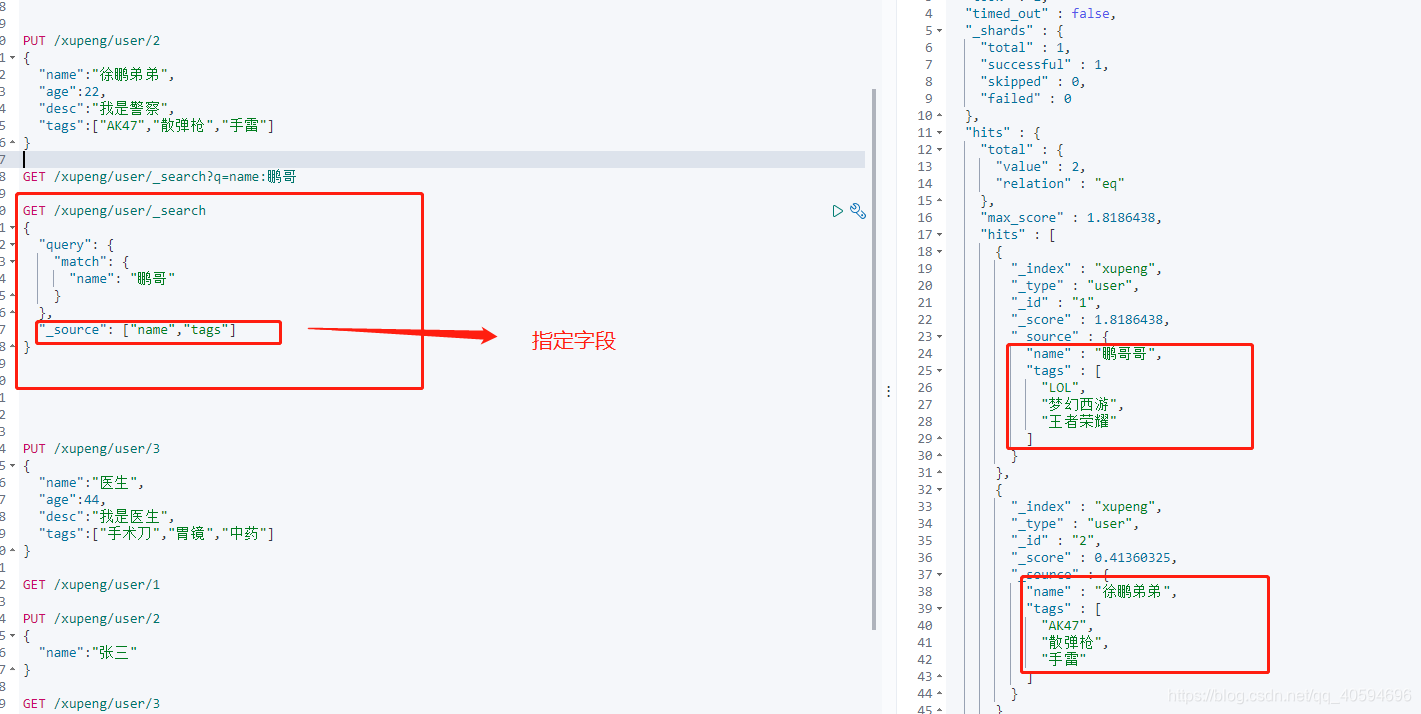
显示指定字段:
GET /xupeng/user/_search
{
"query": {
"match": {
"name": "鹏哥"
}
},
"_source": ["name","tags"]
}
5.根据字段排序
排序:
GET /xupeng/user/_search
{
"query": {
"match": {
"name": "鹏"
}
},
"_source": ["name","tags","age"],
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
6.分页查询
分页:
GET /xupeng/user/_search
{
"query": {
"match": {
"name": "鹏"
}
},
"_source": ["name","tags","age"],
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0,
"size": 2
}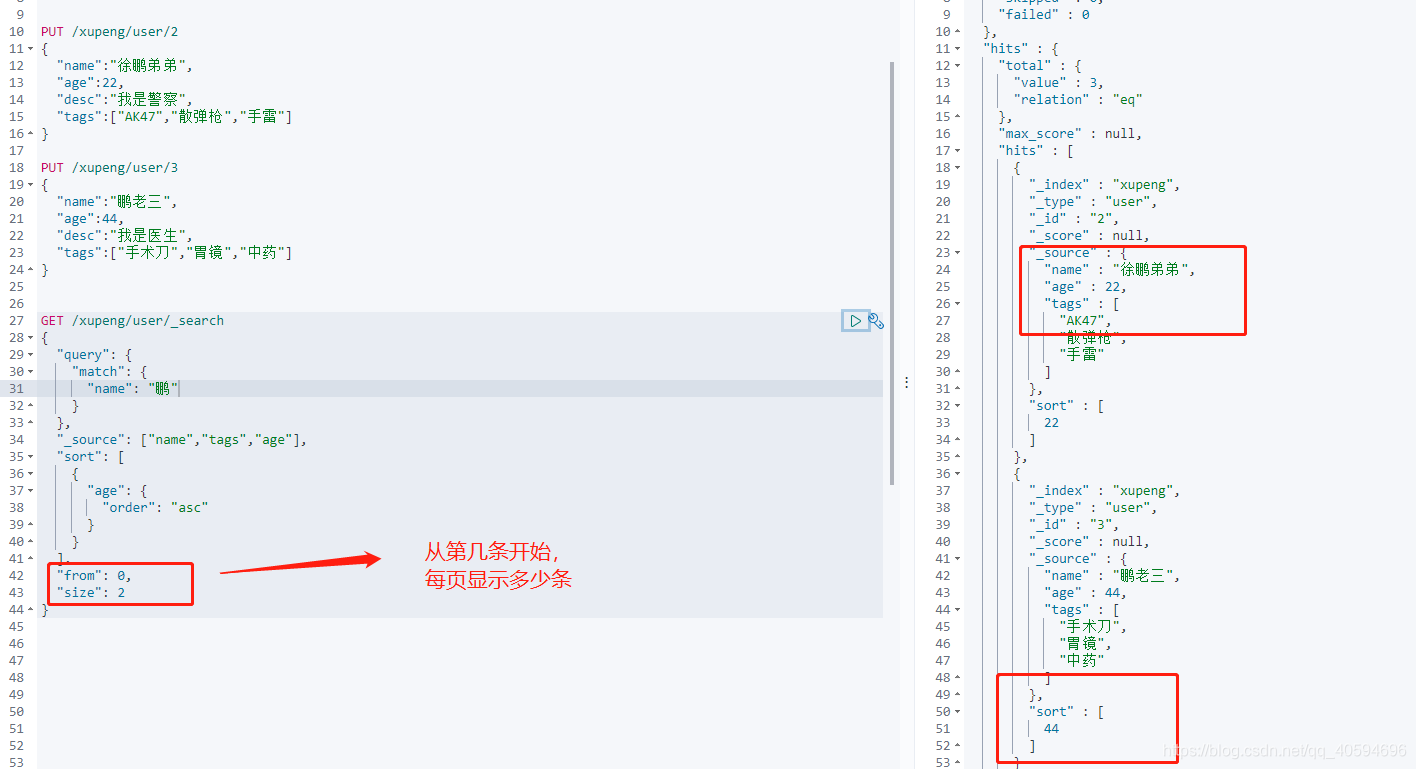
?注:下标从0开始计算?
7.布尔值查询
其实就是对应的多个条件查询。and和or的区别就是bool下面一个是must,一个是should
(1)and
这里稍微解释一下,字符串因为会被拆解,所以只要包含鹏这个字的都会匹配。但是age因为是数字,必须要一样才能匹配:
GET /xupeng/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name":"鹏"
}
},
{
"match": {
"age":44
}
}
]
}
}
}
(2)or
GET /xupeng/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name":"鹏"
}
},
{
"match": {
"age":44
}
}
]
}
}
}
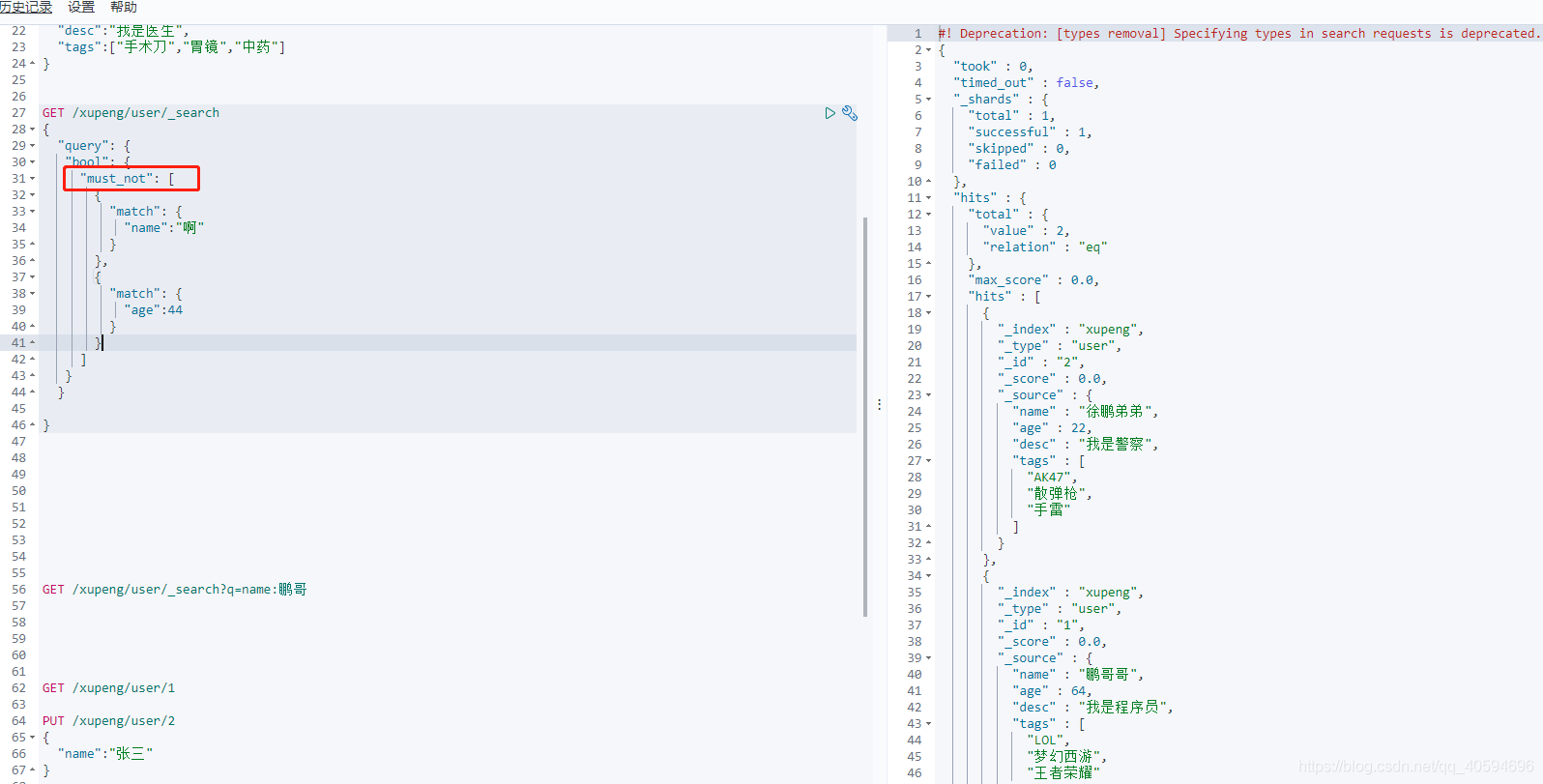
?(3)不等于(!=)
此处的must_not可以理解为!=
GET /xupeng/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name":"鹏"
}
},
{
"match": {
"age":44
}
}
]
}
}
}
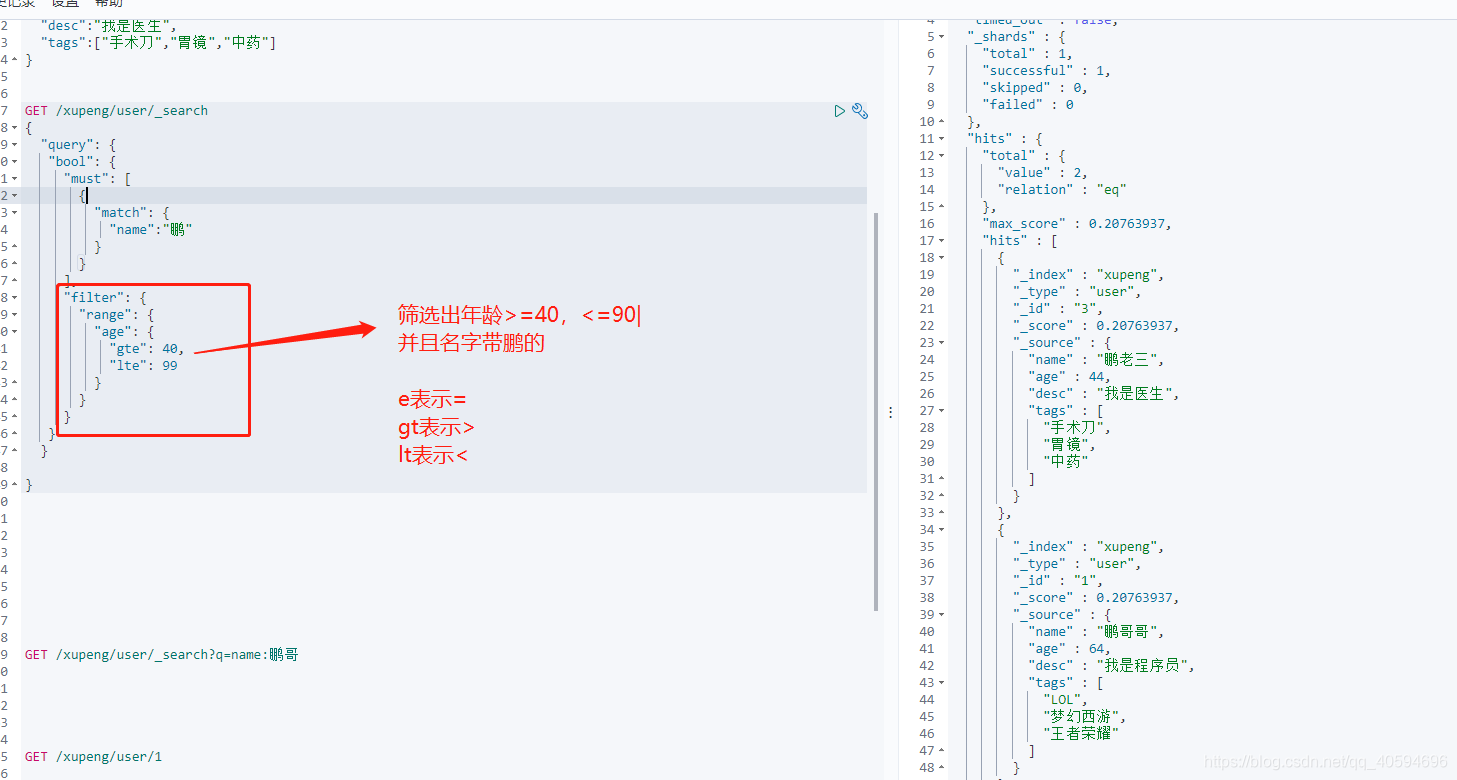
8.filter过滤
对应了sql里的>=和<=
GET /xupeng/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name":"鹏"
}
}
],
"filter": {
"range": {
"age": {
"gte": 40,
"lte": 99
}
}
}
}
}
}?
9.匹配多个内容查询
GET /xupeng/user/_search
{
"query": {
"match": {
"tags": "西游 中药"
}
}
}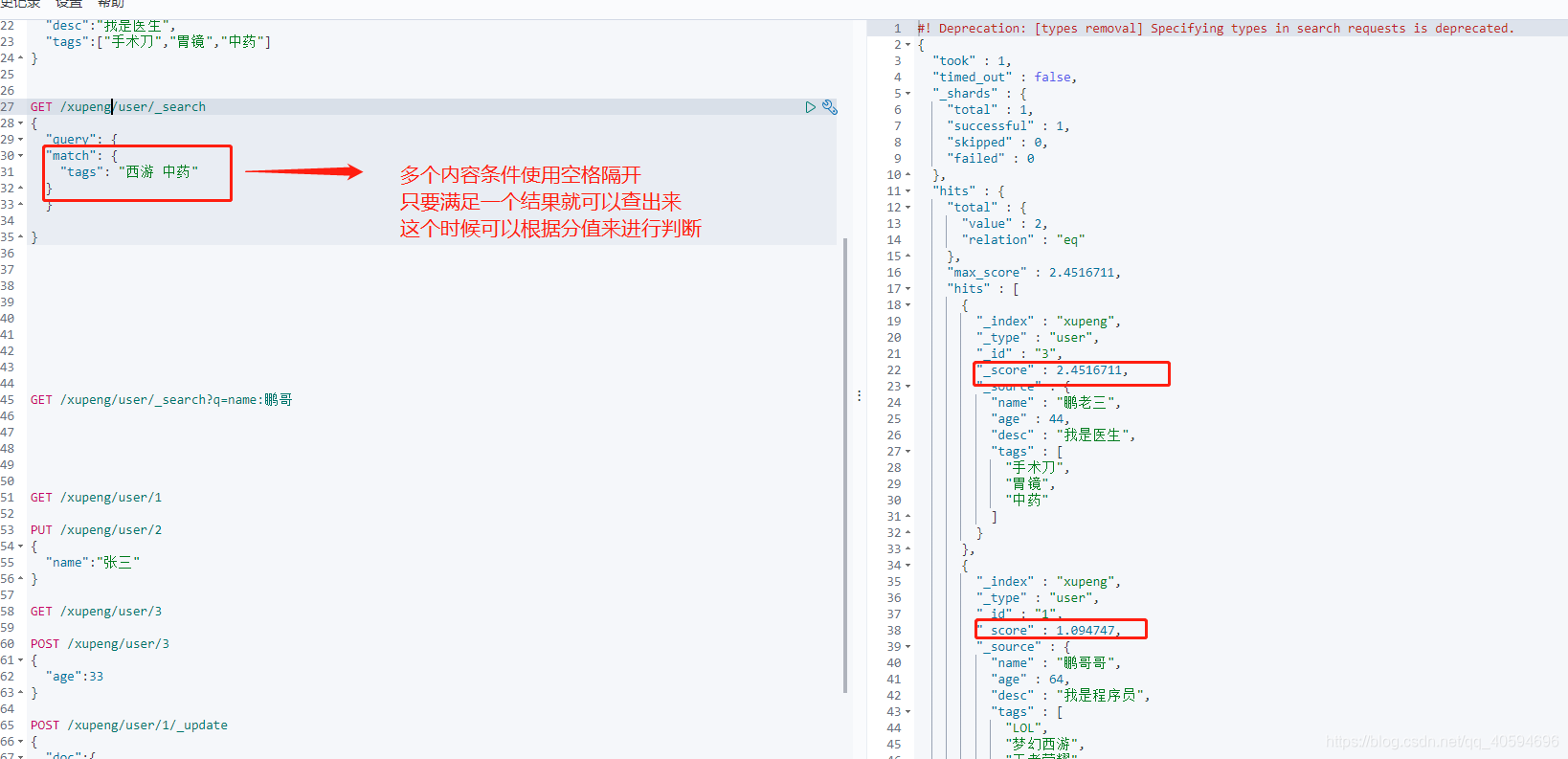
10.精确查询
trem查询是直接通过倒排索引指定的词条进行精确查询。
(1)关于分词
- term:直接根据倒排索引查询(效率高,类似于sql里的=)
- match:使用分词器解析(先分析文档,在通过分析的文档进行查询)
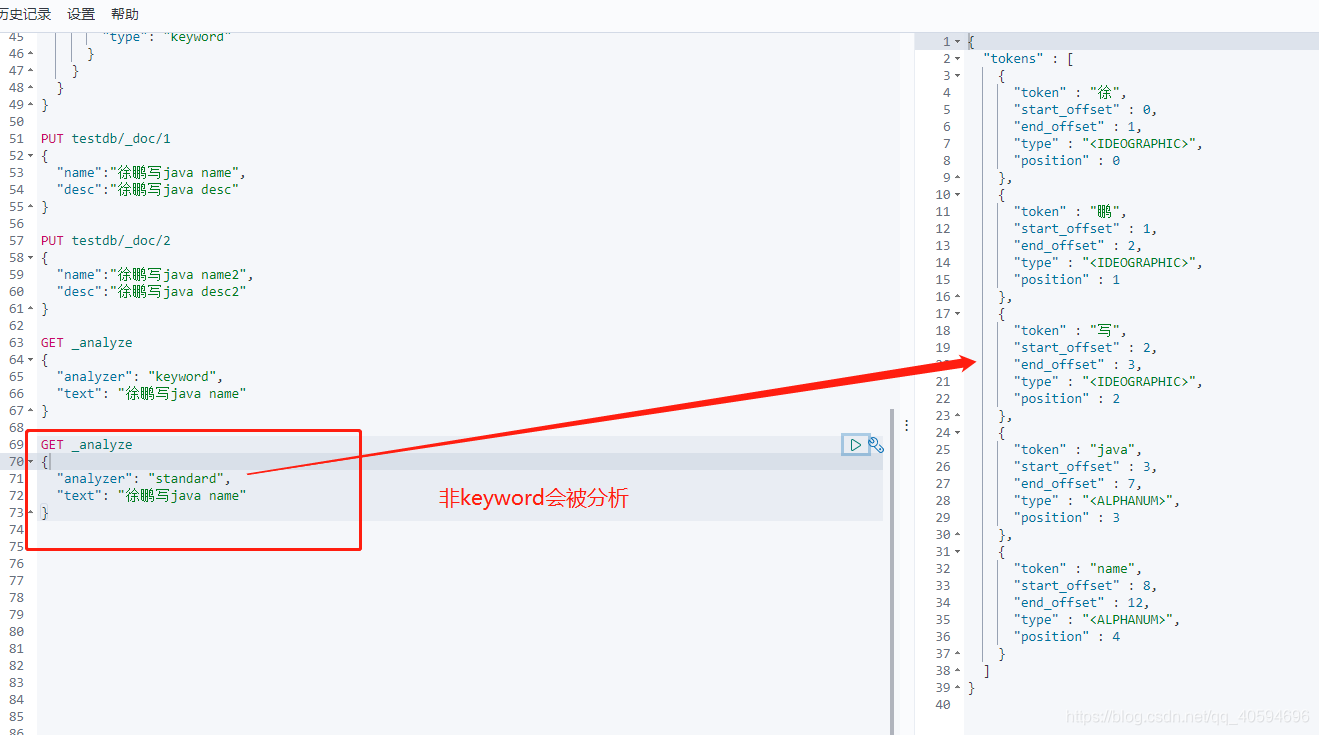
(2)text和keyword
text会被分词器解析,keyword不会被分词器解析
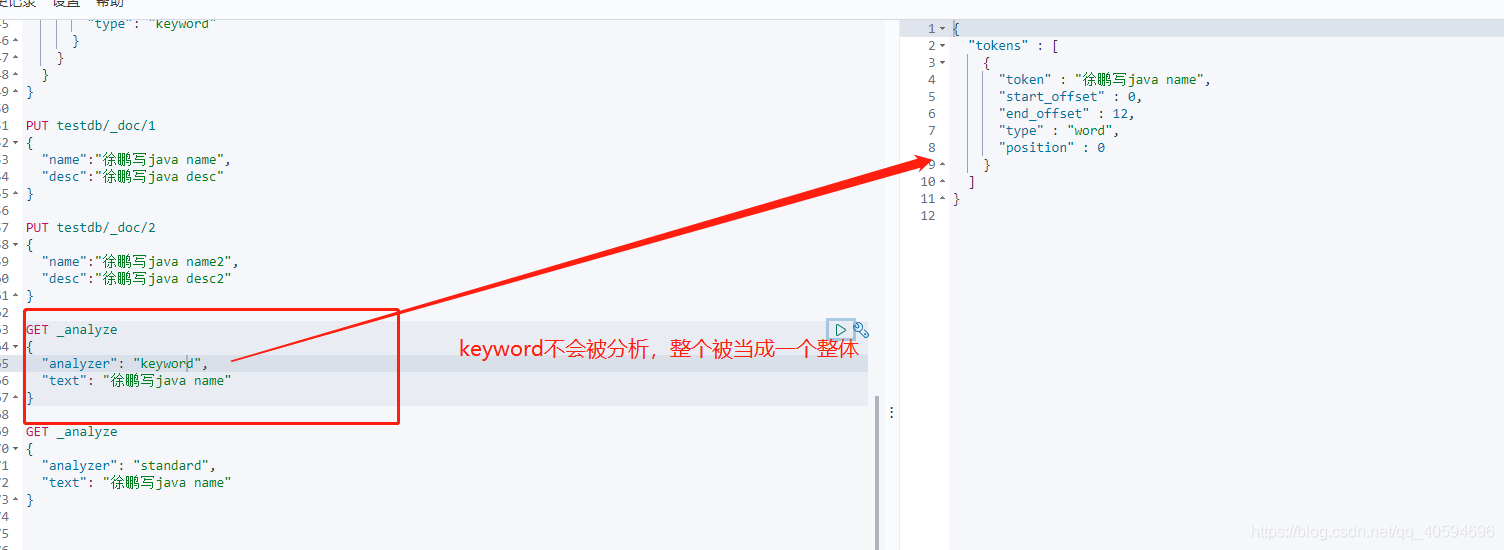
?
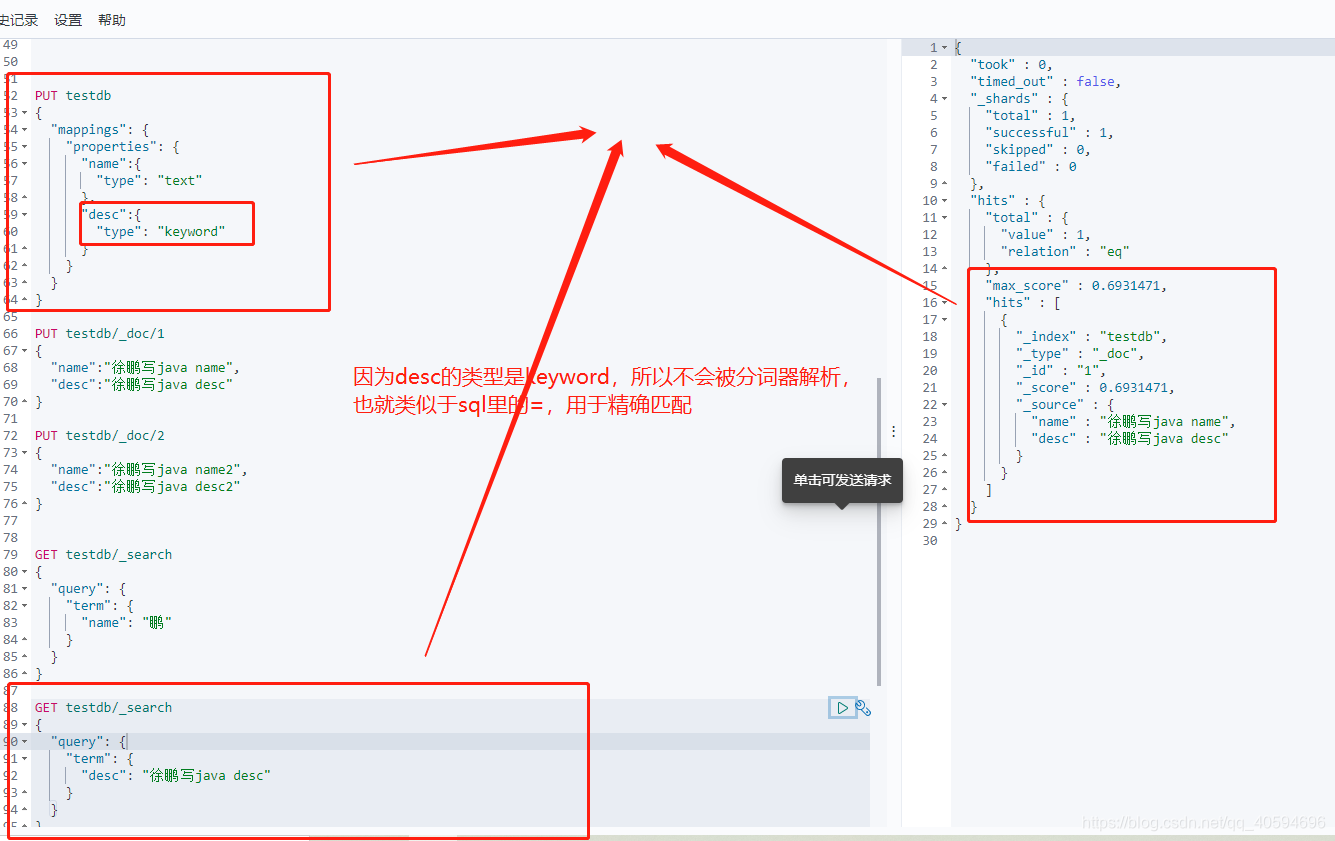
?(3)精确查询
GET testdb/_search
{
"query": {
"term": {
"name": "鹏"
}
}
}
GET testdb/_search
{
"query": {
"term": {
"desc": "徐鹏写java desc"
}
}
}
?
11.多个值精确查询
这句话的作用表示: t1 = 22 or t1 = 33
?完成多个值得查询:
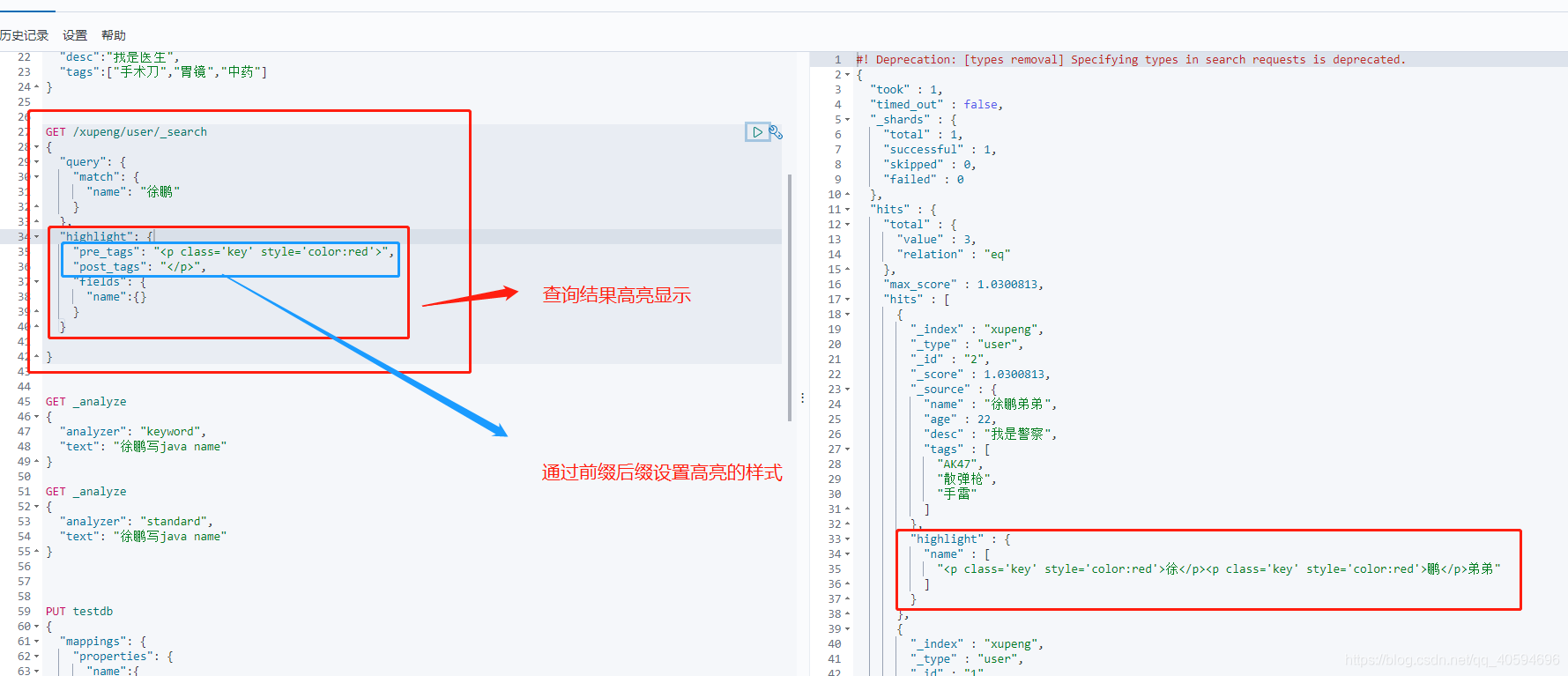
12.高亮
搜索的结果高亮显示:
GET /xupeng/user/_search
{
"query": {
"match": {
"name": "徐鹏"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name":{}
}
}
}
四、SpringBoot集成ES
1.官网文档地址
https://www.elastic.co/guide/en/elasticsearch/client/index.html
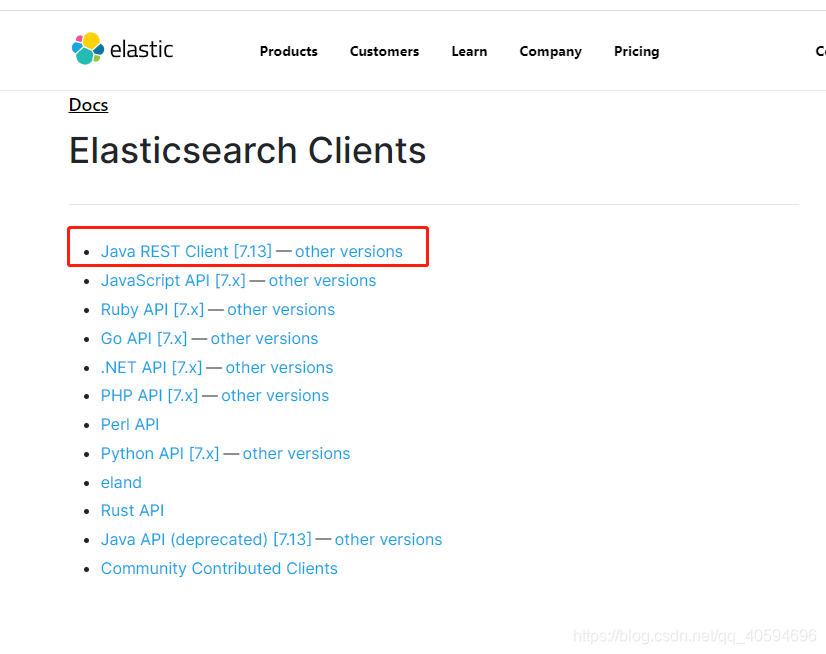
?2.新建项目
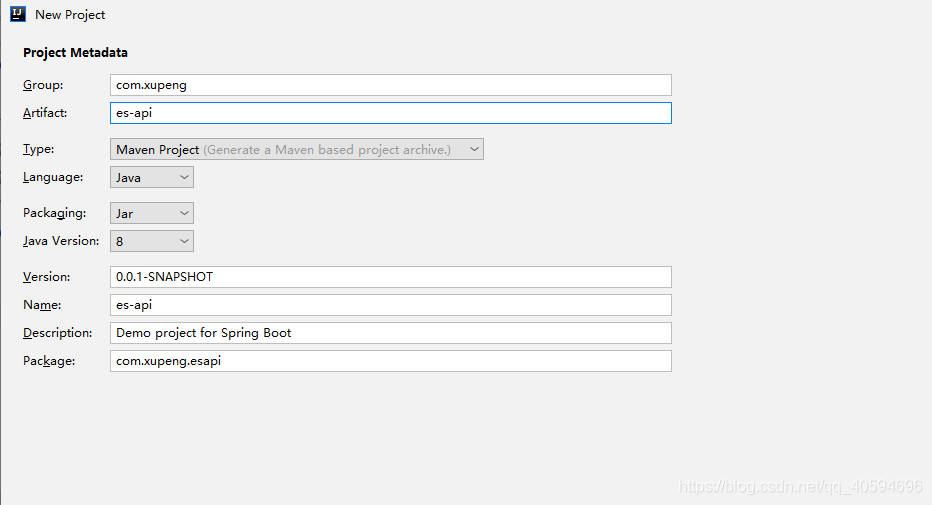
?
3.自定义es的版本,配置config
(1)配置版本
<dependency>都是springboot帮我们设置好的,我们只需要指定es的版本即可。
这一步很重要,一定要设置!?
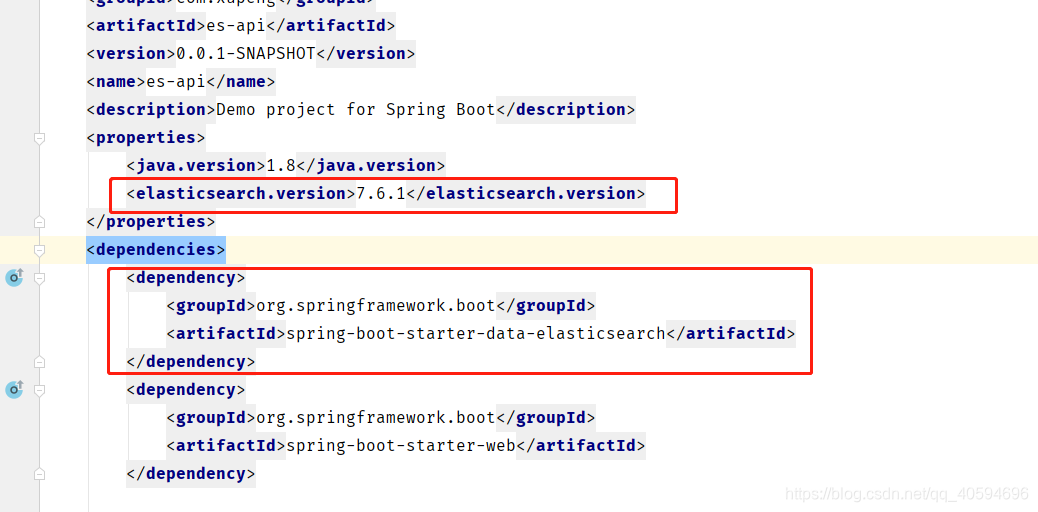
(2)配置config
ElasticSearchConfig:
package com.xupeng.esapi.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* [一句话描述该类的功能]
*
* @author : [xupeng]
* @version : [v1.0]
* @createTime : [2021/7/14 18:44]
*/
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost",9200,"http")));
return client;
}
}
4.关于索引的API操作
索引的增删查(所示代码均自测成功):
package com.xupeng.esapi;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class EsApiApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 创建索引
* @throws IOException
*/
@Test
void createIndex() throws IOException {
//1.创建索引请求
CreateIndexRequest request = new CreateIndexRequest("xupeng_index");
//2.客户端执行请求,请求后获得响应
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 获取索引
*/
@Test
void getIndex() throws IOException {
//1.获取索引请求
GetIndexRequest request = new GetIndexRequest("xupeng_index");
//2.获取索引
boolean isExist = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(isExist);
}
/**
* 删除索引
*/
@Test
void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("xupeng_index");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
}
5.关于文档的API操作
User:
package com.xupeng.esapi.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
/**
* [一句话描述该类的功能]
*
* @author : [xupeng]
* @version : [v1.0]
* @createTime : [2021/7/14 19:25]
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@Component
public class User {
private String name;
private int age;
}
EsApiDocTests:
package com.xupeng.esapi;
import com.alibaba.fastjson.JSON;
import com.xupeng.esapi.pojo.User;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchAllQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class EsApiDocTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 添加文档
*
* @throws IOException
*/
@Test
void createDoc() throws IOException {
User user = new User("徐鹏", 3);
//创建请求
IndexRequest request = new IndexRequest("xupeng_index");
//规则 PUT xupeng_index/_doc/1
//id设置为1
request.id("1");
//请求时长1秒
request.timeout(TimeValue.timeValueSeconds(1));
//数据放入请求
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求
IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
/**
* 批量新增数据
*/
@Test
void batchCreateDoc() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("xu1",2));
userList.add(new User("xu2",2));
userList.add(new User("xu3",2));
userList.add(new User("peng1",4));
userList.add(new User("peng2",4));
userList.add(new User("peng3",4));
for(int i = 0;i<userList.size();i++){
//批量更新和删除与之对应即可
bulkRequest.add(
new IndexRequest("xupeng_index")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON)
);
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
System.out.println(bulkResponse);
System.out.println(bulkResponse.hasFailures());
}
}
/**
* 判断文档是否存在 GET xupeng_index/_doc/1
*
* @throws IOException
*/
@Test
void existDoc() throws IOException {
GetRequest getRequest = new GetRequest("xupeng_index", "1");
boolean isExist = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(isExist);
}
/**
* 根据ID查询信息 GET xupeng_index/_doc/1
*
* @throws IOException
*/
@Test
void getDoc() throws IOException {
GetRequest getRequest = new GetRequest("xupeng_index", "1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());
System.out.println(getResponse);
}
/**
* 修改信息
*
* @throws IOException
*/
@Test
void updateDoc() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("xupeng_index", "1");
updateRequest.timeout("1s");
User user = new User("徐鹏2号",16);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);
System.out.println(updateResponse);
}
/**
* 删除信息
*
* @throws IOException
*/
@Test
void deleteDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("xupeng_index", "1");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest,RequestOptions.DEFAULT);
System.out.println(deleteRequest);
}
/**
* 自定义条件查询
* @throws IOException
*/
@Test
void searchDoc() throws IOException {
SearchRequest searchRequest = new SearchRequest("xupeng_index");
//查询条件,使用QueryBuilders工具实现
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//精确查询
//QueryBuilders.termQuery精确
//QueryBuilders.matchAllQuery()匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","xu1");
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
searchSourceBuilder.query(termQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//分页
searchSourceBuilder.from(2);
searchSourceBuilder.size(10);
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("<spna style='color:red'>");
highlightBuilder.postTags("</span>");
highlightBuilder.requireFieldMatch(false);//多个高亮显示
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
for(SearchHit searchHit:searchResponse.getHits()){
System.out.println(searchHit.getSourceAsMap());
}
}
}
五、打赏请求
如果本篇博客对您有所帮助,打赏一点呗,谢谢了呢~
