Hadoop1.x��Hadoop2.x������
Hadoop1.x��Ҫ��ɲ�����MapReduce �� HDFS,HDFS�������ݴ洢,Mapreduce��������ֲ�ʽ����,���Ҹ�����Դ�ĵ���;
������Hadoop2.x��,HDFS���ɸ������ݴ洢,
MapReduceֻ����ֲ�ʽ����,��Դ������Yarn����,�����ͼ�����MapReduce�ĸ�����
Hadoop����ģʽ
- ����ģʽ:��������,���������²��á�
- α�ֲ�ʽ:Ҳ�ǵ�������,���Ǿ߱�Hadoop��Ⱥ���й���,һ̨������ģ��һ���ֲ�ʽ�Ļ�����
- ��ȫ�ֲ�ʽ:��̨��������ɵķֲ�ʽ������
Hadoop��ȫ�ֲ�ʽ�
���������
һ�� ���л����
- ģ�������������
- ��¡��̨�����
- ��װXshell��Xftp
- ��װJDK
- ��װhadoop
�������÷ֲ�ʽ��Ⱥ
- ����SSH���ܵ�¼
- ��д��Ⱥ�ַ��ű�
- ��Ⱥ����
- ������Ⱥ
- д��Ⱥ��ͣ�ű�
ģ�������������
-
��װVMware �� CentOS(Ҳ������Ubantu,�����˶��ĸ�����Ϥ,����ʹ�õ���CentOS);
-
�½������Ӳ������
IP��ַ:192.168.10.100
��������:hadoop100
�ڴ�:1G
Ӳ��:50G���������ڴ��㹻,������Ϊ2G����4G�����ں�����Ҫͬʱ���������ڵ�,�ұ����ڴ治��,��ѡ��1G
Ӳ���������úú����������,����pingͨ�������ɡ� -
��װepel-release(������һ�������ֿ�)
yum install -y epel-release -
�رշ���ǽ
systemctl stop firewalld systemctl disable firewalld.service -
�����û���������
���ڰ�ȫ����,����ʹ���Լ����������û�,����root�û�;���뾡��������ס��useradd yss //�����û� passwd yss //�������� -
�����û�ʹ�����rootȨ��
vim /etc/sudoers��%wheel��һ��������:�û��� ALL=(ALL) NOPASSWD:ALL
-
ж��������Դ���JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps����: % rpm -qa:��ѯ����װ������ rpm ������ % grep -i:���Դ�Сд % xargs -n1:��ʾÿ��ֻ����һ������ % rpm -e �Cnodeps:ǿ��ж������ -
���������
reboot
��¡��̨�����(��hadoop102Ϊ��)
1.��VMware��ѡ�� ���������>��������>��¡ (��¡�����ʱҪ�ر�hadoop100 )
- �Ŀ�¡�������IP��ַ
�IJ���:vim /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static
IPADDR=192.168.10.102
GATEWAY=192.168.10.2
DNS1=192.168.10.2 - �Ŀ�¡���������������
vim /etc/hostname %hadoop102 - ����Linux��¡������ӳ��hosts�ļ�
vim /etc/hosts����:����IP ������ - ����hadoop102
reboot - ��windows������ӳ���ļ�hosts
·��:C:\Windows\System32\drivers\etc
����IJ��ɹ�,���Խ��ļ�����������,��Notepad++����Pycharm����IDEA��(��Ҫ�ü��±�),Ȼ����ȥ�滻�����ļ��Ϳ����ˡ�
��װXshell ��Xftp
Xshell :�ն�ģ����
Xftp:�ļ����乤��,������Windows��Linux�䴫���ļ�
��װJDK
- ʹ�� XShell �� Xftp �� windows �е� JDK ���� Linux �е� /opt /software ��
- ��ѹJDK��/opt/moduleĿ¼��
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ - ����JDK��������
����������������:sudo vim /etc/profile.d/my_env.sh

- ʹJDK��Ч
source /etc/profile - ����
���������� java ,���������ɡ�
��װHadoop
- ʹ�� XShell �� Xftp �� windows �е� hadoop ���� Linux �� /opt/software ��
- ��ѹJDK��/opt/moduleĿ¼��
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ - ��hadoop���ӵ���������
sudo vim /etc/profile.d/my_env.sh
- ʹ����Ч:
source /etc/profile - ����
hadoop version
����SSH���ܵ�¼
- ���ɹ�Կ��˽Կ
ssh-keygen -t rsa - ����Կ��������������
ssh-copy-id hadoop102 ssh-copy-id hadoop103 ssh-copy-id hadoop104
��д��Ⱥ�ַ��ű�xsync
scp ����ʵ�ַ������������֮������ݿ�����
rsync ��Ҫ���ڱ��ݺ;������ٶȿ졢���⸴����ͬ���ݺ�֧�ַ������ӵ��ŵ㡣
- ��/home/atguigu/bin Ŀ¼�´��� xsync �ļ�
mkdir bin cd bin vim xsync
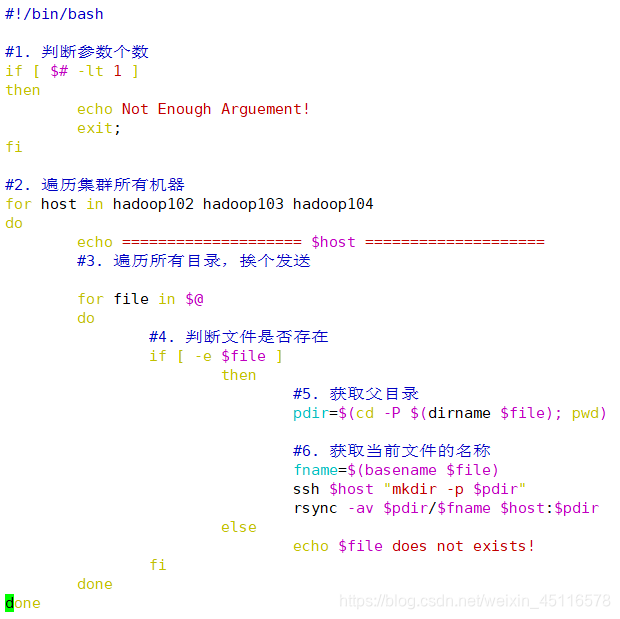
-
�Ľű�Ȩ��
chmod 777 xsync -
���ű����Ƶ�/bin ��,�Ա�ȫ�ֵ���
sudo cp xsync /bin/ -
ͬ��������������(root ������)
sudo ./bin/xsync/etc/profile.d/my_env.sh source /etc/profile -
��JDK��hadoop�ַ���hadoop103��hadoop104
xsync /opt/module
��Ⱥ����
Ϊ�˷�ֹ���������,��NameNode��SecondaryNameNode��ResourceManger��װ�ڲ�ͬ����,������дһ���ű�ͬʱ����hdfs��yarn

�����ļ�core-site.xml��hdfs-site.xml��yarn-site.xml��mapred-site.xml��workers
(hadoop3.x:workers hadoop2.x:slaves)
***!!! �����ļ�Ҫ��ϸ!!!***
- core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- ָ�� NameNode �ĵ�ַ --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- ָ�� hadoop ���ݵĴ洢Ŀ¼ --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- ���� HDFS ��ҳ��¼ʹ�õľ�̬�û�Ϊ atguigu --> <property> <name>hadoop.http.staticuser.user</name> <value>atguigu</value> </property> </configuration> - hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nn web �˷��ʵ�ַ--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web �˷��ʵ�ַ--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration> - yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- ָ�� MapReduce ���������� Yarn �� --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- ��ʷ�������˵�ַ --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <!-- ��ʷ������ web �˵�ַ --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property> </configuration> - mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- ָ�� MR �� shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- ָ�� ResourceManager �ĵ�ַ--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- ���������ļ̳� --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP RED_HOME</value> </property> <!-- ������־�ۼ����� --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- ������־�ۼ���������ַ --> <property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value> </property> <!-- ������־����ʱ��Ϊ 7 �� --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration> - workers
hadoop102 hadoop103 hadoop104 - �ڼ�Ⱥ�Ϸַ����úõ������ļ�
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
������Ⱥ
��һ������:��ʽ��NameNode
hdfs namenode -format
����HDFS
sbin/start-dfs.sh
web��:http://hadoop102:9870
����YARN
sbin/start-yarn.sh
web��:http://hadoop103:8088
��֤�����ɹ�
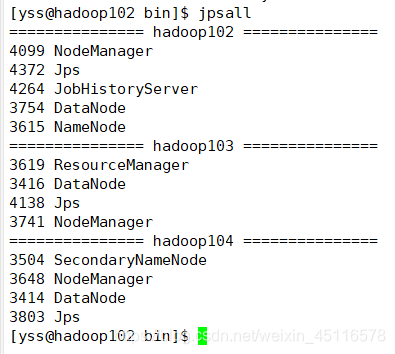
jps
�����ʾNameNode��DataNode��SencondaryNameNode��NodeManger��ResourceManger��������,��Ϊ�ɹ���
�����Ⱥ���ֱ���,����ͣ�ü�Ⱥ,ɾ��DataNode�е���Ϣ(������hdfs-site.xml���ҵ�Ŀ¼,Ĭ��Ϊ\tmp),Ȼ���ʽ��,����������Ⱥ
д��Ⱥ��ͣ�ű�
��д��ͣ�ű�:
cd bin/
vim myhadoop.sh

chmod 777 myhadoop.sh
��дjps�鿴�ű�
cd bin/
vim jpsall

chomd 777 jpsall
��Ⱥ�ַ�
xsync bin/
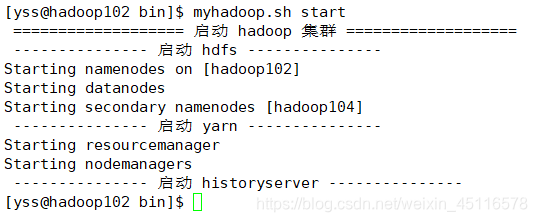
������Ⱥ:myhadoop.sh start
�鿴jps:jpsall
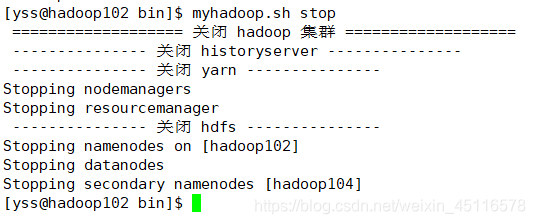
ͣ�ü�Ⱥ:myhadoop.sh stop