1.�ֲ�ʽ��������ķ�չ
- (1) ��һ��:MapReduce
- Ӧ��:��ͳ��������
- ȱ��:���ڴ��̴洢,��д���ܲ�,����Բ�
- (2) �ڶ���:Tez��Storm
- Ӧ��:������
- ȱ��:Tez����MR���˿����Ȳ��,����������,�����ǻ��ڴ���,��д����û�и���
- StormӦ����ʵʱ����
- (3) ������:Spark
- ����+ʵʱ:lambda�ܹ�
- Ŀǰ�ڹ�������Ҫʹ�õ�����������
- (4) ���Ĵ�:Flink
- ���м���ȫ������ͨ��ʵʱ��ʵ�ֵ�:Kappa�ܹ�
- Ŀǰ�ڹ�������Ҫʹ��ʵʱ��������
2.Spark���
- (1) ����:Spark��һ�����ٵġ�ͳһ���ķֲ�ʽ������������ͻ���ѧϰ�㷨��
- (2) ����:
- �� ʵ����������������:SparkCore
- ����MapReduce
- �� ʵ�ֽ���ʽ���ݷ���:SparkSQL
- ����Hiveʵ��SQL�ֲ�ʽ����
- �� ʵ��ʵʱ���ݴ���:SparkStreaming / StructStreaming
- ����Storm/Flink
- �� ʵ�ֻ���ѧϰ�Ŀ���:Spark ML lib
- ����Python�л���ѧϰ��
- �� ͼ����:SparkGraphx
- �� ʵ����������������:SparkCore
- (3) �ص�:
- �� ��:���д����ͼ������ʹ���ڴ���ʵ��
- �� ͨ����ǿ:����ȫ��,�����ڴ���������ݷ������㳡��
- �� ����ʹ��:�ӿڷḻ(Java/Python/SQL/DSL/R/Scala)
- �� �洦����:����Դ�ӿڷḻ,�������ڸ�����Դ��ƽ̨��
- (4) ���ʽ���
- ��SparkCore:���ڴ������������������,������MR
- ��SparkSQL
- 1)����:����SQLʵ����������������,������Hive
- 2)ʵʱ:StructStreaming,ʹ��SQLʵ��ʵʱ���ݼ���
- ��Streaming:����SparkCoreʵ��ʵʱ���ݼ���
- ��MLlib:����ѧϰ�㷨��
- ��Graphx:ͼ����,���ݽṹ�е�ͼ�ļ���
- (5) ʹ�ó���
- ������SparkCore��SparkSQL�������߷�������
- ������SparkStreming��StructStremingʵʱ��������(Ŀǰ������ʵʱ��Ҫ��Flink����Spark)
3.Spark��MapReduce�Ա�
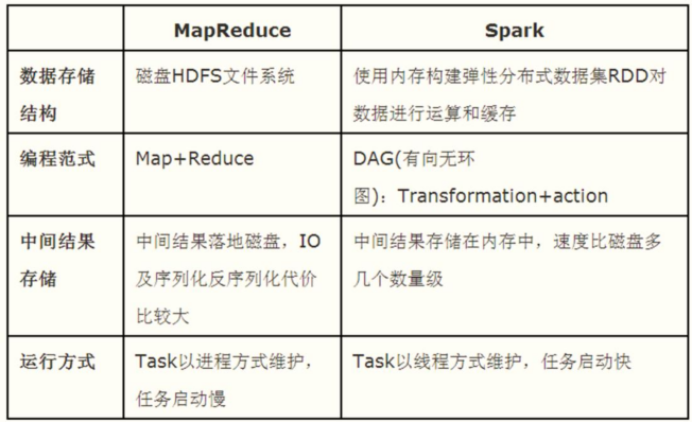
- ����:SparkΪʲô��MR��?
- ��Spark����ʹ���ڴ�ʽ����(RDD);
- ��Sparkʹ��������ͼ(DAG)ִ�мƻ�,����Ը�;
- ��Spark�е�Task���̼߳���:��ʡ���̵Ŀ���,ֻҪ����һ��,ֱ���������
4.Spark�Ļ������
- (1) �����������
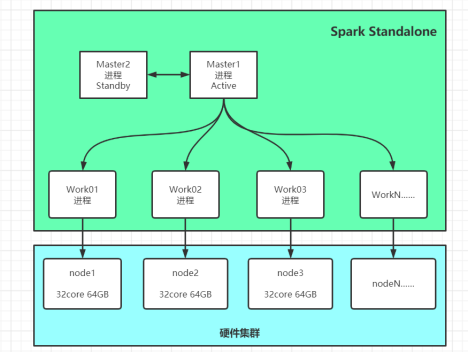
�ֲ�ʽ���Ӽܹ�:- �����ڵ�:master,�����ڵ�
- 1)�����ӽڵ�
- 2)���ܿͻ�������
- 3)������Դ
- �ڴӽڵ�:worker,����ڵ�
- 1)������Դ��Execuor
- 2)����Executor����,ʵ��Task������
- �����ڵ�:master,�����ڵ�
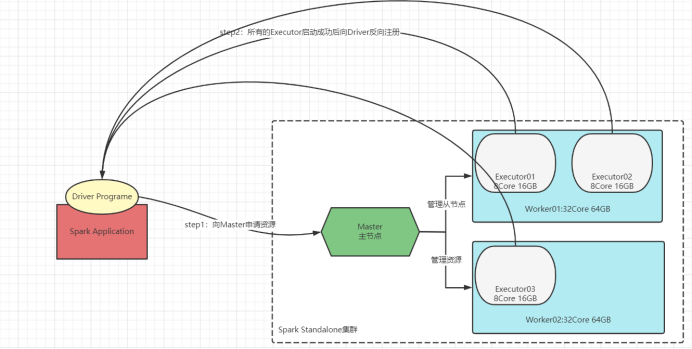
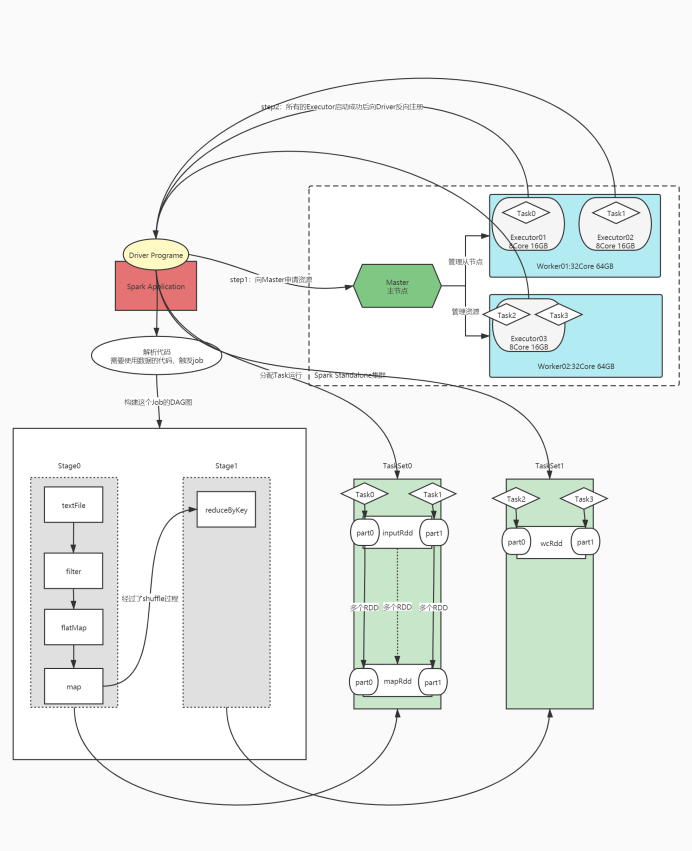
- (2) �������:�κ�һ�����������ֽ��̹���:Driver��Executor
- �� Driver����(��ʼ�����̻���Task��������)
- 1)�����ڵ�����Executor��Դ,�����ڵ��ڴӽڵ��ϸ�����������������Ӧ��Executor
- 2)����������:�������е���ת��ΪTask
- �������RDD�е����ݵ�ʹ��:����һ��Job,����Task����
- 3)��Task�����Executorȥ����
- 4)���ÿ��Executor���е�Task״̬
- �� Executor����(ִ�н���)
- 1)������Worker��,ʹ��Worker�������Դ�ȴ�����Task
- 2)����Executor�����ɹ��Ժ����Driver����ע��
- 3)Executor�յ�����Task����,����Task
- �� Driver����(��ʼ�����̻���Task��������)
- (3) ����ɲ���֮��Ĺ�ϵ:
- ��Master�����������Worker��Դ
- ��Driver����Master��������Executor
- ��Worker�ϸ�������Executor����
- ��Driver������������䡢�������Task�߳���Executor������
5.Spark�е�task����ô�õ���?
- step1:�ȶ�ȡ����:�����ݱ��һ��RDD���ֲ�ʽ�ļ��ϡ�����
- step2:ת����������:��RDD���ϵ���ת���������д���,�õ��µ�RDD
- step3:����������
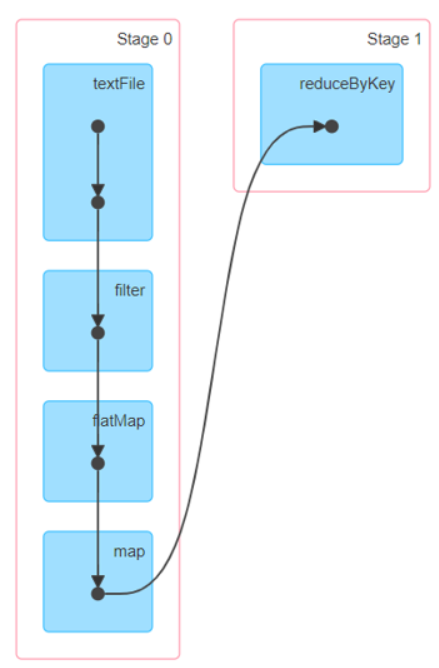
- �� Job:����job,���õ�RDD�е����ݵ�ʱ��,����RDD����Դת����ϵ,����DAG
- �� Stage:����Job��ʹ��RDD��������ϵ,ͨ�������㷨��һ��job�е�����ϵ,����Stage,�õ�DAGͼ
- 1)Stage�Ļ���:�����Ƿ����shuffle,�������shuffle,�ͻ���һ���µ�stage
- 2)ִ��ÿ��Stage:��Stage�����С�Ŀ�ʼ����ִ��
- ��ÿ��Stageת��Ϊһ��Task����:Task������Task�ĸ�����RDD�ķ������ݾ���
- ����:ΪʲôҪ����shuffle����Stage?
��: ͬһ��Stage�е�����Task�������ڴ��в������� - �� Task:ÿ��Stage���Ӧһ��������Task,Task������Stage��RDD�ķ�����������
6.Sparkcore����
- (1) Sparkcore����ģ��
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Todo: SparkCoreģ��
* @auther: Cjp
* @date: 2021/7/12 16:51
*/
object SparkCoreSimpleMode {
def main(args: Array[String]): Unit = {
//todo:1.����SparkContext����
val sc:SparkContext = {
//����SparkConf���ù�������,������Hadoop�е�configuration����
val conf = new SparkConf()
.setMaster("")//ָ������ģʽ
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))//ָ�����г��������
.set("key","value")//ָ�����������
//����SparkContext�Ķ���
SparkContext.getOrCreate(conf)
}
//������־����
sc.setLogLevel("WARN")
//todo:2.ʵ�����ݵ�ת������
//step1:��ȡ����
//step2:��������
//step3:������
//todo:3.�ͷ�SparkContext����
sc.stop()
}
}
- (2)Wordcount����
���䰸��Wordcount����Spark��(Sparkcore/SparkDSL/SparkSQL)https://blog.csdn.net/m0_56919489/article/details/118823291 - (3) jar���ύ����
ע:��IDEA�Ͽ�������ֻ��Ϊ�˲��Դ�����,��ʽ���������г�����Ҫ����ŵ���Ⱥ�Ͻ��в��Ժ�ʹ�õ�- �� ��������ѡ��:
- �C master:ָ��spark�������л���
- �C local:����
- �C spark://node1:7077:Standalone��Ⱥ
- �C yarn:YARN��Ⱥ
- �C deploy-mode:������Driver���������ڱ��ػ���ijһ̨Worker�ڵ���
- �C name:ָ�����������
- �C class:ָ�������ĸ���
- �C jars:ָ��������jar��
- �C conf:ָ������
- �C master:ָ��spark�������л���
- �� ��Դѡ��:
- driverѡ��:
- �C dirver-memory:�����Driver���ڴ�,Ĭ�Ϸ���1GB
- �C driver-cores:�����Driver���е�CPU����,Ĭ�Ϸ���1��
- �C supervise:�����Զ�����
- executorѡ��:
- �C executor-memory:�����ÿ��Executor���ڴ���,Ĭ��Ϊ1G,���м�Ⱥģʽ��ͨ�õ�ѡ��
- �C executor-cores:�����ÿ��Executor�ĺ�����,YARN���Ϻ�Standalone��Ⱥͨ�õ�ѡ��
- YARN:Ĭ��ÿ��Executor����1��core
- �C num-executors NUM:YARNģʽ������ָ��Executor�ĸ���,Ĭ������2��
- Standalone:Ĭ�Ϸ������п��õĺ�����ÿ��Executor
- �C total-executor-cores NUM:Standaloneģʽ������ָ������Executor���õ���CPU����(�ܺ��� / ÿ��Executor���� = Executor�ĸ���)
- driverѡ��:
- �� ʾ��
- �� ��������ѡ��:
//(1) �����ύ
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--class
cn.test.sparkcore.SparkCoreWordCount \
~/spark-WordCount.jar \
/example/WordCount.data \
/output/WordCount
//(2) Standalone��Ⱥ�ύ
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1:7077 \
--class cn.test.sparkcore.SparkCoreWordCount \
hdfs://node1:8020/spark/apps/spark-WordCount.jar \
/example/WordCount.data \
/output/WordCount
//(3) ָ����Դ�ύ
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1:7077 \
--class cn.test.sparkcore.SparkCoreWordCount \
--driver-memory 512M \
--executor-memory 512M \
--executor-cores 1 \
--total-executor-cores 2 \
hdfs://node1:8020/spark/apps/spark-WordCount.jar \
/example/WordCount.data \
/output/WordCount
//(4) Spark on YARN(clientģʽ)
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1:7077 \
--deploy-mode client \
--class cn.test.sparkcore.SparkCoreWordCount \
hdfs://node1:8020/spark/apps/spark-WordCount.jar \
/example/WordCount.data \
/output/WordCount
//(5) Spark on YARN(clusterģʽ)
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1:7077 \
--deploy-mode cluster \
--class bigdata.itcast.cn.spark.core.wordcount.SparkCoreWordCount \
hdfs://node1:8020/spark/apps/spark-wc.jar \
/example/wc.data \
/output/wc
7.Deploymode
- (1) ����:������driver�������е�λ��
- (2) ѡ��
- �� client:Ĭ��ѡ��,driver���������ڿͻ�����
- ����:���һֱʹ��clientģʽ,����Spark�����driver��������ͬһ̨����,���»����ĸ��رȽϸ�,Driver�����ʾͱȽϸ�,���ܱȽϲ�
- �� cluster:driver����������Worker�ڵ���
- �� client:Ĭ��ѡ��,driver���������ڿͻ�����
- (3) Spark on YARN��clientģʽ��clusterģʽ����
- �� client:driver��APPMaster�ǹ����
- APPMaster:������Դ,����Executor,������NodeManager��
- Driver:��������Executor������Jobִ��,���������䡢���Task,������Client��
- Executors:����JVM����,����ִ��Task����ͻ�������
- �� cluster:driver��APPMaster�ϲ���,������ͳһ�Ľ�����ʵ��
- Driver Program(AppMaster):�Ƚ�����Դ����,�ֽ���Job����
- Executors:����JVM����,����ִ��Task����ͻ�������
- ����:ΪʲôҪ��YARN������SparkCore����?
��:Ϊ�˱���ͬһ��������Դ�ɶ�����Դ����ƽ̨����,���¹�������,һ���ڹ�����ѡ��ʹ��һ�ֹ�������Դ����ƽ̨��ʵ��,���������ƽ̨����YARN,������һ�㽫���зֲ�ʽ�������ȫ���ύ��YARN����ʵ������
- �� client:driver��APPMaster�ǹ����
8.Spark���еĻ�������
-
step1:Driver��Executor������
- (1) ������������Driver,Ĭ�������ͻ�����̨������
- (2) Driver��Master������Դ
- (3) �����ύ������,Master����Worker������Executor����
- (4) ����Executor����Driver����ע��
-
step2:Main������ִ��
- (1)Driver��ʼ����Main������ʼ�Ĵ���
- (2)�����г���RDD���ݵ�ʹ��,�ͻᴥ��job
- (3)job������,ͨ�������㷨��RDD��ת������DAGͼ
- �ٻ����㷨:����
- ��ÿ����һ��Shuffle�ͻ���һ��Stage
-
step3:Task�Ľ�������
- (1)����DAG�ӱ����С��Stage��ʼ,ת��ΪTask,
- (2)ÿһ��Stage��ת��Ϊһ��TaskSet����,TaskSet�����л��ж��Task
- (3)Driver��TaskSet�е�Task������ȵ�Executor��ִ��
9.RDD(Resilient Distributed Datasets)
- (1) ����:
-
�� ����:���Էֲ�ʽ���ݼ�,���и��ݴ�����ʵ�����ݷֲ�ʽ�洢�����ݼ���,�䱾�ʾ������ݼ���,ӵ�ж�����������ݼ���
-
�� ����:�洢��������в���������
- �����ȡ���κ����ݶ�����붨��ĵ�һ��RDD1��
- �����ݿ�ʼת������ʱ,RDDҲ����֮ת���õ�RDDN
-
�� �ص�
- ������RDD֮���Ѫ����ϵ,ÿ��RDD�����¼�Լ�����Դ
- �ŵ�:
- a.�ֲ�ʽ:RDD���ж��������ʵ�ֲַ�ʽ�洢,��ʵ�ֲ���ʽ�����ݴ���
- b.�ݴ�����ǿ:ͨ���� RDD ��ת�Ʋ���������������ͼ��ʵ�ֵ�,RDD֮�����Ѫ����ϵ,��RDD����(������,խ����)
-
������(Wide Dependency,Ҳ��shuffle����):�� RDD��һ���������ݸ����� RDD�Ķ������,�漰shuffle
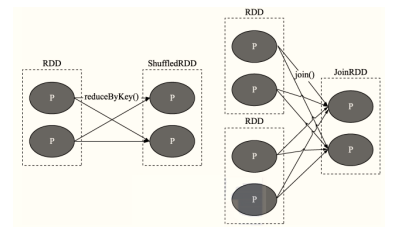
-
խ����(Narrow Dependency):�� RDD��һ����������ֻ������ RDD��һ������
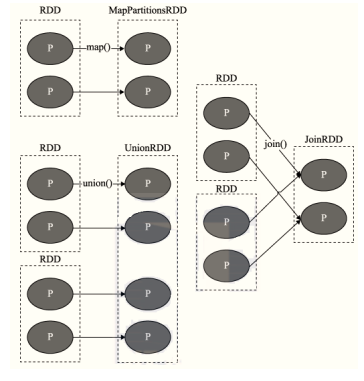
-
-
������:ΪʲôҪ��ƿ�խ����?
- 1)�����ܵĽǶ�������:
��Щ��������Ҫ����shuffle���ÿ�����,�������Ҫ����shuffle�������ʹ��խ���� - 2)������Ѫ���ָ��Ƕ���˵
���������:��RDDij�����������ݶ�ʧ,�������¼���������RDD�����з���;
���խ����:��RDDij�����������ݶ�ʧ,ֻ��Ҫ���㸸RDD��Ӧ���������ݼ���
- 1)�����ܵĽǶ�������:
-
�� RDD������,��ô��֤��ȫ��?
��:Ѫ������:ͨ��������ϵ���ָ�RDD������ -
�� RDD���ݴ�����
- 1��persist����
- ����:��RDD������Executor���ڴ���ߴ�����,����RDD���ظ�����,�������ܱȽϲ������,���˻����Ժ�,��һ�ι����Ժ�,��һ�ο���ֱ�Ӵӻ����ж�ȡ
- Ӧ�ó���:
- RDD�ᱻʹ�ö�Ρ�����2�Ρ�
- ���RDD�Ǿ����dz����ӵĹ��̵õ���,ʹ����2��
- ����:
- cache/persist:���û���
- unpersist:�ͷŻ���
- ���漶��
- Ĭ�ϼ���:MEMORY_ONLY
- ���ü���:MEMORY_AND_DISK_2��
MEMORY_AND_DISK_SER_2
- 1��persist����
-
- ʾ��:
//ֻ�����ڴ�����,2��ʾ��������
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
//ֻ�������ڴ���,2��ʾ��������,ser��ʾ���л��Ժ��ٻ���
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
//���Ȼ����ڴ�,����ڴ治��,�������
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
//�����ڴ�
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
//�������ʹ�ý���,��ȷ������Ҫ�������,�����ֶ��ͷ��������
wcRdd.unpersist()
- 2��checkpoint����
- ����:��RDD�����ݳ־û��洢��HDFS��,�Ժ��ȡRDD������,����ֱ�Ӵ�HDFS�Ͻ��ж�ȡ,����Ҫ���¹���,���ݸ��Ӱ�ȫ
- Ӧ��:�dz���Ҫ��RDD�����������dz���,�ڴ�ռ�Ƚ�С
- ����:
- ���ü���Ŀ¼:sc.setCheckpointDir
- ���ü���:rdd.checkpoint
//���ü���:RDD���ݴ洢��λ��
sc.setCheckpointDir("datas/sparkcore/chk")
//��RDD�����ݴ洢��HDFS��
wcRdd.checkpoint()
-
3�� persist��checkpoint������
- a.��������
- a)persist:�����Զ�ɾ��:Task����,����unpersist
- b)checkpoint:ֻ���ֶ�ɾ��
- b.�洢����
- a)persist:������RDD�������ڴ���,������RDD����������(Ѫ����ϵ������)
- b)checkpoint:ֻ�洢��RDD������
- a.��������
-
(2) RDD���������
- ��A list of partitions
ÿ��RDD�ɶ��������� - ��A function for computing each split
��RDD�Ĵ���ת�������϶���RDDÿ��������ת������(RDD��immutable,���ɱ�,����RDD��ת�����ص���һ���µ�RDD) - ��A list of dependencies on other RDDs
ÿ��RDD�����¼�븸RDD��������ϵ - ��Optionally, a Partitioner for key-value RDDs
��ѡ:���ڶ�Ԫ��KV�ṹ��RDD,�ھ���Shuffle��ʱ��,�����Զ���ָ��������
Spark�Դ��ķ�����:Hash��������Χ���� - ��Optionally, a list of preferred locations to compute each split on
��ѡ:��Task�������ʱ,���Լ�������·����
- ��A list of partitions
-
(3) RDD�Ĵ���
- �ٲ��л�һ���Ѿ����ڵļ���
//�½�һ��1-10�ļ���
val seq: immutable.Seq[Int] = 1.to(10)
//��1-10�ļ��ϲ��л���Ϊһ��RDD
val rdd1: RDD[Int] = sc.parallelize(seq)
sc.parallize / sc.makeRDD:��������������·����:���л�һ�����ϱ��һ��RDD
- �ڶ�ȡ�ⲿ���ݴ���RDD
//��ȡ�ⲿ�ļ�ϵͳ
val rdd2: RDD[String] = sc.textFile("datas/wordcount")
//����Hadoop������һ��������,��������Ľ������RDD
val rdd3 = sc.newAPIHadoopRDD("����Hadoop���ĸ�������","����Key����","����Value����")
sc.textFile/sc.wholeTextFile/sc.newAPIHadoopRDD:��ȡ�ⲿ����Դ
- (4) RDD����
RDD�ķ�������������Task�ĸ���,�����˲��ж�- �� ָ����������:�ڹ���RDDʱ,���ݷ�����������
//���л�����ָ����������
val seq: Seq[Int] = 1.to(10)
val seqRdd: RDD[Int] = sc.parallelize(seq,numSlices = 3)
//��ȡ�ⲿϵͳָ����������
val inputRdd =
sc.textFile("datas/wordcount",minPartitions = 3)
-
�� �ƶ�����ԭ��:
RDD�ķ�������һ��ΪExecutor��CPU������2 ~ 3��
����:10��Executor,ÿ��Executor����4coreCPU,RDD�ķ����������Χ:80 ~ 120���� -
�� ���������鿴:
//��ȡ��ǰRDD�ķ�������
val partitions = seqRdd.getNumPartitions
//��ȡ��ǰ���ݶ�Ӧ�ķ������
TaskContext.getPartitionId()
- �ܳ����ķ��������Ĺ���
- 1��Ĭ��:�߳���,����ײ��ȡ���Ƿֲ�ʽϵͳ
�Զ���:ָ���������� - 2���ֲ�ʽϵͳ:ʵ��1:1�ķ�����ϵ
- a.��HDFS�ļ�:�ļ���һ������Զ���ӦRDD��һ������
- b.��Hbase��:����һ��region�Զ���ӦRDD��һ������
������:һ���ȡ�Ķ��Ƿֲ�ʽϵͳ,һ�㶼��Ĭ�ϵļ���
- 3������:���RDD��ͨ������һ��RDD�õ���,���������Ƕ���?
��:��RDD�����������ø�RDD�ķ������� - 4��С�ļ�����,������̫����ô��?
��:�ϲ���ȡ:wholeTextFile
ʾ��:
- 1��Ĭ��:�߳���,����ײ��ȡ���Ƿֲ�ʽϵͳ
//С�ļ���ȡ
//��100������,�ļ���ÿһ��������Ϊһ��Ԫ��
val rdd3: RDD[String] = sc.textFile("datas/ratings100")
//ÿ���ļ���Ϊһ��KV��,�洢��RDD��
val rdd4: RDD[(String, String)] =
sc.wholeTextFiles("datas/ratings100")
rdd4.take(1).foreach(tuple =>
println(tuple._1+"---------"+tuple._2))
- (5) RDD����(��RDD����)
-
�� ת������(Transformation)
- 1������:ʵ��RDD��ת������
- 2���ص�:��lazyģʽ��,����ֵ��һ���µ�RDD,�������job�ʹ���Task������
- 3����������:
- Map:������Ԫ��(k��v��ӳ��)list,ʵ�ֶ�RDD��ÿ��Ԫ�صĴ���,�������Ľ�������µ�RDD�н��з���
- Flatmap:��ƽ��list,ʵ�ֶ�RDD�е�ÿ��Ԫ�ؽ��б�ƽ������,��RDD�е�ÿ�����ϵ�Ԫ�غϲ���һ��RDD�з���
- Filter:����,ʵ�ֶ�RDD��Ԫ�صĹ���,����������Ԫ�ػ����һ���µ�RDD�з���
- Reducebykey:����ۺ�
- Sortby��sortbykey:����,����shuffle��ת������,ʹ��RangePartition,�����ݲ���ʵ�ַ����������,���ȡ����,����Jobȥ��ȡ����

-
�� ��������(Action)
- 1������:ʵ��RDD���ݵĶ�ȡ����
- 2���ص�:����job������,����Task,ʵ�������ϵ�RDD�����ݶ�ȡ��ת��,����ֵ��ΪRDD����,Ϊ��ͨ���ͻ���Ϊ��
- 3����������:
- foreach:��ӡ���,û�з���ֵ
- collect:��RDDÿ�����������ݷ���һ��������,��������
- reduce:�ۺϺ���,���ؾۺϺ�Ľ��
- fold:�ۺϺ���,���ؾۺϺ�Ľ��
- count:ͳ��Ԫ�صĸ�������
- Take:ȡRDD�����е�����(ͨ�������̴߳�RDD��ÿ��������ȡ��Ҫ������)����һ��������,����Driver��,����ֵ������
- saveAsTextFile:û�з���ֵ,�������ݵ��ⲿ�ļ�ϵͳ

-
10.RDD��������
- (1) ��������
map��flatMap��filter��take��top��foreach - (2) ������������
- �ٺ���:mapPartitions,foreachPartition
- �ڹ���:��RDD��ÿ���������ò����������д���
- �۳���:���ڷ�������Դ����
- (3) �ط�������
- �ٺ���:repartition��coalesce
- �ڹ���:����RDD�ķ�������,����һ���µ�RDD
- �۹�ϵ
���߶������ı�RDD��partition������,repartition�ĵײ���õ���coalesce���� - ������
- repartition:���ڵ����������,���뾭��shuffle
- coalesce(��������,�Ƿ�shuffle:Ĭ��false,��shuffle):һ�����ڵ�С��������,���Ϊtrue,�͵���repartitionЧ��
- (4) �ۺϺ���
- �ٺ���
- reduce:�����ھۺϺͷ�����ۺ���һ��,û�г�ʼֵ
- fold:�����ھۺϺͷ�����ۺ���һ��,�г�ʼֵ
- aggregate:�����ھۺϺͷ�����ۺ��������Զ���,�г�ʼֵ
- �ڹ���:ʵ�ֲַ�ʽ�ľۺ�
- �ٺ���
- (5) PairRDD����
- ������:xxxByKey,ֻ�ж�Ԫ�����͵�RDD���ܵ��õĺ���
����: - �� �ۺϺ���:
- reduceByKey:�÷���reduce��һ�µ�,����Key����,��Value����reduce�ۺ�
����Key���� + reduce�ۺ� - aggregateByKey:�÷���aggregate��һ�µ�,����Key����,��Value����aggregate�ۺ�
����Key���� + aggregate�ۺ�
ע:reduceByKey��foldByKey,aggreageByKey�ײ�ʹ�õĶ���CombinerByKey:�ȷ����ھۺ�,�ٷ�����ۺ�
- reduceByKey:�÷���reduce��һ�µ�,����Key����,��Value����reduce�ۺ�
- �� ���麯��:
- groupByKey:����key�����
- ע��:����reduceByKey�Ͳ�Ҫʹ��groupByKey+reduce
- reduceByKey:����ۺ�,��ÿ�������ڲ�,�ȷ���ۺ�,�ٷ��������ۺ�
- groupByKey + reduce:���������ݷŵ�һ����������
- reduceByKey������Ҫ����groupByKey
- �� ������:
- sortByKey:����Keyʵ������
- ������:xxxByKey,ֻ�ж�Ԫ�����͵�RDD���ܵ��õĺ���
- (6) ��������:Join
rdd1:KV
rdd2:KW
rdd1.join(rdd2) = RDD:[K,(V,W)]
11.Spark��д�ⲿ����
- (1) ԭʼ���ݶ�ȡ
HDFS��Hbase - (2) ���ݴ���
SparkCore - (3) ����洢
HDFS��Hbase��MySQL - (4) SparkCore������Դ�ӿ�
- ��parallelize / makeRDD:��һ��Scala�еļ���ת��Ϊһ��RDD����
- ��textFile / wholeTextFiles:��ȡ�ⲿ�ļ�ϵͳ������ת��Ϊһ��RDD����
- ��newAPIHadoopRDD / newAPIHadoopFile:����Hadoop��InputFormat����ȡ����ת��Ϊһ��RDD����
12.SparkCore�еĹ�������
- (1) ��������
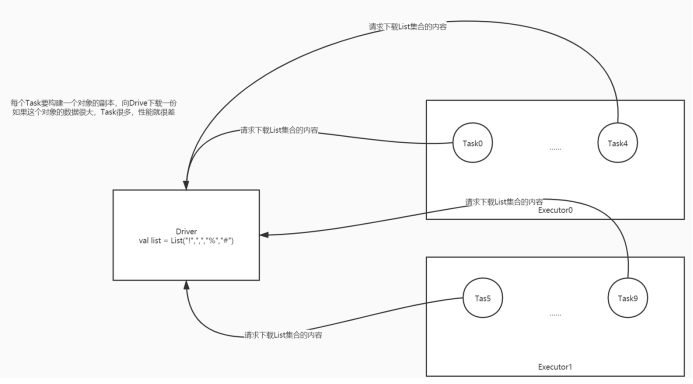
��Ĭ�������,��Spark�ڼ�Ⱥ�Ķ����ͬ�ڵ�Ķ�������ϲ�������һ������ʱ,����Ѻ������漰����ÿ������,��ÿ�������϶�����һ������������,��ʱ����Ҫ�ڶ������֮�乲������,����������(Task)��������ƽڵ�(Driver Program)֮�乲������ - (2) �㲥����(Broadcast Variables)
- �ٹ���:
- ���Խ�Driver�е�һ������ͨ���㲥����ʽ����Executor,�������������Executor��
- ���������������е�IO,�������
- ������Wordcount,���˷���,ֻ��������,ͳ��ÿ�����ʳ��ֵĴ���
-
a.����:ֱ�Ӷ���һ�����ŵļ���,��ÿ��Task��������
-
b.�㲥����
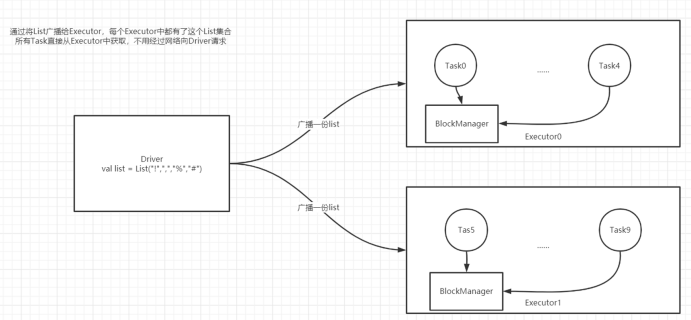
-
- �ٹ���:
����:
//���ŵļ���
val list = List("!",",","%","#")
//ʵ�ֹ㲥:����һ���㲥����
val broad = sc.broadcast(list)
val rsRdd: RDD[(String, Int)] = inputRdd
//���˿���
.filter(line => line != null && line.trim.length > 0)
//ȡ��ÿ������
.flatMap(line => line.trim.split(" "))
//�����Ź��˵�
.filter(word => {
//�Ӹ��ԵĹ㲥�����н����ݻ�ȡ����
val value = broad.value
!value.contains(word) && word.trim.length >0
})
//ת��Ϊ��Ԫ��
.map(word => (word,1))
//����ۺ�
.reduceByKey((temp,item) => temp+item)
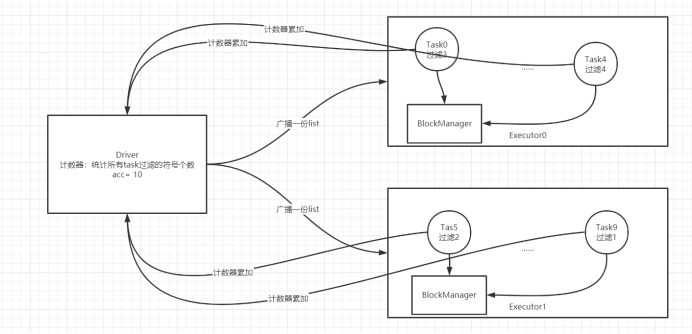
- (3) �ۼ���(Accumulators)
- �ٹ���:
- ʵ�ֲַ�ʽ����:һ�����ڽ������������־����
- a.ÿ�������ڲ�����
- b.�ٽ�ÿ�������Ľ�������ۼ�
- ������Wordcount,���˷���,ֻ��������,ͳ��ÿ�����ʳ��ֵĴ���,�Լ�ͳ�Ʒ��ŵĸ���
- ʵ�ֲַ�ʽ����:һ�����ڽ������������־����
- �ٹ���:
����:
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName WordCountShareVariable
* @Description TODO ʵ���Զ��忪��Wordcount����,ʹ�ù㲥����,���˵���,��ʹ���ۼ���ͳ�Ʒ��ŵĸ���
* @Create By Frank
*/
object WordCountShareVariable {
def main(args: Array[String]): Unit = {
/**
* step1:��ʼ��Driver����,SparkContext
*/
//����һ�����ù�������,��������ǰѧ��Configuration����
val conf = new SparkConf()
//�Ե�ǰ��������Ϊ���������
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
//���ñ���ģʽ����
.setMaster("local[2]")
// .set("fs.defaultFS","hdfs://node1:8020")
//����SparkContext����
val sc = new SparkContext(conf)
//������־����
sc.setLogLevel("WARN")
/**
* step2:��ȡ��ת��������
*/
//todo:1-��ȡ����
val inputRdd = sc.textFile("datas/filter/datas.input")
// println(s"count = ${inputRdd.count()}")
//���ŵļ���
val list = List("!",",","%","#")
//ʵ�ֹ㲥:����һ���㲥����
val broad = sc.broadcast(list)
//����һ���ۼ���,ͳ�����з��ŵĸ���
val acccnt = sc.longAccumulator("acccnt")
//todo:2-��������
val rsRdd: RDD[(String, Int)] = inputRdd
//���˿���
.filter(line => line != null && line.trim.length > 0)
//ȡ��ÿ������
.flatMap(line => line.trim.split(" "))
//�����Ź��˵�
.filter(word => {
//�Ӹ��ԵĹ㲥�����н����ݻ�ȡ����
val value = broad.value
//���ų���һ��,���ۼӼ���һ��
if(value.contains(word)) acccnt.add(1L)
!value.contains(word) && word.trim.length >0
})
//ת��Ϊ��Ԫ��
.map(word => (word,1))
//����ۺ�
.reduceByKey((temp,item) => temp+item)
//todo:3-������
rsRdd.foreach(println)
println(s"���ŵĸ���:${acccnt.value}")
/**
* step3:�ͷ���Դ
*/
Thread.sleep(10000000L)
sc.stop()
}
}
13.Spark shuffle
- (1) �Ա�MapReduce��shuffle
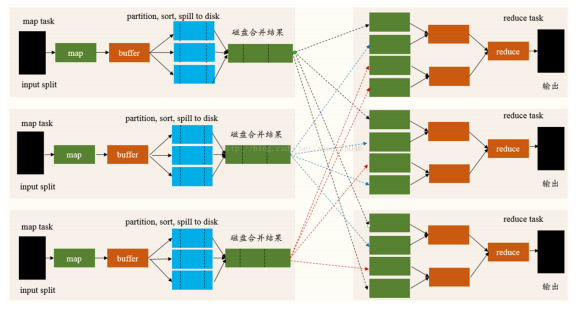
Spark��DAG���ȽλὫһ��Job����Ϊ���Stage,����Stage��map����,����Stage��reduce����,�䱾���ϻ���MapReduce�����ܡ�Shuffle������map��reduce֮�������,����map�������Ӧ��reduce������,�漰�����л������л�����ڵ�����IO�Լ����̶�дIO��
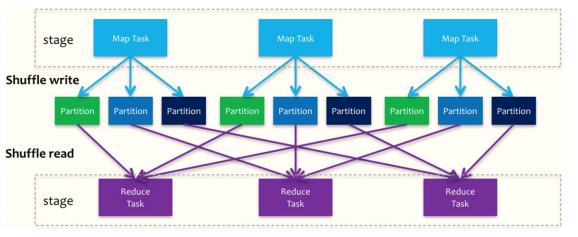
Spark��Shuffle��ΪWrite��Read������,������������ͬ��Stage,ǰ����Parent Stage�����һ��,������Child Stage�ĵ�һ��
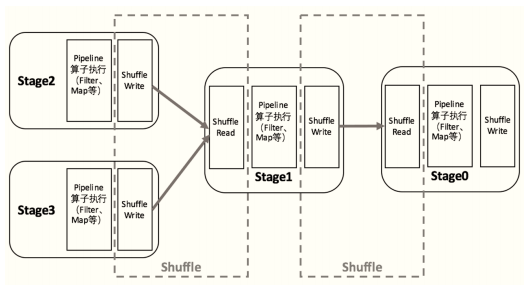
- (2) Shuffle����
- �� ʵ��ȫ�������顢����
- �� Spark��DAG���ȽλὫһ��Job����Ϊ���Stage,����Stage��map����,����Stage��reduce����,�䱾���ϻ���MapReduce�����ܡ�
- �� Shuffle������map��reduce֮�������,����map�������Ӧ��reduce������,�漰�����л������л�����ڵ�����IO�Լ����̶�дIO�ȡ�
- �� Spark��Shuffle��ΪWrite��Read������,������������ͬ��Stage,ǰ����Parent Stage�����һ��,������Child Stage�ĵ�һ��
- �� Stage������������
- ShuffleMapStage,��Spark 1��Job��,�������һ��Stage֮��,�������е�Stage���Ǵ�����
- a.��Shuffle����д�뵽���ش���,ShuffleWriter
- b.�ڴ�Stage��,���е�Task��Ϊ:ShuffleMapTask
- ResultStage,��Spark��1��Job��,���һ��Stage,�Խ��RDD���в���
- a.���ȡǰһ��Stage������,ShuffleReader
- b.�ڴ�Stage��,���е�Task�����ΪResultTask
- ShuffleMapStage,��Spark 1��Job��,�������һ��Stage֮��,�������е�Stage���Ǵ�����
- (3)Spark Shuffle�ķ�չ
- �� Spark��1.1��ǰ�İ汾һֱ�Dz���Hash Shuffle��ʵ�ֵķ�ʽ
- �� ��1.1�汾ʱ�ο�HadoopMapReduce��ʵ�ֿ�ʼ����Sort Shuffle
- �� ��1.5�汾ʱ��ʼTungsten��˿�ƻ�,����UnSafe Shuffle�Ż��ڴ漰CPU��ʹ��
- �� ��1.6�н�Tungstenͳһ��Sort Shuffle��,ʵ�����Ҹ�֪ѡ�����Shuffle��ʽ
- �� ����2.0�汾,Hash Shuffle�ѱ�ɾ��,����Shuffle��ʽȫ��ͳһ��Sort Shuffleһ��ʵ����
14.�ܽ�
- (1) ��������
- �� Application:�û�������SparkӦ�ó���,ÿ��Spark���������һ��Driver���̺Ͷ��Executor�����ڼ�Ⱥ��
- ÿ�������Driver��Executor���Ƕ�����,���ǹ�����
- �� Application jar:�������õij�����jar��,�ύ��Ⱥ����,jar���в��ܰ���hadoop��spark������jar��
- �� Job:��������ִ�г���ĵ�Ԫ,�ɴ�������������job�Ĺ���
- һ��Application�п����ж��job
- �� Stage:��һ��Job�и����Ƿ����������������Stage����:���ƻ���
- �㷨:�����㷨
- ��������������˵,Stage��Applicationȫ�ֱ�ŵ�ÿ����,Ϊ��ʵ�ֲ�ͬjob֮��stage�Ľ������
- �� TaskSet:ÿ��Stage��ת��Ϊһ��TaskSet�������ƻ���,Task�ļ���
- ÿ��TaskSet�п��Զ��Task:Stage�е�RDD����������
- �� Task:��������,ÿ��������Ӧһ��Task������ִ��
- Task��Driver�е�������з���������Executor��,ʹ��Executor�е���Դ��Դ
- ÿ��Taskʹ��1Core���������
- �� Driver:��ʼ������,��������main����,����SparkContext����
- ������Դ:����Executor
- ���������ȡ����Task
- �� Executor:ִ�н���,������Worker�ڵ���,ʹ��Worker�������Դ����ִ��Task
- �� ClusterManager:�ֲ�ʽ��Դ����ƽ̨�����ڵ�
- Standalone:Master
- YARN:RM
- �� Worker Node:�ֲ�ʽ��Դ����ƽ̨�Ĵӽڵ�
- Standalone:Worker
- YARN:NM
- ? deploymode:������driver�������е�λ��,
client���ͻ��ˡ���cluster��Worker�ڵ��ϡ�
- �� Application:�û�������SparkӦ�ó���,ÿ��Spark���������һ��Driver���̺Ͷ��Executor�����ڼ�Ⱥ��
- (2) Spark�ں˵�������(Job��������)
- Step1:��Ⱥ����
- ������Master:�����ڵ�
- a.���ܿͻ�������
- b.�����ӽڵ�Worker�ڵ�
- c.��Դ����
- �ӡ���Worker:����ڵ�
- ʹ���Լ����ڽڵ����Դ����Executor����:��ÿ��Executor����һ������Դ
- ������Master:�����ڵ�
- Step2:�ύ����
- Driver����
- a.��spark-submit�ű��ͻ��˽�������
- b.�����ڵ�����Executor��Դ,�����ڵ��ڴӽڵ��ϸ�����������������Ӧ��Executor
- c.����������:�������е���ת��ΪTask
- �������RDD�е����ݵ�ʹ��:����һ��Job,����Task������
- d.��Task�����Executorȥ����
- e.���ÿ��Executor���е�Task״̬
- Executor����
- a.������Worker��,ʹ��Worker�������Դ�ȴ�����Task
- b.����Executor�����ɹ��Ժ����Driver����ע��
- c.Executor�յ�����Task����,����Task
- Driver����
- Step3:�����
- 1)Driver��ʼ����Main������ʼ�Ĵ���
- 2)�����г���RDD���ݵ�ʹ��,�ͻᴥ��job
- 3)job������,DAGScheduler���ͨ�������㷨��RDD��ת������DAGͼ,��Shuffle����Stage
- DAGScheduler:ר�Ÿ���DAG,�����װ��SparkContext
- ����DAG�ӱ����С��Stage��ʼ,ת��ΪTaskSet
- ÿһ��Stage��ת��Ϊһ��TaskSet����,TaskSet�����л��ж��Task
- TaskScheduler:�������TaskSet��Task,�����װ��SparkContext,��ÿ��Task�ύ��TaskManager
- TaskManager:����ÿ��Task�����Executor����
- Driver��TaskSet�е�Task������ȵ�Executor��ִ��
- DAGScheduler:ר�Ÿ���DAG,�����װ��SparkContext
- Step1:��Ⱥ����
- (3) Spark���ж�
- �� ��Դ���ж�:Executor�ĸ�����ô����?
- ԭ��:������õ�ǰ����������Դ
- ����:����10̨,ÿ̨16core,32GB,����ֻ����һ������,���������õ�������Դ
- CPU����:ÿ��Executor���ٸ���2Core,��֤Executor�п��Բ���
- �ڴ��С:��CPU������2��
- �� ���ݲ��ж�:Task�ĸ�����ô����?
- ԭ��:Task�����ɷ���������,����Task����Ϊ����Executorʹ�õ�CPU������2 ~ 3��
- ����:������10��Executor,ÿ��Executor2Core4GB
- a.��CPU:20��
- b. ����:Task�ͷ����� = 40 ~ 60
- �� ��Դ���ж�:Executor�ĸ�����ô����?