第一章 Map
1.1 InputFormat数据输入
1.2 map阶段
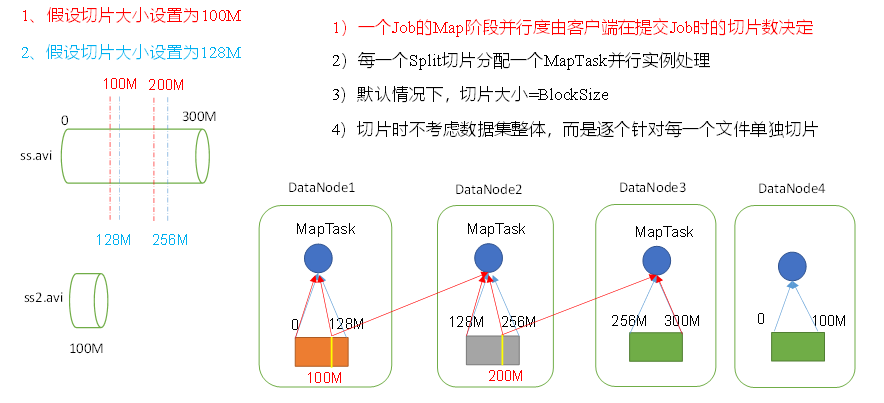
- 一个job的map阶段并行度由客户端在提交job的时候的切片决定
- 每个
split切片分配一个maptask,每个maptask是并行运行 - 每个切片数的大小由块大小决定:
split.size = block.size - 切片时不考虑数据集的整体,而是针对每个文件进行切片
- 每个maptask运行在哪个节点是根据节点上的资源来决定的
- 具体maptask运算过程
- 按行处理,读数据
- 按空格切分行内单词
- 形成kv键值对<单词, 1>
- 将所有的kv键值对中的单词,按照单词首字母分成分区写道磁盘中
1.3 reduce阶段
- reduce的数量由分区数量来决定的,有多少个分区,就会启动多少个reducetask任务
- reduce具体过程
- 假设map阶段产生两个分区的数据,mrappmaster就会启动两个reducetask
a. reduce task1 处理 a-q所在分区的数据
b. reduce task2 处理 q-z所在分区的数据 - reduce task根据value值进行分组
- 将每个分组放进reducer方法中
- 将计算结果写入磁盘中
- 假设map阶段产生两个分区的数据,mrappmaster就会启动两个reducetask
1.4 mapreduce进程
- 负责整个程序的进程调度及状态协调
- 一个MR启动MRAppMaster,当MapTask或ReduceTask出现问题时,MRAPPMaster负责调度
- MapTask:负责Map阶段的整个数据处理流程
- ReduceTask:负责Reduce阶段的整个数据流程
第二章 Job提交及切片流程
2.1 job提交
准备流程:
- 开始进入提交流程:
boolean result = job.waitForCompletion(true); - 通过
submit()方法进行提交:submit() - 先判断状态:
ensureState(JobState.DEFINE) - 解决新老API兼容的问题:
setUseNewAPI() - 获取cluster:
connect() - 根据配置文件的设置,返回一个
Cluster()对象(看是本地运行还是yarn上运行:localProvider或者是yarnProvider):return new Cluster(getConfiguration()) - 实际上是通过
initialize()方法获取的YarnClientProtocolProvider对象或者是LocalClientProvider对象
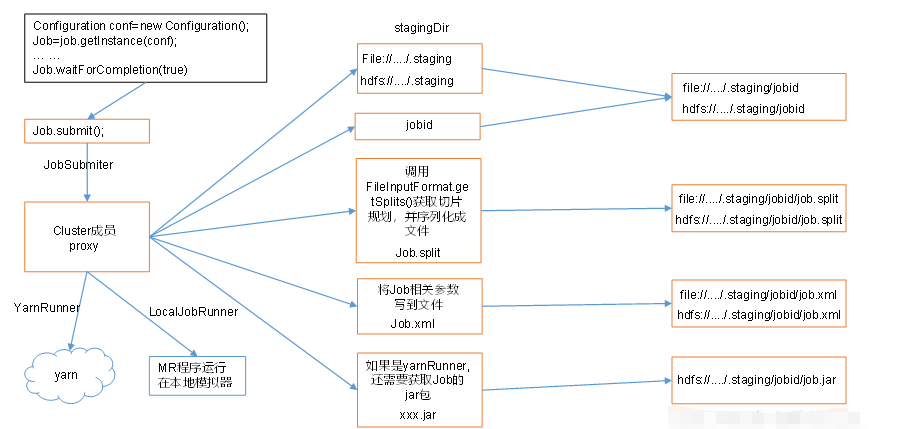
提交流程:
- 获取
submitter对象,通过该对象的submitJobInternal()方法开始提交job, - 先判断输出文件是否以及存在,如果存在会报错并结束程序:
checkSpecs(job); - 若第二步判断输出文件不存在,则继续向下运行,期间会在文件所在的磁盘的根目录下创建
tmp文件夹,存放job提交时mapreduce的切片信息、配置文件和jar包 - 开始切片:
int maps = writeSplits(job, submitJobDir) - 切片结束后,会将切片信息,切片元数据和切片校验数据写入刚刚创建的目录:
JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array) - 将配置写入
job.xml并生成校验文件job.crc,并放入tmp下的目录中:writeConf(conf,submitJobFile);如果由jar包的话,也会在这个目录下生成一个jar包文件 - 提交任务,并获取
status状态:status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials()); - 将
JobState的状态由:DEFINE转变为RUNNING,即job提交成功
任务结束:
- 当任务结束时,会将
xml文件、切片信息和jar包删除。
2.2 切片过程
- 开始切片:
int maps = writeSplits(job, submitJobDir); - 调用
maps = writeNewSplits(job,jobSubmitDir),通过反射InputFormat<?, ?> input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf)获取InputFormat的一个实例对象,默认Map端的输入阶段使用的类为TextInputFormat - 在2中获取的对象中,父类(
FileInputFormat)中有一个getSplits()方法,进行切片,先获取最小的长度,为1,通过long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job))获取,其中getFormatMinSplitSize()获取的值为1,getMinSplitSize(job)的值通过默认配置文件mapred-default.xml中mapreduce.input.fileinputformat.split.minsize=0获取,最终getMinSplitSize(job)的值为0,所以minSize=1;再获取最大值long maxSize = getMaxSplitSize(job),为Long的最大值 - 获取到
minSize和maxSize的值后,先判断文件是否可切片,isSplitable(job, path),再通过计算,得出切片的大小,判断blockSize和maxSize中的最小值,再用得出的最小值与minSize比较,获取两者之间的最大值,即默认情况下splitSize=blockSize:
// 获取切片大小
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
protected long computeSplitSize(long blockSize, long minSize, long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
- 获取切片大小后,开始正式切片,当剩余文件大小
bytesRemaining与切片长度splitSize
的比值大于SPLIT_SLOP=1.1时,就继续切割,直到比值小于SPLIT_SLOP=1.1时,将剩下文件大小单独切一片:
// 切片源码FileInputmat
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
第三章 切片机制
3.1 FileInputFormat切片机制
- 简单按照文件内容长度进行切片(默认按照TextInputFormat()进行切片)
- 切片大小,默认和
blockSize大小相等 - 切片时不考虑整体数据,而是逐一针对每个文件继续切片
minSize不变, 调整maxSize比blockSize小时,可以使得切片变小。maxSize不变,调整minSize比blockSize大时,可以使得切片变大。- 获取切片信息API:
//获取文件名称
String fileName = inputsplit.getPath().getName();
// 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
// 切片大小
Math.max(minSize, Math.min(maxSize, blockSize));
// minSize默认值
minSize = 1
// maxSize 默认值
maxSize = Long.MAX_VALUE
3.2 CombineTextInputFormat切片机制
- 切片时,把多个小文件在逻辑上规划到一个切片中,这样就能同时将多个小文件交给一个
maptask进行处理 - 虚拟存储切片大小设置:
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m;应该根据实际情况进行设置 - 切片包括两部分:
①. 虚拟存储过程:判断文件大小和setMaxInputSplitSize值的大小,进行逻辑划分
②. 进行切片,将小于setMaxInputSplitSize值的大小的文件切成一片,大于setMaxInputSplitSize的值的文件单独切成一片

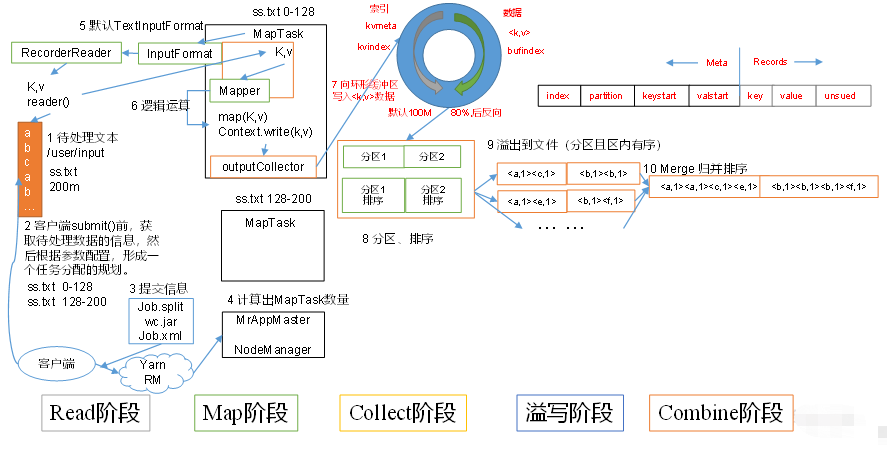
第四章 MapReduce工作流程
4.1 MapReduce工作流程
- 交给集群处理之前,客户端会做预处理:先生产切片信息,读取配置文件产生
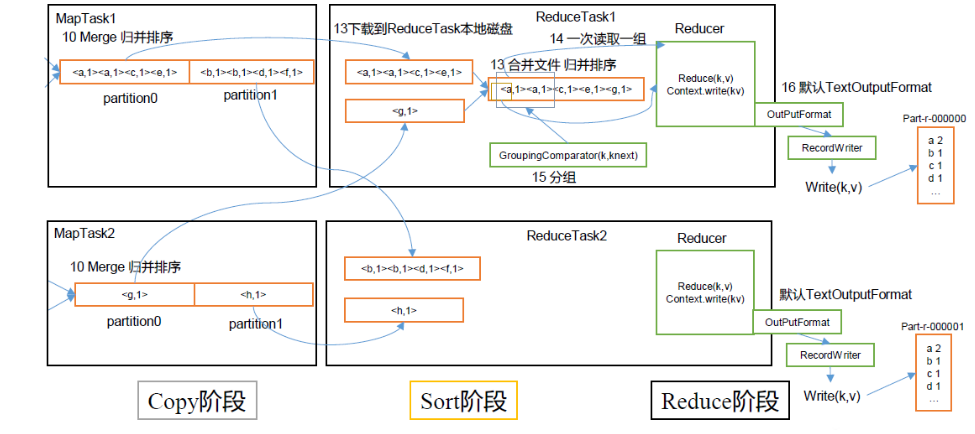
job.xml文件,再和jar包一起上传到集群中; YarnRunner开启MrAppmaster,读取客户端上传的切片信息,并计算出MapTask任务数量,有多少个切片就开启多少个Maptask;MapTask任务开启后,默认的TextInputFormat中的LineRecordReader(recordDelimiterBytes);就会按行去读取文件信息;LineRecorderReader()读取的数据按照Key(偏移量),Value(每行的内容)的形式,传到Map阶段,在map()方法中进行处理,map阶段处理完的数据,会先进入环形缓冲区outputCollector,环形缓冲区是内存中的一片空间,默认为100M,左半部分存放元数据(索引、分区信息、Key的位置和Value的位置),map()输出的数据达到环形缓冲区时,先将数据进行分区(分区是为了将同一区的数据交给同一个reduceTask进行处理),分好区后再开始进行排序(快速排序,对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key的字典序进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序),当数据量到达换新缓冲区容量的80%时,开始反向写入数据,并且先前写入的数据开始溢写到磁盘,产生多个临时小文件,当所有的数据在map阶段处理完了后,MapTask会按分区将所有临时小文件合并成一个大文件然后按照分区进行归并排序,最终生成一个数据文件交由ReduceTask进行处理;MrAppmaster观察所有的MapTask结束后,会启动相应的educeTask进行处理文件,相应的Map阶段分了几个区,就会启动多少个ReduceTask;ReduceTask会主动的去下载MapTask处理完的所有相同分区的数据,然后将所有相同分区的数据再进行一次归并排序,然后交给reduce()方法进行处理,reduce()一次读取一组相同key的数据,然后将数写出context.write(k,v),最后由默认的TextOutputFormat将数据输出到文件中,每一个ReduceTask生产一个排好序的分区文件。
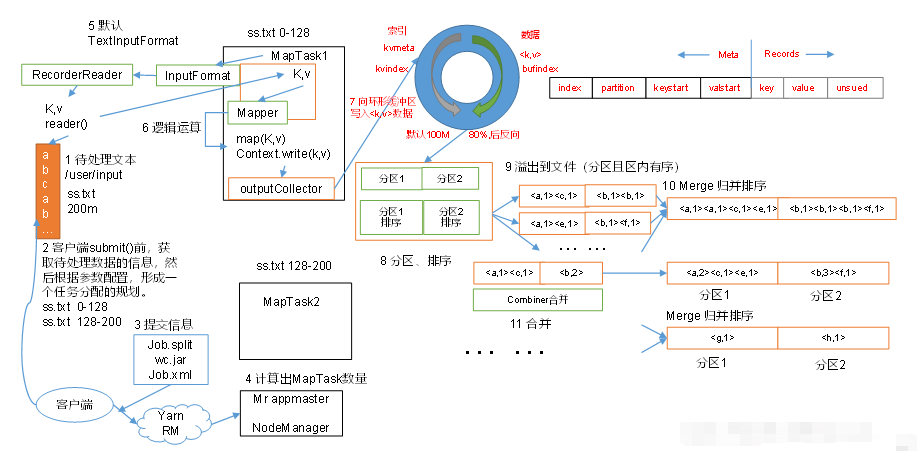
4.2 Shuffle机制
- 在
map()阶段处理完后,进入到环形缓冲区处理数据的过程称为shuffle机制
-. 是内存中开辟的一个环形空间
-.map()处理完的数据存入到缓冲区中,左边部分存索引、分区等元数据,右边存Key,Value数据
-. 将数据按分区存放,并进行快速排序
-. 数据容量到达环形缓冲区的80%时,将数据溢写到磁盘,并反向开始写入新数据
-. 溢写数据时,将相同分区的数据合并(merge),再将合并到同一个文件内的数据用归并排序生一个大的有序的分区文件,并保存在磁盘上。
4.3 Partition分区
- 分区数和
reduceTask的数量有关。 - 当ReduceTask的数量为1时,默认分区就1个
- 当ReduceTask的数量>1时,分区数=
key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; - 默认是通过
HashPartitioner进行分区的
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
- 也可以自定义分区,继承
Partitioner父类,重写getPartition()方法:
public class MyPartitioner<K, V>extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
/*
代码内容
*/
}
}
- 自定义好分区后,需要在驱动中设置
jot.setPartitionerClass(MyPartitioner.class),并设置相应数量的reduceTask:job.setNumReduceTask(int numReduceTask); - 分区总结:
①. 如果ReduceTask的数量>getPartition的结果,则会产生多几个空文件part-r-000xxx;
②. 如果ReduceTask的数量=getPartition=1,则不管MapTask输出多少个文件,都只会交给一个ReduceTask进行处理,最终得到的文件也只有一个part-r-000001;
③. 如果ReduceTask的数量<getPartition的结果,则有一部分数据无处安放,最终会exception
4.4 WritableComparable排序
- 在
MapTask和ReduceTask阶段均会按照key的字典序对数据进行排序 - 如果要自定义排序,那么所创建的Bean类就要继承
WritableComparable父类,并重写compareTo()方法
第五章 MapTask工作机制和Reduce工作机制
5.1 MapTsk工作机制:
Read阶段:读取数据,默认TextInputFormat中的LineRecorderReader()去读取,按行读取数据Ma阶段:对输入的数据Key/value交给用户编写的Map()方法进行处理Collect阶段:Map阶段的数据先存到环形缓冲区中,进行分区和排序,当数据达到一定的量时,进行溢写Spill(溢写)阶段:当环形缓冲区数据量满了时,MapReduce会将数据写到本地磁盘上的一个临时文件中去。- 溢写阶段详情:
①. 快速排序,按照分区先排序,然后再按照key的字典序排序
②. 按照分区将数据分别写入对应的分区内,生产临时文件output/spillN.out(N表示当前溢写次数)
③. 将分区的元数据写入到内存索引数据结构spillRecord中,元数据包括偏移量、压缩前数据大小和压缩后数据大小。
④. 如果内存索引大小超过了1MB,则将内存索引写道文件output/spillN.out.index中。 Combine阶段:当所有数据处理完了,将相同分区的数据合并,并进行归并排序,然后写入到本地磁盘的临时文件中。
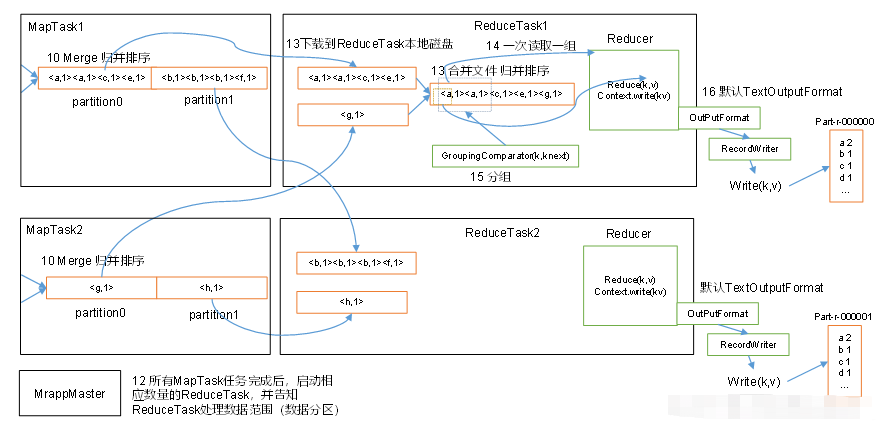
5.2 ReduceTask`工作机制:
Copy阶段:主动去下载MapTask阶段处理的文件;Sort阶段:先用归并排序将数据合并,并按组读取数据交由reduce()方法进行处理;reduce()方法的输入是按key进行聚集的一组数据;Reduce阶段:reduce()计算的结果写到HDFS上。