Spark环境搭建
Spark的部署方式
????????目前Spark支持4种部署方式,分别是Local、Standalone、Spark on Mesos和 Spark on YARN。Local模式是单机模式。Standalone模式即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。Spark On Mesos模式是官方推荐的模式。Spark运行在Mesos上会比运行在YARN上更加灵活。Spark On YARN模式是一种很有前景的部署模式。在应用中通常需要根据实际情况(技术路线、人才储备等)决定采用哪种方案。如果仅仅测试Spark Application,可以选择local模式。如果数据量不大,Standalone 是个不错的选择。如果需要统一管理集群资源(Hadoop、Spark等),考虑到兼容性,Yarn是个不错的选择。如果不仅运行了hadoop,spark。还在资源管理上运行了Docker,Mesos更加通用。但是这样维护成本就会增加。
1.Local模式(本地Spark shell)
????????Scala 是一门多范式的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。Scala 运行在 Java 虚拟机上,并兼容现有的 Java 程序。Scala 源代码被编译成 Java 字节码,所以它可以运行于 JVM 之上,并可以调用现有的Java 类库。
(1)为方便后续操作这里更改为root用户进行操作。

(2)通过命令“tar -zxvf scala-2.10.4.tgz -C /home/”,解压安装包到指定的目录/home/下。

(3)为了后续配置操作方便,在此需要将解压后的文件重命名。

(4)通过命令“vim /etc/profile”编辑用户环境变量,配置Scala的环境变量。
?
(5)?让环境变量立刻生效“source /etc/profile”,并且查看是否安装成功scala。

(6)?通过命令“tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /home”,解压Spark安装包到指定目录。

(7)?为了后续配置操作方便,在此需要将解压后的文件重命名。

(8)通过命令“vim /etc/profile”,配置Spark环境变量。

(9)?让环境变量立即生效“source /etc/profile”。

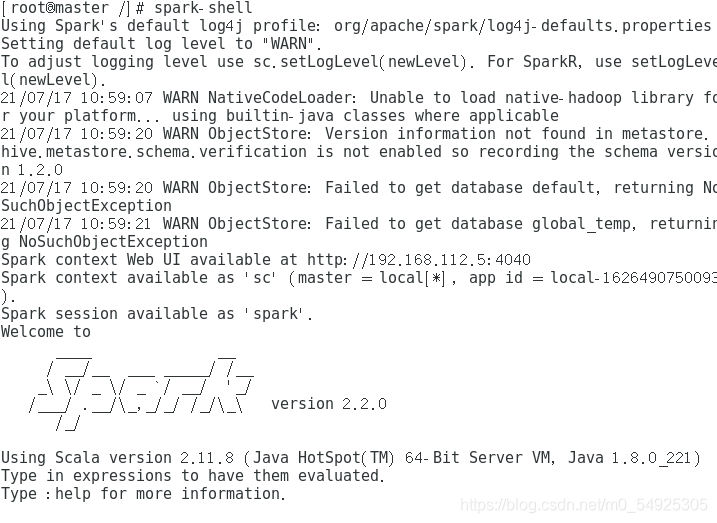
(10)测试运行“spark-shell”命令,查看spark是否成功安装。
2、?Standalone模式部署
(1)通过命令“cd /home/spark/conf/”,切换到conf/目录中,使用“mv slaves.template slaves”命令重命名,并编辑该配置文件。


(2)通过命令cd /home/spark/conf/,切换到conf/目录中,使用vim spark-env.sh命令,编辑该配置文件。如果在conf目录下没有该文件,请使用命令“cp spark-env.sh.template spark-env.sh”,复制模板文件,并重命名为“spark-env.sh”再进行如下配置。


(3)?通过命令“scp -r /home/spark/ slave1:/home”,“scp -r /home/spark/ slave2:/home”将配置好的spark安装包发送至slave1和slave2节点。


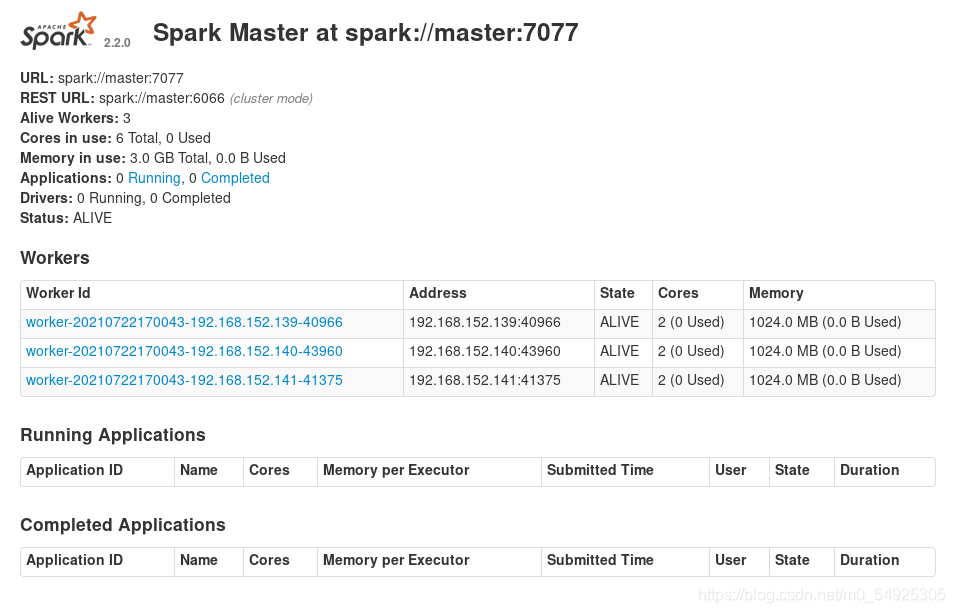
(4)在spark安装路径中运行“sbin/start-all.sh”命令,启动Standalone模式。

(5)?运行“jps”命令查看Spark启动进程如图所示。如果可以查看到“master”和“Worker”进程,即可说明Spark主节点启动成功。

?

(6)在master所在机器的虚拟机浏览器地址栏中输入“master:8080”查看网页spark管理页面。
?3、Spark On YARN模式
(1)使用命令 cd /home/hadoop/etc/hadoop进入到hadoop的配置文件目录,使用“vim yarn-site.xml”编辑该文件,在该文件内添加以下内容。

(2)通过以下命令将yarn-site.xml文件分发至slave1,slave2。?

(3)进入conf目录,修改spark-env.sh,添加如下配置,如图所示,保存退出。

(4)完成spark-env.sh的配置后,在Hadoop安装目录/home/hadoop下使用命令 “sbin/start-all.sh”启动Hadoop集群。

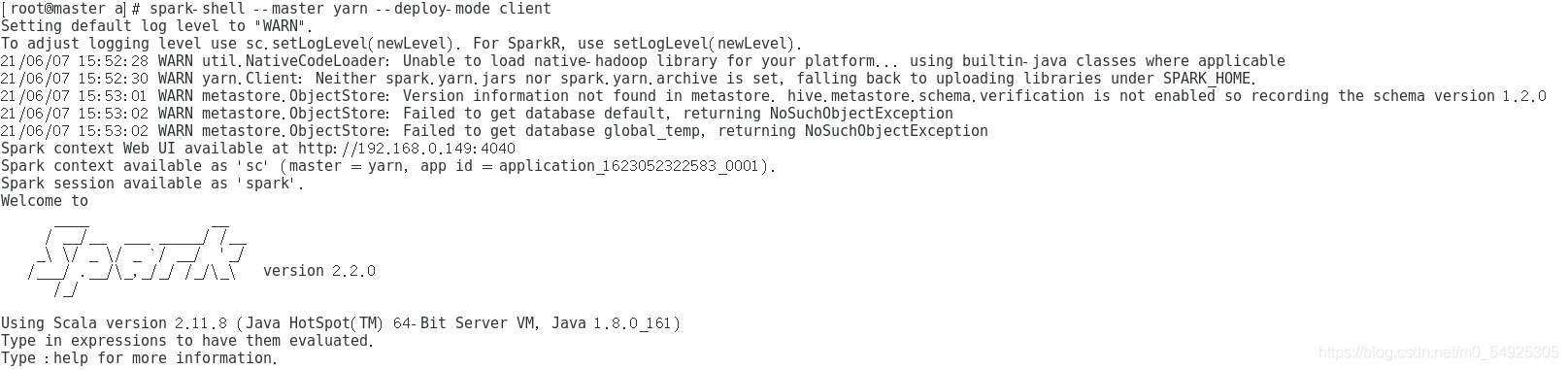
(5)使用命令“spark-shell --master yarn --deploy-mode client”来启动Spark shell。
(6)在spark安装路径中运行“sbin/start-all.sh”命令,启动spark集群。

(7)运行“jps”命令查看Spark启动进程,如果可以查看到“master”和“Worker”进程,即可说明Spark主节点启动成功。如图分别对应master,slave1和slave2的进程。


 ?
?
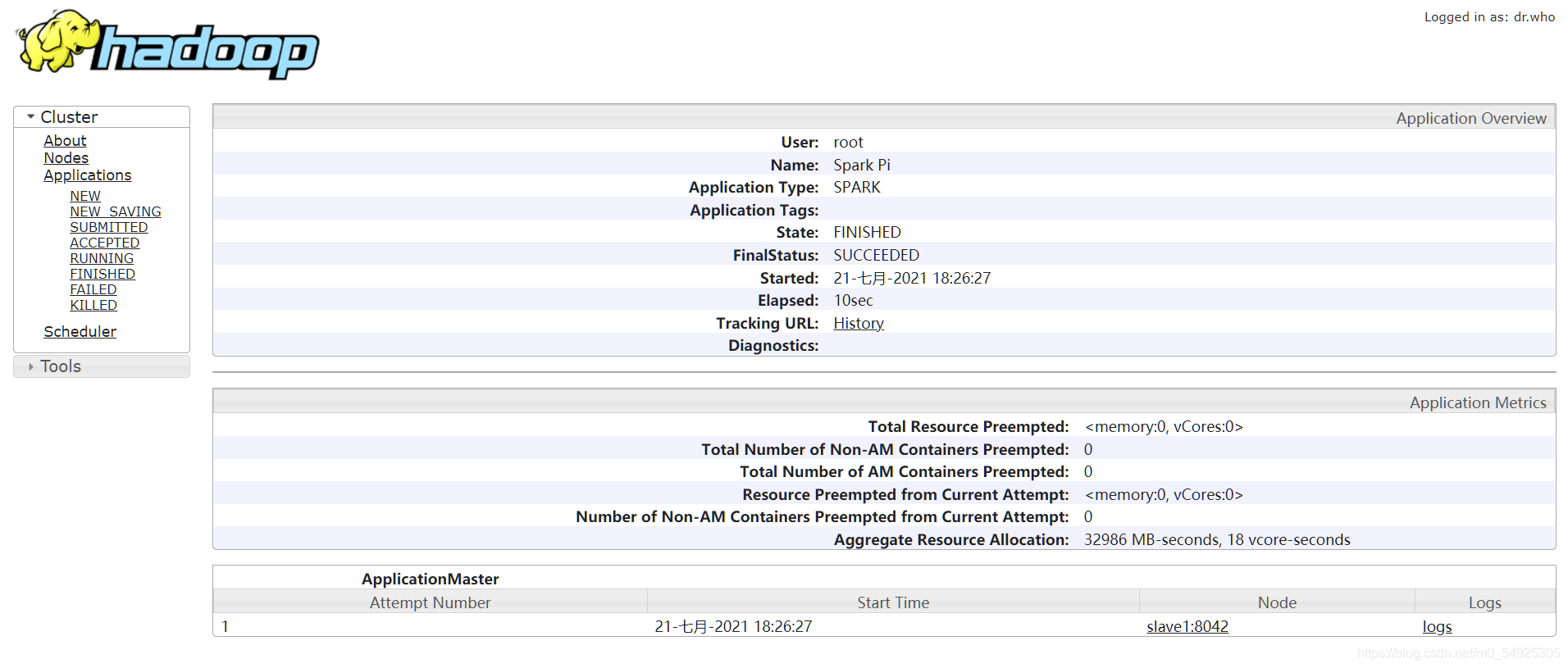
(8)向独立集群管理器提交应用,需要把spark://master:7077作为主节点参数传递给spark-submit命令。可以运行Spark自带的样例程序SparkPi,它的功能是计算得到pi的值。在Linux Shell中执行如图的命令运行SparkPi(jar包可以使用Tab键进行补全),得到如图所示的结果。
?

(9)查看Spark的webUI,在虚拟机浏览器地址栏中输入“master:8088”,查看是否成功上传PI,如图所示。?