第4章 运行模式―YARN模式
- (
重要) 此模式需要创建另外两台虚拟机,可以从目前的虚拟机中拷贝,具体步骤请参考博客:虚拟机环境准备 中第1.1小节末尾处的描述。 - (
重要) 虚拟机环境准备好之后,虚拟机上安装的Hadoop也需要进行相应的配置,详情可参考:完全分布式运行模式 中第4.5小节进行操作。
4.1 搭建运行环境
4.1.1 进入到Spark安装包路径下
[xqzhao@hadoop100 ~]$ cd /opt/software/
4.1.2 解压安装文件到/opt/module下面
[xqzhao@hadoop100 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
4.1.3 查看是否解压成功
[xqzhao@hadoop100 software]$ ls /opt/module/
spark-3.0.0-bin-hadoop3.2
// 重命名文件夹―使用 `YARN模式` 时
[xqzhao@hadoop100 module]$ mv spark-3.0.0-bin-hadoop3.2 spark-yarn
4.2 修改配置文件
- (1) 修改
hadoop配置文件/opt/module/hadoop-3.2.1/etc/hadoop/yarn-site.xml(主机: hadoop100), 并分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- (2) 修改
Spark配置文件conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
[xqzhao@hadoop100 conf]$ mv spark-env.sh.template spark-env.sh
# 设置如下信息:
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop-3.2.1/etc/hadoop
4.3 启动 HDFS 以及 YARN 集群
- HDFS与YARN集群启动方法请参考: 完全分布式运行模式 中第
4.8.2小节进行操作。
4.4 提交应用
注:直接提交应用,不需要启动 Spark集群。
[xqzhao@hadoop100 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
运行效果如下图所示:
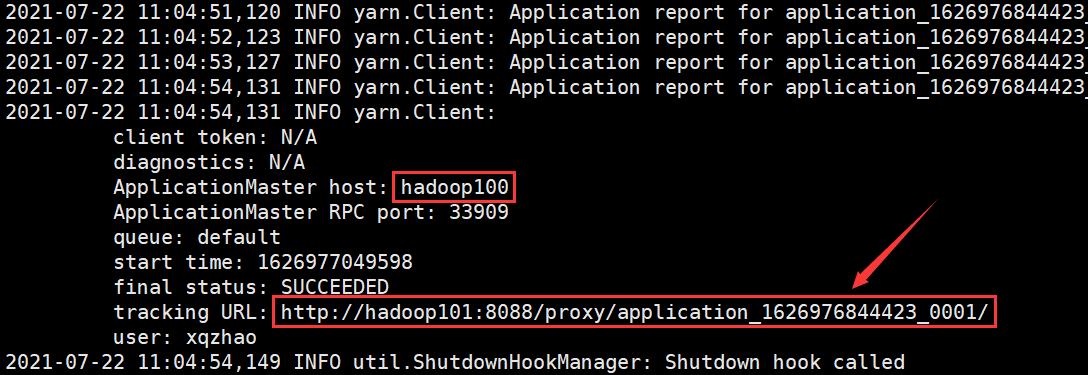
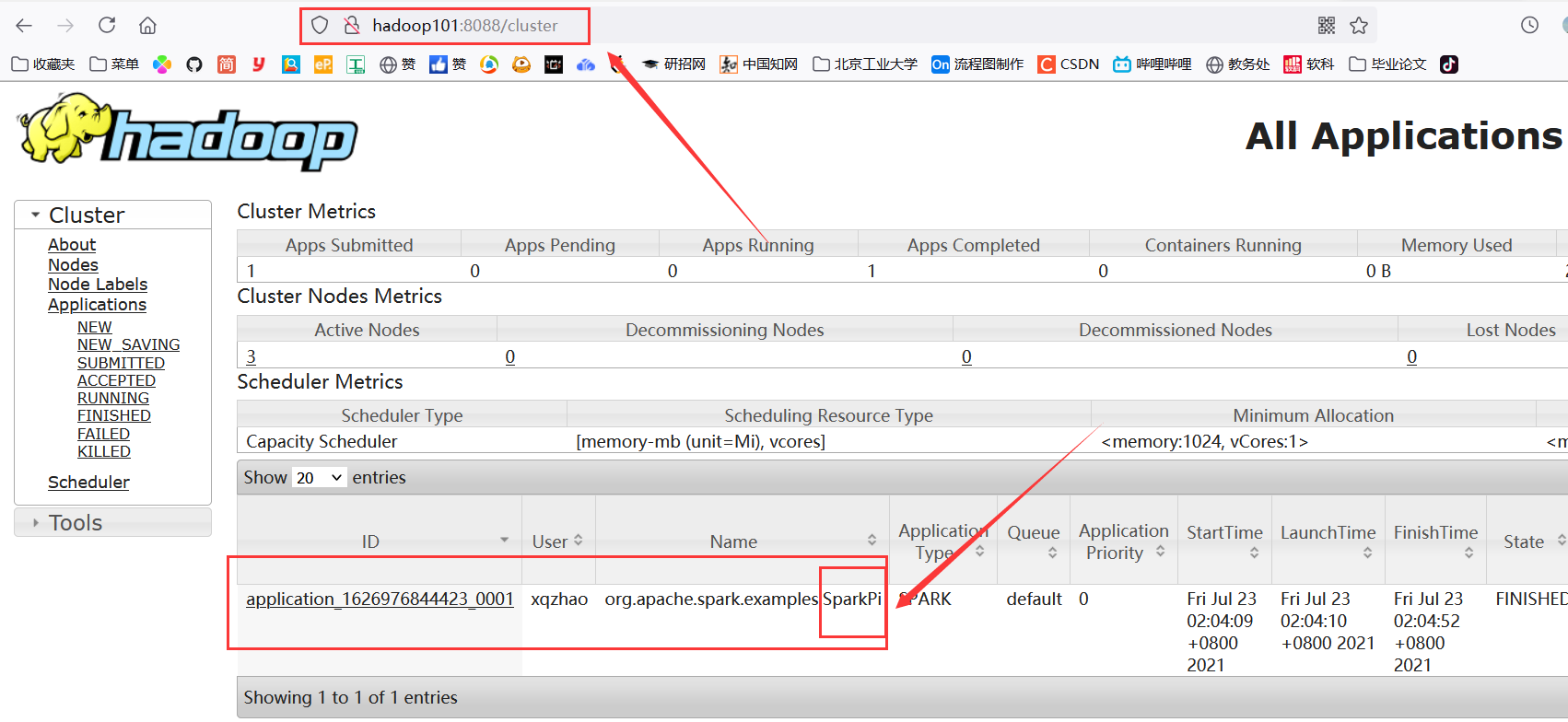
查看 http://hadoop101:8088 页面,点击 History(滑动到最右侧可以看到),查看历史页面:
4.5 配置历史服务器
- (1) 拷贝一份
spark-defaults.conf.template并命名为spark-defaults.conf
[xqzhao@hadoop100 conf]$ cp spark-defaults.conf.template spark-defaults.conf
- (2) 修改
spark-default.conf文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory
注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
[xqzhao@hadoop100 spark-standalone]$ sbin/start-dfs.sh
[xqzhao@hadoop100 spark-standalone]$ hadoop fs -mkdir /directory
- (3) 修改
spark-env.sh文件, 添加日志配置
[xqzhao@hadoop100 spark-standalone]$ vim conf/spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory
-Dspark.history.retainedApplications=30"
- 参数1含义:WEB UI 访问的端口号为
18080 - 参数2含义:指定历史服务器日志存储路径
- 参数3含义:指定保存
Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- (4) 修改
spark-defaults.conf
spark.yarn.historyServer.address=hadoop100:18080
spark.history.ui.port=18080
- (5) 启动集群和历史服务
[xqzhao@hadoop100 spark-standalone]$ sbin/start-history-server.sh
- (6) 重新执行任务
[xqzhao@hadoop100 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
运行效果如下图所示:
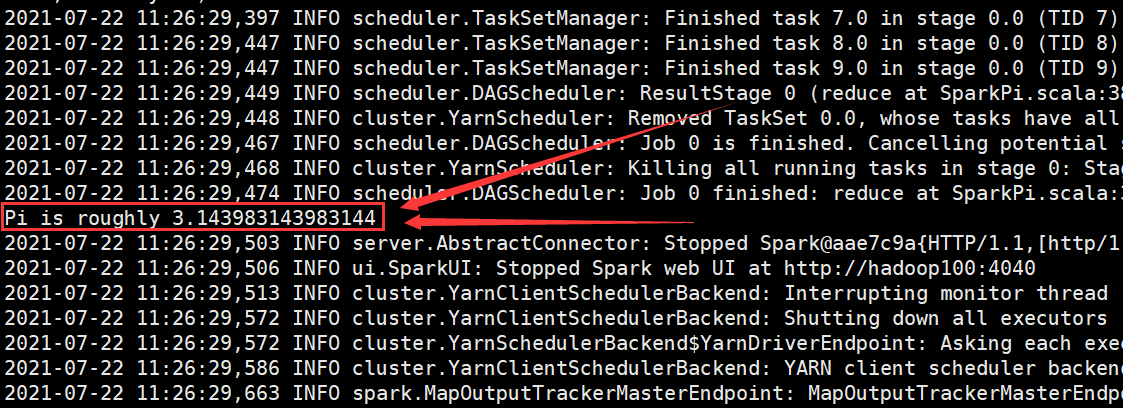
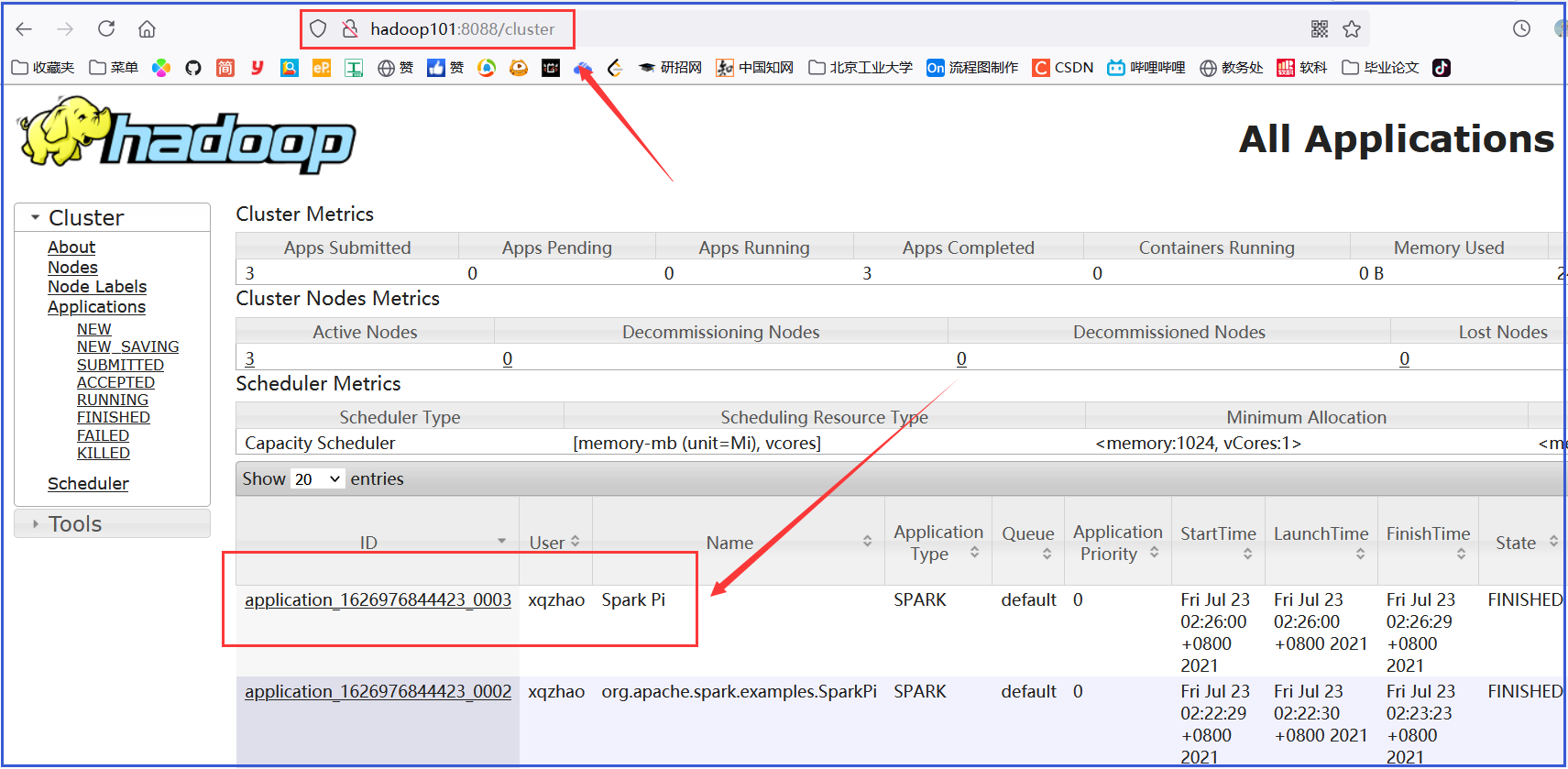
- (7) Web 页面查看日志:
http://hadoop101:8088
第5章 Windows10模式
5.1 解压缩文件
将文件 spark-3.0.0-bin-hadoop3.2.tgz 解压缩到无中文无空格的路径中。
5.2 启动本地环境
-
(1) 执行解压缩文件路径下
bin目录中的spark-shell.cmd文件,启动 Spark 本地环境
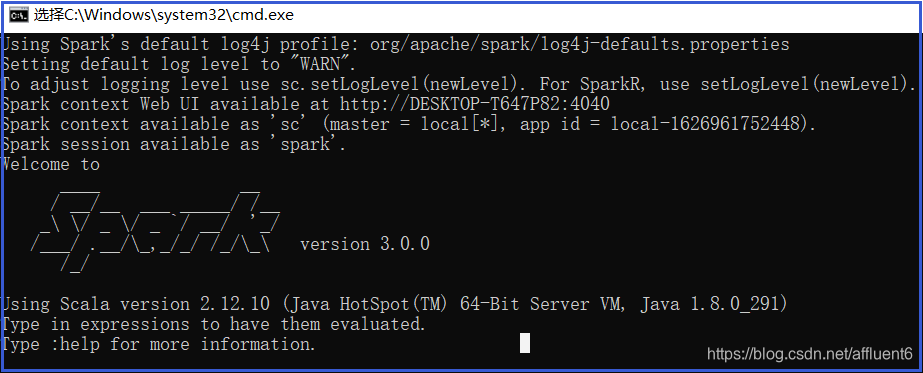
-
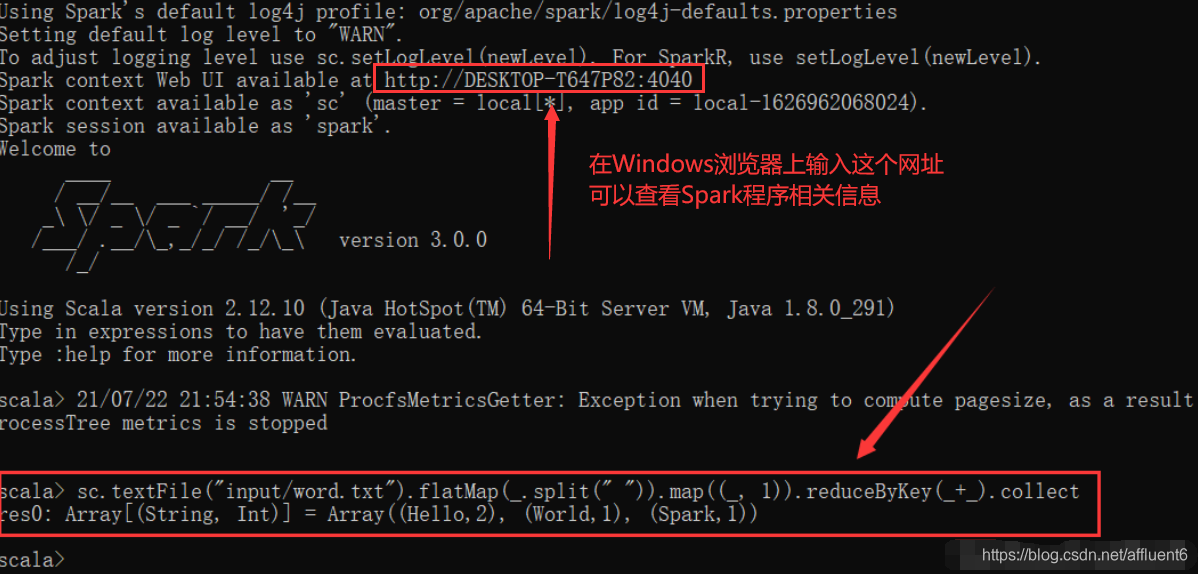
(2) 在
bin目录中创建input目录,并添加word.txt文件, 在命令行中输入下面的脚本代码:
sc.textFile("input/word.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect
5.3 命令行提交应用
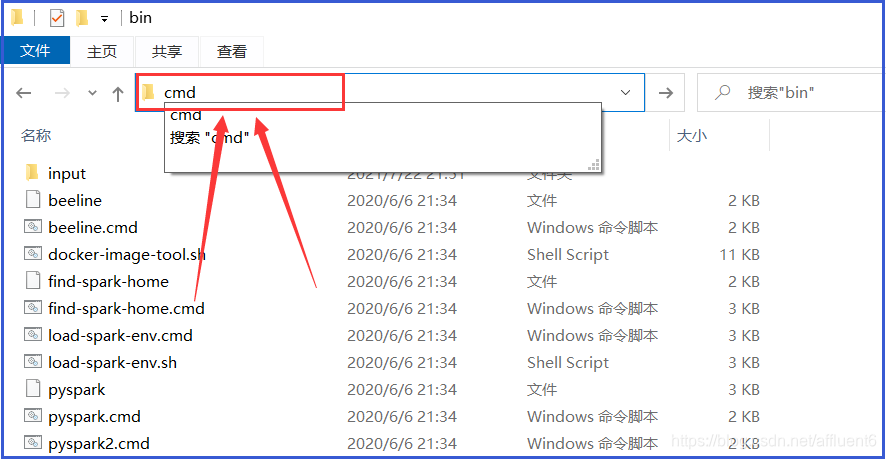
- 在Spark目录的
bin目录中,输入cmd并回车,打开DOS命令行窗口,如下图所示:
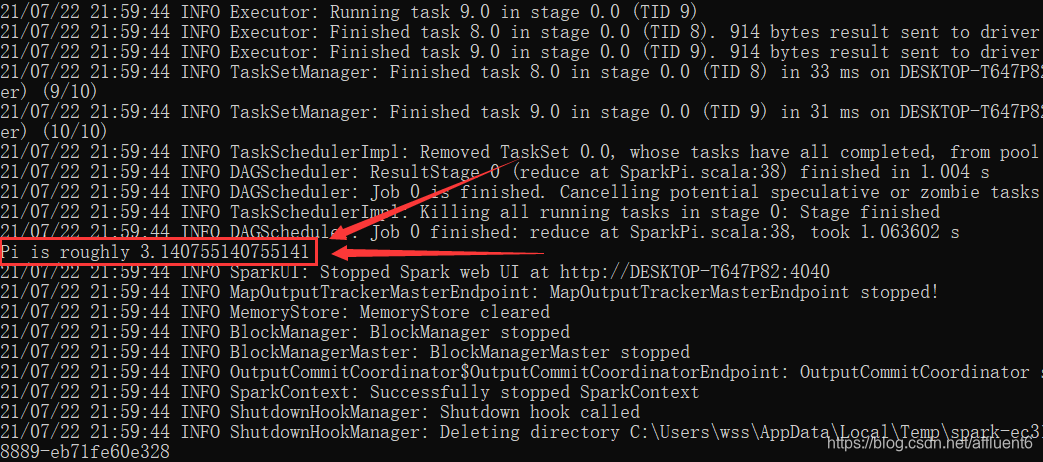
- 在 DOS 命令行窗口中执行提交指令:
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10
输出结果如下图所示:
声明:本文是学习时记录的笔记,如有侵权请告知删除!
原视频地址:https://www.bilibili.com/video/BV11A411L7CK