PyCharm远程连接Spark
使用PyCharm连接远程服务器,总结一下完善的步骤。连接前一定要保证集群已经可以运行pyspark程序
1、添加SFTP连接
找到菜单Tool ->Deployment -> Configuration设置sftp

点击左上角的+号,添加新的SFTP连接

输入需要SFTP的名称, “testSpark”

注意,不要勾选Visible only for this project。根据自己的需求填写host、username、password,然后点击Test SFTP connection ,确认能连接

点击“Test Connetion”进行测试,测试成功,显示如下:
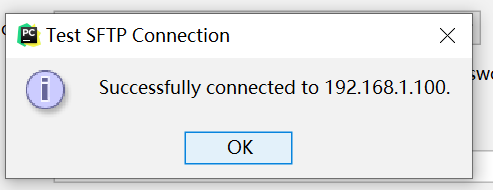
设置一下项目的路径,点击“mapping”。
Local path:本地项目路径
Deployment path:远程项目路径

远程项目路径,需要登录到spark的远端机器进行创建。
[hadoop@master ~]$ mkdir python_project
[hadoop@master ~]$ cd python_project/
[hadoop@master python_project]$ pwd
/home/hadoop/python_project
2、添加SSH INTERPRETER
通过菜单栏File -> Settings
找到本项目的Project Interpreter,点击右上角的Add

选择SSH Interpreter,选择下面的Existing server configuration,选中我们刚刚设置的SSH信息 “testSpark”。

根据需要修改路径,linux上默认的python的路径,我这里的是
/usr/local/bin/python3
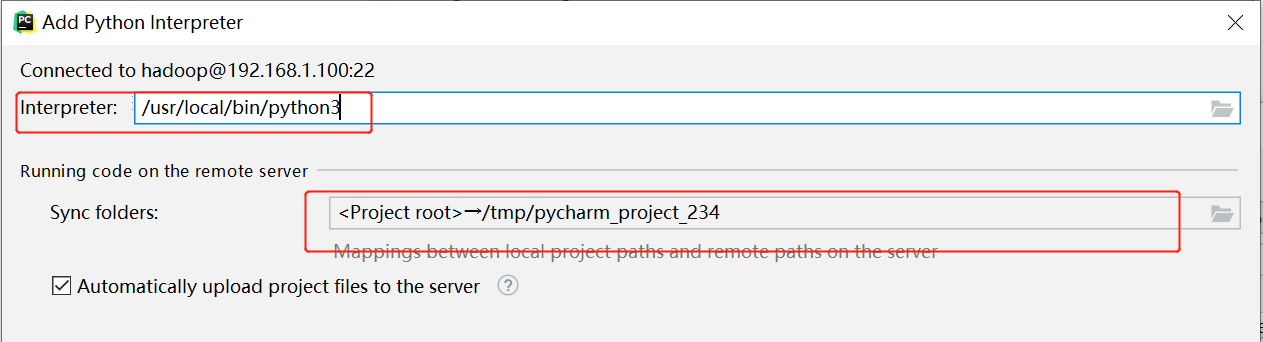
修改本地与服务器路径

点击ok完成
3、代码编写
from pyspark import SparkContext
import os
os.environ['PYSPARK_PYTHON']='/usr/local/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON']='/usr/local/bin/python3'
os.environ['SPARK_HOME']='/home/hadoop/apps/spark-2.3.0-bin-hadoop2.7'
os.environ['PYTHONPATH']='/home/hadoop/apps/spark-2.3.0-bin-hadoop2.7/python'
if __name__ == "__main__":
sc = SparkContext(master="local[*]", appName="pyspark")
lines = sc.textFile("data/words")
result = lines.flatMap(lambda line:line.split(" "))\
.map(lambda word:(word,1))\
.reduceByKey(lambda a,b:a+b)\
.collect()
for(word,count) in result:
print("%s,%i" %(word,count))
将代码同步到服务器
Tools -> Deployment -> Upload to testSpark

4、启动设置
点击右上角的三角形,然后删除working directory里面的路径,并更改Environment variables

5、启动运行
右键 -> Run “项目名”

参考:
https://www.freesion.com/article/76981031055/