背景:flink on yarn ? Per-job 模式下flink 程序会经常挂掉,直接原因是是对应节点上的 flink的 job manager 挂掉了,导致程序失败,flink的重启策略,只对于task manager生效 。 因此为保证稳定性,需要配置job manager 高可用。
实现方案?
?官方:当运行一个高可用的 YARN 集群时,我们不会运行多个 JobManager(ApplicationMaster) 实例,而是只运行一个,在失败时由 YARN 重新启动。确切的行为取决于您使用的特定 YARN 版本。
配置修改
flink-conf.yaml 添加如下配置,这里必须添加zookeeper 信息,官方文档pre job 只要求添加 重启参数,不添加的话,? task manager 会和job manager 一起挂掉,?只会重启对应的job manager? ??
# flink job manager次数 ?这个参数必须小于yarn.resourcemanager.am.max-attempts(没测试过)?
yarn.application-attempts: 3
# 添加zookeeper 配置
high-availability: zookeeper
high-availability.zookeeper.quorum: 10.5.1.142:2181
# job manager元数据在文件系统储存的位置
high-availability.storageDir: hdfs:///flink/recovery ??
测试
? ?1启动flink 程序,??
 ?
?
?2 kill 掉对应的?YarnSessionClusterEntrypoint (对应job manager)所在进程

?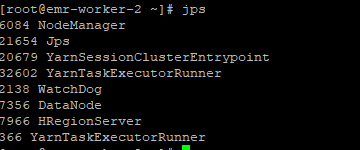
新的job manager,已经被重新,恰巧也和task Manager一个一个节点
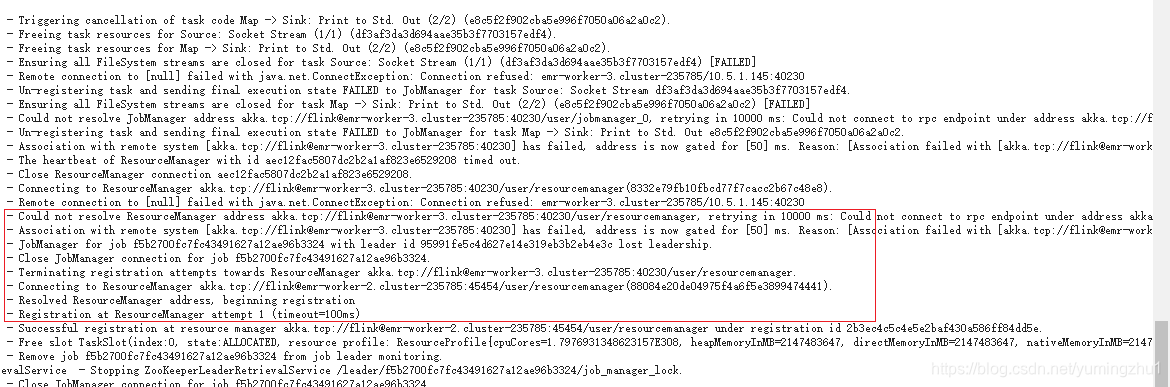
?task manager 上对应日志如上,与旧的job manager 的ResourceManager通信,当超时大于10s后,将其标记为失败,之后根据zookeeper去注册到新的job manager? ???ResourceManager 上个上

相关文档:官方文档地址