在开始之前,需要说明的是 要跑通基本的wordcount程序,是不需要在windows上安装 hadoop 和spark的,因为idea在跑程序的时候,会按照 pom.xml配置文件,从指定的 repository源,按照properties指定的版本,下载dependency中指定的依赖包 。?
如果需要在本地通过 spark-shell,或者 运行开发完的包,那么就需要完整的hadoop 和spark环境,就需要把这两个都安装好。
一、需要安装的软件版本 及 下载地址
jdk 1.8 :https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
Scala 2.11.8? :https://www.scala-lang.org/download/2.11.8.html
Intellij idea 2020.1社区版:?https://www.jetbrains.com/zh-cn/idea/download/other.html
Maven 3.6.3 :http://maven.apache.org/docs/history.html
?
二、配置环境变量 及 验证
1、Java
新增系统环境变量:JAVA_HOME ?C:\Program Files\Java
PATH 中增加:C:\Program Files\Java\jdk1.8.0_91\bin 和 C:\Program Files\Java\jre1.8.0_91\bin
CLASSPATH 中要增加:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar;
验证是否安装成功:
C:\Users\edz>java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b15)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b15, mixed mode)
C:\Users\edz>javac -version
javac 1.8.0_912、Scala
新增系统环境变量:SCALA_HOME C:\Program Files (x86)\scala
PATH 中增加:%SCALA_HOME%\bin
验证:
C:\Users\edz>scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91).
Type in expressions for evaluation. Or try :help.
scala> :quit3、Maven
Maven下载后,解压到了D:\spark_study ,删除了 apache-maven-3.6.3-bin目录,路径为D:\spark_study\apache-maven-3.6.3
新增系统环境变量:MAVEN_HOME D:\spark_study\apache-maven-3.6.3
新增系统环境变量:MAVEN_OPTS -Xms128m -Xmx512m
CLASSPATH 中要增加:%MAVEN_HOME%\bin
设置 本地maven 仓库 的路径为:D:\spark_study\localWarehouse
打开 D:\spark_study\apache-maven-3.6.3\conf\settings.xml,在文件中添加:? ?
? ? ? ?<localRepository>D:\spark_study\localWarehouse</localRepository>
接下来设置 国内maven仓库 如阿里仓库,在 <mirrors>标签中添加:
<mirror>
?? ?<id>nexus-aliyun</id>
?? ?<mirrorOf>central</mirrorOf>
?? ?<name>Nexus aliyun</name>
?? ?<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
验证:
C:\Users\edz>mvn -V
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: D:\spark_study\apache-maven-3.6.3\bin\..
Java version: 1.8.0_91, vendor: Oracle Corporation, runtime: C:\Program Files\Java\jdk1.8.0_91\jre
Default locale: zh_CN, platform encoding: GBK
OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"三、配置 intellij idea
1、安装?intellij idea
注意勾选红色框部分,然后一步一步安装就行。
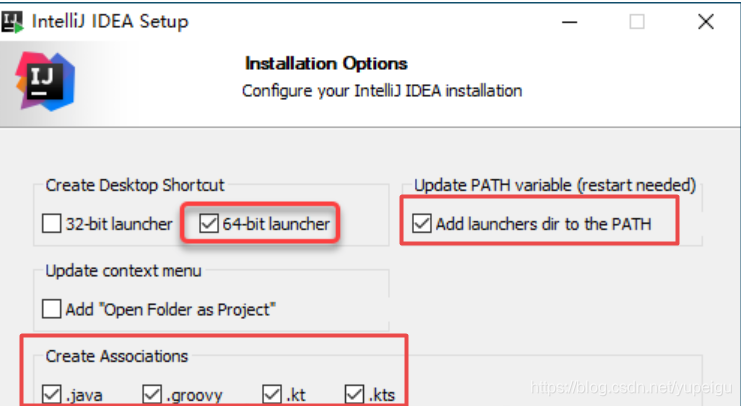
?2、安装scala插件
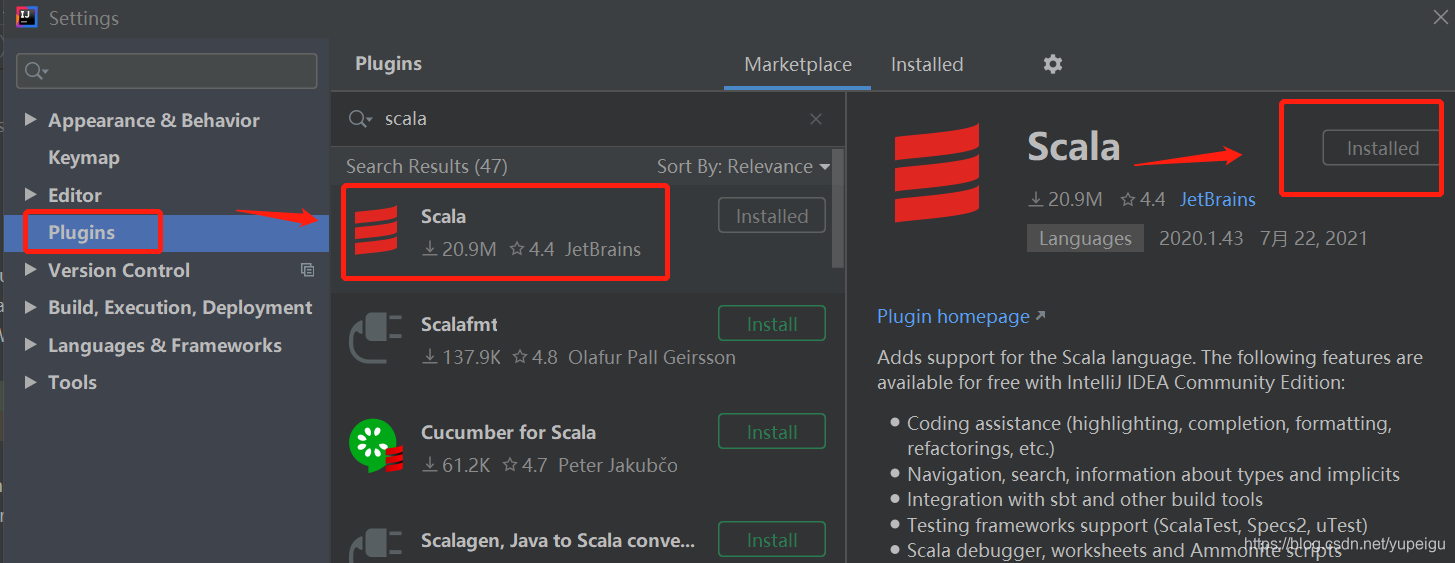
通过菜单 File -》Settings 进入如下页面,然后输入 scala 找到要安装的插件,点击 安装。按照提示,需要重启 IDE。
?如果 显示找不到插件,可以通过 点击 Auto-detect proxy settings 来设置代理,点击保存。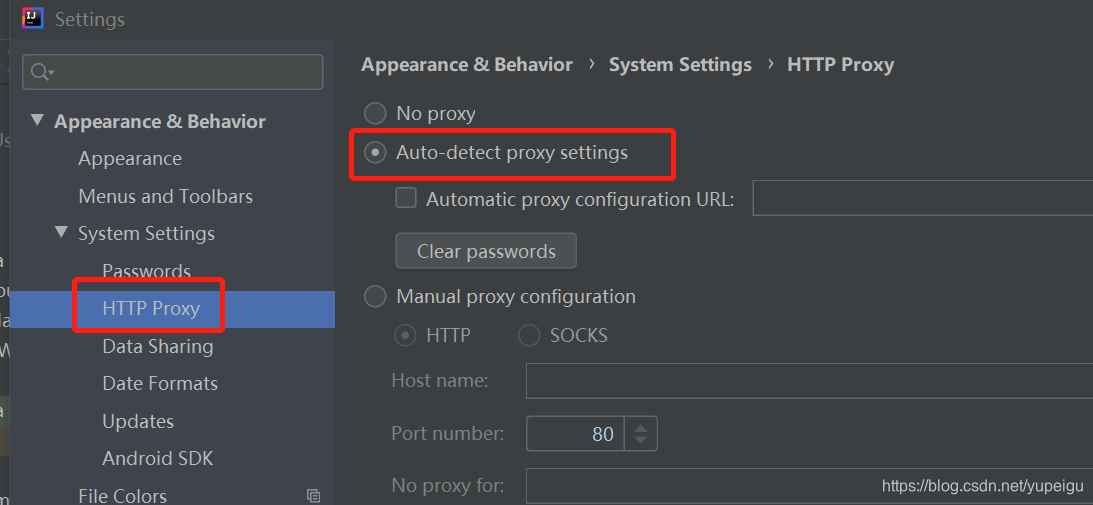
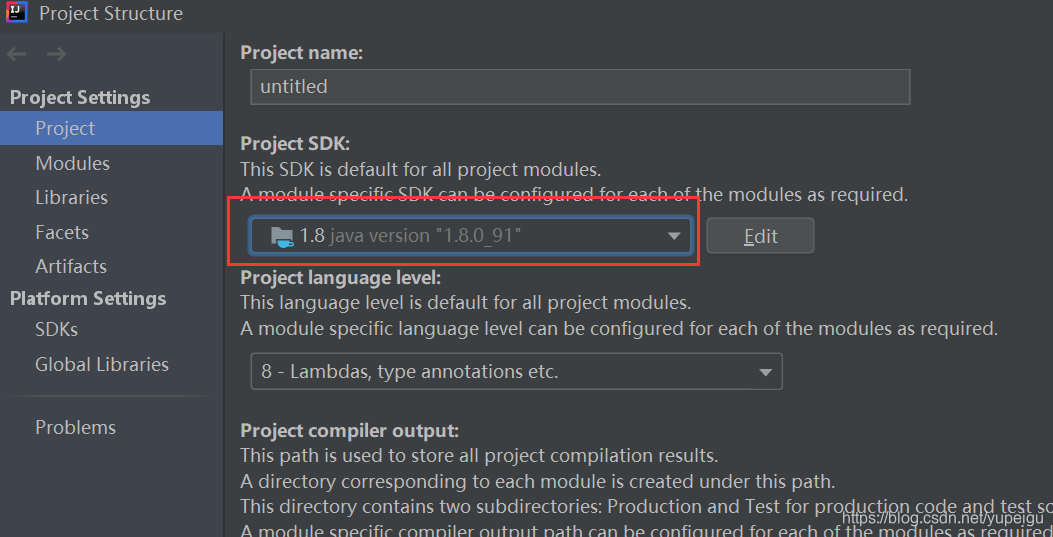
?3、配置java、scala、maven
通过菜单 File -》Project Structure 进入页面进行设置:
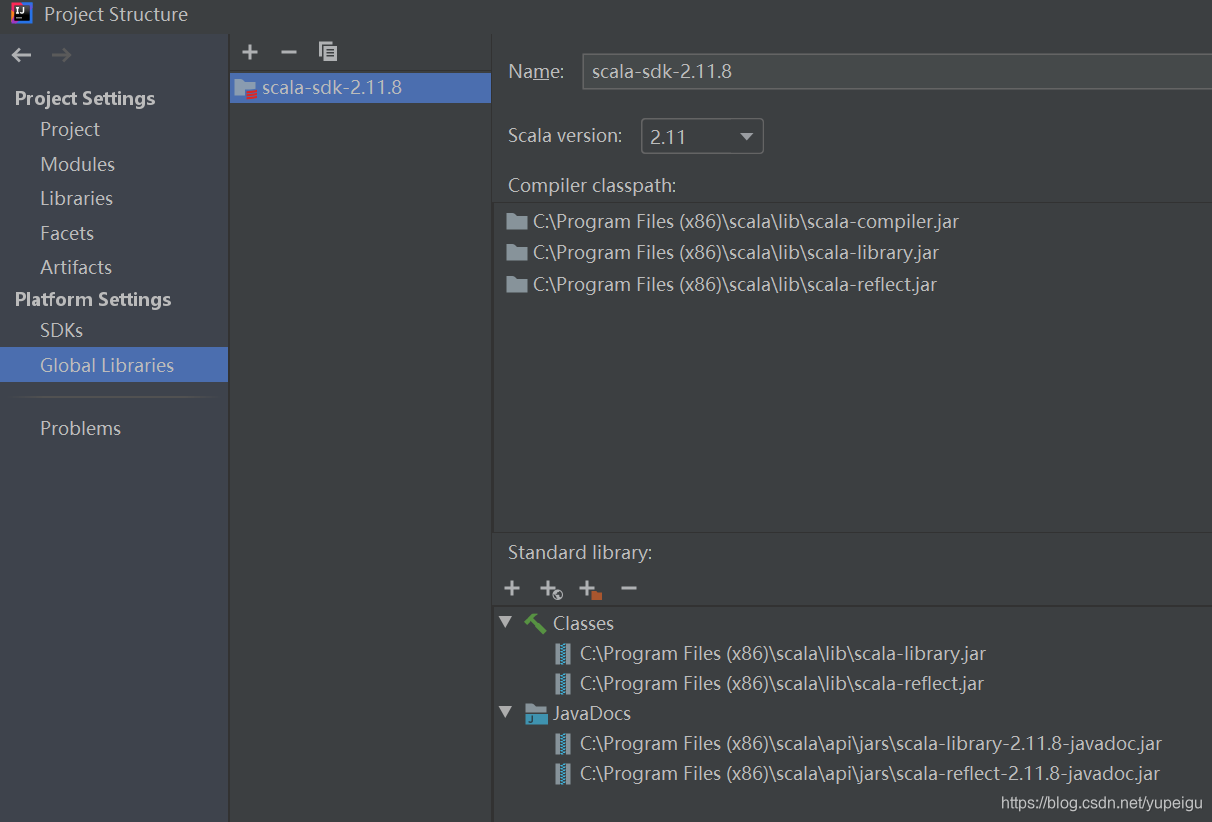
?Global Libraries 点击 + 号,选择 Scala SDK:
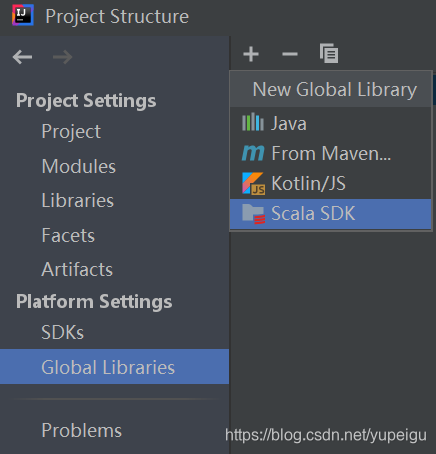
?
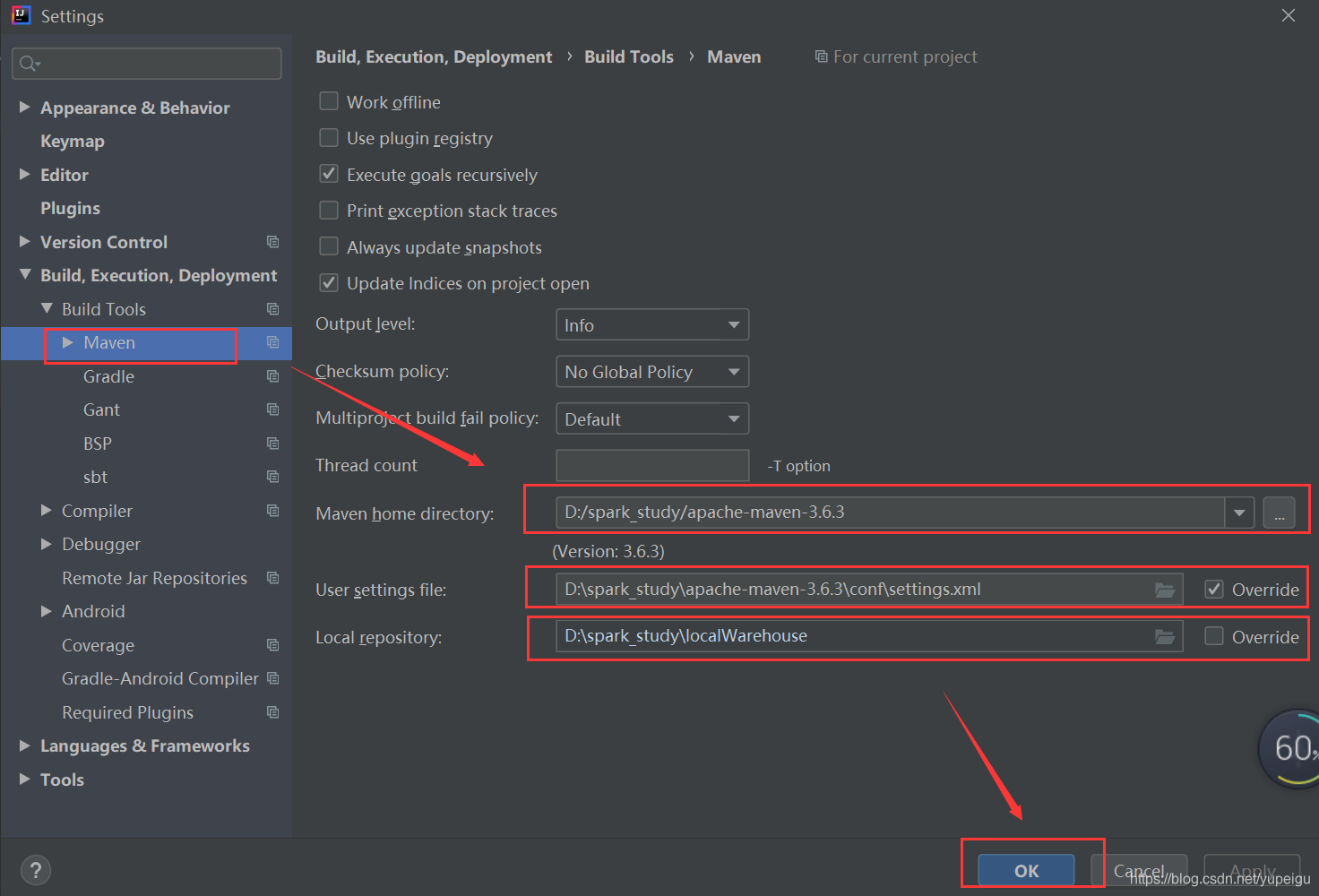
通过菜单 File-》Settings -》?Build,Exection,Deployment -》?Build Tools -》?Maven进入页面,要修改?Maven home directory,User settings file,Local repository,最后点击 OK 保存。
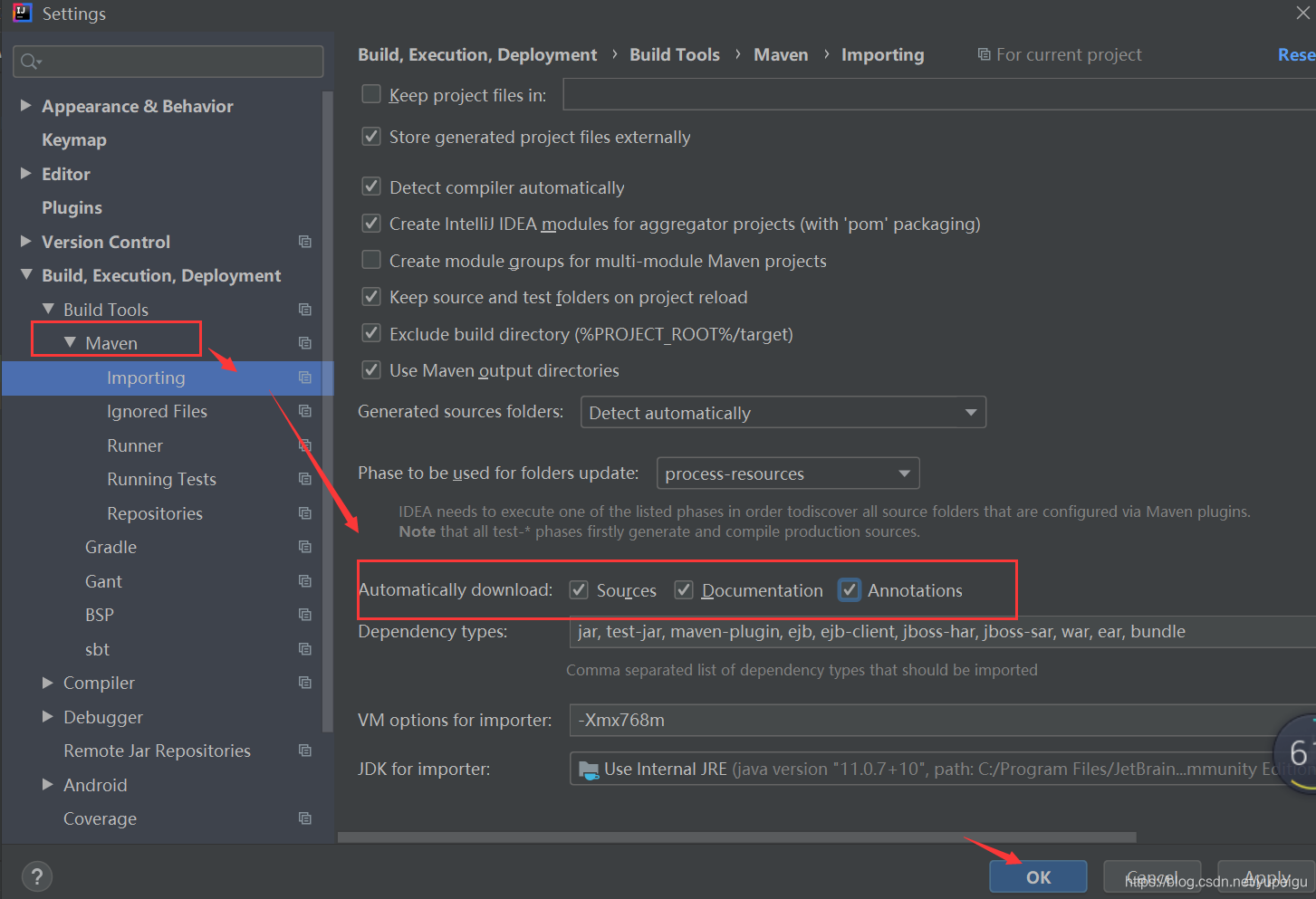
?然后 继续点击 Maven 左侧的向右的三角形,展开子菜单,点击 Importing ,再勾选 红色框的3个 复选框,点击 OK 保存。
四、intellij idea中新建项目
File -》New -》Project,注意 不要勾选 “Create from archetype”,因为?scala-archetype-simple:1.2 版本太低,会有很多问题。?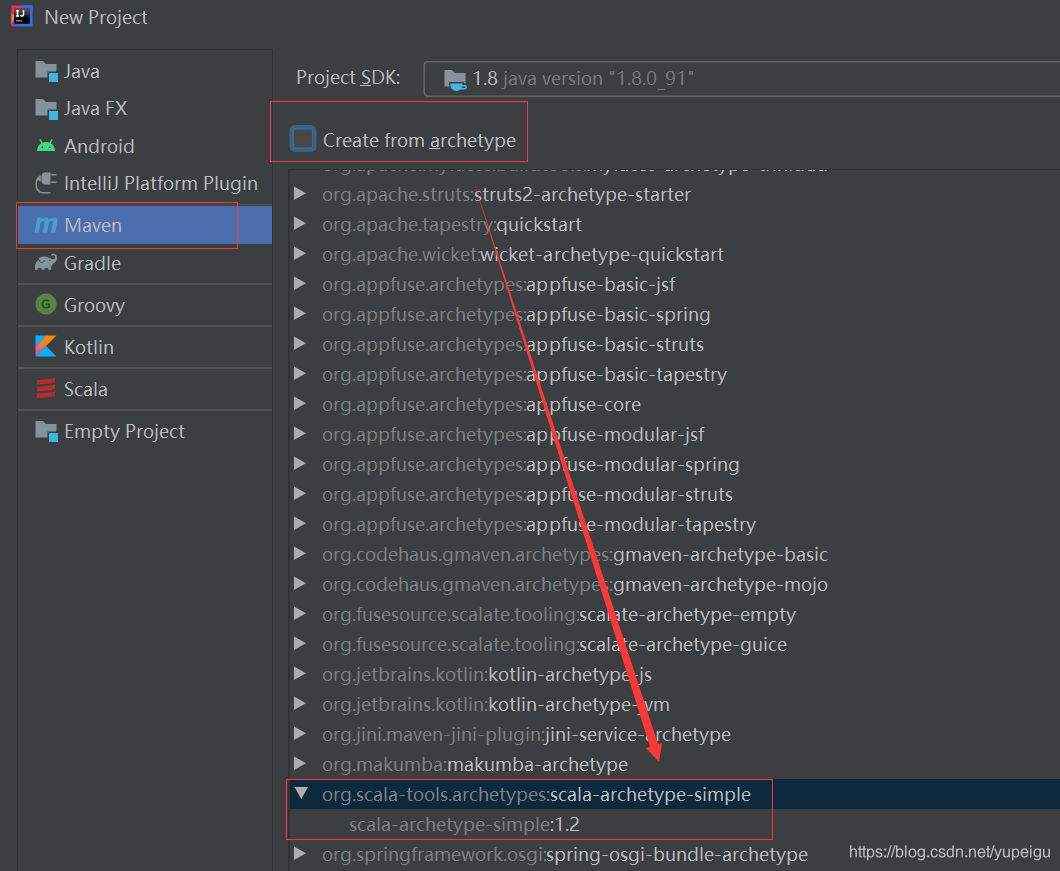
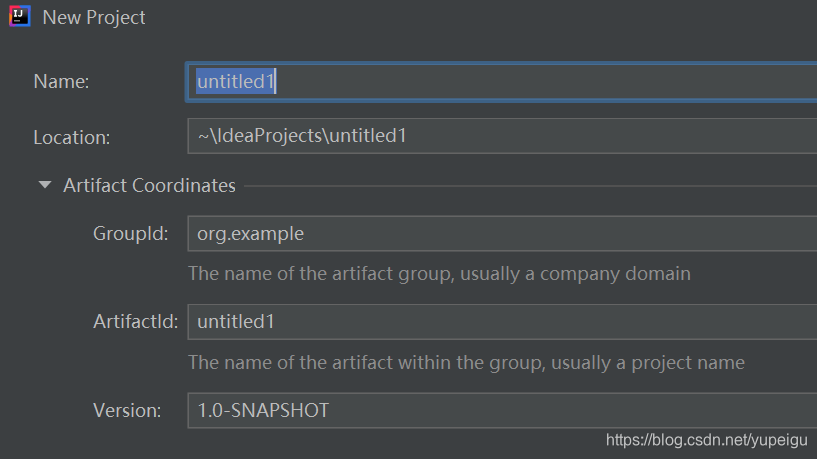
项目名称 都按照默认,没有修改,最后点击 Finish :
?修改pom.xml文件,在 </project> 前面增加 依赖项:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
<scope>${scope.flag}</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
<scope>${scope.flag}</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>${scope.flag}</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<scalaCompatVersion>${scala.binary.version}</scalaCompatVersion>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
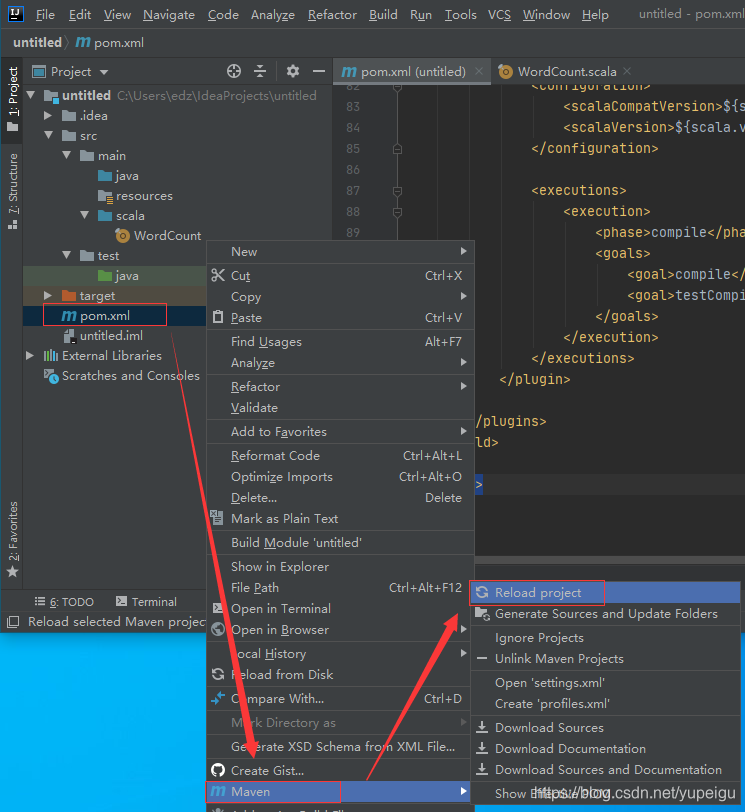
然后 右键项目中的 pom.xml 文件 -》Maven -》reload project 下载依赖包:
?五、编写WordCount代码
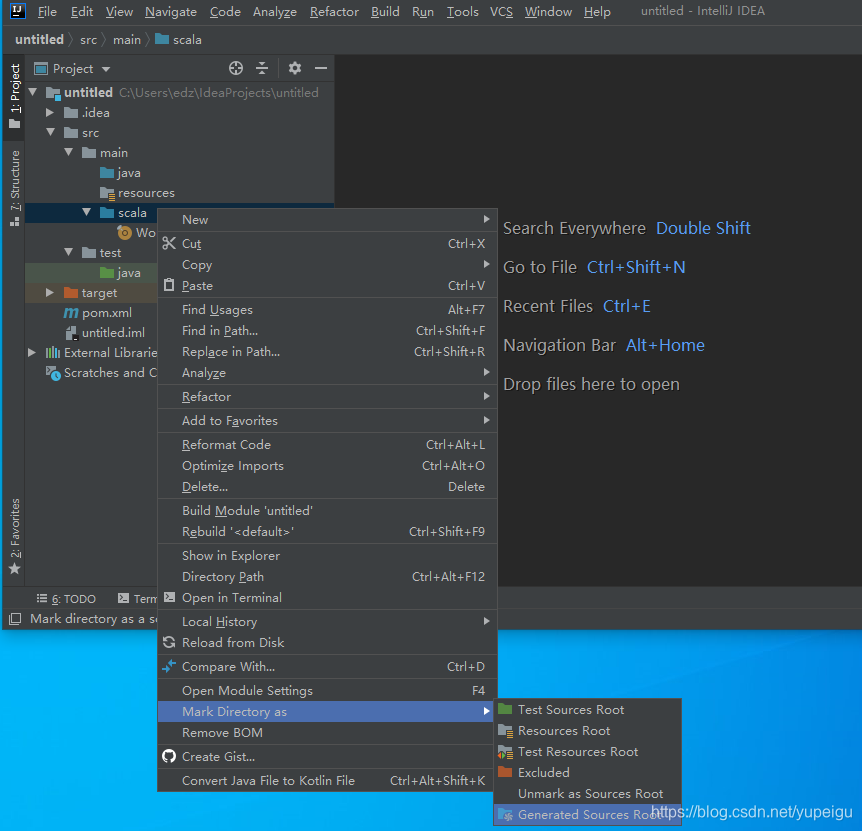
右键 Main 目录 -》 New -》 Directory ,目录名称为: scala
右键 scala 目录 -》Make Directory as -》Generate Sources Root
?右键 scala 目录-》New -》scala class -》 object ,名称为:WordCount
输入代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "D:\\spark_study\\wordcount.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
在D盘的 spark_study 目录下创建文件 wordcount.txt,在上面程序中会引用这个文件(以空格来分隔单词),内容如下:
spark sparkstreaming flink hadoop hbase kafka redis hadoop spark flink clickhouse右键 WordCount ,选择 Run test ,运行结果如下:
"C:\Program Files\Java\jdk1.8.0_91\bin\java.exe" "-javaagent:C:\Program Files\JetBrains\IntelliJ IDEA Community Edition 2020.1.4\lib\idea_rt.jar=52207:C:\Program Files\JetBrains\IntelliJ IDEA Community Edition 2020.1.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_91\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_91\jre\lib\rt.jar;C:\Users\edz\IdeaProjects\untitled\target\classes;C:\Program Files (x86)\scala\lib\scala-library.jar;C:\Program Files (x86)\scala\lib\scala-reflect.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-core_2.11\2.3.0\spark-core_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\apache\avro\avro\1.7.7\avro-1.7.7.jar;D:\spark_study\localWarehouse\org\codehaus\jackson\jackson-core-asl\1.9.13\jackson-core-asl-1.9.13.jar;D:\spark_study\localWarehouse\com\thoughtworks\paranamer\paranamer\2.3\paranamer-2.3.jar;D:\spark_study\localWarehouse\org\apache\commons\commons-compress\1.4.1\commons-compress-1.4.1.jar;D:\spark_study\localWarehouse\org\tukaani\xz\1.0\xz-1.0.jar;D:\spark_study\localWarehouse\org\apache\avro\avro-mapred\1.7.7\avro-mapred-1.7.7-hadoop2.jar;D:\spark_study\localWarehouse\org\apache\avro\avro-ipc\1.7.7\avro-ipc-1.7.7.jar;D:\spark_study\localWarehouse\org\apache\avro\avro-ipc\1.7.7\avro-ipc-1.7.7-tests.jar;D:\spark_study\localWarehouse\com\twitter\chill_2.11\0.8.4\chill_2.11-0.8.4.jar;D:\spark_study\localWarehouse\com\esotericsoftware\kryo-shaded\3.0.3\kryo-shaded-3.0.3.jar;D:\spark_study\localWarehouse\com\esotericsoftware\minlog\1.3.0\minlog-1.3.0.jar;D:\spark_study\localWarehouse\org\objenesis\objenesis\2.1\objenesis-2.1.jar;D:\spark_study\localWarehouse\com\twitter\chill-java\0.8.4\chill-java-0.8.4.jar;D:\spark_study\localWarehouse\org\apache\xbean\xbean-asm5-shaded\4.4\xbean-asm5-shaded-4.4.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-client\2.6.5\hadoop-client-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-common\2.6.5\hadoop-common-2.6.5.jar;D:\spark_study\localWarehouse\xmlenc\xmlenc\0.52\xmlenc-0.52.jar;D:\spark_study\localWarehouse\commons-collections\commons-collections\3.2.2\commons-collections-3.2.2.jar;D:\spark_study\localWarehouse\commons-configuration\commons-configuration\1.6\commons-configuration-1.6.jar;D:\spark_study\localWarehouse\commons-digester\commons-digester\1.8\commons-digester-1.8.jar;D:\spark_study\localWarehouse\commons-beanutils\commons-beanutils\1.7.0\commons-beanutils-1.7.0.jar;D:\spark_study\localWarehouse\commons-beanutils\commons-beanutils-core\1.8.0\commons-beanutils-core-1.8.0.jar;D:\spark_study\localWarehouse\com\google\code\gson\gson\2.2.4\gson-2.2.4.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-auth\2.6.5\hadoop-auth-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\directory\server\apacheds-kerberos-codec\2.0.0-M15\apacheds-kerberos-codec-2.0.0-M15.jar;D:\spark_study\localWarehouse\org\apache\directory\server\apacheds-i18n\2.0.0-M15\apacheds-i18n-2.0.0-M15.jar;D:\spark_study\localWarehouse\org\apache\directory\api\api-asn1-api\1.0.0-M20\api-asn1-api-1.0.0-M20.jar;D:\spark_study\localWarehouse\org\apache\directory\api\api-util\1.0.0-M20\api-util-1.0.0-M20.jar;D:\spark_study\localWarehouse\org\apache\curator\curator-client\2.6.0\curator-client-2.6.0.jar;D:\spark_study\localWarehouse\org\htrace\htrace-core\3.0.4\htrace-core-3.0.4.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-hdfs\2.6.5\hadoop-hdfs-2.6.5.jar;D:\spark_study\localWarehouse\org\mortbay\jetty\jetty-util\6.1.26\jetty-util-6.1.26.jar;D:\spark_study\localWarehouse\xerces\xercesImpl\2.9.1\xercesImpl-2.9.1.jar;D:\spark_study\localWarehouse\xml-apis\xml-apis\1.3.04\xml-apis-1.3.04.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-mapreduce-client-app\2.6.5\hadoop-mapreduce-client-app-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-mapreduce-client-common\2.6.5\hadoop-mapreduce-client-common-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-yarn-client\2.6.5\hadoop-yarn-client-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-yarn-server-common\2.6.5\hadoop-yarn-server-common-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-mapreduce-client-shuffle\2.6.5\hadoop-mapreduce-client-shuffle-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-yarn-api\2.6.5\hadoop-yarn-api-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-mapreduce-client-core\2.6.5\hadoop-mapreduce-client-core-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-yarn-common\2.6.5\hadoop-yarn-common-2.6.5.jar;D:\spark_study\localWarehouse\javax\xml\bind\jaxb-api\2.2.2\jaxb-api-2.2.2.jar;D:\spark_study\localWarehouse\javax\xml\stream\stax-api\1.0-2\stax-api-1.0-2.jar;D:\spark_study\localWarehouse\org\codehaus\jackson\jackson-jaxrs\1.9.13\jackson-jaxrs-1.9.13.jar;D:\spark_study\localWarehouse\org\codehaus\jackson\jackson-xc\1.9.13\jackson-xc-1.9.13.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-mapreduce-client-jobclient\2.6.5\hadoop-mapreduce-client-jobclient-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\hadoop\hadoop-annotations\2.6.5\hadoop-annotations-2.6.5.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-launcher_2.11\2.3.0\spark-launcher_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-kvstore_2.11\2.3.0\spark-kvstore_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\fusesource\leveldbjni\leveldbjni-all\1.8\leveldbjni-all-1.8.jar;D:\spark_study\localWarehouse\com\fasterxml\jackson\core\jackson-core\2.6.7\jackson-core-2.6.7.jar;D:\spark_study\localWarehouse\com\fasterxml\jackson\core\jackson-annotations\2.6.7\jackson-annotations-2.6.7.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-network-common_2.11\2.3.0\spark-network-common_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-network-shuffle_2.11\2.3.0\spark-network-shuffle_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-unsafe_2.11\2.3.0\spark-unsafe_2.11-2.3.0.jar;D:\spark_study\localWarehouse\net\java\dev\jets3t\jets3t\0.9.4\jets3t-0.9.4.jar;D:\spark_study\localWarehouse\org\apache\httpcomponents\httpcore\4.4.1\httpcore-4.4.1.jar;D:\spark_study\localWarehouse\javax\activation\activation\1.1.1\activation-1.1.1.jar;D:\spark_study\localWarehouse\org\bouncycastle\bcprov-jdk15on\1.52\bcprov-jdk15on-1.52.jar;D:\spark_study\localWarehouse\com\jamesmurty\utils\java-xmlbuilder\1.1\java-xmlbuilder-1.1.jar;D:\spark_study\localWarehouse\net\iharder\base64\2.3.8\base64-2.3.8.jar;D:\spark_study\localWarehouse\org\apache\curator\curator-recipes\2.6.0\curator-recipes-2.6.0.jar;D:\spark_study\localWarehouse\org\apache\curator\curator-framework\2.6.0\curator-framework-2.6.0.jar;D:\spark_study\localWarehouse\org\apache\zookeeper\zookeeper\3.4.6\zookeeper-3.4.6.jar;D:\spark_study\localWarehouse\com\google\guava\guava\16.0.1\guava-16.0.1.jar;D:\spark_study\localWarehouse\javax\servlet\javax.servlet-api\3.1.0\javax.servlet-api-3.1.0.jar;D:\spark_study\localWarehouse\org\apache\commons\commons-lang3\3.5\commons-lang3-3.5.jar;D:\spark_study\localWarehouse\org\apache\commons\commons-math3\3.4.1\commons-math3-3.4.1.jar;D:\spark_study\localWarehouse\com\google\code\findbugs\jsr305\1.3.9\jsr305-1.3.9.jar;D:\spark_study\localWarehouse\org\slf4j\slf4j-api\1.7.16\slf4j-api-1.7.16.jar;D:\spark_study\localWarehouse\org\slf4j\jul-to-slf4j\1.7.16\jul-to-slf4j-1.7.16.jar;D:\spark_study\localWarehouse\org\slf4j\jcl-over-slf4j\1.7.16\jcl-over-slf4j-1.7.16.jar;D:\spark_study\localWarehouse\log4j\log4j\1.2.17\log4j-1.2.17.jar;D:\spark_study\localWarehouse\org\slf4j\slf4j-log4j12\1.7.16\slf4j-log4j12-1.7.16.jar;D:\spark_study\localWarehouse\com\ning\compress-lzf\1.0.3\compress-lzf-1.0.3.jar;D:\spark_study\localWarehouse\org\xerial\snappy\snappy-java\1.1.2.6\snappy-java-1.1.2.6.jar;D:\spark_study\localWarehouse\org\lz4\lz4-java\1.4.0\lz4-java-1.4.0.jar;D:\spark_study\localWarehouse\com\github\luben\zstd-jni\1.3.2-2\zstd-jni-1.3.2-2.jar;D:\spark_study\localWarehouse\org\roaringbitmap\RoaringBitmap\0.5.11\RoaringBitmap-0.5.11.jar;D:\spark_study\localWarehouse\commons-net\commons-net\2.2\commons-net-2.2.jar;D:\spark_study\localWarehouse\org\json4s\json4s-jackson_2.11\3.2.11\json4s-jackson_2.11-3.2.11.jar;D:\spark_study\localWarehouse\org\json4s\json4s-core_2.11\3.2.11\json4s-core_2.11-3.2.11.jar;D:\spark_study\localWarehouse\org\json4s\json4s-ast_2.11\3.2.11\json4s-ast_2.11-3.2.11.jar;D:\spark_study\localWarehouse\org\scala-lang\scalap\2.11.0\scalap-2.11.0.jar;D:\spark_study\localWarehouse\org\glassfish\jersey\core\jersey-client\2.22.2\jersey-client-2.22.2.jar;D:\spark_study\localWarehouse\javax\ws\rs\javax.ws.rs-api\2.0.1\javax.ws.rs-api-2.0.1.jar;D:\spark_study\localWarehouse\org\glassfish\hk2\hk2-api\2.4.0-b34\hk2-api-2.4.0-b34.jar;D:\spark_study\localWarehouse\org\glassfish\hk2\hk2-utils\2.4.0-b34\hk2-utils-2.4.0-b34.jar;D:\spark_study\localWarehouse\org\glassfish\hk2\external\aopalliance-repackaged\2.4.0-b34\aopalliance-repackaged-2.4.0-b34.jar;D:\spark_study\localWarehouse\org\glassfish\hk2\external\javax.inject\2.4.0-b34\javax.inject-2.4.0-b34.jar;D:\spark_study\localWarehouse\org\glassfish\hk2\hk2-locator\2.4.0-b34\hk2-locator-2.4.0-b34.jar;D:\spark_study\localWarehouse\org\javassist\javassist\3.18.1-GA\javassist-3.18.1-GA.jar;D:\spark_study\localWarehouse\org\glassfish\jersey\core\jersey-common\2.22.2\jersey-common-2.22.2.jar;D:\spark_study\localWarehouse\javax\annotation\javax.annotation-api\1.2\javax.annotation-api-1.2.jar;D:\spark_study\localWarehouse\org\glassfish\jersey\bundles\repackaged\jersey-guava\2.22.2\jersey-guava-2.22.2.jar;D:\spark_study\localWarehouse\org\glassfish\hk2\osgi-resource-locator\1.0.1\osgi-resource-locator-1.0.1.jar;D:\spark_study\localWarehouse\org\glassfish\jersey\core\jersey-server\2.22.2\jersey-server-2.22.2.jar;D:\spark_study\localWarehouse\org\glassfish\jersey\media\jersey-media-jaxb\2.22.2\jersey-media-jaxb-2.22.2.jar;D:\spark_study\localWarehouse\javax\validation\validation-api\1.1.0.Final\validation-api-1.1.0.Final.jar;D:\spark_study\localWarehouse\org\glassfish\jersey\containers\jersey-container-servlet\2.22.2\jersey-container-servlet-2.22.2.jar;D:\spark_study\localWarehouse\org\glassfish\jersey\containers\jersey-container-servlet-core\2.22.2\jersey-container-servlet-core-2.22.2.jar;D:\spark_study\localWarehouse\io\netty\netty-all\4.1.17.Final\netty-all-4.1.17.Final.jar;D:\spark_study\localWarehouse\io\netty\netty\3.9.9.Final\netty-3.9.9.Final.jar;D:\spark_study\localWarehouse\com\clearspring\analytics\stream\2.7.0\stream-2.7.0.jar;D:\spark_study\localWarehouse\io\dropwizard\metrics\metrics-core\3.1.5\metrics-core-3.1.5.jar;D:\spark_study\localWarehouse\io\dropwizard\metrics\metrics-jvm\3.1.5\metrics-jvm-3.1.5.jar;D:\spark_study\localWarehouse\io\dropwizard\metrics\metrics-json\3.1.5\metrics-json-3.1.5.jar;D:\spark_study\localWarehouse\io\dropwizard\metrics\metrics-graphite\3.1.5\metrics-graphite-3.1.5.jar;D:\spark_study\localWarehouse\com\fasterxml\jackson\core\jackson-databind\2.6.7.1\jackson-databind-2.6.7.1.jar;D:\spark_study\localWarehouse\com\fasterxml\jackson\module\jackson-module-scala_2.11\2.6.7.1\jackson-module-scala_2.11-2.6.7.1.jar;D:\spark_study\localWarehouse\com\fasterxml\jackson\module\jackson-module-paranamer\2.7.9\jackson-module-paranamer-2.7.9.jar;D:\spark_study\localWarehouse\org\apache\ivy\ivy\2.4.0\ivy-2.4.0.jar;D:\spark_study\localWarehouse\oro\oro\2.0.8\oro-2.0.8.jar;D:\spark_study\localWarehouse\net\razorvine\pyrolite\4.13\pyrolite-4.13.jar;D:\spark_study\localWarehouse\net\sf\py4j\py4j\0.10.6\py4j-0.10.6.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-tags_2.11\2.3.0\spark-tags_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\apache\commons\commons-crypto\1.0.0\commons-crypto-1.0.0.jar;D:\spark_study\localWarehouse\org\spark-project\spark\unused\1.0.0\unused-1.0.0.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-streaming_2.11\2.3.0\spark-streaming_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-sql_2.11\2.3.0\spark-sql_2.11-2.3.0.jar;D:\spark_study\localWarehouse\com\univocity\univocity-parsers\2.5.9\univocity-parsers-2.5.9.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-sketch_2.11\2.3.0\spark-sketch_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-catalyst_2.11\2.3.0\spark-catalyst_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\codehaus\janino\janino\3.0.8\janino-3.0.8.jar;D:\spark_study\localWarehouse\org\codehaus\janino\commons-compiler\3.0.8\commons-compiler-3.0.8.jar;D:\spark_study\localWarehouse\org\antlr\antlr4-runtime\4.7\antlr4-runtime-4.7.jar;D:\spark_study\localWarehouse\org\apache\orc\orc-core\1.4.1\orc-core-1.4.1-nohive.jar;D:\spark_study\localWarehouse\com\google\protobuf\protobuf-java\2.5.0\protobuf-java-2.5.0.jar;D:\spark_study\localWarehouse\commons-lang\commons-lang\2.6\commons-lang-2.6.jar;D:\spark_study\localWarehouse\io\airlift\aircompressor\0.8\aircompressor-0.8.jar;D:\spark_study\localWarehouse\org\apache\orc\orc-mapreduce\1.4.1\orc-mapreduce-1.4.1-nohive.jar;D:\spark_study\localWarehouse\org\apache\parquet\parquet-column\1.8.2\parquet-column-1.8.2.jar;D:\spark_study\localWarehouse\org\apache\parquet\parquet-common\1.8.2\parquet-common-1.8.2.jar;D:\spark_study\localWarehouse\org\apache\parquet\parquet-encoding\1.8.2\parquet-encoding-1.8.2.jar;D:\spark_study\localWarehouse\org\apache\parquet\parquet-hadoop\1.8.2\parquet-hadoop-1.8.2.jar;D:\spark_study\localWarehouse\org\apache\parquet\parquet-format\2.3.1\parquet-format-2.3.1.jar;D:\spark_study\localWarehouse\org\apache\parquet\parquet-jackson\1.8.2\parquet-jackson-1.8.2.jar;D:\spark_study\localWarehouse\org\apache\arrow\arrow-vector\0.8.0\arrow-vector-0.8.0.jar;D:\spark_study\localWarehouse\org\apache\arrow\arrow-format\0.8.0\arrow-format-0.8.0.jar;D:\spark_study\localWarehouse\org\apache\arrow\arrow-memory\0.8.0\arrow-memory-0.8.0.jar;D:\spark_study\localWarehouse\com\carrotsearch\hppc\0.7.2\hppc-0.7.2.jar;D:\spark_study\localWarehouse\com\vlkan\flatbuffers\1.2.0-3f79e055\flatbuffers-1.2.0-3f79e055.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-hive_2.11\2.3.0\spark-hive_2.11-2.3.0.jar;D:\spark_study\localWarehouse\com\twitter\parquet-hadoop-bundle\1.6.0\parquet-hadoop-bundle-1.6.0.jar;D:\spark_study\localWarehouse\org\spark-project\hive\hive-exec\1.2.1.spark2\hive-exec-1.2.1.spark2.jar;D:\spark_study\localWarehouse\commons-io\commons-io\2.4\commons-io-2.4.jar;D:\spark_study\localWarehouse\javolution\javolution\5.5.1\javolution-5.5.1.jar;D:\spark_study\localWarehouse\log4j\apache-log4j-extras\1.2.17\apache-log4j-extras-1.2.17.jar;D:\spark_study\localWarehouse\org\antlr\antlr-runtime\3.4\antlr-runtime-3.4.jar;D:\spark_study\localWarehouse\org\antlr\stringtemplate\3.2.1\stringtemplate-3.2.1.jar;D:\spark_study\localWarehouse\antlr\antlr\2.7.7\antlr-2.7.7.jar;D:\spark_study\localWarehouse\org\antlr\ST4\4.0.4\ST4-4.0.4.jar;D:\spark_study\localWarehouse\com\googlecode\javaewah\JavaEWAH\0.3.2\JavaEWAH-0.3.2.jar;D:\spark_study\localWarehouse\org\iq80\snappy\snappy\0.2\snappy-0.2.jar;D:\spark_study\localWarehouse\stax\stax-api\1.0.1\stax-api-1.0.1.jar;D:\spark_study\localWarehouse\net\sf\opencsv\opencsv\2.3\opencsv-2.3.jar;D:\spark_study\localWarehouse\org\spark-project\hive\hive-metastore\1.2.1.spark2\hive-metastore-1.2.1.spark2.jar;D:\spark_study\localWarehouse\com\jolbox\bonecp\0.8.0.RELEASE\bonecp-0.8.0.RELEASE.jar;D:\spark_study\localWarehouse\commons-cli\commons-cli\1.2\commons-cli-1.2.jar;D:\spark_study\localWarehouse\commons-logging\commons-logging\1.1.3\commons-logging-1.1.3.jar;D:\spark_study\localWarehouse\org\datanucleus\datanucleus-api-jdo\3.2.6\datanucleus-api-jdo-3.2.6.jar;D:\spark_study\localWarehouse\org\datanucleus\datanucleus-rdbms\3.2.9\datanucleus-rdbms-3.2.9.jar;D:\spark_study\localWarehouse\commons-pool\commons-pool\1.5.4\commons-pool-1.5.4.jar;D:\spark_study\localWarehouse\commons-dbcp\commons-dbcp\1.4\commons-dbcp-1.4.jar;D:\spark_study\localWarehouse\javax\jdo\jdo-api\3.0.1\jdo-api-3.0.1.jar;D:\spark_study\localWarehouse\javax\transaction\jta\1.1\jta-1.1.jar;D:\spark_study\localWarehouse\commons-httpclient\commons-httpclient\3.1\commons-httpclient-3.1.jar;D:\spark_study\localWarehouse\org\apache\calcite\calcite-avatica\1.2.0-incubating\calcite-avatica-1.2.0-incubating.jar;D:\spark_study\localWarehouse\org\apache\calcite\calcite-core\1.2.0-incubating\calcite-core-1.2.0-incubating.jar;D:\spark_study\localWarehouse\org\apache\calcite\calcite-linq4j\1.2.0-incubating\calcite-linq4j-1.2.0-incubating.jar;D:\spark_study\localWarehouse\net\hydromatic\eigenbase-properties\1.1.5\eigenbase-properties-1.1.5.jar;D:\spark_study\localWarehouse\org\apache\httpcomponents\httpclient\4.5.4\httpclient-4.5.4.jar;D:\spark_study\localWarehouse\org\codehaus\jackson\jackson-mapper-asl\1.9.13\jackson-mapper-asl-1.9.13.jar;D:\spark_study\localWarehouse\commons-codec\commons-codec\1.10\commons-codec-1.10.jar;D:\spark_study\localWarehouse\joda-time\joda-time\2.9.3\joda-time-2.9.3.jar;D:\spark_study\localWarehouse\org\jodd\jodd-core\3.5.2\jodd-core-3.5.2.jar;D:\spark_study\localWarehouse\org\datanucleus\datanucleus-core\3.2.10\datanucleus-core-3.2.10.jar;D:\spark_study\localWarehouse\org\apache\thrift\libthrift\0.9.3\libthrift-0.9.3.jar;D:\spark_study\localWarehouse\org\apache\thrift\libfb303\0.9.3\libfb303-0.9.3.jar;D:\spark_study\localWarehouse\org\apache\derby\derby\10.12.1.1\derby-10.12.1.1.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-mllib_2.11\2.3.0\spark-mllib_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\scala-lang\modules\scala-parser-combinators_2.11\1.0.4\scala-parser-combinators_2.11-1.0.4.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-graphx_2.11\2.3.0\spark-graphx_2.11-2.3.0.jar;D:\spark_study\localWarehouse\com\github\fommil\netlib\core\1.1.2\core-1.1.2.jar;D:\spark_study\localWarehouse\net\sourceforge\f2j\arpack_combined_all\0.1\arpack_combined_all-0.1.jar;D:\spark_study\localWarehouse\org\apache\spark\spark-mllib-local_2.11\2.3.0\spark-mllib-local_2.11-2.3.0.jar;D:\spark_study\localWarehouse\org\scalanlp\breeze_2.11\0.13.2\breeze_2.11-0.13.2.jar;D:\spark_study\localWarehouse\org\scalanlp\breeze-macros_2.11\0.13.2\breeze-macros_2.11-0.13.2.jar;D:\spark_study\localWarehouse\com\github\rwl\jtransforms\2.4.0\jtransforms-2.4.0.jar;D:\spark_study\localWarehouse\org\spire-math\spire_2.11\0.13.0\spire_2.11-0.13.0.jar;D:\spark_study\localWarehouse\org\spire-math\spire-macros_2.11\0.13.0\spire-macros_2.11-0.13.0.jar;D:\spark_study\localWarehouse\org\typelevel\machinist_2.11\0.6.1\machinist_2.11-0.6.1.jar;D:\spark_study\localWarehouse\com\chuusai\shapeless_2.11\2.3.2\shapeless_2.11-2.3.2.jar;D:\spark_study\localWarehouse\org\typelevel\macro-compat_2.11\1.1.1\macro-compat_2.11-1.1.1.jar;D:\spark_study\localWarehouse\org\scala-lang\scala-reflect\2.11.8\scala-reflect-2.11.8.jar;D:\spark_study\localWarehouse\org\scala-lang\scala-compiler\2.11.8\scala-compiler-2.11.8.jar;D:\spark_study\localWarehouse\org\scala-lang\modules\scala-xml_2.11\1.0.4\scala-xml_2.11-1.0.4.jar;D:\spark_study\localWarehouse\org\scala-lang\scala-library\2.11.8\scala-library-2.11.8.jar" WordCount
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/07/23 13:47:46 INFO SparkContext: Running Spark version 2.3.0
21/07/23 13:47:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/07/23 13:47:46 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:378)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:393)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:386)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116)
at org.apache.hadoop.security.Groups.<init>(Groups.java:93)
at org.apache.hadoop.security.Groups.<init>(Groups.java:73)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:283)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:789)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:774)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:647)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2464)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:292)
at WordCount$.main(WordCount.scala:9)
at WordCount.main(WordCount.scala)
21/07/23 13:47:46 INFO SparkContext: Submitted application: WordCount
21/07/23 13:47:46 INFO SecurityManager: Changing view acls to: edz
21/07/23 13:47:46 INFO SecurityManager: Changing modify acls to: edz
21/07/23 13:47:46 INFO SecurityManager: Changing view acls groups to:
21/07/23 13:47:46 INFO SecurityManager: Changing modify acls groups to:
21/07/23 13:47:46 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(edz); groups with view permissions: Set(); users with modify permissions: Set(edz); groups with modify permissions: Set()
21/07/23 13:47:48 INFO Utils: Successfully started service 'sparkDriver' on port 52244.
21/07/23 13:47:49 INFO SparkEnv: Registering MapOutputTracker
21/07/23 13:47:49 INFO SparkEnv: Registering BlockManagerMaster
21/07/23 13:47:49 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
21/07/23 13:47:49 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
21/07/23 13:47:49 INFO DiskBlockManager: Created local directory at C:\Users\edz\AppData\Local\Temp\blockmgr-2ef0a030-120a-49aa-ad7e-2da8fdd565d8
21/07/23 13:47:49 INFO MemoryStore: MemoryStore started with capacity 1981.2 MB
21/07/23 13:47:49 INFO SparkEnv: Registering OutputCommitCoordinator
21/07/23 13:47:50 INFO Utils: Successfully started service 'SparkUI' on port 4040.
21/07/23 13:47:50 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://LAPTOP-0VG107DP:4040
21/07/23 13:47:50 INFO Executor: Starting executor ID driver on host localhost
21/07/23 13:47:50 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 52257.
21/07/23 13:47:50 INFO NettyBlockTransferService: Server created on LAPTOP-0VG107DP:52257
21/07/23 13:47:50 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
21/07/23 13:47:50 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, LAPTOP-0VG107DP, 52257, None)
21/07/23 13:47:50 INFO BlockManagerMasterEndpoint: Registering block manager LAPTOP-0VG107DP:52257 with 1981.2 MB RAM, BlockManagerId(driver, LAPTOP-0VG107DP, 52257, None)
21/07/23 13:47:50 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, LAPTOP-0VG107DP, 52257, None)
21/07/23 13:47:50 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, LAPTOP-0VG107DP, 52257, None)
21/07/23 13:47:50 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 214.5 KB, free 1981.0 MB)
21/07/23 13:47:50 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 20.4 KB, free 1981.0 MB)
21/07/23 13:47:50 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on LAPTOP-0VG107DP:52257 (size: 20.4 KB, free: 1981.2 MB)
21/07/23 13:47:50 INFO SparkContext: Created broadcast 0 from textFile at WordCount.scala:10
21/07/23 13:47:51 INFO FileInputFormat: Total input paths to process : 1
21/07/23 13:47:51 INFO SparkContext: Starting job: foreach at WordCount.scala:12
21/07/23 13:47:51 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:11)
21/07/23 13:47:51 INFO DAGScheduler: Got job 0 (foreach at WordCount.scala:12) with 1 output partitions
21/07/23 13:47:51 INFO DAGScheduler: Final stage: ResultStage 1 (foreach at WordCount.scala:12)
21/07/23 13:47:51 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
21/07/23 13:47:51 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
21/07/23 13:47:51 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:11), which has no missing parents
21/07/23 13:47:51 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.7 KB, free 1981.0 MB)
21/07/23 13:47:51 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.8 KB, free 1981.0 MB)
21/07/23 13:47:51 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on LAPTOP-0VG107DP:52257 (size: 2.8 KB, free: 1981.2 MB)
21/07/23 13:47:51 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1039
21/07/23 13:47:51 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:11) (first 15 tasks are for partitions Vector(0))
21/07/23 13:47:51 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
21/07/23 13:47:51 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7870 bytes)
21/07/23 13:47:51 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
21/07/23 13:47:51 INFO HadoopRDD: Input split: file:/D:/spark_study/wordcount.txt:0+81
21/07/23 13:47:51 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1156 bytes result sent to driver
21/07/23 13:47:51 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 263 ms on localhost (executor driver) (1/1)
21/07/23 13:47:51 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
21/07/23 13:47:51 INFO DAGScheduler: ShuffleMapStage 0 (map at WordCount.scala:11) finished in 0.379 s
21/07/23 13:47:51 INFO DAGScheduler: looking for newly runnable stages
21/07/23 13:47:51 INFO DAGScheduler: running: Set()
21/07/23 13:47:51 INFO DAGScheduler: waiting: Set(ResultStage 1)
21/07/23 13:47:51 INFO DAGScheduler: failed: Set()
21/07/23 13:47:51 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:11), which has no missing parents
21/07/23 13:47:51 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.1 KB, free 1981.0 MB)
21/07/23 13:47:51 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1945.0 B, free 1981.0 MB)
21/07/23 13:47:51 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on LAPTOP-0VG107DP:52257 (size: 1945.0 B, free: 1981.2 MB)
21/07/23 13:47:51 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1039
21/07/23 13:47:51 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:11) (first 15 tasks are for partitions Vector(0))
21/07/23 13:47:51 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
21/07/23 13:47:51 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, executor driver, partition 0, ANY, 7649 bytes)
21/07/23 13:47:51 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
21/07/23 13:47:51 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
21/07/23 13:47:51 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 4 ms
(spark,2)
(hadoop,2)
(sparkstreaming,1)
(flink,2)
(kafka,1)
(clickhouse,1)
(redis,1)
(hbase,1)
21/07/23 13:47:51 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1138 bytes result sent to driver
21/07/23 13:47:51 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 48 ms on localhost (executor driver) (1/1)
21/07/23 13:47:51 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
21/07/23 13:47:51 INFO DAGScheduler: ResultStage 1 (foreach at WordCount.scala:12) finished in 0.062 s
21/07/23 13:47:51 INFO DAGScheduler: Job 0 finished: foreach at WordCount.scala:12, took 0.742531 s
21/07/23 13:47:51 INFO SparkContext: Invoking stop() from shutdown hook
21/07/23 13:47:51 INFO SparkUI: Stopped Spark web UI at http://LAPTOP-0VG107DP:4040
21/07/23 13:47:51 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/07/23 13:47:51 INFO MemoryStore: MemoryStore cleared
21/07/23 13:47:51 INFO BlockManager: BlockManager stopped
21/07/23 13:47:51 INFO BlockManagerMaster: BlockManagerMaster stopped
21/07/23 13:47:51 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/07/23 13:47:51 INFO SparkContext: Successfully stopped SparkContext
21/07/23 13:47:51 INFO ShutdownHookManager: Shutdown hook called
21/07/23 13:47:51 INFO ShutdownHookManager: Deleting directory C:\Users\edz\AppData\Local\Temp\spark-4c379c11-3156-4fac-9cef-261adb05a623
Process finished with exit code 0输出大部分都为日志,wordcount的结果是:
(spark,2)
(hadoop,2)
(sparkstreaming,1)
(flink,2)
(kafka,1)
(clickhouse,1)
(redis,1)
(hbase,1)至此,环境配置成功。