hadoop的安装
解压hadoop
[root@hdp01 sbin]# tar -zxvf /opt/software/hadoop-2.7.6.tar.gz -C /opt/apps/
修改配置hadoop-env.sh文件
[root@hdp01 etc]# cd /opt/apps/hadoop-2.7.6/etc/hadoop/
[root@hdp01 hadoop]# vi ./hadoop-env.sh
#在最后面添加java环境
export JAVA_HOME=/opt/apps/jdk/
配置core-site.xml文件
文件中:hangoer为自定义的名字
? hdp01、hdp02、hdp03为对应的虚拟机名字,需要与之对应。
[root@hdp01 hadoop]# vi ./core-site.xml
##配置如下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hangoer</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/apps/hadoop-2.7.6/data/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp01:2181,hdp02:2181,hdp03:2181</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
</configuration>
再配置hdfs-site.xml文件
[root@hdp01 hadoop]# vi ./hdfs-site.xml
##配置如下
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hangoer</value>
</property>
<property>
<name>dfs.ha.namenodes.hangoer</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hangoer.nn1</name>
<value>hdp01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hangoer.nn2</name>
<value>hdp02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hangoer.nn1</name>
<value>hdp01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hangoer.nn2</name>
<value>hdp02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp01:8485;hdp02:8485;hdp03:8485/hangoer</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/apps/hadoop-2.7.6/journalnode</value>
</property>
<property>
<property>
<name>dfs.client.failover.proxy.provider.hangoer</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
再配置yarn-site.xml
[root@hdp01 hadoop]# vi ./yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdp02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdp03</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hdp02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hdp03:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hdp01:2181,hdp02:2181,hdp03:2181</value>
</property>
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>${yarn.nodemanager.hostname}:45454</value>
</property>
</configuration>
再重写mapred-site.xml(记得先将文件mapred-site.xml.template重命名为mapred-site.xml)
mv mapred-site.xml.template ./mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp03:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp03:19888</value>
</property>
</configuration>
修改slaves文件
cd /opt/apps/hadoop-2.7.2/etc/hadoop/
vi slaves
#修改内容如下(一定要将文件内的内容删除)
hdp1
hdp2
hdp3
将hadoop1的配置好的hadoop发送给其他两台机器,准备格式化
scp -r /opt/apps/hadoop-2.7.2/ hadp2:/opt/apps/
scp -r /opt/apps/hadoop-2.7.2/ hadp3:/opt/apps/
启动三台机器上面的zookeeper
cd /opt/apps/zookeeper-3.4.10/bin
./zkServer.sh start
启动三台日志服务器
cd /opt/apps/hadoop-2.7.2/sbin
./hadoop-daemon.sh start journalnode
在第一台hadoop1上格式化namenode
cd /opt/apps/hadoop-2.7.2/bin
./hdfs namenode -format
格式化成功展示:


在格式化的机器hadoop1上启动namenode进程
cd ../sbin
./hadoop-daemon.sh start namenode
机器hadoop2上同步上一步启动的namenode元数据
cd /opt/apps/hadoop-2.7.2/bin
./hdfs namenode -bootstrapStandby

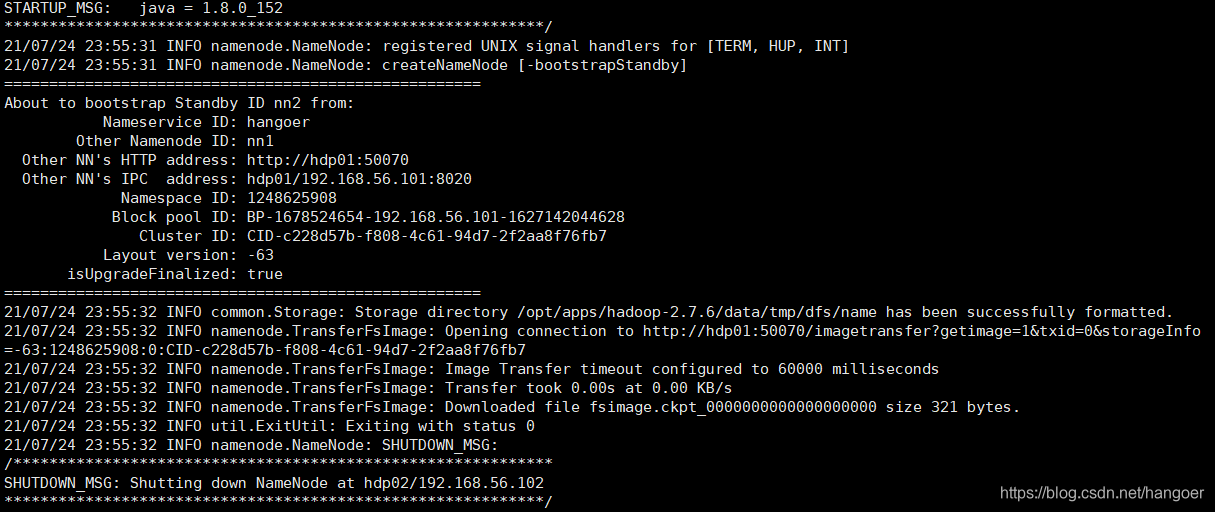
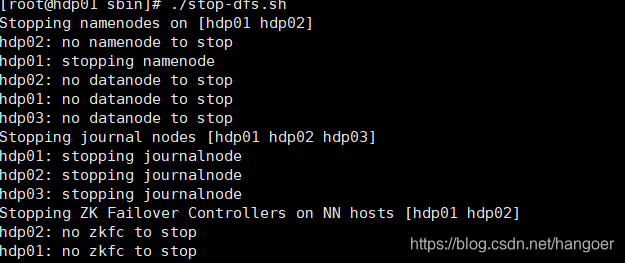
在hadoop1上关闭所有除了zookeeper以外的进程
cd /opt/apps/hadoop-2.7.2/sbin
./stop-dfs.sh
在hadoop1上初始化zkfc
cd ../bin
./hdfs zkfc -formatZK


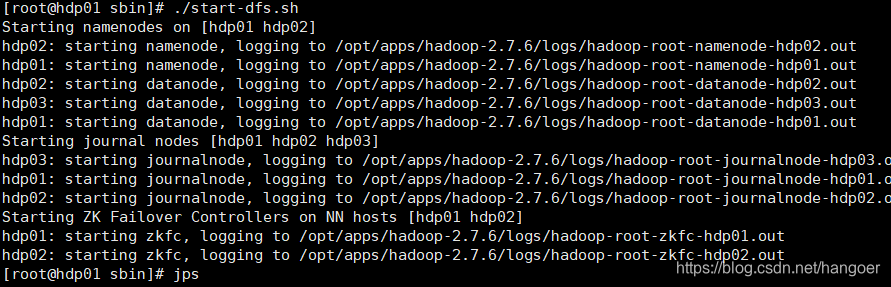
在hadoop1上启动所有进程进行检验
cd ../sbin
./start-dfs.sh
然后在hadoop3上启动yarn框架
./start-yarn.sh

然后在hadoop2上启动resourcemanager
cd /opt/apps/hadoop-2.7.2/sbin
./yarn-daemon.sh start resourcemanager

检查各个机器的进程信息
jps
#hadoop1将有6个进程(除jps外)
#hadoop2将有7个进程(除jps外)
#hadoop3将有5个进程(除jps外)

斜体为zookeeper的节点,加粗为HDFS的节点
然后就可以在浏览器查看各个进程的信息
-
192.168.56.101:50070
-
192.168.56.102:50070
-
192.168.56.102:8088
-
192.168.56.103:8088


Windows与liunxIP地址映射(可加可不加)
路径:C:\Windows\System32\drivers\etc
上面路径下的HOSTS文件中添加;
