һ����װ����ϵͳ������IP
- ��VMware������а�װ��̨Centos7,�ֱ���ΪMaster,Slave1,Slave2,������root�û���
- ������̨�����ľ�̬IP��ַ,����ʾ��IP�ֱ�Ϊ:
Master: 192.168.157.128
Slave1: 192.168.157.129
Slave2: 192.168.157.130
(�������þ�̬ip��������������,https://blog.csdn.net/tearofthemyth/article/details/112800999 Mac VMware Fusion CentOS7���þ�̬IP) - ��������������hosts�ļ�(��̨����)
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
vi /etc/hosts
192.168.157.128 master master.root
192.168.157.129 slave1 slave1.root
192.168.157.130 slave2 slave2.root
�����رշ���ǽ(��̨����)
systemctl stop firewalld #�رշ���ǽ
systemctl status firewalld #�鿴����ǽ״̬
��������ʱ��ͬ��
- �������ú�Masterʱ��,��Master����������tzselect,ѡ��ʱ��,���ΰ���ʾ����5,9,1,1
- yum install �Cy ntp #��̨�����ϰ�װntp
- vi /etc/ntp.conf #Master���������ļ�
server 127.127.1.0
fudge 127.127.1.0 stratum 10 - /bin/systemctl restart ntpd.service #Master������ntp����
- ntpdate master #��Slave1��Slave2����������
�ġ�����SSH����
- ��Master��ִ�����²���:
cd ~
ssh-keygen -t dsa -P ���� -f ~/.ssh/id_dsa
cd .ssh/
cat id_dsa.pub >> authorized_keys #
ssh master #ssh�ڻ�
exit #�dz�
ssh master #�ٴε�½ssh
exit - ��Slave1��Slave2�Ϸֱ�ִ�����²���:
scp master:~/.ssh/id_dsa.pub ./master_dsa.pub
cat master_dsa.pub >> authorized_keys - ��Master��ִ�����²�������֤���ܵ�¼:
ssh slave1
exit
ssh slave2
exit
�塢��װJDK
- ����,����̨�����ϴ���java����Ŀ¼
mkdir -p /usr/java #����java����Ŀ¼(��̨����) - ����̨����������jdk
���²�������master�Ͻ���:
tar -zxvf /home/lan/jdk-8u171-linux-x64.tar.gz -C /usr/java #��ѹ��װ��
cd /usr/java
cd jdk1.8.0.171/
pwd
vi /etc/profile #�Ļ������������ļ�profile
�� export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL ��������:
/usr/java/jdk1.8.0_281
#java
export JAVA_HOME=/usr/java/jdk1.8.0_171
export CLASSPATH=$ JAVA_HOME/lib/
export PATH=$ PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
��ɺ�wq,�˳�����,֮����ִ��:
scp -r /etc/profile slave1:/etc/ #�ַ�����������Slave1��Slave2
scp -r /etc/profile slave2:/etc/
(����ַ�������������Ϊ�˸�slave1��slave2 ������jdk,����Ҫ��סһ��Ҫ��slave1��slave2Ҳ����jdk,���������Ǹ����Ƿַ���������������slave1��slave2�е�jdk������Ч,�����zookeeperҲ�������) - source /etc/profile #ʹ����������Ч(��̨����)
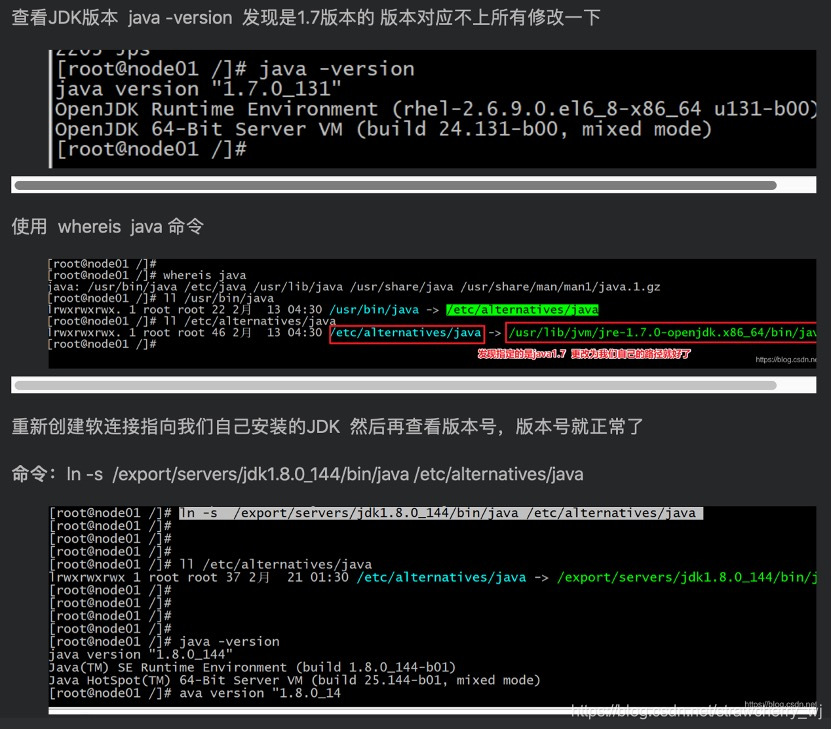
- java -version #�鿴java�汾��
������ֵ�java�汾���п�����������Դ���jdk,��Ҫ�ij������Լ����ص�jdk��
https://blog.csdn.net/dlc_996/article/details/104414585
����Zookeeper��װ
- ����,����̨�����ϴ���zookeeper����Ŀ¼
mkdir -p /usr/zookeeper #����zookeeper����Ŀ¼(��̨����) - ���²�������Master�ϲ���
1)tar -zxvf /home/lan/zookeeper-3.4.10.tar.gz -C /usr/zookeeper #��ѹ
2)cd /usr/zookeeper/zookeeper-3.4.10/conf/
scp zoo_sample.cfg zoo.cfg #����zoo_sample.cfg������Ϊzoo.cfg
3)��������zoo.cft�ļ�(���»��ߵ�Ϊ��Ҫ�Ļ����ӵ�):
#The number of milliseconds of each tick
tickTime=2000
#The number of ticks that the initial
#synchronization phase can take
initLimit=10
#The number of ticks that can pass between
#sending a request and getting an acknowledgement
syncLimit=5
#the directory where the snapshot is stored.
#do not use /tmp for storage, /tmp here is just
#example sakes.
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata
#the port at which the clients will connect
clientPort=2181
#the maximum number of client connections.
#increase this if you need to handle more clients
#maxClientCnxns=60
#
#Be sure to read the maintenance section of the
#administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html
#sc_maintenance
#
#The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
#Purge task interval in hours
#Set to ��0�� to disable auto purge feature
#autopurge.purgeInterval=1
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
4)֮��zookeeper-3.4.10�ļ���,����zkdata��zkdatalog�����ļ��С�
cd ��
mkdir zkdata
mkdir zkdatalog
5)����zkdata�ļ���,�����ļ�myid,���ڱ�ʾ�Ǽ��ŷ�������master������,���÷�����idΪ1:
vi myid
1
6)�������Ļ��������ļ�,��java���ӵ��±�����:
#zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
export PATH=$ PATH:$ZOOKEEPER_HOME/bin
7)�ĺ�,�ַ���Slave1��Slave2��:
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/
scp -r /usr/zookeeper slave1:/usr/zookeeper
scp -r /usr/zookeeper slave2:/usr/zookeeper - ʹ��̨�����Ļ���������Ч
source /etc/profile #����̨��������������,ʹ����������Ч�� - ֮����Ҫ��Slave1��Slave2��myid�ļ�
cd /usr/zookeeper/zookeeper-3.4.10/zkdata #��Slave1�ϲ���
vi myid
2
cd /usr/zookeeper/zookeeper-3.4.10/zkdata #��Slave2�ϲ���
vi myid
3 - ����zookeeper��Ⱥ(��̨����)
cd /usr/zookeeper/zookeeper-3.4.10/
bin/zkServer.sh start
bin/zkServer.sh status
�ߡ�Hadoop��װ
1.ΪMaster��������Ŀ¼,����ѹ
mkdir -p /usr/hadoop
tar -zxvf /home/lan/hadoop-2.7.3.tar.gz -C /usr/hadoop
2.�Ļ��������ļ�:
vi /etc/profile
��zookeeper��������������:
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$ CLASSPATH:$ HADOOP_HOME/lib
export PATH=$ PATH:$HADOOP_HOME/bin
3.����hadoop���
1)cd /usr/hadoop/hadoop-2.7.3/etc/hadoop
2)vi hadoop-env.sh #�༭hadoop-env.sh�ļ�
#The jsvc implementation to use. Jsvc is required to run secure datanodes
export JAVA_HOME=/usr/java/jdk1.8.0_171
#that bind to privileged ports to provide authentication of data transfer
#protocol. Jsvc is not required if SASL is configured for authentication of
#data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
3)vi core-site.xml #�༭core-site.xml�ļ�
```
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
<description>A base for orher temporary directories</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.perio</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
</configuration>
```
4)vim yarn-site.xml #�༭yarn-site.xml�ļ�
```
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
```
5)vi hdfs-site.xml #�༭hdfs-site.xml�ļ�
```
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>ture</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>ture</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>ture</value>
</property>
<property>
<name>dfs.permissions</name>
<value>flase</value>
</property>
</configuration>
```
6)����Hadoopû��mapred-site.xml�ļ�,��Ҫ����mapred-site.xml.template������mapred-site.xml�ļ����ݡ�
cp mapred-site.xml.template mapred-site.xml #����mapred-site.xml�ļ�
vim mapred-site.xml #�༭mapred-site.xml�ļ�
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7)vim slaves #�༭slaves�ļ�
master
slave1
slave2
8)vi master #�������༭master�ļ�
master
4.������Master���Ѿ����hadoop,�������ַ���Slave1��Slave2��:
scp -r /etc/profile slave1:/etc/ #�ַ����������ļ�
scp -r /etc/profile slave2:/etc/
scp -r /usr/hadoop slave1:/usr/ #�ַ�hadoopĿ¼
scp -r /usr/hadoop slave2:/usr/
5.ʹ����������Ч
��̨�����ֱ�source /etc/profile
����,��̨����hadoop�Ѱ�װ��ϡ�
6.��Master�ϸ�ʽ��Namenode
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop
hadoop namenode �Cformat
�����֡�Exiting with status 0����ʱ��,������ʽ���ɹ���֮����Ҫ������Ⱥ:
cd /usr/hadoop/hadoop-2.7.3/
sbin/start-all.sh
master�������: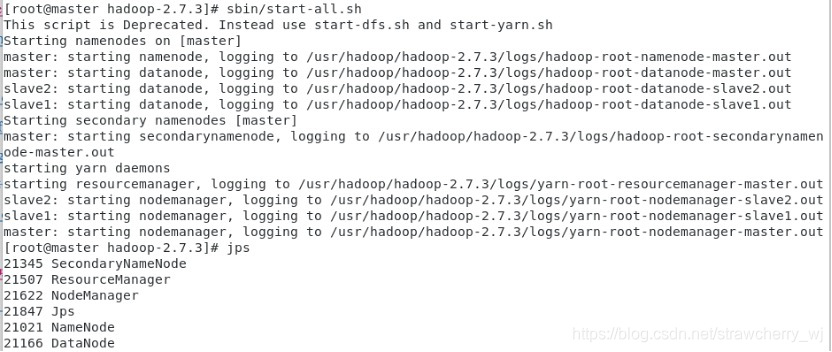
slave1��2�������:
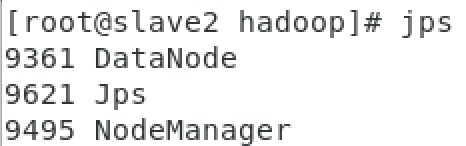
�����������Ĵ���:
����1:slave1��2�ڵ�û��nodemanager
- ��������Ϊyarn-site.xml�ļ������ô���(֮ǰ�Ұ�mapreduce�����mapseduce)
- Ҳ�п�������Ϊ:
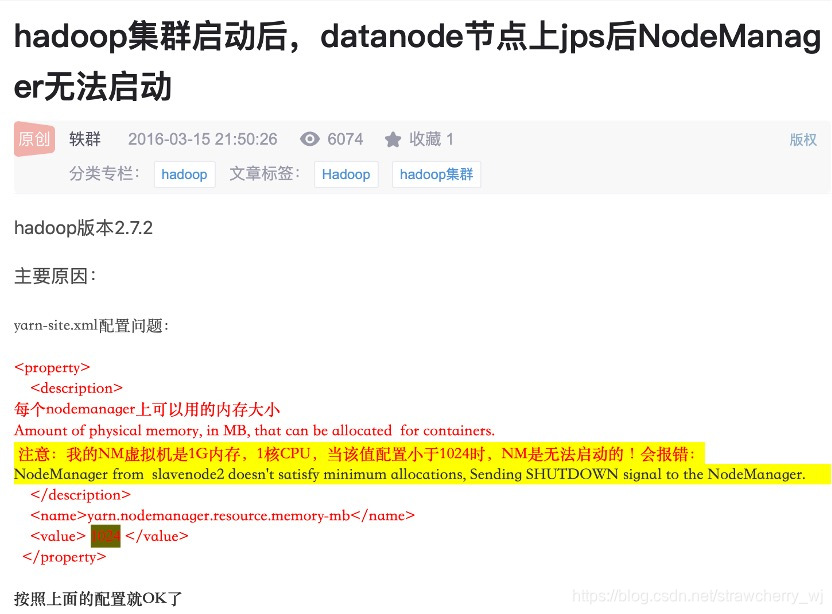
����2:����50070�����DataNode informationû�дӽڵ�
����ΪNameNode��9000�˿�û�д�ʹ��:
firewall-cmd --zone=public --add-port=9000/tcp --permanent��9000�˿ڡ�
9000�˿��ѿ���:
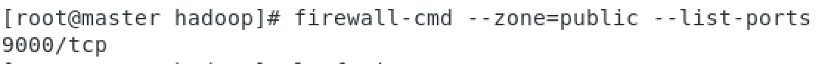
�ο�֪ʶ1:

�ο�֪ʶ2:

����50070����,���óɹ�:

����3:������8080����
�����ļ���ͬ,���ʵĶ˿�Ҳ��ͬ,�˿ڵ�ַ�������²鿴,��Ӧ���Ƿ���8088�˿ڡ�
