?目录
问题
配置
原理
问题
通过hive beeline进入后建的表与通过spark-sql进入建表互相不可见
配置
//变量位置:org.apache.hadoop.hive.metastore.conf.MetastoreConf.ConfVars#CATALOG_DEFAULT//默认值CATALOG_DEFAULT("metastore.catalog.default",?"metastore.catalog.default",?"hive","The default catalog to use when a catalog is not specified. Default is 'hive' (the " +"default catalog)."),
更改spark的hive-site配置metastore.catalog.default值为hive,以保证互通。
原理
hive高版本为3.1.x,此版本相对旧版本的(如2.1.1),存在较多升级,根据hive-exec包源码,可看到
org.apache.hadoop.hive.metastore.ObjectStore#getAllDatabases的方法实现有区别,高版本限制了catname,信息见Hive元数据库中dbs表的字段 CTLG_NAME
若要使用高版本且要保持spark-sql和hive beeline数据库相关信息一致,方法1是保持相同catname;方法2是手工修改此方法实现并重新编译高版本的hive-exec包??当前互通采用的方法1解决
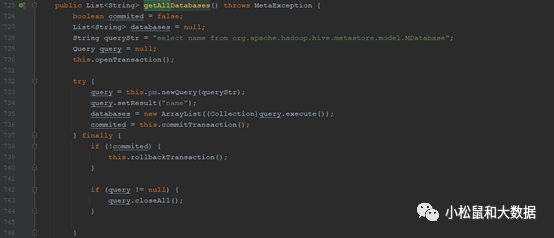
V2.1.1
@Overridepublic List<String> getAllDatabases() throws MetaException {boolean commited = false;List<String> databases = null;????//注意:这里是查询所有数据库String queryStr = "select name from org.apache.hadoop.hive.metastore.model.MDatabase";Query query = null;?openTransaction();try {query = pm.newQuery(queryStr);query.setResult("name");databases = new ArrayList<String>((Collection<String>) query.execute());commited = commitTransaction();} finally {if (!commited) {rollbackTransaction();}if (query != null) {query.closeAll();}}Collections.sort(databases);return databases;}
? ? ? ? ??
V3.1.0 如下图所示,查询所有数据库时候会限制catname,而Ambari平台在搭建spark服务时候会默认为spark创建自己的catname
@Overridepublic List<String> getAllDatabases(String catName) throws MetaException {boolean commited = false;List<String> databases = null;?Query query = null;catName = normalizeIdentifier(catName);?openTransaction();try {query = pm.newQuery("select name from org.apache.hadoop.hive.metastore.model.MDatabase " +"where catalogName == catname");query.declareParameters("java.lang.String catname");query.setResult("name");databases = new ArrayList<>((Collection<String>) query.execute(catName));commited = commitTransaction();} finally {rollbackAndCleanup(commited, query);}Collections.sort(databases);return databases;}

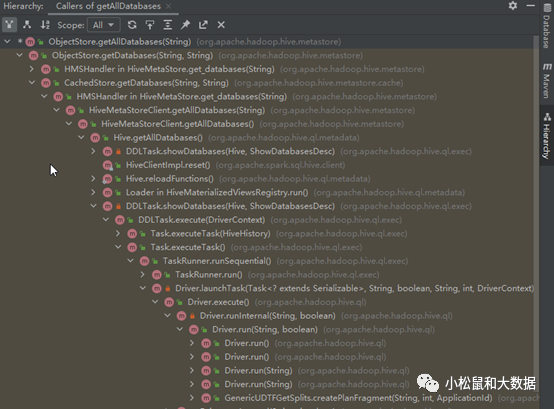
调用链
ObjectStore.getAllDatabases(String) (org.apache.hadoop.hive.metastore)HMSHandler in HiveMetaStore.get_databases(String) (org.apache.hadoop.hive.metastore)HiveMetaStoreClient.getAllDatabases(String) (org.apache.hadoop.hive.metastore)HiveMetaStoreClient.getAllDatabases() (org.apache.hadoop.hive.metastore)Hive.getAllDatabases() (org.apache.hadoop.hive.ql.metadata)DDLTask.showDatabases(Hive, ShowDatabasesDesc) (org.apache.hadoop.hive.ql.exec)DDLTask.execute(DriverContext) (org.apache.hadoop.hive.ql.exec)UpdateDeleteSemanticAnalyzer.analyzeAcidExport(ASTNode) (org.apache.hadoop.hive.ql.parse)Task.executeTask() (org.apache.hadoop.hive.ql.exec)TaskRunner.runSequential() (org.apache.hadoop.hive.ql.exec)TaskRunner.run() (org.apache.hadoop.hive.ql.exec)Driver.launchTask(Task<? extends Serializable>, String, boolean, String, int, DriverContext) (org.apache.hadoop.hive.ql)Driver.execute() (org.apache.hadoop.hive.ql)Driver.runInternal(String, boolean) (org.apache.hadoop.hive.ql)Driver.run(String, boolean) (org.apache.hadoop.hive.ql)Driver.run(String) (org.apache.hadoop.hive.ql)
最后:
如果本文能对您有帮助,您可以在心里点个赞,也可以分享给大家,欢迎随时沟通~
我的公众号:小松鼠与大数据

?