1. ʲô��analysis?
analysis��Elasticsearch���ĵ�����֮ǰ���ĵ�����ִ�еĹ���,�����ӵ�����������(inverted index)�� �ڽ��ĵ����ӵ�����֮ǰ,Elasticsearch��Ϊÿ���������ֶ�ִ�����ಽ��:
- Character filtering (�ַ�������): ʹ���ַ�������ת���ַ�
- Breaking text into tokens (������ת��Ϊ���): ���ı��ֳ�һ��һ���������
- Token filtering:ʹ�ñ�ǹ�����ת��ÿ�����(��Сдת��/ɾ�����ôʵȵ�)
- Token indexing:����Щ��Ǵ���index��
�ı��ִʻᷢ���������ط�:
��������:�������ĵ��ַ�����Ϊtextʱ,�ڽ�������ʱ����Ը��ֶν��зִʡ�����:����һ��text���͵��ֶν���ȫ�ļ���ʱ,����û�������ı����зִʡ�
2. ��Ҫ���
����˵��һ��analyzer���Է�Ϊ���µļ�������:
-
0����1�����ϵ�character filter
����ԭ�ַ���,ͨ�����ӡ�ɾ�������滻�����ı�ԭ�ַ���������:ȥ���ı��е�html��ǩ,���߽���������ת���ɰ��������ֵȡ�һ���ַ�������������������߶����
-
1��tokenizer
��˵���ǽ�һ�����ı���ֳ�һ�����Ĵʡ�������Ӣ��,ͨ���ո��ܽ����Ӳ�ֳ�һ�����Ĵ�,���Ƕ���������˵,��ʹ�����ַ�ʽ��ʵ�֡���һ���ִ�����,����ֻ��һ��tokenizeer
-
0����1�����ϵ�token filter
���зֵĵ������ӡ�ɾ�����߸ı䡣���罫����Ӣ�ĵ���Сд,���߽�Ӣ���е�ͣ��aɾ���ȡ���token filters��,��������token(�ֳ��Ĵ�)��position����offset�ı䡣ͬʱ,��һ���ִ�����,������������߶��token filters.
���ʵĹ���˳���� filter��������˳��
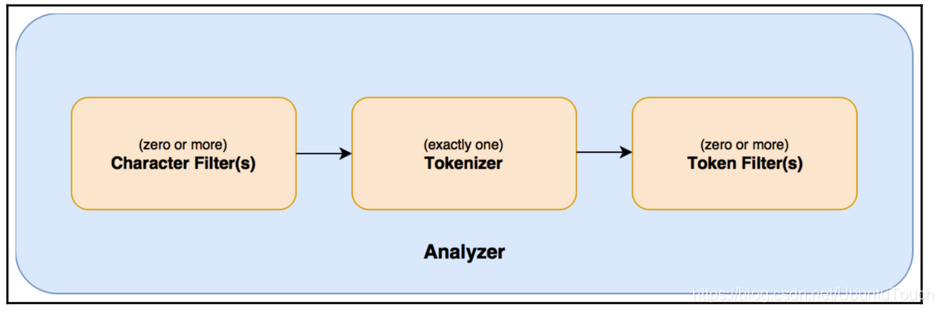
3. ʹ�÷�����
Ĭ��ESʹ��standard analyzer
3.1 Elasticsearch�����÷�����
Analyzer
- Standard Analyzer - Ĭ�Ϸִ���,�����з�,Сд����
- Simple Analyzer - ���շ���ĸ�з�(���ű�����), Сд����
- Stop Analyzer - Сд����,ͣ�ôʹ���(the,a,is)
- Whitespace Analyzer - ���տո��з�,��תСд
- Keyword Analyzer - ���ִ�,ֱ�ӽ����뵱�����
- Patter Analyzer - �������ʽ,Ĭ��\W+(���ַ��ָ�)
- Language - �ṩ��30���ֳ������Եķִ���
- Customer Analyzer �Զ���ִ���
Character Filter
| character filter | logical name | description |
|---|---|---|
| mapping char filter | mapping | �������õ�ӳ���ϵ�滻�ַ� |
| html strip char filter | html_strip | ȥ��HTMLԪ�� |
| pattern replace char filter | pattern_replace | ���������ʽ�����ַ��� |
Tokenizer
| tokenizer | logical name | description |
|---|---|---|
| standard tokenizer | standard | |
| edge ngram tokenizer | edgeNGram | |
| keyword tokenizer | keyword | ���ִ� |
| letter analyzer | letter | �����ʷ� |
| lowercase analyzer | lowercase | letter tokenizer, lower case filter |
| ngram analyzers | nGram | |
| whitespace analyzer | whitespace | �Կո�Ϊ�ָ������ |
| pattern analyzer | pattern | ����ָ������������ʽ |
| uax email url analyzer | uax_url_email | ����� url �� email |
| path hierarchy analyzer | path_hierarchy | �������� /path/to/somthing��ʽ���ַ��� |
Token Filter
| token filter | logical name | description |
|---|---|---|
| standard filter | standard | |
| ascii folding filter | asciifolding | |
| length filter | length | ȥ��̫������̫�̵� |
| lowercase filter | lowercase | ת��Сд |
| ngram filter | nGram | |
| edge ngram filter | edgeNGram | |
| porter stem filter | porterStem | ���شʸ��㷨 |
| shingle filter | shingle | ����ָ������������ʽ |
| stop filter | stop | �Ƴ� stop words |
| word delimiter filter | word_delimiter | ��һ�������ٲ���ӷִ� |
| stemmer token filter | stemmer | |
| stemmer override filter | stemmer_override | |
| keyword marker filter | keyword_marker | |
| keyword repeat filter | keyword_repeat | |
| kstem filter | kstem | |
| snowball filter | snowball | |
| phonetic filter | phonetic | ��� |
| synonym filter | synonyms | ����ͬ��� |
| compound word filter | dictionary_decompounder, hyphenation_decompounder | �ֽ⸴�ϴ� |
| reverse filter | reverse | ��ת�ַ��� |
| elision filter | elision | ȥ�������� |
| truncate filter | truncate | �ض��ַ��� |
| unique filter | unique | |
| pattern capture filter | pattern_capture | |
| pattern replace filte | pattern_replace | ���������ʽ�滻 |
| trim filter | trim | ȥ���ո� |
| limit token count filter | limit | ���� token ���� |
| hunspell filter | hunspell | ƴд��� |
| common grams filter | common_grams | |
| normalization filter | arabic_normalization, persian_normalization |
3.2 ����������
����ͨ��_analyzerAPI�����Էִʵ�Ч����
POST _analyze
{
"analyzer": "standard",
"text": "The quick Brown Fox"
}
���: ���ո��з�,���Ի����ĸ���
����������Ĺ������ʹ��:
- 0�����߶��
character filters - һ��
tokenizer - 0�����߶��
token filters
POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "The quick Brown Fox"
}
���: ���ո��з�,���Ի����ĸ���,��ÿ���ʶ���Сд
3.3 �Զ��������
�����õķִ�������������ʱ,���Դ���custom���͵ķִ�����
tokenizer:���û��Ƶ�tokenizer.(����)char_filter:���û��Ƶ�char_filter(�DZ���)filter:���û��Ƶ�token filter(�DZ���)position_increment_gap:��ֵΪ�ı�����ʱ,���ø�ֵ�����ı����м����ٿ�϶�����ø�����,�������IJ�ѯ����Ӱ�졣Ĭ�ϸ�ֵΪ100.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"char_filter":["html_strip"],
"filter":["lowercase","asciifolding"]
}
}
}
}
}
�����ʾ���ж�����һ����Ϊmy_custom_analyzer�ķ�����,�÷�������typeΪcustom,tokenizerΪstandard,char_filterΪhmtl_strip,filter�����������ֱ�Ϊ:lowercase��asciifolding.
����һ��:
POST my_index/_analyze
{
"text": "Is this <b>d��j�� vu</b>?",
"analyzer": "my_custom_analyzer"
}
���:
{
"tokens" : [
{
"token" : "is",
"start_offset" : 0,
"end_offset" : 2,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "this",
"start_offset" : 3,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "deja",
"start_offset" : 11,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "vu",
"start_offset" : 16,
"end_offset" : 22,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
4. ����������λ�ü�ʹ��
��������ʹ�õط�������:
- ��������ʱ
- ��������ʱ
4.1 ��������ʱָ��������
��������ֶ������˷�����,ES����������˳����ȷ��ʹ���ĸ�������:
- ���ж��ֶ��Ƿ������÷�����,�����,��ʹ���ֶ������ϵķ���������
- ���������
analysis.analyzer.default,��ʹ�ø����õķ����� - �������������δ����,��ʹ��Ĭ�ϵ�
standard������
Ϊ�ֶ�ָ��������
PUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace"
}
}
}
}
��������Ĭ�Ϸ�����
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
}
}
}
}
}
4.2 ����ʱ���ȷ��������
������ʱ,ͨ������������μ������ʱʹ�õķִ���:
- ����ʱָ��analyzer����
- ����mappingʱָ���ֶε�search_analyzer����
- ��������ʱָ��
setting��analysis.analyzer.default_search - �鿴��������ʱ�ֶ�ָ����analyzer����
- ������漸�ֶ�δ����,��ʹ��Ĭ�ϵ�standard�ִ�����
����ʱָ��analyzer��ѯ����
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}
ָ���ֶε�seach_analyzer
PUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
// ����ָ����������ʱʹ�õ�Ĭ�Ϸ�����Ϊwhitespace�ִ���,��������Ĭ�Ϸִ���Ϊ simple�ִ�����
ָ��������Ĭ�������ִ���
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
},
"default_seach":{
"type":"whitespace"
}
}
}
}
}
// ����ָ����������ʱʹ�õ�Ĭ�Ϸִ���Ϊsimple�ִ���,��������Ĭ�Ϸִ���Ϊwhitespace�ִ�����
5. ���÷�����
5.1 ����ת��������
����ͷ���ļ�����Ҫ���:
-
���β���,�������α������������Բ���,�焢����,һ���ǵ����֡�
-
�ʻ�IJ���,ϰ�ߡ��Ļ�������ɵ��÷�����,�绬�������,һ���Ƕ��ִ��
-
������̬����,�кܶ������ͬ��˼�ķ���������һ����,���Ծͳ����˶����Ͷ���ļ�����,��:�j���l��𩙪����Ӧ��һ������:쮡�
��Ӧ��һ��,���ǿ��Բ����滻�İ취,�����еķ��嶼�滻�ɶ�Ӧ�ļ���,�ڴ���������ʱ��,�ͽ��б���,�ȽϺ�ʵ��,(���Ľ���Ե�һ��)
�ڶ������ǿ��Բ����ռ���Ӧ�Ĵʻ�ת����ϵ,�����滻,������Ϊ�Ƕ��ִ�����滻,���������滹��Ҫ��ȡ�����÷ִ�,��Ȼ���п����滻����������������⡣
���������,��Ϊ����ͼ�����һ�Զ�����,���ǽ�����ͨ��ӳ���ת�ɼ����������,������������ת���ɷ��彫��������,������Ҫ���ǰ��������ѡ����ȷ�ķ��塣
5.1.1 ��װ����֤
Github �ϵĵ�ַ��:https://github.com/medcl/elasticsearch-analysis-stconvert/releases
����֮���ѹ��es�İ�װĿ¼�µ�plugins ��Ŀ¼,����es���� (����ѡ���Ӧ�汾)
��֤:

�����ļ�Ⱥ�����в�ֹһ�� Elasticsearch �Ľڵ�,����Ҫ��ÿһ̨ Elasticsearch ��ʵ����ִ����ͬ�IJ����װ,�������������������Ч��
5.1.2 �������
STConvert ������һ���ṩ�� 4 ����ͬ�����:
- һ����Ϊ
stconvert�� Analyzer,���Խ�����ת���ɷ��� - һ����Ϊ
stconvert�� Tokenizer,���Խ�����ת���ɷ��� - һ����Ϊ
stconvert�� Token Filter,���Խ�����ת���ɷ��� - һ����Ϊ
stconvert�� Char Filter,���Խ�����ת���ɷ���
ÿ�����������������3���������������Զ�������,�ֱ���:
- ����
convert_type����ת���ķ���,Ĭ����s2t,��ʾ���嵽����,���Ҫ������ת��Ϊ����,������Ϊt2s - ����
keep_both���������Ƿ���ת��֮ǰ������,һ����˵����ԭʼ���ݿ���������ǵ�����������(Ҳ����˵����ͬʱ��������ͼ���),Ĭ����false,Ҳ���Dz����� - ����
delimiter��Ҫ������,������ԭʼ���ݵ�ʱ��,��ηָ�����������,Ĭ�ϵ�ֵ�Ƕ���,
t: Traditional (��ͳ��) => Traditional Chinese (����)
s: Simplified (��) => Simplified Chinese (����)
5.1.3 ��ת��
��ת������,��Ϊ���Ĭ�Ͼ����������
GET /_analyze
{
"tokenizer" : "standard",
"filter" : ["lowercase"],
"char_filter" : ["stconvert"],
"text" : "�Ұ�China��"
}
����ָ���� Tokenizer Ϊ
standard,Ҳָ����lowercase��Ϊ�ִ�֮��� Filter,���������� Standard Analyzer �ķ���Ч��һ����,���ǻ�������һ�� Char Filter �IJ�������,ʹ�õ��������°�װ�ļ���ת������ṩ��stconvert,Ҳ���ǽ�����ת�ɷ���,��������
{
"tokens": [
{
"token": "��",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "��",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "china",
"start_offset": 2,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
}
]
}
���Կ���,���˺� Standard �ִ�Ч��һ���ĵط�����,���ǻ�����Ľ������ַ���ת���˷���,
����ת������,����û�б仯,����Ϊ���ķ���Ҳ�����������������������ֽ����Զ���ִ�֮ǰ,ͨ�������ķ�ʽ�Ƚ��зִ�Ч���IJ���,�õ�����Ľ��֮���ٽ��о�����Զ��� Analyzer �Ĵ���������
5.1.4 ��ת��
��������ʱָ��������
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": ["tsconvert"]
}
},
"char_filter": {
"tsconvert" : {
"type" : "stconvert",
"delimiter" : "#",
"keep_both" : false,
"convert_type" : "t2s"
}
}
}
}
}
// delimiter �� keep_both ���Կ��Բ�д
����:
POST /my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "�Ґ�China��"
}
����ִ��,�õ��ķ����������:
{
"tokens": [
{
"token": "��",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "��",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "china",
"start_offset": 2,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
}
]
}
5.2 Ik������
IK���������Lucene IK������(http://code.google.com/p/ik-analyzer/)���ɵ�elasticsearch��,֧���Զ����ֵ䡣
5.2.1 ��װ����֤
Github �ϵĵ�ַ��:https://github.com/medcl/elasticsearch-analysis-ik/releases
����֮���ѹ��es�İ�װĿ¼�µ�plugins ��Ŀ¼,����es���� (����ѡ���Ӧ�汾)
5.2.2 �������
- Analyzer:
ik_smart,ik_max_word, - Tokenizer:
ik_smart,ik_max_word
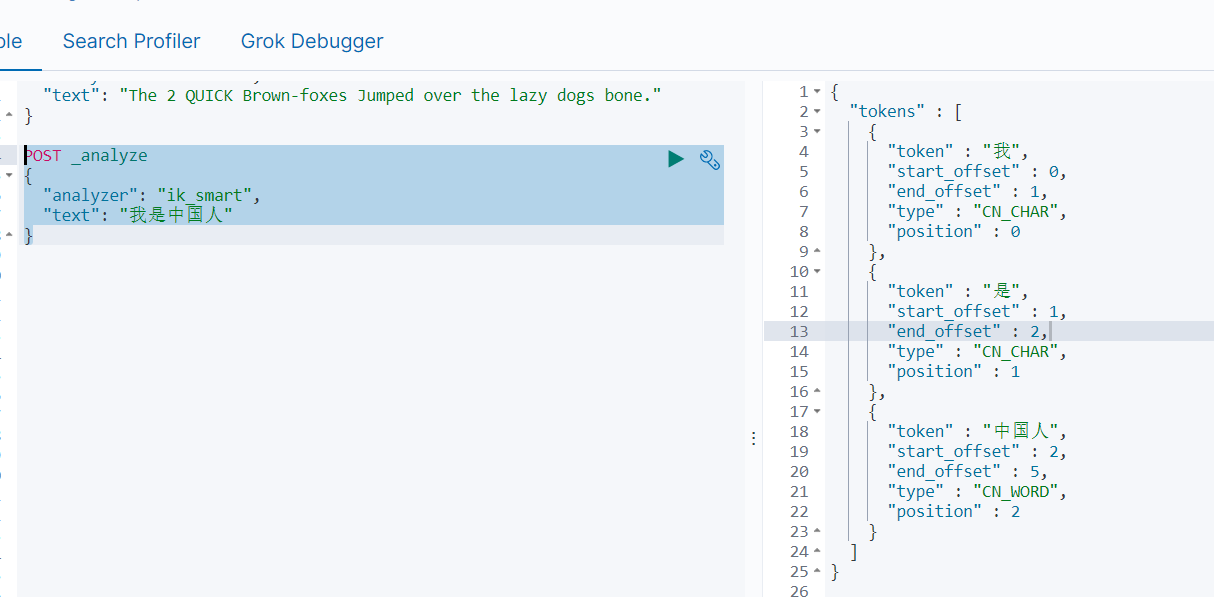
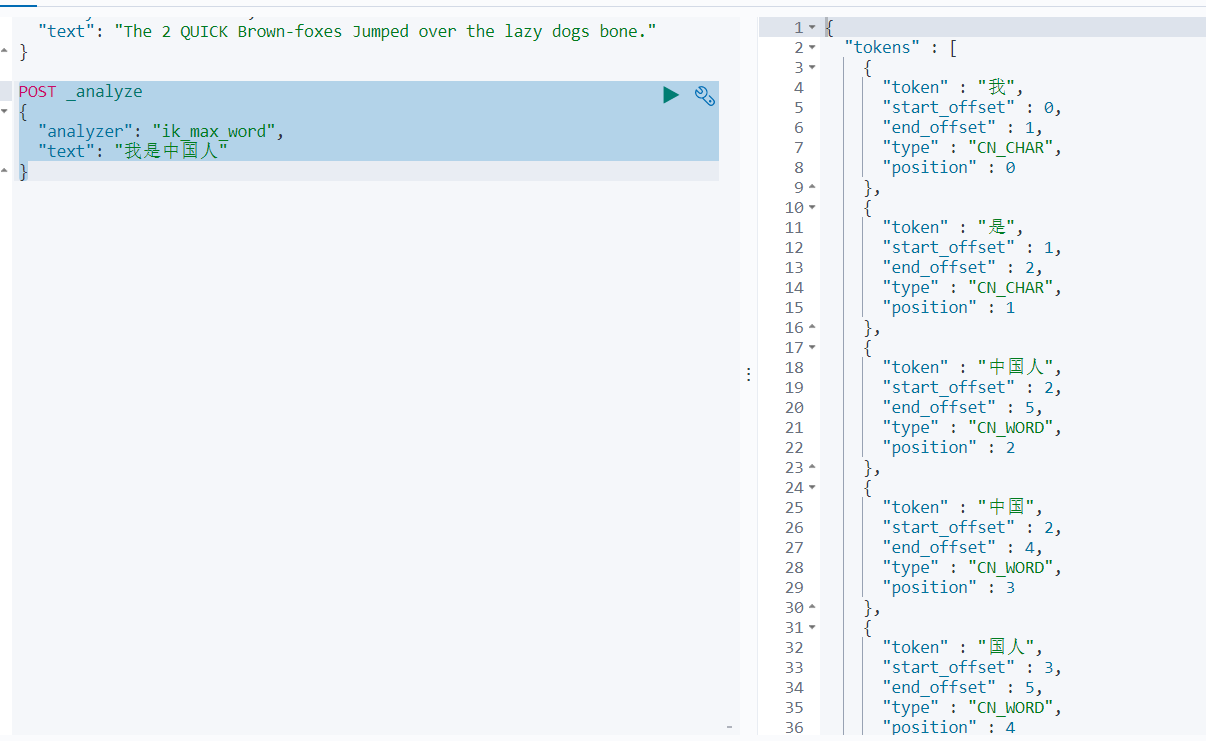
ik_max_word��ik_smartʲô����?
ik_max_word: �Ὣ�ı�����ϸ���ȵIJ��,����Ὣ���л��������衱���Ϊ���л�����,�л�����,�л�,����,����,����,��,��,����,����,��,����,���衱,������ֿ��ܵ����,�ʺ� Term Query;
ik_smart: ����������ȵIJ��,����Ὣ���л��������衱���Ϊ���л�����,���衱,�ʺ� Phrase ��ѯ��
5.2.3 ����ʹ��
ʹ��analyzer:
ʹ��tokenizer
PUT product
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"filter": [
"lowercase"
],
"tokenizer": "ik_smart"
}
}
}
}
}
5.2.4 �Զ���ִʿ�
���� ��ik��������configĿ¼�µ� IKAnalyzer.cfg.xml
��������:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer ��չ����</comment>
<!--�û����������������Լ�����չ�ֵ� -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--�û����������������Լ�����չֹͣ���ֵ�-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--�û���������������Զ����չ�ֵ� -->
<entry key="remote_ext_dict">location</entry>
<!--�û���������������Զ����չֹͣ���ֵ�-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
��չ��: ���뱻�ִʵĴ�: ����, �DZ���, ����������
ֹͣ��: ����Ҫ�Ĵ�,����ʱ��������, ����: �� ,��, the , a ��
Զ�̴ʵ�߱��ȸ��µ�����, ��������ǰ���㼴��ʵ���ȸ���
���� location ��ָһ�� url,���� http://yoursite.com/getCustomDict,������ֻ�������������㼴����ɷִ��ȸ��¡�
-
�� http ������Ҫ��������ͷ��(header),һ����
Last-Modified,һ����ETag,�����߶����ַ�������,ֻҪ��һ�������仯,�ò���ͻ�ȥץȡ�µķִʽ������´ʿ⡣д���ӿ�,������ʱ���ETag����
������Ngת����̬�ļ�, ���Զ����������������,���ļ��Ķ�ʱ,������ֵ�Զ��ı�
-
�� http ���ص����ݸ�ʽ��һ��һ���ִ�,���з���
\n���ɡ� -
url����һ��UTF-8��ʽ���ı�����
����ж���ļ�,��Ӣ�ķֺŸ���
;
�������
��ȡ
IKAnalyzer.cfg.xml�����ļ�,���������е�������ʿ����������Head����
����Ӧ�л�ȡ
Last- Modify��Etags�ֶ�ֵ,�ж��Ƿ�仯���δ�仯,����1min,���ص�0��
? ����б仯,���¼�ꪴʵ�
����1min,���ص�0��
�Զ���ʻ�ֻ����¼ӵ�������Ч,����Դ���������Ч,��Ҫ����һ�β���
������д��ʱ���ѷִʴ洢,�����Զ���ʻ㲻��Դ���������Ч
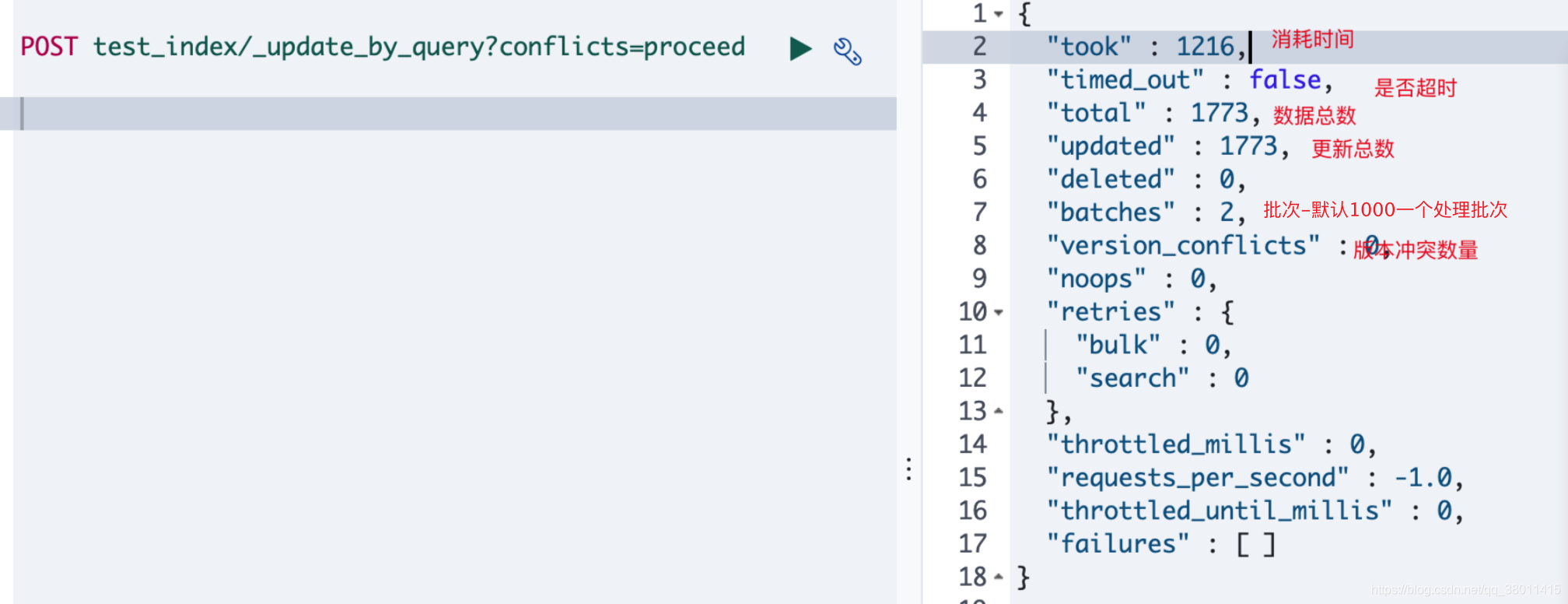
�ٷ� �ṩ���·�ʽ POST product/_update_by_query?conflicts=proceed
update_by_queryԭ��
��ʼʱ��ȡһ�������Ŀ���,����ʹ���ڲ��汾���������и��¡�����ζ������ĵ��ڻ�ÿ��պ�,���������� �����а汾��������,���ᷢ���汾��ͻ�������յİ汾�������汾һֱʱ����и���,���ҵ����ĵ��汾�š�
��������ͻ�������������¹���ʧ��ʱ,���¹����Dz���ع��ġ����������Ϊ��ͻ�����������¹�����ֹ,������url�����Ӳ���conflicts=proceed������������body�����ӡ�conflicts��:��proceed��
�������������,��es�ĵ�Ҳ����
_update_by_queryִ�н����ͼ:(����ʱ�䵥λ : ����)
����es��Ⱥ,ִ��Ч�ʴ����2300��/s, 26������,��Ż���1.7����
���¿��ܺ�ʱ̫�õ��¿ͻ������ӳ�ʱ,����������鿴����ִ�����(δ����������)
GET _tasks?actions=*update*&detailed
5.3 ͬ��ʷ�����
5.4 ƴ��������
Pinyin Analysis for Elasticsearch
�����: