Hadoop生态
其实我们在做工业级的大数据框架部署的时候,所说的hadoop大数据部署通常指的是一整个生态,其中包括hadoop,spark,hive,hdfs,flink等,而不是单独指hadoop。
基础原理介绍
在进行hadoop集群部署的之前,首先得了解一下hadoop的工作原理。
什么是hadoop呢,hadoop是一套大数据处理框架,主要解决海量数据的存储和分析计算。那到底是在hadoop中哪些解决存储问题?哪些解决分析计算问题?下面就详细看一下hadoop的组成结构,看它是如何解决存储和分析计算的:
首先来看看hadoop的结构组件如下
Hadoop组成结构
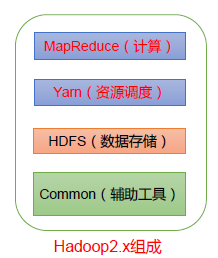
这就是hadoop的结构,HDFS解决了数据的存储,MapReduce用于分析计算,这就和上面的对应上了,其中还会有一个Yarn,它的功能主要是做一个任务调度。早先分析计算和任务调度是一个组件完成 的,在hadoop2.x后才正式分离,这样解耦性更强。
下面再慢慢的推进看看其中各个模块是如何工作的?原理是什么?
HDFS
hdfs是一个分布式文件系统,用于存储文件,有很多的服务器联合起来实现分布式功能,通常hdfs适合一次写入,多次读出的应用场景。请看下面的结构:
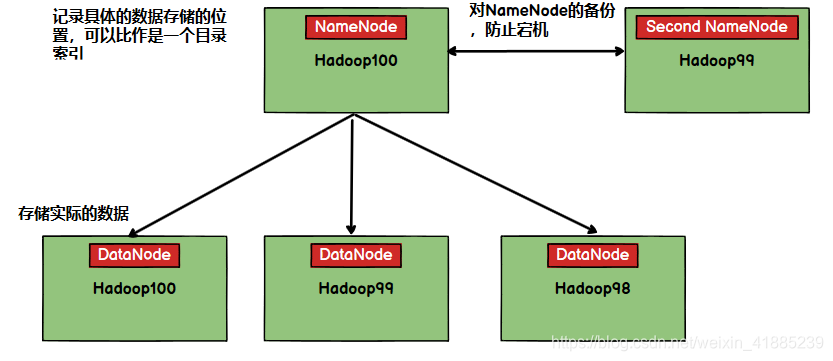
以上就是hdfs的一个大概的分布式解决方案,既然是分布式存储,自然数据会被分别存到不同的服务器上,在hdfs层面上,把每一个具体存储数据的服务器看作是DataNode,试想一下当我们在查询或者存储数据的时候,需要挨个遍历服务器节点,看某个具体的DataNode上是否有数据或者是否空缺,那这样显然不可行,效率太低了。所以单独有具体的数据存储的节点服务器DataNode还不够呀,这时NameNode就出现,可以理解为NameNode节点服务器是一个索引记录服务器,它记录着具体的数据到底存储在哪个位置,记录着哪个服务器还有空间,注意的是当我们在设计NameNode的时候,通常也并不是用独立的服务器来布置这个节点,而是和某个NameNode共用一个服务器,也就是说在集群中的某个服务器中,在保存具体存储索引表的同时还完成了实际的存储任务,提高利用率吧。现在还有一个问题,如果NameNode节点服务器挂掉,那整个集群将无法工作,什么数据存在哪里就不知道了,这时候,Second NameNode出现,它的功能就是对NameNode做一个备份,当NameNode挂了,Second NameNode可以继续工作,或者拷贝数据到NameNode节点服务器,重启服务。所以可以知道这两个节点服务器是必然不能是同一个的。这里就简单的做一个理解,只有理解了这个具体的内容,你才能知道为什么要这么部署。
Yarn
Yarn是一个资源调度平台,首先要理解为什么需要这个东西,举一个具体的应用场景,当我提交一个具体任务时,这时候该决定它运行在哪里呢?如果运行到某一个节点服务器上,万一这个阶段服务器CPU资源和内存资源都已经耗光了,那就不好办了,那当资源还充足的情况下,该分配多少资源给他,如果一个任务比较简单时,却分配很多的cpu资源和内存资源给他,这也不太合理,所以Yarn就出现了,它作为一个资源调度平台,可以解决以上问题。下面还是简单的抛出一个关于Yarn的结构关系图。
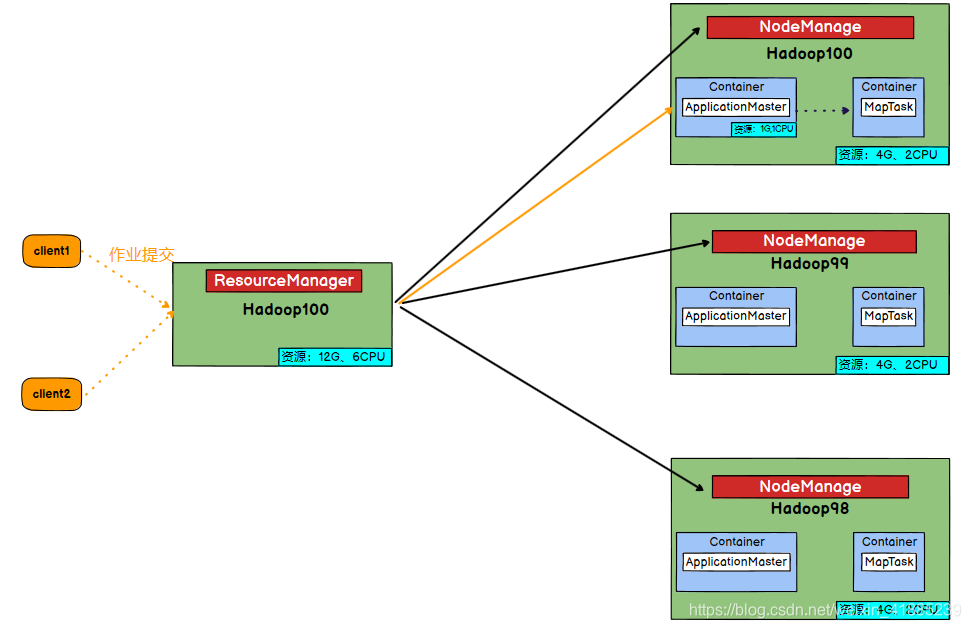
以上就是Yarn平台的一个大概的分布图,可以看到每一个方块表示的就是一台独立的服务器,这个服务器中会有固定的资源,比如每一台的资源是4G存储空间,2核,这些资源是通过NodeManager进行管理的,假设当我要执行一个任务进程时,如果只有NodeManager,那我必须去得遍历每一台服务器,去查看它的NodeManager下是否还有空余的资源,这样就显得效率很低,所以ResourceManager出现了,它会对集群的所有资源进行管理,记录着每一台服务器节点到底还剩余多少资源。
注:因为ResourceManager是作为一个集中的资源管理节点,你可以理解为只是记录着每一台服务器使用的资源情况,所以如果用一台单独的服务器来布置,显然有些浪费,所以通常会和某一个NodeManager布置到一起,在某一个服务器上,既是一个集群的资源管理节点,同时自身也就是一个实际的执行任务的一个资源节点服务器。
下面举一个小例子,来大概看一下Yarn的工作流程,顺便解释一下Container、ApplicationMaster等名字的大概意思
首先client1会提交一个具体的任务,这时候,ResourceManager作为一个集中的资源管理器,它会查看本机记录的所有子服务器上的资源使用情况,如果子服务器hadoop100(也就是自身,因为自身也可以作为一个实际的任务执行节点服务器)还有足够的资源,此时会将任务交给hadoop100,在hadoop100中首先会交给NodeManager,它会依据client1提交的任务大小来评估到底需要给它多少资源,这时会产生一个Container,在里面产生一个ApplicationMaster,这里的Container你可以理解为一个虚拟机,或者是一个docker容器,它就是独立的小电脑,里边分配了的资源给这个任务,ApplicationMaster是用来管理client1提交的任务,为什么会有这个东西,而不是直接执行client1的任务呢,是因为client1提交的任务如果比较复杂,我们可能需要开辟很多进程或者更复杂,这时候需要放到多台服务器上进行执行,所以还是需要一个总的ApplicationMaster进行管理。ApplicationMaster会依据提交任务的具体情况,再开辟一系列Container,在里面执行的Map Task才是具体的任务进程(这里就和MapReduce联系到一起了),所以这里的Container可以理解是具体的进程执行需要的资源。自此一个完成的流程结束,当然这只是简单的的理解,在本文中只要理解ResourceManager和NodeManager就行。方便后面进行部署。
MapReduce
MapReduce是一个分布式实时计算框架,在hadoop整个框架中,它解决的就是分析计算的问题,现在随着技术的进步,spark开始流行起来,用于替代MapReduce的工作。
由于这对于我们做集群部署的时候并没有太多相关,所以不做详细的介绍。
正式分布式集群搭建
准备三台服务器
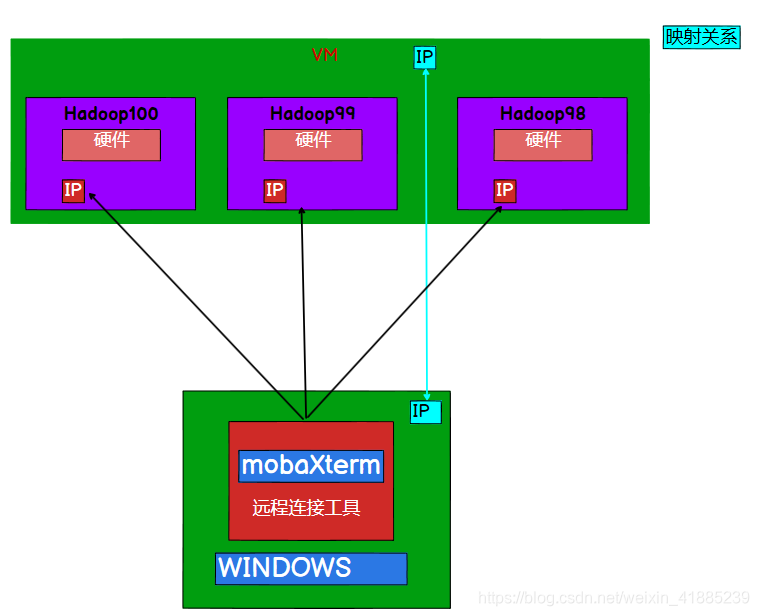
既然是搭建集群,那就得有多台服务器,由于本人资源有限,没有多台pc,所以采用的是在一台电脑上安装多个虚拟机来实现分布式集群的搭建,先看一下原理图如下
三台虚拟机ip设置
注意:
这里已经默认我们已经克隆完毕,拥有了相同的三台虚拟机,具体如何克隆,后面会做说明,这里你姑且认为你有三台虚拟机了,但其实到这一步,你只拥有了一台虚拟机,你先按照一台的来设置。没关系。
首先我们要安装VMware,然后在里面安装多个虚拟机系统,这里选择安装三台虚拟机系统,首先第一个问题就是每个虚拟机里面的IP如何设置的问题,通常这三台虚拟机的我们会设置成静态ip,如果的动态的话,每次打开都要查看ip,然后连接,如果是静态ip,则可以省去这部分的工作,所以,这三台虚拟机的ip应该设置成静态ip,且在同一个网段(因为要进行通信),
既然这里我们这里对三台虚拟机的命名是hadoop100,hadoop99,hadoop98,那就设置ip地址为:
192.168.83.100, 192.168.83.99, 192.168.83.98
注意
1.这里的ip的网段是根据你自己所在网段进行设置,每个人都可能不一样,我这里是83网段,但你 的不一定是83网段。
2.关于静态ip的设置我也不做说明,因为不同系统的设置方法不一样,如果是centos,则参照centos对应教程设置,如果是ubuntu,则也有对应教程,但整体都不难,也有些类似。
第一台虚拟机ip

第二台虚拟机ip
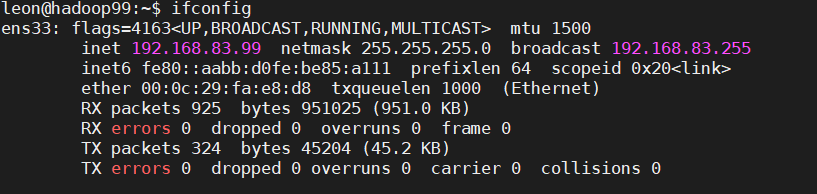
第三台虚拟机ip
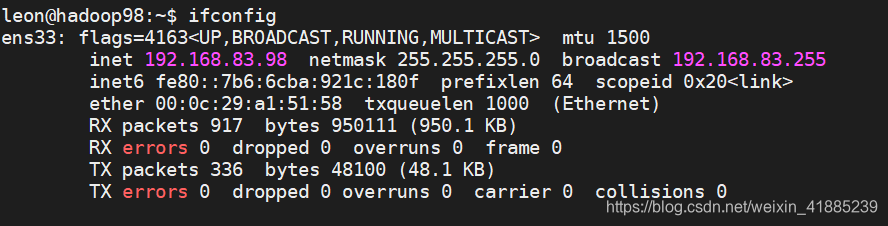
网关设置
三台虚拟机ip设置好之后,表示我们已经有三台电脑啦,那接下来的问题是,外界如何和这三台虚拟的电脑通信呢?这是一个问题,细细看最开始给出的原理图,发现这三台虚拟的电脑是装在一个VMware软件里面,所以我们要先搞定,VMware如何和三台虚拟机通信?
所以VMware本身也要有一个ip,或者说要设置一个网关,网段要和三台虚拟机是一样的。
第一步点击“编辑”
第二步点击“虚拟网络编辑器”
第三步要先选择wmnet8,nat模式,然后点击“更改设置”,这时才可以对wmnat8进行更改
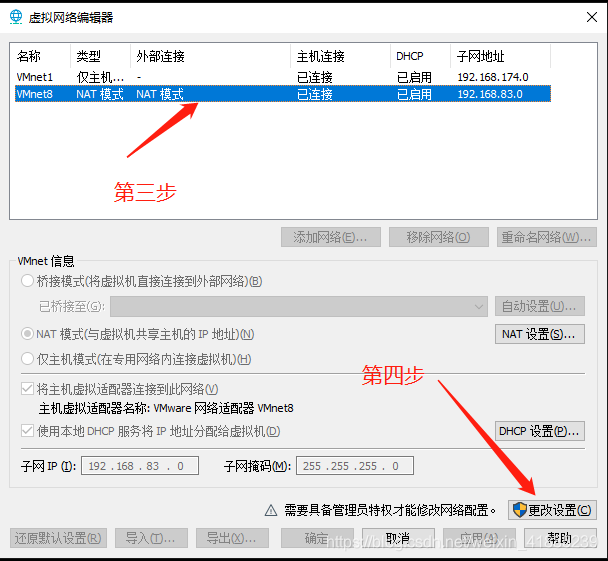

在第六步中,就i要更改网关,网段要和前三个虚拟机是一样的,这样VMware才可以和三台虚拟机通信。
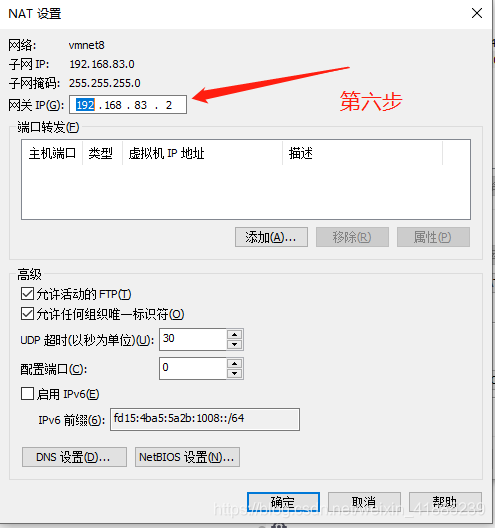
ip映射
现在VMware也可以和三台虚拟机通信了,那外界如何和这三台虚拟机通信呢?再仔细看原理图,其实我们只需要将外界的网络映射到VMware上就可以搞定了,映射是什么意思,就好比是将两个网络绑定,如下的网络1映射到网络2,好比是给网络1起了个别名,他们其实是同一个东西,当别人访问网络2时,就好比访问到了网络1。

那回到主题,我们也只需要将VMware的ip(或者网关)映射到我们的windows物理机的ip上,当我们物理机访问三台虚拟机时,其实就是以VMware的身份访问三台虚拟机,这样才能访问得通,因为他们才是真的在一个网段。

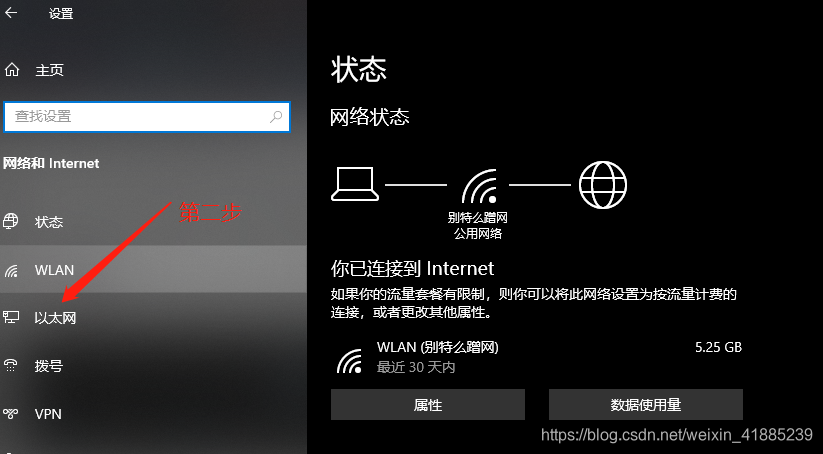


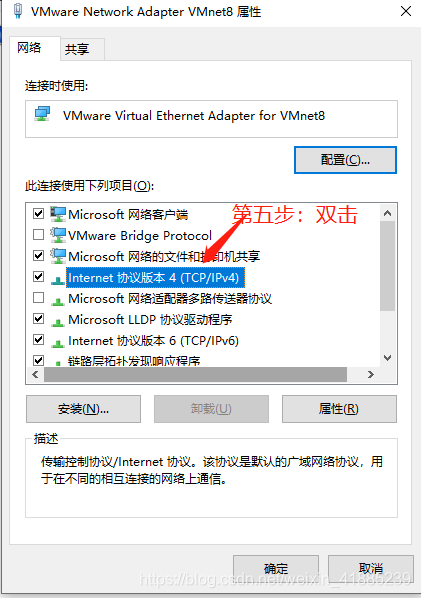
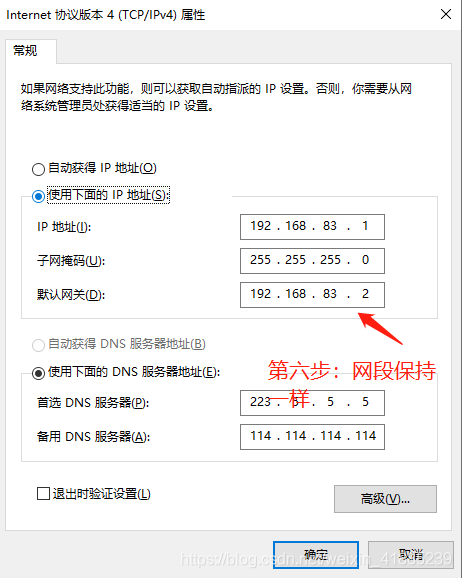
至此,三台虚拟机已经准备好了,且已经可以和物理机通信。
关闭防火墙
在真实的工业生产环境中,通常只会对VMware设置一个总的防火墙,虚拟机中的防火墙都是要关闭的
systemctl stop firewalld:用于关闭当前状态下的防火墙
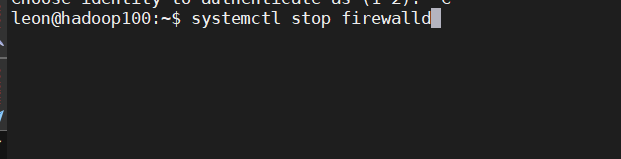
systemctl disable firewalld.service:用于开机时关闭防火墙

给普通用户设置最高权限
其实这一步我觉得也没太大必要,只是说提供了一种方便,不至于做什么操作都要输入密码,或者sudo
sudo vim /etc/sudoers
进入后对leon进行如下的添加
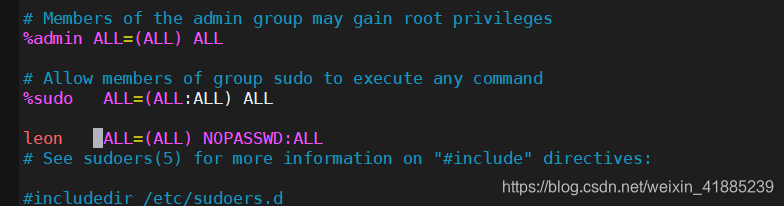
到这里,其实才是完整的一台虚拟机设置完成,剩下的就是克隆剩下的两台虚拟机出来,克隆出来后,按照最开始的提前讲过的来更改ip就可以了。
总结一下:
1、本篇文章就写了hadoop的基础原理,一定要弄懂,这是我们后面部署的关键。
2、本篇文章还准备了三台虚拟机,提供后续集群搭建来使用。
就写到这里,下一篇将正式部署hadoop