��1�� Elasticsearch����
01-��ƪ
�ṹ������
�ǽṹ������
��ṹ������
??
02-����ѡ��
Elasticsearch ��ʲô
The Elastic Stack, ���� Elasticsearch�� Kibana�� Beats �� Logstash(Ҳ��Ϊ ELK Stack)���ܹ���ȫ�ɿ��ػ�ȡ�κ���Դ���κθ�ʽ������,Ȼ��ʵʱ�ض����ݽ��������������Ϳ��ӻ���
Elaticsearch,���Ϊ ES, ES ��һ����Դ�ĸ���չ�ķֲ�ʽȫ����������, ������ ElasticStack ����ջ�ĺ��ġ�
�����Խ���ʵʱ�Ĵ洢����������;������չ�Ժܺ�,������չ���ϰ�̨������,���� PB ��������ݡ�
ȫ����������
Google,�ٶ������վ����,���Ƕ��Ǹ�����ҳ�еĹؼ�����������,������������ʱ������ؼ���,���ǻὫ�ùؼ��ּ�����ƥ�䵽��������ҳ����;���г�������Ŀ��Ӧ����־�������ȵȡ�������Щ�ǽṹ���������ı�,��ϵ�����ݿ����������ܺܺõ�֧�֡�
һ�㴫ͳ���ݿ�,ȫ�ļ�����ʵ�ֵĺܼ���,��Ϊһ��Ҳû�������ݿ���ı��ֶΡ�����ȫ�ļ�����Ҫɨ��������,�����������Ļ���ʹ�� SQL ����Ż�,Ҳ��Ч��������������,����ά������Ҳ���鷳,���� insert �� update �����������¹���������
��������ԭ����Է����ó�,��һЩ����������,ʹ�ó����������ʽ,�����Ƿdz����:
- ���������ݶ����Ǵ����ķǽṹ�����ı����ݡ�
- �ļ���¼���ﵽ��ʮ�����������������ࡣ
- ֧�ִ������ڽ���ʽ�ı��IJ�ѯ��
- ����dz�����ȫ��������ѯ��
- �Ը߶���ص��������������������,����û�п��õĹ�ϵ���ݿ�������㡣
- �Բ�ͬ��¼���͡����ı����ݲ�����ȫ��������������Խ��ٵ������Ϊ�˽���ṹ�����������ͷǽṹ������������������,���Ǿ���Ҫרҵ,��׳,ǿ���ȫ���������� ��
- ����˵����ȫ����������ָ����Ŀǰ�㷺Ӧ�õ������������档���Ĺ���ԭ���Ǽ������������ͨ��ɨ�������е�ÿһ����,��ÿһ���ʽ���һ������,ָ���ô��������г��ֵĴ�����λ��,���û���ѯʱ,��������������Ƚ������������в���,�������ҵĽ���������û��ļ�����ʽ���������������ͨ���ֵ��еļ����ֱ����ֵĹ��̡�
Elasticsearch Ӧ�ð���
- GitHub: 2013 ���,������ Solr,��ȡ Elasticsearch ���� PB ���������� ��GitHub ʹ��Elasticsearch ���� 20TB ������,���� 13 ���ļ��� 1300 ���д��롱��
- ά���ٿ�:������ Elasticsearch Ϊ�����ĺ��������ܹ�
- �ٶ�:Ŀǰ�㷺ʹ�� Elasticsearch ��Ϊ�ı����ݷ���,�ɼ��ٶ����з������ϵĸ���ָ�����ݼ��û��Զ�������,ͨ���Ը������ݽ��ж�ά����չʾ,������λ����ʵ���쳣��ҵ������쳣��Ŀǰ���ǰٶ��ڲ� 20 ���ҵ����(�����Ʒ��������ˡ�Ԥ�⡢�Ŀ⡢ֱ��š�Ǯ���� ��ص�),����Ⱥ��� 100 ̨����, 200 �� ES �ڵ�,ÿ�쵼�� 30TB+���ݡ�
- ����:ʹ�� Elasticsearch �������� 32 ����ʵʱ��־��
- ����:ʹ�� Elasticsearch ������־�ɼ��ͷ�����ϵ��
- Stack Overflow:��� Bug �������վ,ȫӢ��,�����Ա��������վ��
03-��ѧ���
- ��1�� Elasticsearch����
- ��2�� Elasticsearch����
- ��3�� Elasticsearch����
- ��4�� Elasticsearch����
- ��5�� Elasticsearch����
- ��6�� Elasticsearch�Ż�
- ��7�� Elasticsearch������
��2�� Elasticsearch����
�ٷ���ַ? ? ??�ٷ��ĵ�? ? ??Elasticsearch 7.8.0����ҳ��
Windows ��� Elasticsearch ѹ����,��ѹ����װ���,��ѹ��� Elasticsearch ��Ŀ¼�ṹ���� :
| Ŀ¼ | ���� |
|---|---|
| bin | ��ִ�нű�Ŀ¼ |
| config | ����Ŀ¼ |
| jdk | ���� JDK Ŀ¼ |
| lib | ��� |
| logs | ��־Ŀ¼ |
| modules | ģ��Ŀ¼ |
| plugins | ���Ŀ¼ |
��ѹ��,���� bin �ļ�Ŀ¼,��� elasticsearch.bat �ļ����� ES ���� ��
ע��: 9300 �˿�Ϊ Elasticsearch ��Ⱥ�������ͨ�Ŷ˿�, 9200 �˿�Ϊ��������ʵ� httpЭ�� RESTful �˿ڡ�
{
"name" : "DESKTOP-LNJQ0VF",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "nCZqBhfdT1-pw8Yas4QU9w",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
05-����-RESTful & JSON
REST ָ����һ��ܹ�Լ��������ԭ��������ЩԼ��������ԭ���Ӧ�ó������ƾ��� RESTful�� Web Ӧ�ó�������Ҫ�� REST ԭ����,�ͻ��˺ͷ�����֮��Ľ���������֮������״̬�ġ��ӿͻ��˵���������ÿ����������������������������Ϣ�����������������֮����κ�ʱ�������,�ͻ��˲���õ�֪ͨ������,��״̬����������κο��÷������ش�,��ʮ���ʺ��Ƽ���֮��Ļ������ͻ��˿��Ի��������ԸĽ����ܡ�
�ڷ�������,Ӧ�ó���״̬���ܿ��Է�Ϊ������Դ����Դ��һ����Ȥ�ĸ���ʵ��,����ͻ��˹�������Դ��������:Ӧ�ó���������ݿ��¼���㷨�ȵȡ�ÿ����Դ��ʹ�� URI(Universal Resource Identifier) �õ�һ��Ψһ�ĵ�ַ��������Դ������ͳһ�Ľӿ�,�Ա��ڿͻ��˺ͷ�����֮�䴫��״̬��ʹ�õ��DZ��� HTTP ����,���� GET�� PUT�� POST ��DELETE��
�� REST ��ʽ�� Web ������,ÿ����Դ����һ����ַ����Դ�������Ƿ������õ�Ŀ
��,�����б���������Դ����һ���ġ���Щ�������DZ�����,���� HTTP GET�� POST��PUT�� DELETE,�����ܰ��� HEAD �� OPTIONS�����������,�����Ҫ���ʻ������ϵ���Դ,�ͱ�������Դ���ڵķ�������������,�������б��������Դ������·��, �Լ�����Դ���еIJ���(��ɾ�IJ�)��
REST ��ʽ�� Web �������з��ؽ��,�������JSON�ַ�����ʽ���ء�
06-����-Postman�ͻ��˹���? ? ?
���ֱ��ͨ��������� Elasticsearch ������������,��ô��Ҫ�ڷ��͵������а���
HTTP ���ķ���,�� HTTP �Ĵ������ҽ�֧�� GET �� POST ����������Ϊ���ܷ���ؽ��пͻ��˵ķ���,����ʹ�� Postman ����Postman ��һ��ǿ�����ҳ���Թ���,�ṩ����ǿ��� Web API �� HTTP ������ԡ�
��������ǿ��,����������������������,��Ƶú����Ի��� Postman ���İ��ܹ������κ����͵� HTTP ���� (GET, HEAD, POST, PUT��),�����ܹ������ύ,�ҿ��Ը����������������塣
07-����-��������
��������(��ͳ)
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
��������
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
Elasticsearch �������ĵ������ݿ�,һ���������������һ���ĵ��� Ϊ�˷���������,���ǽ� Elasticsearch ��洢�ĵ����ݺ�ϵ�����ݿ� MySQL �洢���ݵĸ������һ�����
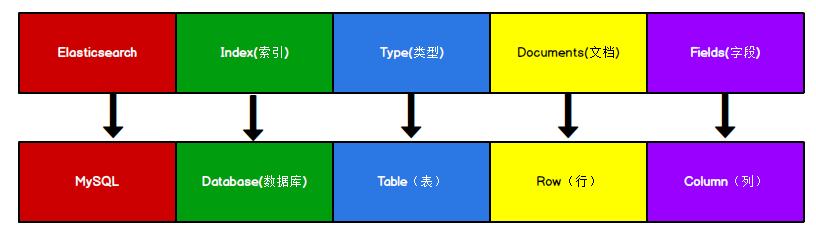
ES ��� Index ���Կ���һ����,�� Types �൱�ڱ�, Documents ���൱�ڱ����С����� Types �ĸ����Ѿ���������, Elasticsearch 6.X ��,һ�� index ���Ѿ�ֻ�ܰ���һ��type, Elasticsearch 7.X ��, Type �ĸ����Ѿ���ɾ���ˡ�
08-����-HTTP-����-����
�Աȹ�ϵ�����ݿ�,���������͵�ͬ�ڴ������ݿ⡣
�� Postman ��,�� ES �������� PUT ���� : http://127.0.0.1:9200/shopping
�����,������������Ӧ:
{
"acknowledged": true,//��Ӧ���
"shards_acknowledged": true,//��Ƭ���
"index": "shopping"//��������
}��̨��־:
[2021-04-08T13:57:06,954][INFO ][o.e.c.m.MetadataCreateIndexService] [DESKTOP-LNJQ0VF] [shopping] creating index, cause [api], templates [], shards [1]/[1], mappings []
?����ظ��� PUT ���� : http://127.0.0.1:9200/shopping ��������,�᷵�ش�����Ϣ :
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists",
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ",
"index": "shopping"
}
],
"type": "resource_already_exists_exception",
"reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists",
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ",
"index": "shopping"
},
"status": 400
}
09-����-HTTP-����-��ѯ & ɾ��
�鿴��������
�� Postman ��,�� ES �������� GET ���� : http://127.0.0.1:9200/_cat/indices?v
��������·���е�_cat ��ʾ�鿴����˼, indices ��ʾ����,�������庬����Dz鿴��ǰ ES�������е���������,�ͺ��� MySQL �е� show tables �ĸо�,��������Ӧ������� :
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open shopping J0WlEhh4R7aDrfIc3AkwWQ 1 1 0 0 208b 208b
| ��ͷ | ���� |
| health | ��ǰ����������״̬: green(��Ⱥ����) yellow(������������Ⱥ������) red(���㲻����) |
| status | �������ر�״̬ |
| index | ������ |
| uuid | ����ͳһ��� |
| pri | ����Ƭ���� |
| rep | �������� |
| docs.count | �����ĵ����� |
| docs.deleted | �ĵ�ɾ��״̬(��ɾ��) |
| store.size | ����Ƭ����Ƭ����ռ�ռ��С |
| pri.store.size | ����Ƭռ�ռ��С |
�鿴��������
�� Postman ��,�� ES �������� GET ���� : http://127.0.0.1:9200/shopping
���ؽ������:
{
"shopping": {//������
"aliases": {},//����
"mappings": {},//ӳ��
"settings": {//����
"index": {//���� - ����
"creation_date": "1617861426847",//���� - ���� - ����ʱ��
"number_of_shards": "1",//���� - ���� - ����Ƭ����
"number_of_replicas": "1",//���� - ���� - ����Ƭ����
"uuid": "J0WlEhh4R7aDrfIc3AkwWQ",//���� - ���� - ����Ƭ����
"version": {//���� - ���� - ����Ƭ����
"created": "7080099"
},
"provided_name": "shopping"//���� - ���� - ����Ƭ����
}
}
}
}
ɾ������
�� Postman ��,�� ES �������� DELETE ���� : http://127.0.0.1:9200/shopping
���ؽ������:
{
"acknowledged": true
}
�ٴβ鿴��������,GET http://127.0.0.1:9200/_cat/indices?v,���ؽ������:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
�ɹ�ɾ����
10-����-HTTP-�ĵ�-����(Put & Post)
���������Ѿ���������,�����������������ĵ�,���������ݡ�������ĵ��������Ϊ��ϵ�����ݿ��еı�����,���ӵ����ݸ�ʽΪ JSON ��ʽ
�� Postman ��,�� ES �������� POST ���� : http://127.0.0.1:9200/shopping/_doc,������JSON����Ϊ:
?
{
"title":"С���ֻ�",
"category":"��",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
ע��,�˴���������ķ�ʽ����Ϊ POST,������ PUT,����ᷢ������ ��
���ؽ��:
{
"_index": "shopping",//����
"_type": "_doc",//����-�ĵ�
"_id": "ANQqsHgBaKNfVnMbhZYU",//Ψһ��ʶ,�������Ϊ MySQL �е�����,�������
"_version": 1,//�汾
"result": "created",//���,����� create ��ʾ�����ɹ�
"_shards": {//
"total": 2,//��Ƭ - ����
"successful": 1,//��Ƭ - ����
"failed": 0//��Ƭ - ����
},
"_seq_no": 0,
"_primary_term": 1
}
��������ݴ�����,����û��ָ������Ψһ�Ա�ʶ(ID),Ĭ�������, ES ���������������һ����
�����Ҫ�Զ���Ψһ�Ա�ʶ,��Ҫ�ڴ���ʱָ��: http://127.0.0.1:9200/shopping/_doc/1,������JSON����Ϊ:
{
"title":"С���ֻ�",
"category":"��",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
���ؽ������:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",//<------------------�Զ���Ψһ�Ա�ʶ
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}?�˴���Ҫע��:�����������ʱ��ȷ��������,��ô����ʽҲ����Ϊ PUT��
11-����-HTTP-��ѯ-������ѯ & ȫ��ѯ
�鿴�ĵ�ʱ,��Ҫָ���ĵ���Ψһ�Ա�ʶ,������ MySQL �����ݵ�������ѯ
�� Postman ��,�� ES �������� GET ���� : http://127.0.0.1:9200/shopping/_doc/1 ��
���ؽ������:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
���Ҳ����ڵ�����,�� ES �������� GET ���� : http://127.0.0.1:9200/shopping/_doc/1001��
���ؽ������:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"found": false
}
�鿴��������������,�� ES �������� GET ���� : http://127.0.0.1:9200/shopping/_search��
���ؽ������:
{
"took": 133,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
12-����-HTTP-ȫ���� & �ֲ��� & ɾ��
ȫ����
�������ĵ�һ��,������ͬ�� URL ��ַ����,���������仯,�Ὣԭ�е��������ݸ���
�� Postman ��,�� ES �������� POST ���� : http://127.0.0.1:9200/shopping/_doc/1
������JSON����Ϊ:
{
"title":"��Ϊ�ֻ�",
"category":"��Ϊ",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":1999.00
}
�ijɹ���,��������Ӧ���:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 2,
"result": "updated",//<-----------updated ��ʾ���ݱ�����
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
�ֲ���
������ʱ,Ҳ����ֻ��ijһ�������ݵľֲ���Ϣ
�� Postman ��,�� ES �������� POST ���� : http://127.0.0.1:9200/shopping/_update/1��
������JSON����Ϊ:
{
"doc": {
"title":"С���ֻ�",
"category":"��"
}
}
���ؽ������:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 3,
"result": "updated",//<-----------updated ��ʾ���ݱ�����
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_doc/1,�鿴������:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 3,
"_seq_no": 3,
"_primary_term": 1,
"found": true,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/hw.jpg",
"price": 1999
}
}
ɾ��
ɾ��һ���ĵ����������Ӵ������Ƴ�,��ֻ�DZ���dz���ɾ��(��ɾ��)��
�� Postman ��,�� ES �������� DELETE ���� : http://127.0.0.1:9200/shopping/_doc/1
���ؽ��:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 4,
"result": "deleted",//<---ɾ���ɹ�
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_doc/1,�鿴�Ƿ�ɾ���ɹ�:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"found": false
}
13-����-HTTP-������ѯ & ��ҳ��ѯ & ��ѯ����
������ѯ
�����������ĵ�����,(�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search):
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
URL���β�ѯ
����categoryΪС���ĵ�,�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search?q=category:С��,���ؽ������:
{
"took": 94,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
����ΪURL��������ʽ��ѯ,��������ò������Ļ�����,���߲���ֵ�������Ļ�������������Ϊ�˱�����Щ���,���ǿ���ʹ�ô�JSON������������в�ѯ��
��������β�ѯ
���´�JSON������,���Dz���categoryΪС���ĵ�,�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
?
{
"query":{
"match":{
"category":"��"
}
}
}
���ؽ������:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
�������巽ʽ�IJ�����������
���������ĵ�����,Ҳ��������,�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"match_all":{}
}
}
�������ĵ�����:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
��ѯָ���ֶ�
��������ѯָ���ֶ�,�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"match_all":{}
},
"_source":["title"]
}
���ؽ������:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "С���ֻ�"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "С���ֻ�"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "С���ֻ�"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�"
}
}
]
}
}
��ҳ��ѯ
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"match_all":{}
},
"from":0,
"size":2
}
���ؽ������:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
��ѯ����
�������ͨ���������۸���ߵ��ֻ�,�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"match_all":{}
},
"sort":{
"price":{
"order":"desc"
}
}
}
���ؽ������:
{
"took": 96,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": null,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
},
"sort": [
3999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": null,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": null,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": null,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": null,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": null,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
}
]
}
}
14-����-HTTP-��������ѯ & ��Χ��ѯ
��������ѯ
�������ҳ�С������,�۸�Ϊ3999Ԫ�ġ�(must�൱�����ݿ��&&)
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"bool":{
"must":[{
"match":{
"category":"��"
}
},{
"match":{
"price":3999.00
}
}]
}
}
}
���ؽ������:
{
"took": 134,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.3862944,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 2.3862944,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
�������ҳ�С�ͻ�Ϊ�����ӡ�(should�൱�����ݿ��||)
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"bool":{
"should":[{
"match":{
"category":"��"
}
},{
"match":{
"category":"��Ϊ"
}
}]
},
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
���ؽ������:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1.3862942,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1.3862942,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1.3862942,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
��Χ��ѯ
�������ҳ�С�ͻ�Ϊ������,�۸����2000Ԫ���ֻ���
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"bool":{
"should":[{
"match":{
"category":"��"
}
},{
"match":{
"category":"��Ϊ"
}
}],
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
}
���ؽ������:
{
"took": 72,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
15-����-HTTP-ȫ�ļ��� & ��ȫƥ�� & ������ѯ
ȫ�ļ���
�����������������,��Ʒ�����롰С����,���ؽ������Ʒ���С�С�ס��ͻ�Ϊ�ġ�
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"match":{
"category" : "��"
}
}
}
���ؽ������:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 0.6931471,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 0.6931471,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 0.6931471,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
��ȫƥ��
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"match_phrase":{
"category" : "Ϊ"
}
}
}
���ؽ������:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
������ѯ
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"query":{
"match_phrase":{
"category" : "Ϊ"
}
},
"highlight":{
"fields":{
"category":{}//<----�������ֶ�
}
}
}
���ؽ������:
{
"took": 100,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"highlight": {
"category": [
"��<em>Ϊ</em>"//<------����һ��Ϊ�֡�
]
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"highlight": {
"category": [
"��<em>Ϊ</em>"
]
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 0.6931471,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"highlight": {
"category": [
"��<em>Ϊ</em>"
]
}
}
]
}
}
16-����-HTTP-�ۺϲ�ѯ
�ۺ�����ʹ���߶� es �ĵ�����ͳ�Ʒ���,�������ϵ�����ݿ��е� group by,��Ȼ���кܶ������ľۺ�,����ȡ���ֵmax��ƽ��ֵavg�ȵȡ�
��������price�ֶν��з���:
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
?
{
"aggs":{//�ۺϲ���
"price_group":{//����,��������
"terms":{//����
"field":"price"//�����ֶ�
}
}
}
}
���ؽ������:
{
"took": 63,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "С���ֻ�",
"category": "��",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "��Ϊ�ֻ�",
"category": "��Ϊ",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1999,
"doc_count": 5
},
{
"key": 3999,
"doc_count": 1
}
]
}
}
}
���淵�ؽ���ḽ��ԭʼ���ݵġ�������Ҫ������ԭʼ���ݵĽ��,�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"aggs":{
"price_group":{
"terms":{
"field":"price"
}
}
},
"size":0
}
���ؽ������:
{
"took": 60,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1999,
"doc_count": 5
},
{
"key": 3999,
"doc_count": 1
}
]
}
}
}
����������ֻ��۸���ƽ��ֵ��
�� Postman ��,�� ES �������� GET���� : http://127.0.0.1:9200/shopping/_search,����JSON������:
{
"aggs":{
"price_avg":{//����,��������
"avg":{//��ƽ��
"field":"price"
}
}
},
"size":0
}
���ؽ������:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_avg": {
"value": 2332.3333333333335
}
}
}
17-����-HTTP-ӳ���ϵ
����������,�����������ݿ��е� database��
����������Ҫ��������(index)�е�ӳ����,���������ݿ�(database)�еı��ṹ(table)��
�������ݿ����Ҫ�����ֶ�����,����,����,Լ����;������Ҳһ��,��Ҫ֪���������������Щ�ֶ�,ÿ���ֶ�����ЩԼ����Ϣ,��ͽ���ӳ��(mapping)��
�ȴ���һ������:
# PUT http://127.0.0.1:9200/user
���ؽ��:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user"
}
����ӳ��:
# PUT http://127.0.0.1:9200/user/_mapping
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "keyword",
"index": true
},
"tel":{
"type": "keyword",
"index": false
}
}
}
���ؽ������:
{
"acknowledged": true
}
��ѯӳ��
#GET http://127.0.0.1:9200/user/_mapping
?���ؽ������:
{
"user": {
"mappings": {
"properties": {
"name": {
"type": "text"
},
"sex": {
"type": "keyword"
},
"tel": {
"type": "keyword",
"index": false
}
}
}
}
}
��������
#PUT http://127.0.0.1:9200/user/_create/1001
{
"name":"��",
"sex":"�е�",
"tel":"1111"
}
���ؽ������:
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
����name����������:
#GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"name":"С"
}
}
}
���ؽ������:
{
"took": 495,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_score": 0.2876821,
"_source": {
"name": "��",
"sex": "�е�",
"tel": "1111"
}
}
]
}
}
����sex����������:
#GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"sex":"��"
}
}
}
���ؽ������:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
�Ҳ���Ҫ�Ľ��,ֻ��ӳ��ʱ"sex"������Ϊ"keyword"��
"sex"ֻ����ȫΪ���еġ�,���ܵó�ԭ���ݡ�
#GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"sex":"�е�"
}
}
}
���ؽ������:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_score": 0.2876821,
"_source": {
"name": "��",
"sex": "�е�",
"tel": "1111"
}
}
]
}
}
��ѯ�绰
# GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"tel":"11"
}
}
}
���ؽ������:
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "user",
"node": "4P7dIRfXSbezE5JTiuylew",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [tel] since it is not indexed."
}
}
}
]
},
"status": 400
}
����ֻ��ӳ��ʱ"tel"��"index"Ϊfalse��
18-����-JavaAPI-������
�½�Maven���̡�
��������:
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch �Ŀͻ��� -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch ���� 2.x �� log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<!-- junit ��Ԫ���� -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
HelloElasticsearch
import java.io.IOException;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
public class HelloElasticsearch {
public static void main(String[] args) throws IOException {
// �����ͻ��˶���
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// ...
System.out.println(client);
// �رտͻ�������
client.close();
}
}
19-����-JavaAPI-����-����
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import java.io.IOException;
public class CreateIndex {
public static void main(String[] args) throws IOException {
// �����ͻ��˶���
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// �������� - �������
CreateIndexRequest request = new CreateIndexRequest("user2");
// ��������,��ȡ��Ӧ
CreateIndexResponse response = client.indices().create(request,
RequestOptions.DEFAULT);
boolean acknowledged = response.isAcknowledged();
// ��Ӧ״̬
System.out.println("����״̬ = " + acknowledged);
// �رտͻ�������
client.close();
}
}
��̨��ӡ:
���� 09, 2021 2:12:08 ���� org.elasticsearch.client.RestClient logResponse
����: request [PUT http://localhost:9200/user2?master_timeout=30s&include_type_name=true&timeout=30s] returned 1 warnings: [299 Elasticsearch-7.8.0-757314695644ea9a1dc2fecd26d1a43856725e65 "[types removal] Using include_type_name in create index requests is deprecated. The parameter will be removed in the next major version."]
����״̬ = true
Process finished with exit code 0
20-����-JavaAPI-����-��ѯ & ɾ��
��ѯ
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import java.io.IOException;
public class SearchIndex {
public static void main(String[] args) throws IOException {
// �����ͻ��˶���
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// ��ѯ���� - �������
GetIndexRequest request = new GetIndexRequest("user2");
// ��������,��ȡ��Ӧ
GetIndexResponse response = client.indices().get(request,
RequestOptions.DEFAULT);
System.out.println("aliases:"+response.getAliases());
System.out.println("mappings:"+response.getMappings());
System.out.println("settings:"+response.getSettings());
client.close();
}
}
��̨��ӡ:
aliases:{user2=[]}
mappings:{user2=org.elasticsearch.cluster.metadata.MappingMetadata@ad700514}
settings:{user2={"index.creation_date":"1617948726976","index.number_of_replicas":"1","index.number_of_shards":"1","index.provided_name":"user2","index.uuid":"UGZ1ntcySnK6hWyP2qoVpQ","index.version.created":"7080099"}}
Process finished with exit code 0
ɾ��
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import java.io.IOException;
public class DeleteIndex {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// ɾ������ - �������
DeleteIndexRequest request = new DeleteIndexRequest("user2");
// ��������,��ȡ��Ӧ
AcknowledgedResponse response = client.indices().delete(request,RequestOptions.DEFAULT);
// �������
System.out.println("������� : " + response.isAcknowledged());
client.close();
}
}
��̨��ӡ:
������� : true
Process finished with exit code 0
21-����-JavaAPI-�ĵ�-���� & ��
�ع�
��������Ƶ��ʹ����������Elasticsearch�ر����Ĵ���,�����������������ع���
public class SomeClass {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
...
client.close();
}
}
�ع���Ĵ���:
import org.elasticsearch.client.RestHighLevelClient;
public interface ElasticsearchTask {
void doSomething(RestHighLevelClient client) throws Exception;
}
public class ConnectElasticsearch{
public static void connect(ElasticsearchTask task){
// �����ͻ��˶���
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
try {
task.doSomething(client);
// �رտͻ�������
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
������,�������Elasticsearch���һЩ����,�ͱ�дһ��lambdaʽ���ɡ�
public class SomeClass {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//do something
});
}
}
����
import com.fasterxml.jackson.databind.ObjectMapper;
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.model.User;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.xcontent.XContentType;
public class InsertDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
// �����ĵ� - �������
IndexRequest request = new IndexRequest();
// ����������Ψһ�Ա�ʶ
request.index("user").id("1001");
// �������ݶ���
User user = new User();
user.setName("zhangsan");
user.setAge(30);
user.setSex("��");
ObjectMapper objectMapper = new ObjectMapper();
String productJson = objectMapper.writeValueAsString(user);
// �����ĵ�����,���ݸ�ʽΪ JSON ��ʽ
request.source(productJson, XContentType.JSON);
// �ͻ��˷�������,��ȡ��Ӧ����
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
3.��ӡ�����Ϣ
System.out.println("_index:" + response.getIndex());
System.out.println("_id:" + response.getId());
System.out.println("_result:" + response.getResult());
});
}
}
��̨��ӡ:
_index:user
_id:1001
_result:UPDATED
Process finished with exit code 0
��
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.xcontent.XContentType;
public class UpdateDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
// ���ĵ� - �������
UpdateRequest request = new UpdateRequest();
// �����IJ���
request.index("user").id("1001");
// ����������,�����ݽ�����
request.doc(XContentType.JSON, "sex", "Ů");
// �ͻ��˷�������,��ȡ��Ӧ����
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println("_index:" + response.getIndex());
System.out.println("_id:" + response.getId());
System.out.println("_result:" + response.getResult());
});
}
}
��̨��ӡ:
_index:user
_id:1001
_result:UPDATED
Process finished with exit code 0
22-����-JavaAPI-�ĵ�-��ѯ & ɾ��
��ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.client.RequestOptions;
public class GetDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//1.�����������
GetRequest request = new GetRequest().index("user").id("1001");
//2.�ͻ��˷�������,��ȡ��Ӧ����
GetResponse response = client.get(request, RequestOptions.DEFAULT);
3.��ӡ�����Ϣ
System.out.println("_index:" + response.getIndex());
System.out.println("_type:" + response.getType());
System.out.println("_id:" + response.getId());
System.out.println("source:" + response.getSourceAsString());
});
}
}
��̨��ӡ:
_index:user
_type:_doc
_id:1001
source:{"name":"zhangsan","age":30,"sex":"��"}
Process finished with exit code 0
?ɾ��
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.client.RequestOptions;
public class DeleteDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//�����������
DeleteRequest request = new DeleteRequest().index("user").id("1001");
//�ͻ��˷�������,��ȡ��Ӧ����
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
//��ӡ��Ϣ
System.out.println(response.toString());
});
}
}
��̨��ӡ:
DeleteResponse[index=user,type=_doc,id=1001,version=16,result=deleted,shards=ShardInfo{total=2, successful=1, failures=[]}]
Process finished with exit code 0
23-����-JavaAPI-�ĵ�-�������� & ����ɾ��
��������
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.xcontent.XContentType;
public class BatchInsertDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//�������������������
BulkRequest request = new BulkRequest();
request.add(new
IndexRequest().index("user").id("1001").source(XContentType.JSON, "name",
"zhangsan"));
request.add(new
IndexRequest().index("user").id("1002").source(XContentType.JSON, "name",
"lisi"));
request.add(new
IndexRequest().index("user").id("1003").source(XContentType.JSON, "name",
"wangwu"));
//�ͻ��˷�������,��ȡ��Ӧ����
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//��ӡ�����Ϣ
System.out.println("took:" + responses.getTook());
System.out.println("items:" + responses.getItems());
});
}
}
��̨��ӡ
took:294ms
items:[Lorg.elasticsearch.action.bulk.BulkItemResponse;@2beee7ff
Process finished with exit code 0
����ɾ��
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.client.RequestOptions;
public class BatchDeleteDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//��������ɾ���������
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest().index("user").id("1001"));
request.add(new DeleteRequest().index("user").id("1002"));
request.add(new DeleteRequest().index("user").id("1003"));
//�ͻ��˷�������,��ȡ��Ӧ����
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//��ӡ�����Ϣ
System.out.println("took:" + responses.getTook());
System.out.println("items:" + responses.getItems());
});
}
}
��̨��ӡ
took:108ms
items:[Lorg.elasticsearch.action.bulk.BulkItemResponse;@7b02881e
Process finished with exit code 0
24-����-JavaAPI-�ĵ�-����ѯ-ȫ����ѯ
��������������
public class BatchInsertDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//�������������������
BulkRequest request = new BulkRequest();
request.add(new IndexRequest().index("user").id("1001").source(XContentType.JSON, "name", "zhangsan", "age", "10", "sex","Ů"));
request.add(new IndexRequest().index("user").id("1002").source(XContentType.JSON, "name", "lisi", "age", "30", "sex","Ů"));
request.add(new IndexRequest().index("user").id("1003").source(XContentType.JSON, "name", "wangwu1", "age", "40", "sex","��"));
request.add(new IndexRequest().index("user").id("1004").source(XContentType.JSON, "name", "wangwu2", "age", "20", "sex","Ů"));
request.add(new IndexRequest().index("user").id("1005").source(XContentType.JSON, "name", "wangwu3", "age", "50", "sex","��"));
request.add(new IndexRequest().index("user").id("1006").source(XContentType.JSON, "name", "wangwu4", "age", "20", "sex","��"));
//�ͻ��˷�������,��ȡ��Ӧ����
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//��ӡ�����Ϣ
System.out.println("took:" + responses.getTook());
System.out.println("items:" + responses.getItems());
});
}
}
��̨��ӡ
took:168ms
items:[Lorg.elasticsearch.action.bulk.BulkItemResponse;@2beee7ff
Process finished with exit code 0
��ѯ������������
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class QueryDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
// ���������������
SearchRequest request = new SearchRequest();
request.indices("user");
// ������ѯ��������
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// ��ѯ��������
sourceBuilder.query(QueryBuilders.matchAllQuery());
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ��ѯƥ��
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//���ÿ����ѯ�Ľ����Ϣ
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
});
}
}
��̨��ӡ
took:2ms
timeout:false
total:6 hits
MaxScore:1.0
hits========>>
{"name":"zhangsan","age":"10","sex":"Ů"}
{"name":"lisi","age":"30","sex":"Ů"}
{"name":"wangwu1","age":"40","sex":"��"}
{"name":"wangwu2","age":"20","sex":"Ů"}
{"name":"wangwu3","age":"50","sex":"��"}
{"name":"wangwu4","age":"20","sex":"��"}
<<========
Process finished with exit code 0
25-����-JavaAPI-�ĵ�-����ѯ-��ҳ��ѯ & ������ѯ & ��ѯ����
������ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_CONDITION = client -> {
// ���������������
SearchRequest request = new SearchRequest();
request.indices("user");
// ������ѯ��������
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery("age", "30"));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ��ѯƥ��
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//���ÿ����ѯ�Ľ����Ϣ
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_CONDITION);
}
}
��̨��ӡ
took:1ms
timeout:false
total:1 hits
MaxScore:1.0
hits========>>
{"name":"lisi","age":"30","sex":"Ů"}
<<========
��ҳ��ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_PAGING = client -> {
// ���������������
SearchRequest request = new SearchRequest();
request.indices("user");
// ������ѯ��������
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
// ��ҳ��ѯ
// ��ǰҳ��ʵ����(��һ�����ݵ�˳���), from
sourceBuilder.from(0);
// ÿҳ��ʾ������ size
sourceBuilder.size(2);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ��ѯƥ��
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//���ÿ����ѯ�Ľ����Ϣ
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_CONDITION);
}
}
��̨��ӡ
took:1ms
timeout:false
total:6 hits
MaxScore:1.0
hits========>>
{"name":"zhangsan","age":"10","sex":"Ů"}
{"name":"lisi","age":"30","sex":"Ů"}
<<========
��ѯ����
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_ORDER = client -> {
// ���������������
SearchRequest request = new SearchRequest();
request.indices("user");
// ������ѯ��������
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
// ����
sourceBuilder.sort("age", SortOrder.ASC);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ��ѯƥ��
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//���ÿ����ѯ�Ľ����Ϣ
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_ORDER);
}
}
��̨��ӡ
took:1ms
timeout:false
total:6 hits
MaxScore:NaN
hits========>>
{"name":"zhangsan","age":"10","sex":"Ů"}
{"name":"wangwu2","age":"20","sex":"Ů"}
{"name":"wangwu4","age":"20","sex":"��"}
{"name":"lisi","age":"30","sex":"Ů"}
{"name":"wangwu1","age":"40","sex":"��"}
{"name":"wangwu3","age":"50","sex":"��"}
<<========
26-����-JavaAPI-�ĵ�-����ѯ-��ϲ�ѯ & ��Χ��ѯ
��ϲ�ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_BOOL_CONDITION = client -> {
// ���������������
SearchRequest request = new SearchRequest();
request.indices("user");
// ������ѯ��������
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// �������
boolQueryBuilder.must(QueryBuilders.matchQuery("age", "30"));
// һ������
boolQueryBuilder.mustNot(QueryBuilders.matchQuery("name", "zhangsan"));
// ���ܰ���
boolQueryBuilder.should(QueryBuilders.matchQuery("sex", "��"));
sourceBuilder.query(boolQueryBuilder);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ��ѯƥ��
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//���ÿ����ѯ�Ľ����Ϣ
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_BOOL_CONDITION);
}
}
��̨��ӡ
took:28ms
timeout:false
total:1 hits
MaxScore:1.0
hits========>>
{"name":"lisi","age":"30","sex":"Ů"}
<<========
Process finished with exit code 0
��Χ��ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_RANGE = client -> {
// ���������������
SearchRequest request = new SearchRequest();
request.indices("user");
// ������ѯ��������
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("age");
// ���ڵ���
//rangeQuery.gte("30");
// С�ڵ���
rangeQuery.lte("40");
sourceBuilder.query(rangeQuery);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ��ѯƥ��
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//���ÿ����ѯ�Ľ����Ϣ
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_RANGE);
}
}
��̨��ӡ
took:1ms
timeout:false
total:5 hits
MaxScore:1.0
hits========>>
{"name":"zhangsan","age":"10","sex":"Ů"}
{"name":"lisi","age":"30","sex":"Ů"}
{"name":"wangwu1","age":"40","sex":"��"}
{"name":"wangwu2","age":"20","sex":"Ů"}
{"name":"wangwu4","age":"20","sex":"��"}
<<========
Process finished with exit code 0
27-����-JavaAPI-�ĵ�-����ѯ-ģ����ѯ & ������ѯ
ģ����ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_FUZZY_CONDITION = client -> {
// ���������������
SearchRequest request = new SearchRequest();
request.indices("user");
// ������ѯ��������
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.fuzzyQuery("name","wangwu").fuzziness(Fuzziness.ONE));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ��ѯƥ��
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//���ÿ����ѯ�Ľ����Ϣ
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
// ConnectElasticsearch.connect(SEARCH_ALL);
// ConnectElasticsearch.connect(SEARCH_BY_CONDITION);
// ConnectElasticsearch.connect(SEARCH_BY_PAGING);
// ConnectElasticsearch.connect(SEARCH_WITH_ORDER);
// ConnectElasticsearch.connect(SEARCH_BY_BOOL_CONDITION);
// ConnectElasticsearch.connect(SEARCH_BY_RANGE);
ConnectElasticsearch.connect(SEARCH_BY_FUZZY_CONDITION);
}
}
��̨��ӡ
took:152ms
timeout:false
total:4 hits
MaxScore:1.2837042
hits========>>
{"name":"wangwu1","age":"40","sex":"��"}
{"name":"wangwu2","age":"20","sex":"Ů"}
{"name":"wangwu3","age":"50","sex":"��"}
{"name":"wangwu4","age":"20","sex":"��"}
<<========
Process finished with exit code 0
������ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermsQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_HIGHLIGHT = client -> {
// ������ѯ
SearchRequest request = new SearchRequest().indices("user");
//2.������ѯ�����幹����
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//������ѯ��ʽ:������ѯ
TermsQueryBuilder termsQueryBuilder =
QueryBuilders.termsQuery("name","zhangsan");
//���ò�ѯ��ʽ
sourceBuilder.query(termsQueryBuilder);
//���������ֶ�
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");//���ñ�ǩǰ
highlightBuilder.postTags("</font>");//���ñ�ǩ��
highlightBuilder.field("name");//���ø����ֶ�
//���ø�����������
sourceBuilder.highlighter(highlightBuilder);
//����������
request.source(sourceBuilder);
//3.�ͻ��˷�������,��ȡ��Ӧ����
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.��ӡ��Ӧ���
SearchHits hits = response.getHits();
System.out.println("took::"+response.getTook());
System.out.println("time_out::"+response.isTimedOut());
System.out.println("total::"+hits.getTotalHits());
System.out.println("max_score::"+hits.getMaxScore());
System.out.println("hits::::>>");
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
//��ӡ�������
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
System.out.println(highlightFields);
}
System.out.println("<<::::");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_HIGHLIGHT);
}
}
��̨��ӡ
took::672ms
time_out::false
total::1 hits
max_score::1.0
hits::::>>
{"name":"zhangsan","age":"10","sex":"Ů"}
{name=[name], fragments[[<font color='red'>zhangsan</font>]]}
<<::::
Process finished with exit code 0
28-����-JavaAPI-�ĵ�-����ѯ-���ֵ��ѯ & �����ѯ
���ֵ��ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermsQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_MAX = client -> {
// ������ѯ
SearchRequest request = new SearchRequest().indices("user");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.aggregation(AggregationBuilders.max("maxAge").field("age"));
//����������
request.source(sourceBuilder);
//3.�ͻ��˷�������,��ȡ��Ӧ����
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.��ӡ��Ӧ���
SearchHits hits = response.getHits();
System.out.println(response);
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_MAX);
}
}
{"took":16,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":6,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"user","_type":"_doc","_id":"1001","_score":1.0,"_source":{"name":"zhangsan","age":"10","sex":"Ů"}},{"_index":"user","_type":"_doc","_id":"1002","_score":1.0,"_source":{"name":"lisi","age":"30","sex":"Ů"}},{"_index":"user","_type":"_doc","_id":"1003","_score":1.0,"_source":{"name":"wangwu1","age":"40","sex":"��"}},{"_index":"user","_type":"_doc","_id":"1004","_score":1.0,"_source":{"name":"wangwu2","age":"20","sex":"Ů"}},{"_index":"user","_type":"_doc","_id":"1005","_score":1.0,"_source":{"name":"wangwu3","age":"50","sex":"��"}},{"_index":"user","_type":"_doc","_id":"1006","_score":1.0,"_source":{"name":"wangwu4","age":"20","sex":"��"}}]},"aggregations":{"max#maxAge":{"value":50.0}}}
Process finished with exit code 0
�����ѯ
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermsQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_GROUP = client -> {
SearchRequest request = new SearchRequest().indices("user");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.aggregation(AggregationBuilders.terms("age_groupby").field("age"));
//����������
request.source(sourceBuilder);
//3.�ͻ��˷�������,��ȡ��Ӧ����
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.��ӡ��Ӧ���
SearchHits hits = response.getHits();
System.out.println(response);
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_GROUP);
}
}
��̨��ӡ
{"took":10,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":6,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"user","_type":"_doc","_id":"1001","_score":1.0,"_source":{"name":"zhangsan","age":"10","sex":"Ů"}},{"_index":"user","_type":"_doc","_id":"1002","_score":1.0,"_source":{"name":"lisi","age":"30","sex":"Ů"}},{"_index":"user","_type":"_doc","_id":"1003","_score":1.0,"_source":{"name":"wangwu1","age":"40","sex":"��"}},{"_index":"user","_type":"_doc","_id":"1004","_score":1.0,"_source":{"name":"wangwu2","age":"20","sex":"Ů"}},{"_index":"user","_type":"_doc","_id":"1005","_score":1.0,"_source":{"name":"wangwu3","age":"50","sex":"��"}},{"_index":"user","_type":"_doc","_id":"1006","_score":1.0,"_source":{"name":"wangwu4","age":"20","sex":"��"}}]},"aggregations":{"lterms#age_groupby":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":20,"doc_count":2},{"key":10,"doc_count":1},{"key":30,"doc_count":1},{"key":40,"doc_count":1},{"key":50,"doc_count":1}]}}}
Process finished with exit code 0
��3�� Elasticsearch����
29-����-���
- ���� & ��Ⱥ
��̨ Elasticsearch �������ṩ����,�����������ĸ�������,���������ֵ,���������ܾͻ�������������,��������������,һ�㶼��������ָ����������Ⱥ�С����˸�������,���������Ҳ������������:
- ��̨�����洢��������
- �����������׳��ֵ������,��ʵ�ָ߿���
- ������IJ���������������
���÷�������Ⱥʱ,��Ⱥ�нڵ�����û������,���ڵ��� 2 ���ڵ�Ϳ��Կ����Ǽ�Ⱥ�ˡ�һ����ڸ����ܼ��߿��÷��������Ǽ�Ⱥ�нڵ��������� 3 ������,��֮,��Ⱥ���������,�����ݴ���
- ��Ⱥ Cluster
һ����Ⱥ������һ�������������ڵ���֯��һ��,��ͬ��������������,��һ���ṩ�������������ܡ�**һ�� Elasticsearch ��Ⱥ��һ��Ψһ�����ֱ�ʶ,�������Ĭ�Ͼ��ǡ�elasticsearch���������������Ҫ��,��Ϊһ���ڵ�ֻ��ͨ��ָ��ij����Ⱥ������,�����������Ⱥ��
- �ڵ� Node
��Ⱥ�а����ܶ������, һ���ڵ�������е�һ���������� ��Ϊ��Ⱥ��һ����,���洢����,���뼯Ⱥ���������������ܡ�
һ���ڵ�Ҳ����һ����������ʶ��,Ĭ�������,���������һ�����������������ɫ������,������ֻ���������ʱ����ڵ㡣������ֶ��ڹ���������˵ͦ��Ҫ��,��Ϊ���������������,���ȥȷ�������е���Щ��������Ӧ�� Elasticsearch ��Ⱥ�е���Щ�ڵ㡣
һ���ڵ����ͨ�����ü�Ⱥ���Ƶķ�ʽ������һ��ָ���ļ�Ⱥ��Ĭ�������,ÿ���ڵ㶼�ᱻ���ż��뵽һ��������elasticsearch���ļ�Ⱥ��,����ζ��,�������������������������ɸ��ڵ�,���ٶ������ܹ�����ֱ˴�,���ǽ����Զ����γɲ����뵽һ��������elasticsearch���ļ�Ⱥ�С�
��һ����Ⱥ��,ֻҪ����,����ӵ���������ڵ㡣����,�����ǰ���������û�������κ� Elasticsearch �ڵ�,��ʱ����һ���ڵ�,��Ĭ�ϴ���������һ��������elasticsearch���ļ�Ⱥ��
30-����-Windows��Ⱥ����
����Ⱥ
һ������ elasticsearch-cluster �ļ���
���� elasticsearch-7.8.0-cluster �ļ���,���ڲ��������� elasticsearch ����

�����ļ�Ⱥ�ļ�Ŀ¼��ÿ���ڵ�� config/elasticsearch.yml �����ļ�
node-1001 �ڵ�
#�ڵ� 1 ��������Ϣ:
#��Ⱥ����,�ڵ�֮��Ҫ����һ��
cluster.name: my-elasticsearch
#�ڵ�����,��Ⱥ��ҪΨһ
node.name: node-1001
node.master: true
node.data: true
#ip ��ַ
network.host: localhost
#http �˿�
http.port: 1001
#tcp �����˿�
transport.tcp.port: 9301
#discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
#��Ⱥ�ڵĿ��Ա�ѡΪ���ڵ�Ľڵ��б�
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#��������
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1002 �ڵ�
#�ڵ� 2 ��������Ϣ:
#��Ⱥ����,�ڵ�֮��Ҫ����һ��
cluster.name: my-elasticsearch
#�ڵ�����,��Ⱥ��ҪΨһ
node.name: node-1002
node.master: true
node.data: true
#ip ��ַ
network.host: localhost
#http �˿�
http.port: 1002
#tcp �����˿�
transport.tcp.port: 9302
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#��Ⱥ�ڵĿ��Ա�ѡΪ���ڵ�Ľڵ��б�
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#��������
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1003 �ڵ�
#�ڵ� 3 ��������Ϣ:
#��Ⱥ����,�ڵ�֮��Ҫ����һ��
cluster.name: my-elasticsearch
#�ڵ�����,��Ⱥ��ҪΨһ
node.name: node-1003
node.master: true
node.data: true
#ip ��ַ
network.host: localhost
#http �˿�
http.port: 1003
#tcp �����˿�
transport.tcp.port: 9303
#��ѡ���ڵ�ĵ�ַ,�ڿ����������Ա�ѡΪ���ڵ�
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#��Ⱥ�ڵĿ��Ա�ѡΪ���ڵ�Ľڵ��б�
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#��������
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
?��������б�Ҫ,ɾ��ÿ���ڵ��е� data Ŀ¼���������� ��
������Ⱥ
�ֱ�����˫��ִ�нڵ��bin/elasticsearch.bat, �����ڵ������(���Ա�дһ���ű�����),������,���Զ�����ָ�����Ƶļ�Ⱥ��
���Լ�Ⱥ
һ����Postman,�鿴��Ⱥ״̬
GET http://127.0.0.1:1001/_cluster/healthGET http://127.0.0.1:1002/_cluster/healthGET http://127.0.0.1:1003/_cluster/health
���ؽ����Ϊ����:
{
"cluster_name": "my-application",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
status�ֶ�ָʾ�ŵ�ǰ��Ⱥ���������Ƿ�������������������ɫ��������:
green:���е�����Ƭ������Ƭ���������С�
yellow:���е�����Ƭ����������,���������еĸ�����Ƭ���������С�
red:������Ƭû���������С�
������Postman,��һ�ڵ���������,��һ�ڵ��ȡ����
��Ⱥ�е�node-1001�ڵ���������:
#PUT http://127.0.0.1:1001/user���ؽ��:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user"
}
��Ⱥ�е�node-1003�ڵ��ȡ����:
#GET http://127.0.0.1:1003/user
���ؽ��:
{
"user": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1617993035885",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "XJKERwQlSJ6aUxZEN2EV0w",
"version": {
"created": "7080099"
},
"provided_name": "user"
}
}
}
}
�����1003��������,ͬ����1001Ҳ�ܻ�ȡ������Ϣ,����Ǽ�Ⱥ������
31-����-Linux���ڵ㲿��
������װ
һ����������
������ѹ����
# ��ѹ��
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module
# ����
mv elasticsearch-7.8.0 es
���������û�
��Ϊ��ȫ����, Elasticsearch ������ root �û�ֱ������,����Ҫ�������û�,�� root �û��д������û���
useradd es #���� es �û�
passwd es #Ϊ es �û���������
userdel -r es #�������,����ɾ���ټ�
chown -R es:es /opt/module/es #�ļ���������
�ġ��������ļ�
��/opt/module/es/config/elasticsearch.yml�ļ���
# ������������
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
��/etc/security/limits.conf
# ���ļ�ĩβ��������������
# ÿ�����̿��Դ��ļ���������
es soft nofile 65536
es hard nofile 65536
��/etc/security/limits.d/20-nproc.conf
# ���ļ�ĩβ��������������
# ÿ�����̿��Դ��ļ���������
es soft nofile 65536
es hard nofile 65536
# ����ϵͳ�����ÿ���û������Ľ�����������
* hard nproc 4096
# ע: * ���� Linux �����û�����
��/etc/sysctl.conf
# ���ļ���������������
# һ�����̿���ӵ�е� VMA(�����ڴ�����)������,Ĭ��ֵΪ 65536
vm.max_map_count=655360
���¼���
sysctl -p
��������
ʹ�� ES �û�����
cd /opt/module/es/
#����
bin/elasticsearch
#��̨����
bin/elasticsearch -d
����ʱ,�ᶯ̬�����ļ�,����ļ������û���ƥ��,�ᷢ������,��Ҫ���½������û����û���
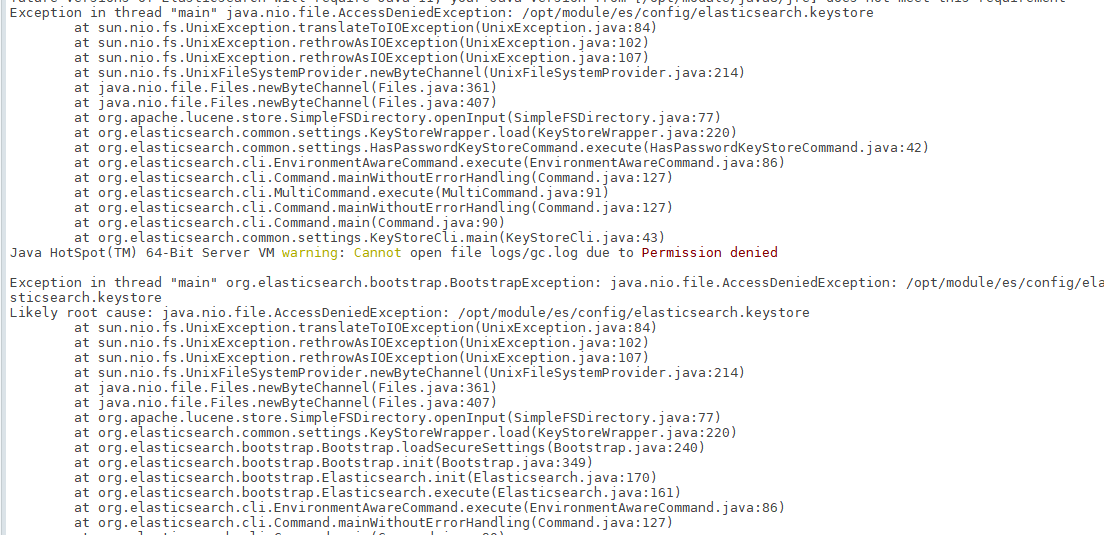
?�رշ���ǽ
#��ʱ�رշ���ǽ
systemctl stop firewalld
#���ùرշ���ǽ
systemctl enable firewalld.service #����ǽ��������Ч,�����Ḵԭ
systemctl disable firewalld.service #�رշ���ǽ,��������Ч,�����Ḵԭ
��������
������������ַ: http://linux1:9200/

32-����-Linux��Ⱥ����
������װ
һ����������
������ѹ����
# ��ѹ��
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module
# ����
mv elasticsearch-7.8.0 es-cluster
�������ַ��������ڵ�: linux2, linux3
���������û�
��Ϊ��ȫ����, Elasticsearch ������ root �û�ֱ������,����Ҫ�������û�,�� root �û��д������û���
useradd es #���� es �û�
passwd es #Ϊ es �û���������
userdel -r es #�������,����ɾ���ټ�
chown -R es:es /opt/module/es #�ļ���������
�ġ��������ļ�
��/opt/module/es/config/elasticsearch.yml �ļ�,�ַ��ļ���
# ������������
#��Ⱥ����
cluster.name: cluster-es
#�ڵ�����, ÿ���ڵ�����Ʋ����ظ�
node.name: node-1
#ip ��ַ, ÿ���ڵ�ĵ�ַ�����ظ�
network.host: linux1
#�Dz������ʸ����ڵ�
node.master: true
node.data: true
http.port: 9200
# head �����Ҫ�������������
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x ֮������������,��ʼ��һ���µļ�Ⱥʱ��Ҫ��������ѡ�� master
cluster.initial_master_nodes: ["node-1"]
#es7.x ֮������������,�ڵ㷢��
discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#��Ⱥ��ͬʱ�����������������,Ĭ���� 2 ��
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#���ӻ�ɾ���ڵ㼰���ؾ���ʱ�����ָ����̸߳���,Ĭ�� 4 ��
cluster.routing.allocation.node_concurrent_recoveries: 16
#��ʼ�����ݻָ�ʱ,�����ָ��̵߳ĸ���,Ĭ�� 4 ��
cluster.routing.allocation.node_initial_primaries_recoveries: 16
��/etc/security/limits.conf ,�ַ��ļ�
# ���ļ�ĩβ��������������
es soft nofile 65536
es hard nofile 65536
��/etc/security/limits.d/20-nproc.conf,�ַ��ļ�?
# ���ļ�ĩβ��������������
es soft nofile 65536
es hard nofile 65536
\* hard nproc 4096
\# ע: * ���� Linux �����û�����
��/etc/sysctl.conf
# ���ļ���������������
vm.max_map_count=655360
���¼���
sysctl -p
��������
�ֱ��ڲ�ͬ�ڵ������� ES ����
cd /opt/module/es-cluster
#����
bin/elasticsearch
#��̨����
bin/elasticsearch -d
���Լ�Ⱥ

��4�� Elasticsearch����
33-����-���ĸ���
����Index?
һ����������һ��ӵ�м��������������ĵ��ļ��ϡ�����˵,�������һ���ͻ����ݵ�����,��һ����ƷĿ¼������,����һ���������ݵ�������һ��������һ����������ʶ(����ȫ����Сд��ĸ),���ҵ�����Ҫ����������е��ĵ��������������������º�ɾ��(CRUD)��ʱ��,��Ҫʹ�õ�������֡���һ����Ⱥ��,���Զ���������������
�����������ݱ�������,�����ĺô��ǿ�����߲�ѯ�ٶ�,����:�»��ֵ�ǰ���Ŀ¼������������˼,Ŀ¼������߲�ѯ�ٶȡ�
Elasticsearch �����ľ���:һ����ƶ���Ϊ��������������ܡ�
����Type
��һ��������,����Զ���һ�ֻ�������͡�
һ�����������������һ�����ϵķ���/����,��������ȫ����������ͨ��,��Ϊ��
��һ�鹲ͬ�ֶε��ĵ�����һ�����͡���ͬ�İ汾,���ͷ����˲�ͬ�ı仯��
| �汾 | Type |
|---|---|
| 5.x | ֧�ֶ��� type |
| 6.x | ֻ����һ�� type |
| 7.x | Ĭ�ϲ���֧���Զ�����������(Ĭ������Ϊ: _doc) |
�ĵ�Document
һ���ĵ���һ���ɱ������Ļ�����Ϣ��Ԫ,Ҳ����һ�����ݡ�
����:�����ӵ��ijһ���ͻ����ĵ�,ijһ����Ʒ��һ���ĵ�,��Ȼ,Ҳ����ӵ��ij��������һ���ĵ����ĵ��� JSON(Javascript Object Notation)��ʽ����ʾ,�� JSON ��һ���������ڵĻ��������ݽ�����ʽ,��һ�� index/type ����,����Դ洢�������ĵ���
�ֶ�Field
�൱�������ݱ����ֶ�,���ĵ����ݸ��ݲ�ͬ���Խ��еķ����ʶ��
ӳ��Mapping
mapping �Ǵ������ݵķ�ʽ��������һЩ����,��:ij���ֶε��������͡�Ĭ��ֵ�����������Ƿ������ȵȡ���Щ����ӳ������������õ�,�������Ǵ��� ES �������ݵ�һЩʹ�ù�������Ҳ����ӳ��,�������Ź��������ݶ�������ߺܴ�,��˲���Ҫ����ӳ��,������Ҫ˼����ν���ӳ����ܶ����ܸ��á�
��ƬShards
һ���������Դ洢���������ڵ�Ӳ�����ƵĴ������ݡ�����,һ������ 10 ���ĵ�����
������ռ�� 1TB �Ĵ��̿ռ�,����һ�ڵ㶼����û��������Ĵ��̿ռ䡣 ���ߵ����ڵ㴦����������,��Ӧ̫����Ϊ�˽���������,**Elasticsearch �ṩ�˽��������ֳɶ�ݵ�����,ÿһ�ݾͳ�֮Ϊ��Ƭ��**���㴴��һ��������ʱ��,�����ָ������Ҫ�ķ�Ƭ��������ÿ����Ƭ����Ҳ��һ���������Ʋ��Ҷ����ġ�������,��������������Ա����õ���Ⱥ�е��κνڵ��ϡ�
��Ƭ����Ҫ,��Ҫ���������ԭ��:
- ������ˮƽ�ָ� / ��չ�������������
- �������ڷ�Ƭ֮�Ͻ��зֲ�ʽ�ġ����еIJ���,�����������/��������
����һ����Ƭ�����ֲ�,�����ĵ������ۺϺ���������,����ȫ�� Elasticsearch ������,������Ϊ�û�������˵,��Щ��������,������ֹ��ġ�
�������ĸ�����,һ�� Lucene ���� ������ Elasticsearch ���� ��Ƭ �� һ��Elasticsearch ���� �Ƿ�Ƭ�ļ��ϡ� �� Elasticsearch ��������������ʱ��, �����Ͳ�ѯ��ÿһ�����������ķ�Ƭ(Lucene ����),Ȼ��ϲ�ÿ����Ƭ�Ľ����һ��ȫ�ֵĽ������
Lucene �� Apache ��������� Jakarta ��Ŀ���һ������Ŀ,�ṩ��һ����ȴǿ���Ӧ�ó�ʽ�ӿ�,�ܹ���ȫ����������Ѱ���� Java ���������� Lucene ��һ���������ѿ�Դ���ߡ����䱾������, Lucene �ǵ�ǰ�Լ�����������ܻ�ӭ����� Java ��Ϣ��������⡣�� Lucene ֻ��һ���ṩȫ�������������ĺ��Ĺ��߰�,������ʹ��������Ҫһ�����Ƶķ����ܴ��������Ӧ�á�
Ŀǰ���������е�������������,�����ľ�����: Elasticsearch �� Solr,������ǻ��� Lucene ���,���Զ�����������������������������������ں���ͬ,�������߳��˷�������װ�����𡢹�������Ⱥ����,�������ݵIJ��� �ġ����ӡ����桢��ѯ�ȵȶ�ʮ�����ơ�
����Replicas
��һ������ / �ƵĻ�����,ʧ����ʱ�����ܷ���,��ij����Ƭ/�ڵ㲻֪��ô�ľʹ���
����״̬,���������κ�ԭ����ʧ��,���������,��һ������ת�ƻ����Ƿdz����ò�����ǿ���Ƽ��ġ�Ϊ��Ŀ��, Elasticsearch �����㴴����Ƭ��һ�ݻ��ݿ���,��Щ�����������Ʒ�Ƭ(����)��
���Ʒ�Ƭ֮������Ҫ,��������Ҫԭ��:
- �ڷ�Ƭ/�ڵ�ʧ�ܵ������,�ṩ�˸߿���������Ϊ���ԭ��,ע����Ʒ�Ƭ�Ӳ���ԭ/��Ҫ(original/primary)��Ƭ����ͬһ�ڵ����Ƿdz���Ҫ�ġ�
- ��չ���������/������,��Ϊ�������������еĸ����ϲ������С�
��֮,ÿ���������Ա��ֳɶ����Ƭ��һ������Ҳ���Ա����� 0 ��(��˼��û�и���)���Ρ�һ��������,ÿ����������������Ƭ(��Ϊ����Դ��ԭ���ķ�Ƭ)���Ʒ�Ƭ(����Ƭ�Ŀ���)֮��
��Ƭ���Ƶ���������������������ʱ��ָ��������������֮��,��������κ�ʱ��̬�ظı临�Ƶ�����,�������º��ܸı��Ƭ��������
Ĭ�������,Elasticsearch �е�ÿ����������Ƭ 1 ������Ƭ�� 1 ������,����ζ��,�����ļ�Ⱥ�������������ڵ�,������������� 1 ������Ƭ������ 1 �����Ʒ�Ƭ(1 ����ȫ����),�����Ļ�ÿ�������ܹ����� 2 ����Ƭ, ������Ҫ����������Ҫȷ����Ƭ������
����Allocation
����Ƭ�����ij���ڵ�Ĺ���,������������Ƭ���߸���������Ǹ���,������������Ƭ�������ݵĹ��̡������������ master �ڵ���ɵġ�
34-����-ϵͳ�ܹ�-���

һ�������е� Elasticsearch ʵ����Ϊһ���ڵ�,����Ⱥ����һ�����߶��ӵ����ͬ
cluster.name ���õĽڵ����, ���ǹ�ͬ�е����ݺ��ص�ѹ�������нڵ���뼯Ⱥ�л��ߴӼ�Ⱥ���Ƴ��ڵ�ʱ,��Ⱥ��������ƽ���ֲ����е����ݡ�
��һ���ڵ㱻ѡ�ٳ�Ϊ���ڵ�ʱ, �������������Ⱥ��Χ�ڵ����б��,�������ӡ�
ɾ������,�������ӡ�ɾ���ڵ�ȡ� �����ڵ㲢����Ҫ�漰���ĵ�����ı���������Ȳ���,���Ե���Ⱥֻӵ��һ�����ڵ�������,��ʹ������������Ҳ�����Ϊƿ���� �κνڵ㶼���Գ�Ϊ���ڵ㡣���ǵ�ʾ����Ⱥ��ֻ��һ���ڵ�,������ͬʱҲ��Ϊ�����ڵ㡣
��Ϊ�û�,���ǿ��Խ������͵���Ⱥ�е��κνڵ� ,�������ڵ㡣 ÿ���ڵ㶼֪��
�����ĵ�������λ��,�����ܹ������ǵ�����ֱ��ת�����洢���������ĵ��Ľڵ㡣 �������ǽ������͵��ĸ��ڵ�,�����ܸ���Ӹ����������������ĵ��Ľڵ��ռ�������,�������ս�����ؽo�ͻ��ˡ� Elasticsearch ����һ�еĹ����������ġ�
35-����-���ڵ㼯Ⱥ
�����ڰ���һ���սڵ�ļ�Ⱥ�ڴ�����Ϊ users ������,Ϊ����ʾĿ��,���ǽ����� 3������Ƭ��һ�ݸ���(ÿ������Ƭӵ��һ��������Ƭ)��
#PUT http://127.0.0.1:1001/users
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
��Ⱥ������ӵ��һ�������ĵ��ڵ㼯Ⱥ������ 3 ������Ƭ���������� node-1 ��

ͨ�� elasticsearch-head ���(һ��Chrome���)�鿴��Ⱥ��� ��

- ��Ⱥ����ֵ:yellow( 3 of 6 ):��ʾ��ǰ��Ⱥ��ȫ������Ƭ����������,���Ǹ�����Ƭû��ȫ����������״̬��
 ?:3 ������Ƭ������
?:3 ������Ƭ������
 ??3 ��������Ƭ���� Unassigned,���Ƕ�û�б����䵽�κνڵ㡣 ��ͬ һ���ڵ��ϼȱ���ԭʼ�����ֱ��渱����û�������,��Ϊһ��ʧȥ���Ǹ��ڵ�,����Ҳ����ʧ�ýڵ� �ϵ����и������ݡ�
??3 ��������Ƭ���� Unassigned,���Ƕ�û�б����䵽�κνڵ㡣 ��ͬ һ���ڵ��ϼȱ���ԭʼ�����ֱ��渱����û�������,��Ϊһ��ʧȥ���Ǹ��ڵ�,����Ҳ����ʧ�ýڵ� �ϵ����и������ݡ�
��ǰ��Ⱥ���������е�,�����ڶ�ʧ���ݵķ��ա�
elasticsearch-head chrome�����װ
�����ȡ��ַ,����ѹ����,��ѹ�����ݷ����Զ�������Ϊelasticsearch-head�ļ��С�
���ŵ��Chrome���Ͻ�ѡ��->����->������չ(�����ַ������chrome://extensions/),ѡ���������ģʽ��,�ú����������ѽ�ѹ����չ����,ѡ��elasticsearch-head/_site,�������chrome�����װ��
36-����-����ת��
����Ⱥ��ֻ��һ���ڵ�������ʱ,��ζ�Ż���һ������������⡪��û�����ࡣ ���˵���,����ֻ��������һ���ڵ㼴�ɷ�ֹ���ݶ�ʧ��������ͬһ̨�����������˵ڶ����ڵ�ʱ,ֻҪ���͵�һ���ڵ���ͬ���� cluster.name ����,���ͻ��Զ����ּ�Ⱥ�����뵽���С������ڲ�ͬ�����������ڵ��ʱ��,Ϊ�˼��뵽ͬһ��Ⱥ,����Ҫ����һ�������ӵ��ĵ��������б���֮��������Ϊʹ�õ�������,�Է�ֹ�ڵ������м��뼯Ⱥ��ֻ����ͬһ̨������
���еĽڵ�Ż��Զ���ɼ�Ⱥ��
��������˵ڶ����ڵ�,��Ⱥ����ӵ�������ڵ� : ��������Ƭ������Ƭ���ѱ����� ��
ͨ�� elasticsearch-head ����鿴��Ⱥ���

- ��Ⱥ����ֵ:green( 3 of 6 ):��ʾ���� 6 ����Ƭ(���� 3 ������Ƭ�� 3 ��������Ƭ)�����������С�
 ?:3 ������Ƭ������
?:3 ������Ƭ������
?:�ڶ����ڵ���뵽��Ⱥ��, 3 ��������Ƭ������䵽����ڵ��ϡ���ÿ ������Ƭ��Ӧһ��������Ƭ������ζ�ŵ���Ⱥ���κ�һ���ڵ��������ʱ,���ǵ����ݶ���������� ���½����������ĵ������ᱣ��������Ƭ��,Ȼ���еĸ��Ƶ���Ӧ�ĸ�����Ƭ�ϡ���ͱ�֤������ �ȿ��Դ�����Ƭ�ֿ��ԴӸ�����Ƭ�ϻ���ĵ���
37-����-ˮƽ����
����Ϊ���ǵ����������е�Ӧ�ó�����������?�������˵������ڵ�,���ǵļ�Ⱥ����ӵ�������ڵ�ļ�Ⱥ : Ϊ�˷�ɢ���ض��Է�Ƭ�������·��� ��
ͨ�� elasticsearch-head ����鿴��Ⱥ�����

- ��Ⱥ����ֵ:green( 3 of 6 ):��ʾ���� 6 ����Ƭ(���� 3 ������Ƭ�� 3 ��������Ƭ)�����������С�

- Node 1 �� Node 2 �ϸ���һ����Ƭ��Ǩ�Ƶ����µ� Node 3 �ڵ�,����ÿ���ڵ��϶�ӵ�� 2 ����Ƭ, ������֮ǰ�� 3 ���� ���ʾÿ���ڵ��Ӳ����Դ(CPU, RAM, I/O)�������ٵķ�Ƭ������,ÿ����Ƭ �����ܽ���õ�������?
��Ƭ��һ��������������������,��ӵ��ʹ��һ���ڵ��ϵ�������Դ�������� �������ӵ�� 6 ���� Ƭ(3 ������Ƭ�� 3 ��������Ƭ)����������������ݵ� 6 ���ڵ�,ÿ���ڵ��ϴ���һ����Ƭ,����ÿ�� ��Ƭӵ�����ڽڵ��ȫ����Դ��
�������������Ҫ���ݳ��� 6 ���ڵ���ô����?
����Ƭ����Ŀ����������ʱ���Ѿ�ȷ����������ʵ����,�����Ŀ��������������ܹ��洢 �������������(ʵ�ʴ�Сȡ����������ݡ�Ӳ����ʹ�ó�����) ����,���������������ͷ������ݡ�������ͬʱ������Ƭ �� ������Ƭ������,���Ե���ӵ��Խ��ĸ�����Ƭʱ,Ҳ��ӵ��Խ�ߵ���������
�������еļ�Ⱥ���ǿ��Զ�̬����������Ƭ��Ŀ��,���ǿ�����������Ⱥ�������ǰѸ�������Ĭ�ϵ� 1 ���ӵ� 2��
#PUT http://127.0.0.1:1001/users/_settings
{
"number_of_replicas" : 2
}
users ��������ӵ�� 9 ����Ƭ: 3 ������Ƭ�� 6 ��������Ƭ�� ����ζ�����ǿ��Խ���Ⱥ���ݵ� 9 ���ڵ�,ÿ���ڵ���һ����Ƭ�����ԭ�� 3 ���ڵ�ʱ,��Ⱥ�������ܿ������� 3 ����

ͨ�� elasticsearch-head ����鿴��Ⱥ���:

��Ȼ,���ֻ������ͬ�ڵ���Ŀ�ļ�Ⱥ�����Ӹ���ĸ�����Ƭ�������������,��Ϊÿ����Ƭ�ӽڵ��ϻ�õ���Դ����١� ����Ҫ���Ӹ����Ӳ����Դ��������������
���Ǹ���ĸ�����Ƭ�����������������:��������Ľڵ�����,���ǿ�����ʧȥ 2 ���ڵ������²���ʧ�κ����ݡ�
38-����-Ӧ�Թ���?
���ǹرյ�һ���ڵ�,��ʱ��Ⱥ��״̬Ϊ:�ر���һ���ڵ��ļ�Ⱥ��
���ǹرյĽڵ���һ�����ڵ㡣����Ⱥ����ӵ��һ�����ڵ�����֤��������,���Է����ĵ�һ���������ѡ��һ���µ����ڵ�: Node 2 �������ǹر� Node 1 ��ͬʱҲʧȥ����
��Ƭ 1 �� 2 ,������ȱʧ����Ƭ��ʱ������Ҳ�������������� �����ʱ����鼯Ⱥ��״��,���ǿ�����״̬����Ϊ red :������������Ƭ�����������������˵���,�������ڵ��ϴ���������������Ƭ����������, �����µ����ڵ���������Щ��Ƭ�� Node 2 �� Node 3 �϶�Ӧ�ĸ�����Ƭ����Ϊ����Ƭ, ��ʱ��Ⱥ��״̬����Ϊyellow�������������Ƭ�Ĺ�����˲�䷢����,��ͬ����һ������һ�㡣

Ϊʲô���Ǽ�Ⱥ״̬�� yellow ������ green ��?
��Ȼ����ӵ�����е���������Ƭ,����ͬʱ������ÿ������Ƭ��Ҫ��Ӧ 2 �ݸ�����Ƭ,����ʱֻ����һ�ݸ�����Ƭ�� ���Լ�Ⱥ����Ϊ green ��״̬,�������Dz��ع��ڵ���:�������ͬ���ر��� Node 2 ,���ǵij��� ��Ȼ ���Ա����ڲ����κ����ݵ����������,��ΪNode 3 Ϊÿһ����Ƭ��������һ�ݸ�����
discovery.seed_hosts: ["localhost:9302", "localhost:9303"]
��Ⱥ���Խ�ȱʧ�ĸ�����Ƭ�ٴν��з���,��ô��Ⱥ��״̬Ҳ���ָ���֮ǰ��״̬�� ��� Node 1 ��Ȼӵ����֮ǰ�ķ�Ƭ,��������ȥ��������,ͬʱ��������Ƭ���Ʒ������ĵ������ļ�����֮ǰ�ļ�Ⱥ���,ֻ�� Master �ڵ��л��ˡ�

39-����-·�ɼ��� & ��Ƭ����?
·�ɼ���
������һ���ĵ���ʱ��,�ĵ��ᱻ�洢��һ������Ƭ�С� Elasticsearch ���֪��һ���ĵ�Ӧ�ô�ŵ��ĸ���Ƭ����?�����Ǵ����ĵ�ʱ,����ξ�������ĵ�Ӧ�����洢�ڷ�Ƭ 1 ���Ƿ�Ƭ 2 ����?������϶������������,������Ҫ��ȡ�ĵ���ʱ�����ǾͲ�֪���Ӻδ�Ѱ���ˡ�ʵ����,��������Ǹ������������ʽ������:
shard = hash(routing) % number_of_primary_shards
routing ��һ���ɱ�ֵ,Ĭ�����ĵ��� _id ,Ҳ�������ó�һ���Զ����ֵ�� routing ͨ��hash ��������һ������,Ȼ����������ٳ��� number_of_primary_shards (����Ƭ������)��õ����� ������ֲ��� 0 �� number_of_primary_shards-1 ֮�������,����������Ѱ����ĵ����ڷ�Ƭ��λ�á�
��ͽ�����Ϊʲô����Ҫ�ڴ���������ʱ���ȷ��������Ƭ������������Զ����ı��������:��Ϊ��������仯��,��ô����֮ǰ·�ɵ�ֵ������Ч,�ĵ�Ҳ��Ҳ�Ҳ����ˡ�
���е��ĵ�API ( get . index . delete �� bulk , update�Լ� mget )������һ������routing ��·�ɲ���,ͨ������������ǿ����Զ����ĵ�����Ƭ��ӳ�䡣һ���Զ����·�ɲ�����������ȷ��������ص��ĵ���һ������������ͬһ���û����ĵ����������洢��ͬһ����Ƭ�С�
��Ƭ����
���ǿ��Է�������Ⱥ�е���һ�ڵ㡣ÿ���ڵ㶼������������������ÿ���ڵ㶼֪����Ⱥ����һ�ĵ�λ��,���Կ���ֱ�ӽ�����ת������Ҫ�Ľڵ��ϡ��������������,��������е������͵�Node 1001,���ǽ����ΪЭ���ڵ�coordinating node��

�����������ʱ��, Ϊ����չ����,���õ���������ѯ��Ⱥ�����еĽڵ㡣
40-����-�������?
�ڿͻ����յ��ɹ���Ӧʱ,�ĵ�����Ѿ�������Ƭ�����и�����Ƭִ�����,����ǰ�ȫ�ġ���һЩ��ѡ���������������Ӱ���������,���������ݰ�ȫΪ�����������ܡ���Щѡ�����ʹ��,��Ϊ Elasticsearch �Ѿ��ܿ�,����Ϊ���������, ��ο�����:
- consistency
��һ���ԡ���Ĭ��������,��ʹ����������ͼִ��һ��д����֮ǰ,����Ƭ����Ҫ�����Ҫ�й涨����quorum(������˵��,Ҳ������Ҫ�д����)�ķ�Ƭ�������ڻ�Ծ����״̬,�Ż�ȥִ��д����(���з�Ƭ���� ����������Ƭ���߸�����Ƭ)������Ϊ�˱����ڷ��������������(network partition)��ʱ�����д����,�����������ݲ�һ�¡� �涨������: int((primary + number_of_replicas) / 2 ) + 1
consistency ������ֵ������Ϊ:
- one :ֻҪ����Ƭ״̬ ok ������ִ��д������
- all:����Ҫ����Ƭ�����и�����Ƭ��״̬û���������ִ��д������
- quorum:Ĭ��ֵΪquorum , ��������ķ�Ƭ����״̬û���������ִ��д������
ע��,�涨�����ļ��㹫ʽ��number_of_replicasָ���������������е��趨������Ƭ��,������ָ��ǰ�����״̬�ĸ�����Ƭ��������������������ָ���˵�ǰ����ӵ��3��������Ƭ,�ǹ涨�����ļ�������:int((1 primary + 3 replicas) / 2) + 1 = 3,�����ʱ��ֻ���������ڵ�,��ô���ڻ�Ծ״̬�ķ�Ƭ���������ʹﲻ���涨����,Ҳ���������������ɾ���κ��ĵ���
- timeout
���û���㹻�ĸ�����Ƭ�ᷢ��ʲô?Elasticsearch ��ȴ�,ϣ������ķ�Ƭ���֡�Ĭ�������,�����ȴ� 1 ���ӡ� �������Ҫ,�����ʹ��timeout����ʹ��������ֹ:100��100 ����,30s��30�롣
������Ĭ����1��������Ƭ,����ζ��Ϊ����涨����Ӧ����Ҫ������ķ�Ƭ������ ����,��ЩĬ�ϵ����û���ֹ�����ڵ�һ�ڵ������κ����顣Ϊ�˱����������,Ҫ��ֻ�е�number_of_replicas ����1��ʱ��,�涨�����Ż�ִ�С�
41-����-���ݶ�����

?�ڴ�����ȡ����ʱ,Э�������ÿ�������ʱ��ͨ����ѯ���еĸ�����Ƭ���ﵽ���ؾ��⡣���ĵ�������ʱ,�Ѿ����������ĵ������Ѿ�����������Ƭ�ϵ��ǻ�û�и��Ƶ�������Ƭ�� �����������,������Ƭ���ܻᱨ���ĵ�������,��������Ƭ���ܳɹ������ĵ��� һ����������ɹ����ظ��û�,�ĵ�������Ƭ������Ƭ���ǿ��õġ�
?
42-����-�������� & ������������
��������
���ָ���һ���ĵ��������ǰ˵���Ķ�ȡ��д������:

���ָ���һ���ĵ��IJ�������:
- �ͻ�����Node 1����������
- ��������ת��������Ƭ���ڵ�Node 3 ��
- Node 3������Ƭ�����ĵ�,��_source�ֶ��е�JSON,���ҳ���������������Ƭ���ĵ�������ĵ��Ѿ�����һ��������,�������Բ���3 ,����retry_on_conflict�κ������
- ��� Node 3�ɹ��ظ����ĵ�,�����°汾���ĵ�����ת����Node 1�� Node 2�ϵĸ�����Ƭ,���½���������һ�����и�����Ƭ�����سɹ�,Node 3��Э���ڵ�Ҳ���سɹ�,Э���ڵ���ͻ��˷��سɹ���
������Ƭ�Ѹ���ת����������Ƭʱ, ������ת���������� �෴,��ת�������ĵ����°汾�����ס,��Щ���Ľ����첽ת����������Ƭ,���Ҳ��ܱ�֤�����Է���������ͬ��˳� ��� Elasticsearch ��ת����������,������Դ����˳��Ӧ�ø���,���µõ����ĵ���
������������
**mget�� bulk API��ģʽ�����ڵ��ĵ�ģʽ��**��������Э���ڵ�֪��ÿ���ĵ��������ĸ���Ƭ�С������������ĵ�����ֽ��ÿ����Ƭ�Ķ��ĵ�����,���ҽ���Щ������ת����ÿ������ڵ㡣
Э���ڵ�һ���յ�����ÿ���ڵ��Ӧ��,�ͽ�ÿ���ڵ����Ӧ�ռ������ɵ�����Ӧ,���ظ��ͻ��ˡ�
?

�õ��� mget ����ȡ�ض���ĵ�����IJ���˳��:?
- �ͻ����� Node 1 ���� mget ����
- Node 1Ϊÿ����Ƭ�������ĵ���ȡ����,Ȼ����ת����Щ�����й���ÿ�����������Ƭ���߸�����Ƭ�Ľڵ��ϡ�һ���յ����д�,Node 1 ������Ӧ�����䷵�ظ��ͻ��ˡ�
���Զ�docs������ÿ���ĵ�����routing������
bulk API, �����ڵ�������������ִ�ж��������������ɾ����������

?bulk API �����²���˳��ִ��:
- �ͻ�����Node 1 ���� bulk����
- Node 1Ϊÿ���ڵ㴴��һ����������,������Щ������ת����ÿ����������Ƭ�Ľڵ�������
- ����Ƭһ����һ����˳��ִ��ÿ����������ÿ�������ɹ�ʱ,����Ƭ����ת�����ĵ�(��ɾ��)��������Ƭ,Ȼ��ִ����һ��������һ�����еĸ�����Ƭ�������в����ɹ�,�ýڵ㽫��Э���ڵ㱨��ɹ�,Э���ڵ㽫��Щ��Ӧ�ռ����������ظ��ͻ��ˡ�
43-����-��������?
��Ƭ��Elasticsearch��С�Ĺ�����Ԫ�����Ǿ���ʲô��һ����Ƭ,������ι�����?
��ͳ�����ݿ�ÿ���ֶδ洢����ֵ,�����ȫ�ļ������������ı��ֶ��е�ÿ��������Ҫ������,�����ݿ���ζ����Ҫ�����ֶ���������ֵ����������õ�֧����һ���ֶζ��ֵ��������ݽṹ������������
��������ԭ��
Elasticsearchʹ��һ�ֳ�Ϊ���������Ľṹ,�������ڿ��ٵ�ȫ��������
������,֪����,�е�������,�϶����Ӧ��������������������(forward index),��������(inverted index)����Ϥ�������ǵ���������
��ν����������,������������Ὣ���������ļ�����Ӧһ���ļ�ID,����ʱ�����ID�������ؼ��ֽ��ж�Ӧ,�γ�K-V��,Ȼ��Թؼ��ֽ���ͳ�Ƽ�����(ͳ��??�����н���)
?
���ǻ���������¼�����������е��ĵ�����Ŀ�Ǹ���������,�����������ṹ����������ʵʱ�������������Ҫ������,��������Ὣ�����������¹���Ϊ��������,�����ļ�ID��Ӧ���ؼ��ʵ�ӳ��ת��Ϊ�ؼ��ʵ��ļ�ID��ӳ��,ÿ���ؼ��ʶ���Ӧ��һϵ�е��ļ�,��Щ�ļ��ж���������ؼ��ʡ�
?��������������
һ�������������ĵ������в��ظ��ʵ��б�����,��������ÿ����,��һ�����������ĵ��б�������,���������������ĵ�,ÿ���ĵ���content�������������:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
Ϊ�˴�����������,�������Ƚ�ÿ���ĵ���content���ֳɵ����Ĵ�(���dz���Ϊ������tokens ),����һ���������в��ظ������������б�,Ȼ���г�ÿ�������������ĸ��ĵ������������ʾ:

����,�������������?quick?brown?,����ֻ��Ҫ���Ұ���ÿ���������ĵ�:

�����ĵ���ƥ��,���ǵ�һ���ĵ��ȵڶ���ƥ��ȸ��ߡ��������ʹ�ý�����ƥ����������ļ��������㷨,��ô���ǿ���˵,�������Dz�ѯ�����������,��һ���ĵ��ȵڶ����ĵ����ѡ�
����,����Ŀǰ�ĵ���������һЩ����:
-
Quick��quick�Զ����Ĵ�������,Ȼ���û�������Ϊ��������ͬ�Ĵʡ� -
fox��foxes�dz�����,����dog��dogs;��������ͬ�Ĵʸ��� -
jumped��leap,����û����ͬ�Ĵʸ�,�����ǵ���˼�������������ͬ��ʡ�
ʹ��ǰ�����������+Quick +fox����õ��κ�ƥ���ĵ���(��ס,+ǰ��������ʱ������)��
ֻ��ͬʱ����Quick��fox ���ĵ������������ѯ����,���ǵ�һ���ĵ�����quick fox ,�ڶ����ĵ�����Quick foxes ��
���ǵ��û����Ժ��������������ĵ����ѯƥ�䡣���ǿ������ĸ��á�
������ǽ������淶Ϊ��ģʽ,��ô���ǿ����ҵ����û������Ĵ�������ȫһ��,�������㹻����Ե��ĵ�������:
Quick����Сд��Ϊquick��foxes���Դʸ���ȡ��Ϊ�ʸ��ĸ�ʽΪfox�����Ƶ�,dogs����Ϊ��ȡΪdog��jumped��leap��ͬ���,��������Ϊ��ͬ�ĵ���jump?��
������������ȥ������:

�ԶԶ��������������+Quick +fox ��Ȼ��ʧ��,��Ϊ�����ǵ�������,�Ѿ�û��Quick�ˡ�����,������Ƕ��������ַ���ʹ����content����ͬ�ı�������,���ɲ�ѯ+quick +fox,���������ĵ�����ƥ��!�ִʺͱ����Ĺ��̳�Ϊ����,��dz���Ҫ����ֻ�������������г��ֵĴ���,���������ı��Ͳ�ѯ�ַ����������Ϊ��ͬ�ĸ�ʽ��
44-����-�ĵ�����
���ɸı�ĵ�������
���ڵ�ȫ�ļ�����Ϊ�����ĵ����Ͻ���һ���ܴ�ĵ�������������д�뵽���̡� һ���µ���������,�ɵľͻᱻ���滻,��������ı仯����Ա���������
- ����������д����̺��Dz��ɸı��:����Զ�����ġ�����Ҫ����������������������,��Ͳ���Ҫ���Ķ����ͬʱ�����ݵ����⡣
- һ�������������ں˵��ļ�ϵͳ����,�����������,�����䲻���ԡ�ֻҪ�ļ�ϵͳ�����л����㹻�Ŀռ�,��ô�ֶ������ֱ�������ڴ�,���������д��̡����ṩ�˺ܴ������������
- ��������(��filter����),������������������ʼ����Ч�����Dz���Ҫ��ÿ�����ݸı�ʱ���ؽ�,��Ϊ���ݲ���仯��
- д�뵥����ĵ��������������ݱ�ѹ��,���ٴ���IO����Ҫ�����浽�ڴ��������ʹ������
��Ȼ,һ�����������Ҳ�в��õĵط�����Ҫ��ʵ�����Dz��ɱ��! �㲻���������������Ҫ��һ���µ��ĵ��ɱ�����,����Ҫ�ؽ�������������Ҫô��һ���������ܰ���������������˺ܴ������,Ҫô�������ɱ����µ�Ƶ������˺ܴ�����ơ�
?��̬��������
����ڱ��������Ե�ǰ����ʵ�ֵ��������ĸ���?
����:�ø����������ͨ�������µIJ�����������ӳ�½�����,������ֱ����д��������������ÿһ�������������ᱻ������ѯ��,������Ŀ�ʼ��ѯ����ٶԽ�����кϲ���
Elasticsearch����Lucene,���java�������˰��������ĸ��ÿһ�α�������һ����������,�������� Lucene �г���ʾ���жεļ�����,���������ύ��ĸ��һ���г���������֪�ε��ļ���
?
��������������������ִ��:
һ�����ĵ����ռ����ڴ��������档
������ʱ��, ���汻�ύ��
- һ���µĶ�,һ���ӵĵ�������,��д����̡�
- һ���µİ����¶����ֵ��ύ�㱻д����̡�
- ���̽���ͬ��,�������ļ�ϵͳ�����еȴ���д�붼ˢ�µ�����,��ȷ�����DZ�д�������ļ�
�����µĶα�����,�����������ĵ��ɼ��Ա�������
�ġ��ڴ滺�汻���,�ȴ������µ��ĵ���

��һ����ѯ������,������֪�Ķΰ�˳��ѯ������ͳ�ƻ�����жεĽ�����оۺ�,�Ա�֤ÿ���ʺ�ÿ���ĵ��Ĺ�������ȷ���㡣���ַ�ʽ��������Խϵ͵ijɱ������ĵ����ӵ�������
���Dz��ɸı��,���ԼȲ��ܴӰ��ĵ��ӾɵĶ����Ƴ�,Ҳ�����ľɵĶ������з�ӳ�ĵ��ĸ��¡�ȡ����֮����,ÿ���ύ������һ��.del �ļ�,�ļ��л��г���Щ��ɾ���ĵ��Ķ���Ϣ��
��һ��**�ĵ�����ɾ����**ʱ,��ʵ����ֻ���� .del �ļ��б����ɾ����һ�������ɾ�����ĵ���Ȼ���Ա���ѯƥ�䵽,�����������ս��������ǰ�ӽ�������Ƴ���
�ĵ�����Ҳ�����ƵIJ�����ʽ:��һ���ĵ�������ʱ,�ɰ汾�ĵ������ɾ��,�ĵ����°汾��������һ���µĶ��С����������汾���ĵ����ᱻһ����ѯƥ�䵽,����ɾ�����Ǹ��ɰ汾�ĵ��ڽ��������ǰ���Ѿ����Ƴ���
?
?45-����-�ĵ�ˢ�� & �ĵ�ˢд & �ĵ��ϲ�
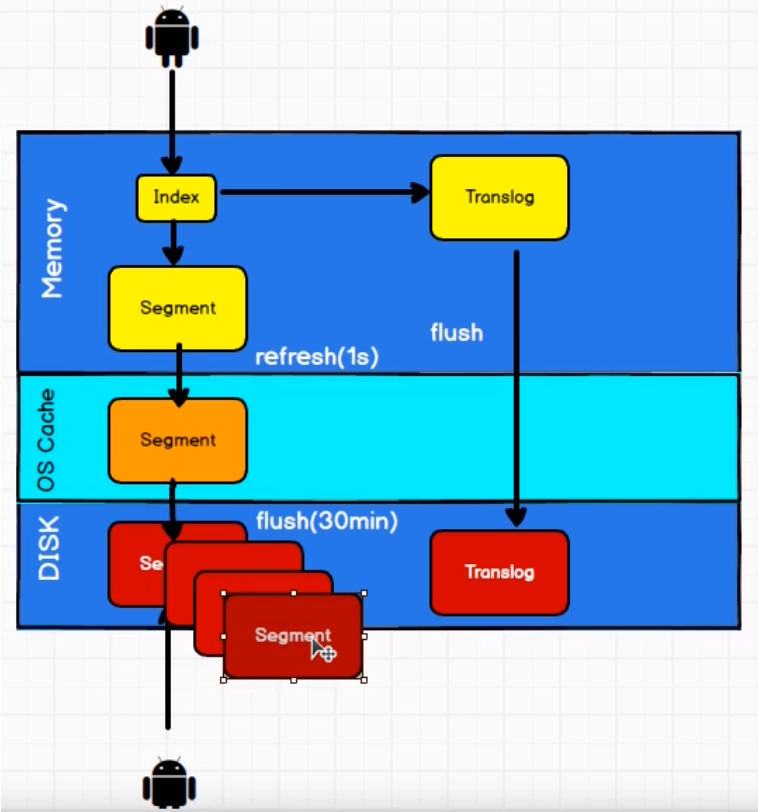
?��ʵʱ����
���Ű���(per-segment)�����ķ�չ,һ���µ��ĵ����������ɱ��������ӳ����������ˡ����ĵ��ڼ�����֮�ڼ��ɱ�����,���������Dz����졣�����������Ϊ��ƿ�����ύ(Commiting)һ���µĶε�������Ҫһ��fsync��ȷ���α������Ե�д�����,�����ڶϵ��ʱ��Ͳ��ᶪʧ���ݡ�����fsync�������ۺܴ�;���ÿ������һ���ĵ���ȥִ��һ�εĻ�����ɺܴ���������⡣
������Ҫ����һ���������ķ�ʽ��ʹһ���ĵ��ɱ�����,����ζ��fsyncҪ�����������б��Ƴ�����Elasticsearch�ʹ���֮�����ļ�ϵͳ���档��֮ǰ������һ��,���ڴ������������е��ĵ��ᱻд�뵽һ���µĶ��С����������¶λᱻ��д�뵽�ļ�ϵͳ���桪��һ�����ۻ�Ƚϵ�,�Ժ��ٱ�ˢ�µ����̡���һ�����۱Ƚϸߡ�����ֻҪ�ļ��Ѿ��ڻ�����,�Ϳ����������ļ�һ�����Ͷ�ȡ�ˡ�

Lucene�����¶α�д��ʹ�,ʹ��������ĵ���δ����һ�������ύʱ��������ɼ������ַ�ʽ�Ƚ���һ���ύ����ҪС�ö�,�����ڲ�Ӱ�����ܵ�ǰ���¿��Ա�Ƶ����ִ�С�

�� Elasticsearch ��,д��ʹ�һ���¶ε������Ĺ��̽���refresh��Ĭ�������ÿ����Ƭ��ÿ���Զ�ˢ��һ�Ρ������Ϊʲô����˵ Elasticsearch�ǽ�ʵʱ����:�ĵ��ı仯�����������������ɼ�,������һ��֮�ڱ�Ϊ�ɼ���
��Щ��Ϊ���ܻ�����û��������:����������һ���ĵ�Ȼ����������,��ȴû���ѵ����������Ľ���취����refresh APIִ��һ���ֶ�ˢ��:/usersl_refresh
����ˢ���DZ��ύ�����ܶ�IJ���,�����ǻ������ܿ�������д���Ե�ʱ��,�ֶ�ˢ�º�����,���Dz�Ҫ������������ÿ������һ���ĵ���ȥ�ֶ�ˢ�¡��෴,���Ӧ����Ҫ��ʶ��Elasticsearch �Ľ�ʵʱ������,���������IJ��㡣
���������е��������Ҫÿ��ˢ�¡�����������ʹ��Elasticsearch������������־�ļ�,��������Ż������ٶȶ����ǽ�ʵʱ����,����ͨ������refresh_interval ,����ÿ��������ˢ��Ƶ��
?
{
"settings": {
"refresh_interval": "30s"
}
}
?refresh_interval�����ڼȴ������Ͻ��ж�̬���¡�������������,�������ڽ���һ�����������ʱ,�����ȹر��Զ�ˢ��,����ʼʹ�ø�����ʱ,�ٰ����ǵ�������
# �ر��Զ�ˢ��
PUT /users/_settings
{ "refresh_interval": -1 }
# ÿһ��ˢ��
PUT /users/_settings
{ "refresh_interval": "1s" }
?�־û����
���û����fsync�����ݴ��ļ�ϵͳ����ˢ(flush)��Ӳ��,���Dz��ܱ�֤�����ڶϵ������dz��������˳�֮����Ȼ���ڡ�Ϊ�˱�֤Elasticsearch �Ŀɿ���,��Ҫȷ�����ݱ仯���־û������̡��ڶ�̬��������,����˵һ���������ύ�Ὣ��ˢ������,��д��һ���������ж��б����ύ�㡣Elasticsearch �����������´�һ�������Ĺ�����ʹ������ύ�����ж���Щ�������ڵ�ǰ��Ƭ��
��ʹͨ��ÿ��ˢ��(refresh)ʵ���˽�ʵʱ����,������Ȼ��Ҫ�������������ύ��ȷ���ܴ�ʧ���лָ������������ύ֮�䷢���仯���ĵ���ô��?����Ҳ��ϣ����ʧ����Щ���ݡ�Elasticsearch ������һ��translog ,���߽�������־,��ÿһ�ζ�Elasticsearch���в���ʱ����������־��¼��
������������:
һ��һ���ĵ�������֮��,�ͻᱻ���ӵ��ڴ滺����,�����ӵ��� translog

����ˢ��(refresh)ʹ��Ƭÿ�뱻ˢ��(refresh)һ��:
- ��Щ���ڴ滺�������ĵ���д�뵽һ���µĶ���,��û�н���fsync������
- ����α���,ʹ��ɱ�������
- �ڴ滺��������ա�

����������̼�������,������ĵ������ӵ��ڴ滺�������ӵ�������־��

�ġ�ÿ��һ��ʱ�䡪����translog���Խ��Խ��,������ˢ��(flush);һ���µ�translog������,����һ��ȫ���ύ��ִ�С�
- �������ڴ滺�������ĵ�����д��һ���µĶΡ�
- ����������ա�
- һ���ύ�㱻д��Ӳ�̡�
- �ļ�ϵͳ����ͨ��fsync��ˢ��(flush) ��
- �ϵ�translog��ɾ����
translog �ṩ���л�û�б�ˢ�����̵IJ�����һ���־û���¼����Elasticsearch������ʱ��,����Ӵ�����ʹ�����һ���ύ��ȥ�ָ���֪�Ķ�,���һ��ط�translog �����������һ���ύ�����ı��������
translog Ҳ�������ṩʵʱCRUD����������ͨ��ID��ѯ�����¡�ɾ��һ���ĵ�,�����ڳ��Դ���Ӧ�Ķ��м���֮ǰ,���ȼ�� translog�κ�����ı��������ζ���������ܹ�ʵʱ�ػ�ȡ���ĵ������°汾��

ִ��һ���ύ���ҽض�translog ����Ϊ�� Elasticsearch������һ��flush����Ƭÿ30���ӱ��Զ�ˢ��(flush),������ translog ̫���ʱ��Ҳ��ˢ�¡�
�������Ҫ�Լ��ֶ�ִ��flush����,ͨ�������,�Զ�ˢ�¾��㹻�ˡ������˵,�������ڵ��ر�����֮ǰִ�� flush�����������������Elasticsearch���Իָ������´�һ������,����Ҫ�ط�translog�����еIJ���,���������־Խ��,�ָ�Խ�졣
translog ��Ŀ���DZ�֤�������ᶪʧ,���ļ���fsync������ǰ,��д����ļ�������֮��ͻᶪʧ��Ĭ��translog��ÿ5�뱻fsyncˢ�µ�Ӳ��,������ÿ��д�������֮��ִ��(e.g. index, delete, update, bulk)���������������Ƭ���Ʒ�Ƭ���ᷢ��������,������,����ζ������������fsync������Ƭ���Ʒ�Ƭ��translog֮ǰ,��Ŀͻ��˲���õ�һ��200 OK��Ӧ��
��ÿ�������ִ��һ��fsync�����һЩ������ʧ,����ʵ������������ʧ��Խ�С(�ر��� bulk ����,����һ��������ƽ̯�˴����ĵ��Ŀ���)��
���Ƕ���һЩ��������ż����ʧ������������Ҳ�������صļ�Ⱥ,ʹ���첽�� fsync���DZȽ�����ġ�����,д������ݱ����浽�ڴ���,��ÿ5��ִ��һ�� fsync ����������ʹ���첽translog �Ļ�,����Ҫ��֤�ڷ��� crash ʱ,��ʧ�� sync_intervalʱ��ε�����Ҳ����ν�����ھ���ǰ֪��������ԡ�����㲻ȷ�������Ϊ�ĺ��,�����ʹ��Ĭ�ϵIJ���{��index.translog.durability��: ��request��}���������ݶ�ʧ��
�κϲ�
�����Զ�ˢ������ÿ��ᴴ��һ���µĶ�,�����ᵼ�¶�ʱ���ڵĶ�����������������Ŀ̫�������ϴ���鷳��ÿһ���ζ��������ļ�������ڴ�� cpu�������ڡ�����Ҫ����,ÿ�������������������ÿ����;���Զ�Խ��,����Ҳ��Խ����
Elasticsearchͨ���ں�̨���жκϲ������������⡣С�Ķα��ϲ�����Ķ�,Ȼ����Щ��Ķ��ٱ��ϲ�������ĶΡ�
�κϲ���ʱ��Ὣ��Щ�ɵ���ɾ���ĵ����ļ�ϵͳ���������ɾ�����ĵ�(�����ĵ��ľɰ汾)���ᱻ�������µĴ���С�
�����κϲ�����Ҫ�����κ��¡���������������ʱ���Զ����С�
һ����������ʱ��,ˢ��(refresh)�����ᴴ���µĶβ����δ��Թ�����ʹ�á�
�����ϲ�����ѡ��һС���ִ�С���ƵĶ�,�����ں�̨�����Ǻϲ�������Ķ��С��Ⲣ�����ж�������������

����һ���ϲ�����,�ϵĶα�ɾ��
- �µĶα�ˢ��(flush)���˴��̡�
- д��һ�������¶����ų��ɵĺͽ�С�Ķε����ύ�㡣
- �µĶα��������������ϵĶα�ɾ����

�ϲ���Ķ���Ҫ���Ĵ����� I/O �� CPU ��Դ,������䷢չ��Ӱ���������ܡ� Elasticsearch��Ĭ������»�Ժϲ����̽�����Դ����,����������Ȼ���㹻����Դ�ܺõ�ִ�С�
46-����-�ĵ�����?
���������������:
- ��һ���ı��ֳ��ʺ��ڵ��������Ķ����Ĵ�����
- ����Щ����ͳһ��Ϊ����ʽ��������ǵġ��������ԡ�,����recall��
������ִ������Ĺ�����������ʵ�����ǽ��������ܷ�װ����һ������:
- �ַ�������:����,�ַ�����˳��ͨ��ÿ�� �ַ������� �����ǵ��������ڷִ�ǰ�����ַ�����һ���ַ���������������ȥ�� HTML,���߽� & ת���� and��
- �ִ���:���,�ַ������ִ�����Ϊ�����Ĵ�����һ���ķִ��������ո�ͱ���ʱ��,���ܻὫ�ı���ֳɴ�����
- Token ������:���,������˳��ͨ��ÿ�� token ������ ��������̿��ܻ�ı����(����,Сд��Quick ),ɾ������(����, �� a, and, the �����ô�),�������Ӵ���(����,��jump��leap����ͬ���)
���÷�����
Elasticsearch�������˿���ֱ��ʹ�õ�Ԥ��װ�ķ����������������ǻ��г�����Ҫ�ķ�������Ϊ��֤�����ǵIJ���,���ǿ���ÿ�����������������ַ����õ���Щ����:
"Set the shape to semi-transparent by calling set_trans(5)"
- ��������
����������Elasticsearch Ĭ��ʹ�õķ����������Ƿ������������ı���õ�ѡ��������Unicode ���˶���ĵ��ʱ߽绮���ı���ɾ�����ֱ�㡣���,������Сд���������:
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
- ������
���������κβ�����ĸ�ĵط��ָ��ı�,������Сд���������:
set, the, shape, to, semi, transparent, by, calling, set, trans
- ���Է�����
�ض����Է����������ںܶ����ԡ����ǿ��Կ���ָ�����Ե��ص㡣����,Ӣ�������������һ��Ӣ�����ô�(���õ���,����and����the ,���Ƕ������û�ж���Ӱ��),���ǻᱻɾ������������Ӣ����Ĺ���,����ִ���������ȡӢ�ﵥ�ʵĴʸɡ�
Ӣ��ִ������������Ĵ���:
set, shape, semi, transpar, call, set_tran, 5
ע�⿴transparent��calling�� set_trans�Ѿ���Ϊ�ʸ���ʽ��
������ʹ�ó���?
����������һ���ĵ�,����ȫ�������ɴ���������������������������,��������ȫ����������ʱ��,������Ҫ����ѯ�ַ���ͨ����ͬ�ķ�������,�Ա�֤���������Ĵ�����ʽ�������еĴ�����ʽһ�¡�
ȫ�IJ�ѯ,����ÿ��������ζ����,������ǿ�������ȷ����:
- �����ѯһ��ȫ����ʱ,��Բ�ѯ�ַ���Ӧ����ͬ�ķ�����,�Բ�����ȷ�����������б���
- �����ѯһ����ȷֵ��ʱ,���������ѯ�ַ���,����������ָ���ľ�ȷֵ��
���Է�����
��Щʱ���������ִʵĹ��̺�ʵ�ʱ��洢�������еĴ���,�ر�����սӴ�Elasticsearch��Ϊ�����ⷢ����ʲô,�����ʹ��analyze API�����ı�����α������ġ�����Ϣ����,ָ����������Ҫ�������ı���
#GET http://localhost:9200/_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
�����ÿ��Ԫ�ش���һ�������Ĵ���:
{
"tokens": [
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "analyze",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 3
}
]
}
- token��ʵ�ʴ洢�������еĴ�����
- start_ offset ��end_ offsetָ���ַ���ԭʼ�ַ����е�λ�á�
- positionָ��������ԭʼ�ı��г��ֵ�λ�á�
ָ��������
��Elasticsearch������ĵ��м�һ���µ��ַ�����,�����Զ�������Ϊһ��ȫ���ַ�����,ʹ�� �� �������������з������㲻ϣ��������������������ʹ��һ����ͬ�ķ�����,�������������ʹ�õ����ԡ���ʱ������Ҫһ���ַ��������һ���ַ�����,��ʹ�÷���,ֱ�������㴫��ľ�ȷֵ,�����û� ID ����һ���ڲ���״̬����ǩ��Ҫ������һ��,���DZ����ֶ�ָ����Щ���ӳ�䡣
(ϸ����ָ��������)
IK�ִ���
����ͨ�� Postman ���� GET �����ѯ�ִ�Ч��
# GET http://localhost:9200/_analyze
{
"text":"���Ե���"
}
ES ��Ĭ�Ϸִ�����ʶ�������в��ԡ� ���������Ĵʻ�,���ǼĽ�ÿ���ֲ����Ϊһ���ʡ�
{
"tokens": [
{
"token": "��",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "��",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "��",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "��",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
�����Ľ����Ȼ���������ǵ�ʹ��Ҫ��,����������Ҫ���� ES ��Ӧ�汾�����ķִ�����
IK ���ķִ���������ַ
����ѹ��ĺ���ļ��з��� ES ��Ŀ¼�µ� plugins Ŀ¼��,���� ES ����ʹ�á�
������μ����µIJ�ѯ����"analyzer":��ik_max_word����
# GET http://localhost:9200/_analyze
{
"text":"���Ե���",
"analyzer":"ik_max_word"
}
- ik_max_word:�Ὣ�ı�����ϸ���ȵIJ�֡�
- ik_smart:�Ὣ�ı���������ȵIJ�֡�
ʹ�����ķִʺ�Ľ��Ϊ:
{
"tokens": [
{
"token": "����",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "����",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
]
}
?ES ��Ҳ���Խ�����չ�ʻ�,���Ȳ�ѯ
#GET http://localhost:9200/_analyze
{
"text":"������",
"analyzer":"ik_max_word"
}
�������Եõ�ÿ���ֵķִʽ��,������Ҫ���ľ���ʹ�ִ���ʶ������Ҳ��һ�����
{
"tokens": [
{
"token": "��",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "��",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "��",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 3
},
{
"token": "��",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}
- ���Ƚ��� ES ��Ŀ¼�е� plugins �ļ����µ� ik �ļ���,���� config Ŀ¼,���� custom.dic�ļ�,д�롰�����¡���
- ͬʱ�� IKAnalyzer.cfg.xml �ļ�,���½��� custom.dic �������С�
- ���� ES ������ ��
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer ��չ����</comment>
<!--�û����������������Լ�����չ�ֵ� -->
<entry key="ext_dict">custom.dic</entry>
<!--�û����������������Լ�����չֹͣ���ֵ�-->
<entry key="ext_stopwords"></entry>
<!--�û���������������Զ����չ�ֵ� -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--�û���������������Զ����չֹͣ���ֵ�-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
��չ���ٴβ�ѯ
# GET http://localhost:9200/_analyze
{
"text":"���Ե���",
"analyzer":"ik_max_word"
}
���ؽ������:
{
"tokens": [
{
"token": "������",
"start_offset": 0,
"end_offset": 5,
"type": "CN_WORD",
"position": 0
}
]
}
�Զ��������
��ȻElasticsearch����һЩ�ֳɵķ�����,Ȼ���ڷ�������Elasticsearch������ǿ��֮������,�����ͨ����һ���ʺ�����ض����ݵ�����֮������ַ����������ִ������ʻ㵥Ԫ�������������Զ���ķ��������ڷ��������������˵��,һ��������������һ����������������ֺ�����һ����װ��,���ֺ�������˳��ִ��:
�ʵ�Ԫ������
�����ִ�,��Ϊ����Ĵʵ�Ԫ���ᰴ��ָ����˳��ͨ��ָ���Ĵʵ�Ԫ���������ʵ�Ԫ�����������ġ����ӻ����Ƴ��ʵ�Ԫ�������Ѿ��ᵽ��lowercase��stop�ʹ�����,������Elasticsearch ���滹�кܶ�ɹ�ѡ��Ĵʵ�Ԫ���������ʸɹ������ѵ��ʶ���Ϊ�ʸɡ�ascii_folding�������Ƴ�������,��һ����"tr��s�������Ĵ�ת��Ϊ��tres����
ngram�� edge_ngram�ʵ�Ԫ���������Բ����ʺ����ڲ���ƥ������Զ���ȫ�Ĵʵ�Ԫ��
?
�Զ������������
������,���ǿ�����δ����Զ���ķ�����:
#PUT http://localhost:9200/my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [
"&=> and "
]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [
"the",
"a"
]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"&_to_and"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"my_stopwords"
]
}
}
}
}
}
�����������Ժ�,ʹ�� analyze API �� ��������µķ�����:
# GET http://127.0.0.1:9200/my_index/_analyze
{
"text":"The quick & brown fox",
"analyzer": "my_analyzer"
}
���ؽ��Ϊ:
{
"tokens": [
{
"token": "quick",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "and",
"start_offset": 10,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "fox",
"start_offset": 18,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 4
}
]
}
47-����-�ĵ�����?
�ĵ���ͻ
������ʹ��index API�����ĵ�,����һ���Զ�ȡԭʼ�ĵ�,�����ǵ���,Ȼ���������������ĵ����������������ʤ:���������һ���ĵ�������,������Ψһ�洢�� Elasticsearch �С����������ͬʱ��������ĵ�,���ǵĸ��Ľ���ʧ��
�ܶ�ʱ������û������ġ�Ҳ�����ǵ������ݴ洢��һ����ϵ�����ݿ�,����ֻ�ǽ����ݸ��Ƶ�Elasticsearch�в�ʹ��ɱ�������Ҳ��������ͬʱ������ͬ���ĵ��ļ��ʺ�С�����߶������ǵ�ҵ����˵ż����ʧ���IJ����Ǻ����ص����⡣
����ʱ��ʧ��һ��������Ƿdz����صġ���������ʹ��Elasticsearch �洢���������̳���Ʒ��������,ÿ��������һ����Ʒ��ʱ��,������ Elasticsearch �н�����������١���һ��,�����������һ�δ�����ͻȻ��,����һ��Ҫ���ü�����Ʒ������������web����������,ÿһ����ͬʱ����������Ʒ�����ۡ�
web_1 ��stock_count�����ĸ����Ѿ���ʧ,��Ϊ web_2��֪������ stock_count�Ŀ����Ѿ����ڡ�������ǻ���Ϊ�г�����Ʒ��ʵ�������Ŀ��,��Ϊ�����˿͵Ŀ����Ʒ��������,���ǽ������Ƿdz�ʧ����
���ԽƵ��,�����ݺ������ݵļ�϶Խ��,Ҳ��Խ���ܶ�ʧ����������ݿ�������,�����ַ���ͨ��������ȷ����������ʱ������ᶪʧ:
- ���۲�������:���ַ�������ϵ�����ݿ�㷺ʹ��,���ٶ��б����ͻ���ܷ���,�������������Դ�Է�ֹ��ͻ��һ�����͵������Ƕ�ȡһ������֮ǰ�Ƚ�����ס,ȷ��ֻ�з��������߳��ܹ����������ݽ����ġ�
- �ֹ۲�������:Elasticsearch ��ʹ�õ����ַ����ٶ���ͻ�Dz����ܷ�����,���Ҳ����������ڳ��ԵIJ�����Ȼ��,���Դ�����ڶ�д���б���,���½���ʧ�ܡ�Ӧ�ó������������������ν����ͻ������,�������Ը��¡�ʹ���µ����ݡ����߽�������������û���
?
�ֹ۲�������
Elasticsearch�Ƿֲ�ʽ�ġ����ĵ����������»�ɾ��ʱ,�°汾���ĵ����븴�Ƶ���Ⱥ�е������ڵ㡣ElasticsearchҲ���첽�Ͳ�����,����ζ����Щ���������з���,���ҵ���Ŀ�ĵ�ʱҲ��˳�����ҵġ�Elasticsearch��Ҫһ�ַ���ȷ���ĵ��ľɰ汾���Ḳ���µİ汾��
������֮ǰ����index , GET��DELETE����ʱ,����ָ��ÿ���ĵ�����һ��_version(�汾��),���ĵ�����ʱ�汾�ŵ�����Elasticsearchʹ�����version����ȷ���������ȷ˳��õ�ִ�С�����ɰ汾���ĵ����°汾֮��,�����Ա��ĺ��ԡ�
���ǿ�������version����ȷ��Ӧ�������ͻ�ı�����ᵼ�����ݶ�ʧ������ͨ��ָ����Ҫ���ĵ��� version�����ﵽ���Ŀ�ġ�����ð汾���ǵ�ǰ�汾��,���ǵ�����ʧ�ܡ�
�ϵİ汾esʹ��version,�����°汾��֧����,�ᱨ����Ĵ���,��ʾ������if_seq _no��if _primary_term
?
��������
#PUT http://127.0.0.1:9200/shopping/_create/1001
?���ؽ��
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 10,
"_primary_term": 15
}
��������?
#POST http://127.0.0.1:9200/shopping/_update/1001
{
"doc":{
"title":"��Ϊ�ֻ�"
}
}
���ؽ��:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 15
}
�ɰ汾ʹ�õķ�ֹ��ͻ���·���:
#POST http://127.0.0.1:9200/shopping/_update/1001?version=1
{
"doc":{
"title":"��Ϊ�ֻ�2"
}
}
���ؽ��:?
{
"error": {
"root_cause": [
{
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"
}
],
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"
},
"status": 400
}
?�°汾ʹ�õķ�ֹ��ͻ���·���:
#POST http://127.0.0.1:9200/shopping/_update/1001?if_seq_no=11&if_primary_term=15
{
"doc":{
"title":"��Ϊ�ֻ�2"
}
}
���ؽ��:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 12,
"_primary_term": 16
}
�ⲿϵͳ�汾����
һ��������������ʹ���������ݿ���Ϊ��Ҫ�����ݴ洢,ʹ��Elasticsearch�����ݼ���,����ζ�������ݿ�����и��ķ���ʱ����Ҫ�����Ƶ�Elasticsearch,���������̸�����һ����ͬ��,���������������֮ǰ�����IJ������⡣
�����������ݿ��Ѿ����˰汾��,��һ������Ϊ�汾�ŵ��ֶ�ֵ����timestamp,��ô��Ϳ����� Elasticsearch ��ͨ������ version_type=extermal����ѯ�ַ����ķ�ʽ������Щ��ͬ�İ汾��,�汾�ű����Ǵ����������,��С��9.2E+18,һ��Java�� long���͵���ֵ��
�ⲿ�汾�ŵĴ�����ʽ������֮ǰ���۵��ڲ��汾�ŵĴ�����ʽ��Щ��ͬ,Elasticsearch���Ǽ�鵱ǰ_version��������ָ���İ汾���Ƿ���ͬ,���Ǽ�鵱ǰ_version�Ƿ�С��ָ���İ汾�š��������ɹ�,�ⲿ�İ汾����Ϊ�ĵ�����_version���д洢��
?
#POST http://127.0.0.1:9200/shopping/_doc/1001?version=300&version_type=external
{
"title":"��Ϊ�ֻ�2"
}
���ؽ��:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 300,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 13,
"_primary_term": 16
}
48-����-�ĵ�չʾ-Kibana
Kibana��һ������ҿ��ŵ��û�����,�ܹ������Elasticsearch ���ݽ��п��ӻ�,��������Elastic Stack �н��е���������Խ��и��ֲ���,�Ӹ��ٲ�ѯ����,������������������������Ӧ��,����������ɡ�
һ����ѹ�����ص� zip �ļ���
������ config/kibana.yml �ļ���
# Ĭ�϶˿�
server.port: 5601
# ES �������ĵ�ַ
elasticsearch.hosts: ["http://localhost:9200"]
# ������
kibana.index: ".kibana"
# ֧������
i18n.locale: "zh-CN"
����Windows ������ִ�� bin/kibana.bat �ļ���(�״������е��ʱ)
�ġ�ͨ�����������:http://localhost:5601��

?