内容源于
https://ganeshvernekar.com/blog/prometheus-tsdb-persistent-block-and-its-index/
比如一个metrics的格式如下:
cpu{host=“computer",ip="1.2.3.4",systerm="64bit"} timestamp=xxx, value=12
cpu{host=“computer",ip="1.2.3.5",systerm="64bit"} timestamp=xxx, value=13
index总体格式分为:
symbol_table
{}内部的str信息保存。即,

str按照字典序排列,比如len(computer),str_1="computer"?
可以看到,symbol是所有出现过的label的string的汇总,他和具体的某一个series,并没有直接关系,也无法反应某些关系特征。只是提供一个string的字典集合。方便后续使用到该string的地方,直接使用索引值。
Series
这一部分是放真实series数据的地方。
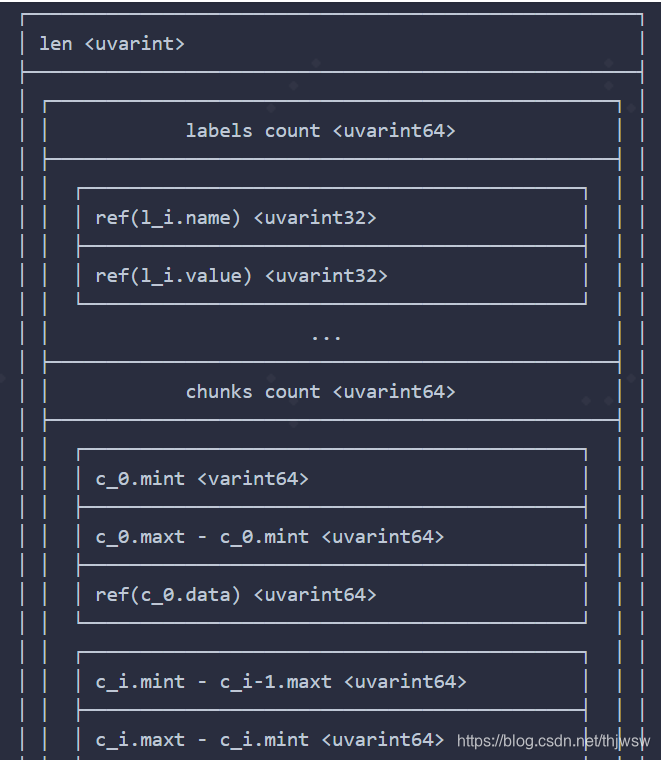
比如举例中有3个标签信息,那么labels count就是3。注意这里不包括metric name信息。具体的每一个label中,name和value,存放的是对应string在symbol table中的索引。
chunks count表示了该series信息,比如举例的cpu信息,存在于哪几个block里面,以及在每一个block中的时间范围。
到这里,似乎看起来,需要的信息都有了。但是,我们假设给一个请求,如何找到对应的数据。
比如请求cpu{host=“computer",ip="1.2.3.5"}的信息。
此时,存在两个查询条件,host和ip。很明显,symbol table只是字符串信息,并不是series信息,对查询没有直接帮助。series又是所有的metric集合,如果直接去每一个series的label count下面的name,value去匹配,就相当于全盘扫描,也体现不出index的作用了。
所以,对于label本身,还需要一个索引集合,能快速定位到series的位置。
Postings i

?
?在series组装完成后,series_1的ID为10,series_2的ID为20,那么host=computer有两个指标满足,就在posting i中,存放[10,20]
series_1
series_2
同时,还有其他组合,比如ip=xx,也会生成对应的series信息,因为ip不同,会生成[10],[20]两个posting i 信息。
Postings Offset Table
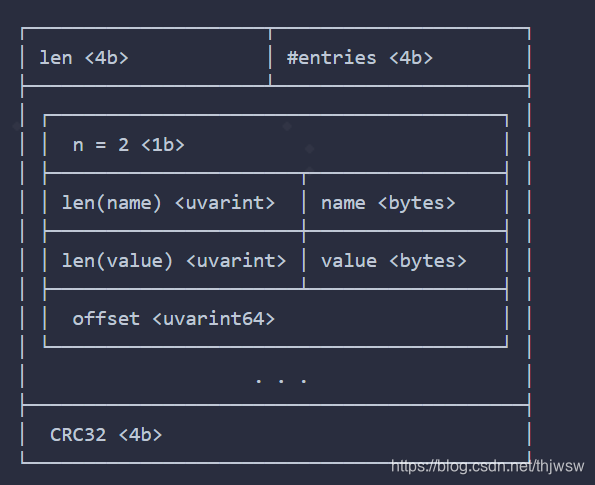
?当posting 组装完成后,就会生成对应的offset列表。比如对于host=computer的场景,
offset对应的就是[10,20]的posting位置。
对于ip=xx,offset就是[10]的posting位置。
综上,一次查找cpu{host=“computer",ip="1.2.3.5"}的过程如下:
首先查找host的posting offset table,根据offset, 去posting i表,找到了[10,20]
同时,再查找ip=.5的posting offset table.根据offset, 去posting i表,找到了20,?
所以,这次查找就需要series id=20的信息。
根据20*16的索引,在series中找到20的所有block索引信息。同时根据symbol table和block索引,拼接完数据后,就返回所有series数据了。
?