笔记最近一直在尝试flink+hudi集成开发,参考Hudi官网,使用flink1.13.0在sql-client命名行上没有成功运行,相关依赖添加至lib目录下依旧有些奇奇怪怪的错误,有兴趣的同学可以尝试下。经过多次尝试不行,笔者决定用table api实现,因为table api在idea本地运行也比较方便看日志查找错误。尝试了好多遍,终于可以使用了,感动呀!希望能帮助快速体验flink+hudi强大的功能的同学提供一点点帮助。
1.新建maven项目
? ?maven项目这里不多做介绍,大家参考网上的资料都可以
2.pom.xml文件
? 这里尝试了flink1.13.0和flink1.12.0版本,貌似只有1.12.0能成功运行,scala版本1.11或者1.12都可以运行
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>flink-parent</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink-hudi</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<scala.binary.version>2.12</scala.binary.version>
<flink.version>1.12.0</flink.version>
</properties>
<dependencies>
<!-- table start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- hudi start -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-bundle_${scala.binary.version}</artifactId>
<version>0.8.0</version>
<scope>provided</scope>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.apache.hudi</groupId>-->
<!-- <artifactId>hudi-flink_${scala.binary.version}</artifactId>-->
<!-- <version>0.8.0</version>-->
<!-- <scope>provided</scope>-->
<!-- </dependency>-->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-client</artifactId>
<version>0.8.0</version>
<scope>provided</scope>
</dependency>
<!-- hudi end -->
<!-- Add logging framework-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.15</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
</project>2.main程序
path路径可以自行修改,使用flink?DataGen 连接器灵活地生成记录
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class HudiTable {
public static void main(String[] args) throws Exception {
// System.setProperty("hadoop.home.dir", "/home/monica/bigdata/hadoop-2.10.1");
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
bsEnv.setStateBackend(new FsStateBackend("file:///home/monica/study/flink/flink-parent/flink-hudi/src/main/resources/checkpoints"));
// // 每 1000ms 开始一次 checkpoint
bsEnv.enableCheckpointing(10000);
//
// // 高级选项:
//
设置模式为精确一次 (这是默认值)
bsEnv.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//
确认 checkpoints 之间的时间会进行 500 ms
// bsEnv.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//
Checkpoint 必须在一分钟内完成,否则就会被抛弃
// bsEnv.getCheckpointConfig().setCheckpointTimeout(60000);
//
同一时间只允许一个 checkpoint 进行
// bsEnv.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//
开启在 job 中止后仍然保留的 externalized checkpoints
// bsEnv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
bsEnv.setParallelism(1);
StreamTableEnvironment env = StreamTableEnvironment.create(bsEnv, bsSettings);
env.executeSql("create table t2(\n" +
" uuid VARCHAR(20), \n" +
" name VARCHAR(10),\n" +
" age INT,\n" +
" ts TIMESTAMP(3),\n" +
" `partition` INT\n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'fields.partition.max' = '5',\n" +
" 'fields.partition.min' = '1',\n" +
" 'rows-per-second' = '1'\n" +
")");
// env.executeSql("select * from t2").print();
// env.executeSql("CREATE TABLE t1(uuid VARCHAR(20),name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` INT) PARTITIONED BY (`partition`) WITH ('connector' ='hudi','path' = 'file:///home/monica/study/flink/flink-parent/flink-hudi/src/main/resources/test','write.tasks' = '1', 'compaction.tasks' = '1', 'table.type' = 'COPY_ON_WRITE')");
env.executeSql("CREATE TABLE t1(\n" +
" uuid VARCHAR(20), -- you can use 'PRIMARY KEY NOT ENFORCED' syntax to mark the field as record key\n" +
" name VARCHAR(10),\n" +
" age INT,\n" +
" ts TIMESTAMP(3),\n" +
" `partition` INT\n" +
")\n" +
"PARTITIONED BY (`partition`)\n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'file:///home/monica/study/flink/flink-parent/flink-hudi/src/main/resources/test',\n" +
" 'write.tasks' = '1', -- default is 4 ,required more resource\n" +
" 'read.streaming.enabled'= 'true', \n" +
" 'table.type' = 'MERGE_ON_READ' -- this creates a MERGE_ON_READ table, by default is COPY_ON_WRITE\n" +
")");
//插入一条数据
// env.executeSql("INSERT INTO t1 SELECT * FROM source_table");
// env.sqlQuery("SELECT * FROM t1")//结果①
// .execute()
// .print();
// //修改数据
env.executeSql("INSERT INTO t1 select * from t2")
.print();
// env.executeSql("INSERT INTO t1 VALUES('id1','Danny',24,TIMESTAMP '1970-01-01 00:00:01','par1')")
// .print();
// env.sqlQuery("SELECT * FROM t1")//结果②
// .execute()
// .print();
}
}
3.log4j配置文件(查看看日志需要)
命名log4j.properties,放在资源路径下即可
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
log4j.rootLogger=info, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
4,运行main程序
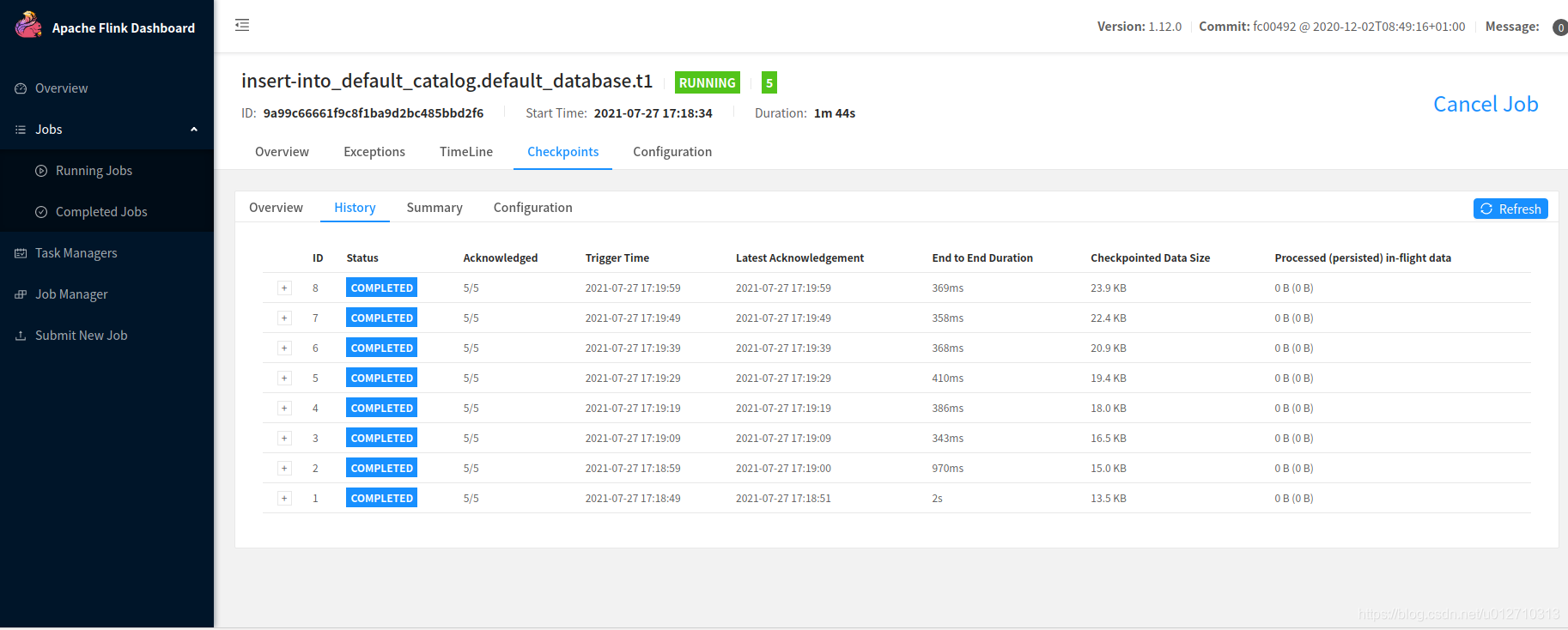
运行main程序,查看日志输出的端口,访问flink web界面看到程序正常运行以及checkpoint正常就ok了
?
?
参考文档:
https://blog.csdn.net/huashetianzu/article/details/117166515