**Python Spark+hadoop安装配置及安装包**
最近有用到python的spark框架,所以和大家来聊聊这些配置安装方面的问题,后期会更新spark方面的知识。
我采用的spark版本是spark-3.0.3-bin-hadoop2.7
hadoop的版本是hadoop-2.8.3
废话不多说,先直接贴下载地址
我的百度云链接链接:https://pan.baidu.com/s/1z4a4J1D01Clbeoy5NRKCQQ
提取码:krqi
永久有效,无效可私聊本人
前提:jdk8的配置安装,这里我就不多做描述了,大家可以百度看看
1.spark解压及配置
下载完以后首先将spark-3.0.3-bin-hadoop2.7解压
解压
这是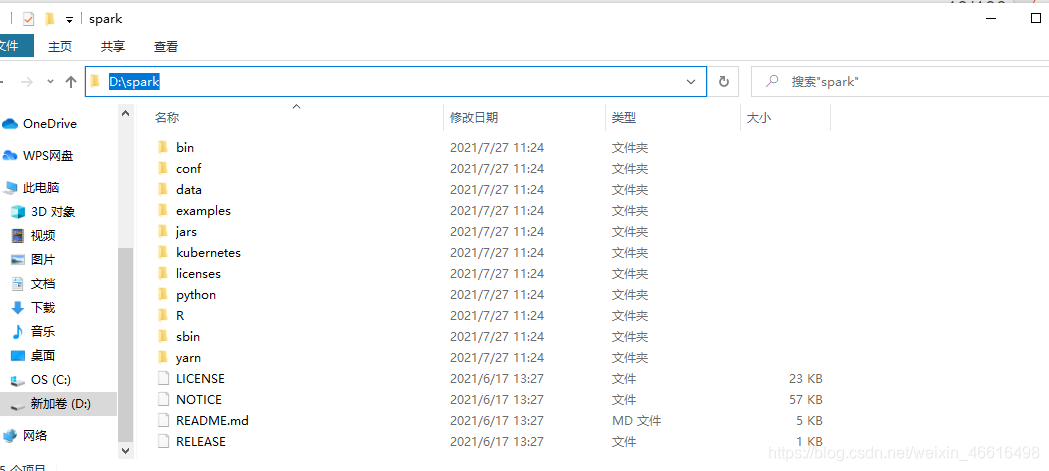
这个是解压以后的目录
配置环境变量
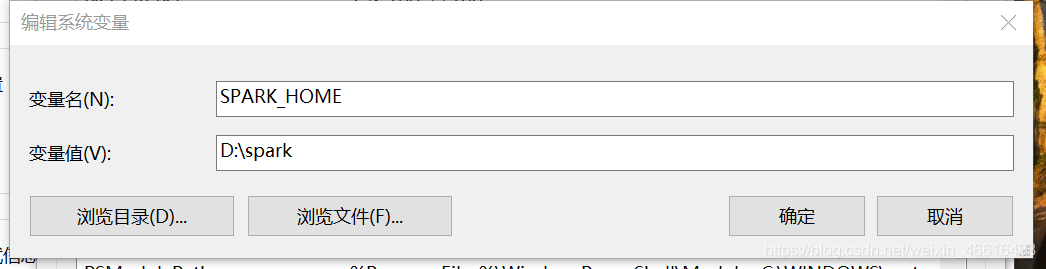
新增环境变量
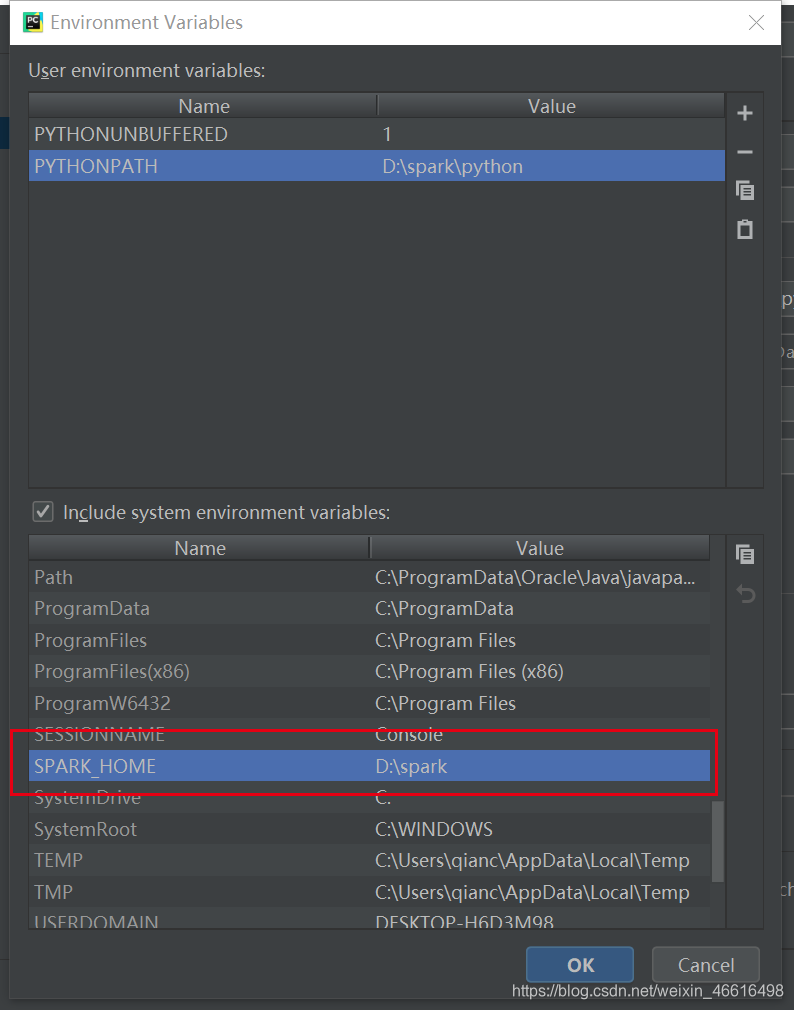
变量名:SPARK_HOME
变量值:D:\spark
注意,变量值是你解压后的spark的文件路径
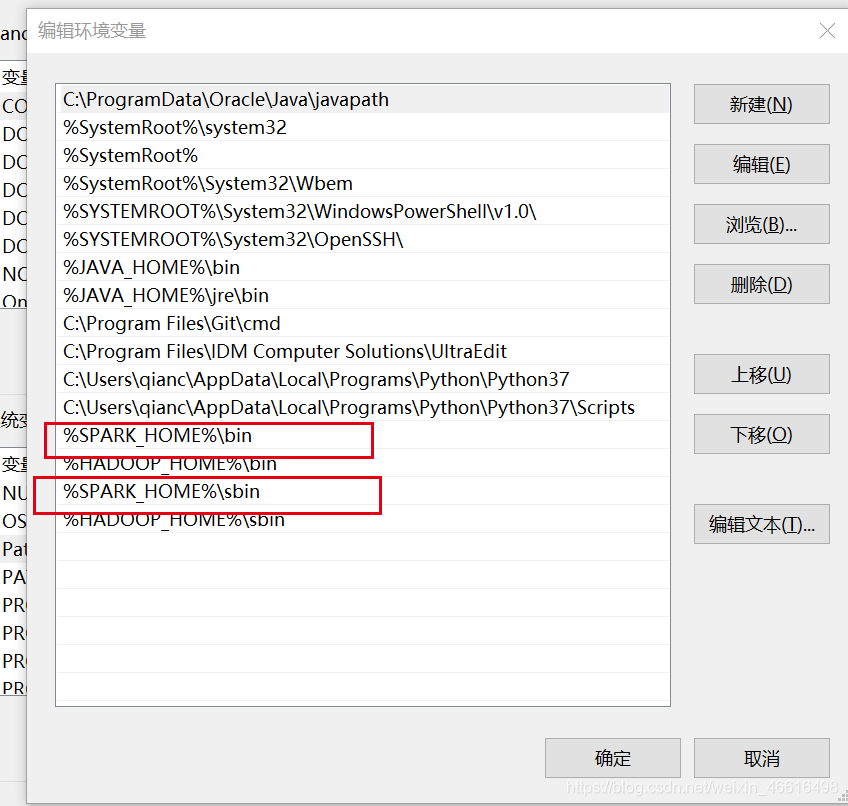
然后需要在环境变量PATH下新增变量值
%SPARK_HOME%\bin和%SPARK_HOME%\sbin
如图
2.hadoop解压及配置
同理
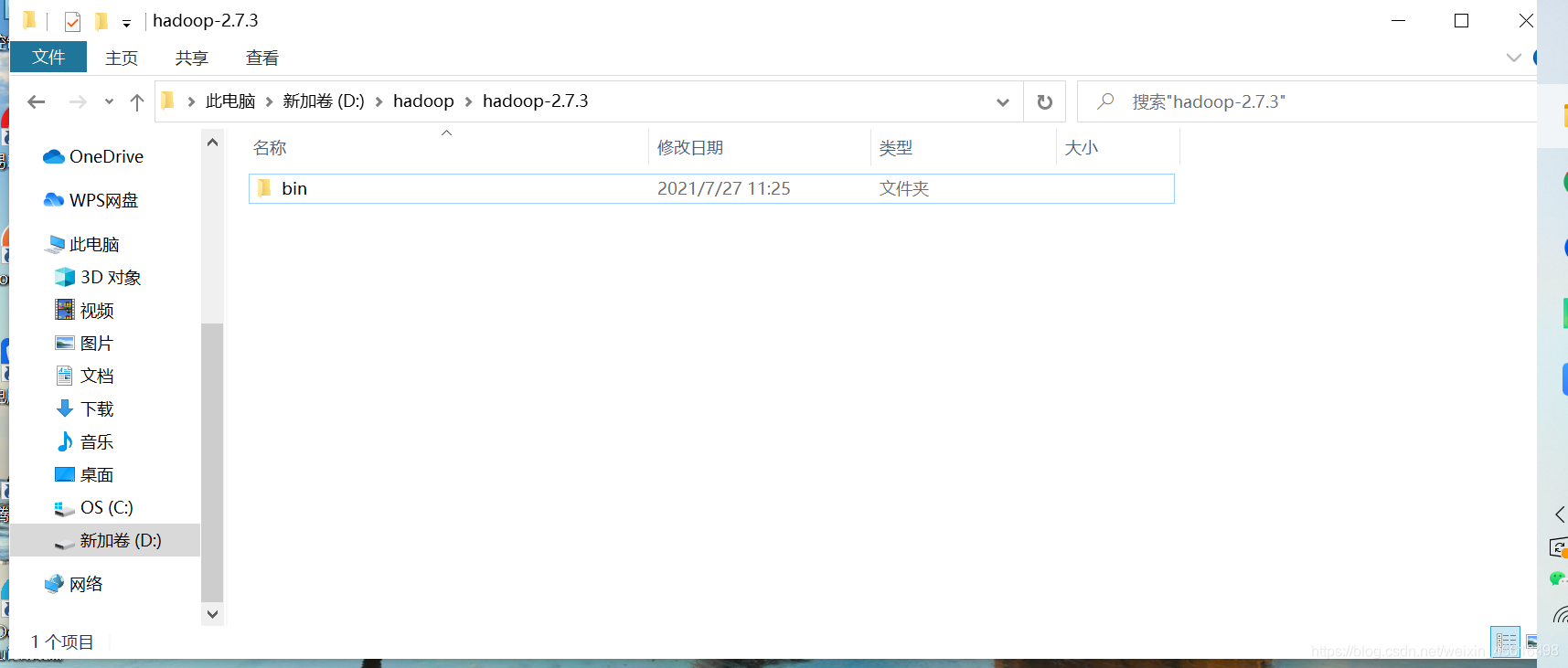
其他的目录我删除了,我没有用到,有需要的小伙伴可以重新下载
配置
新增系统变量
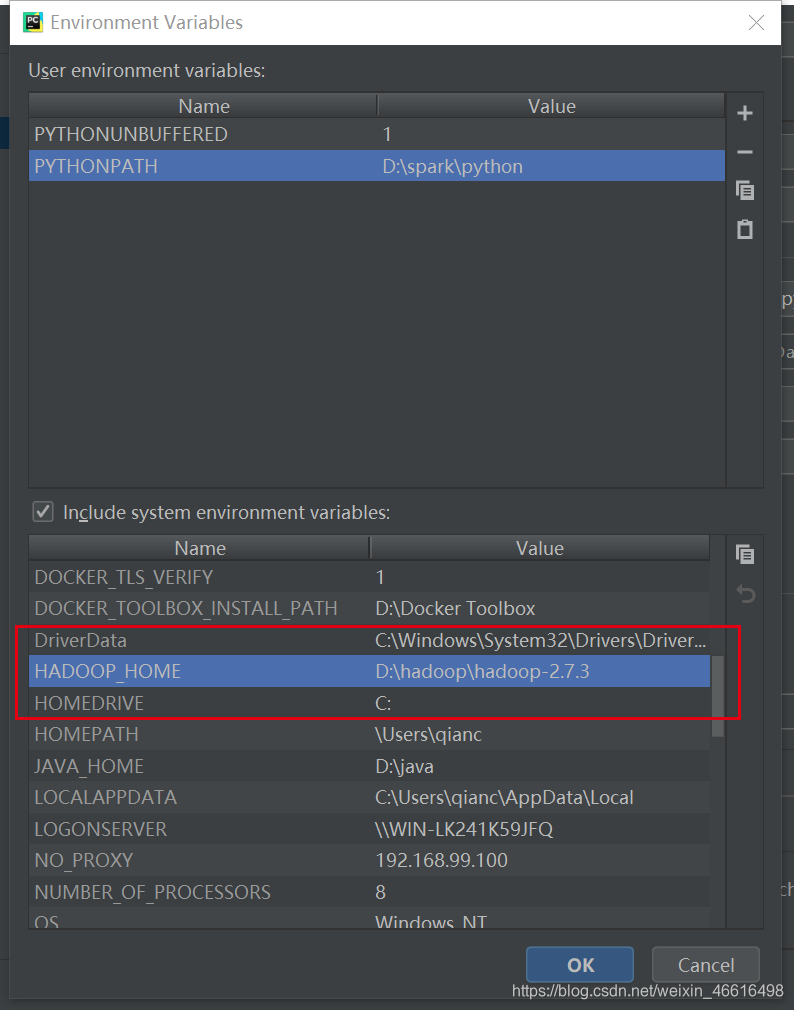
变量名:HADOOP_HOME
变量值:D:\hadoop\hadoop-2.7.3
变量值是解压以后的hadoop地址
同理Path下也需要进行配置
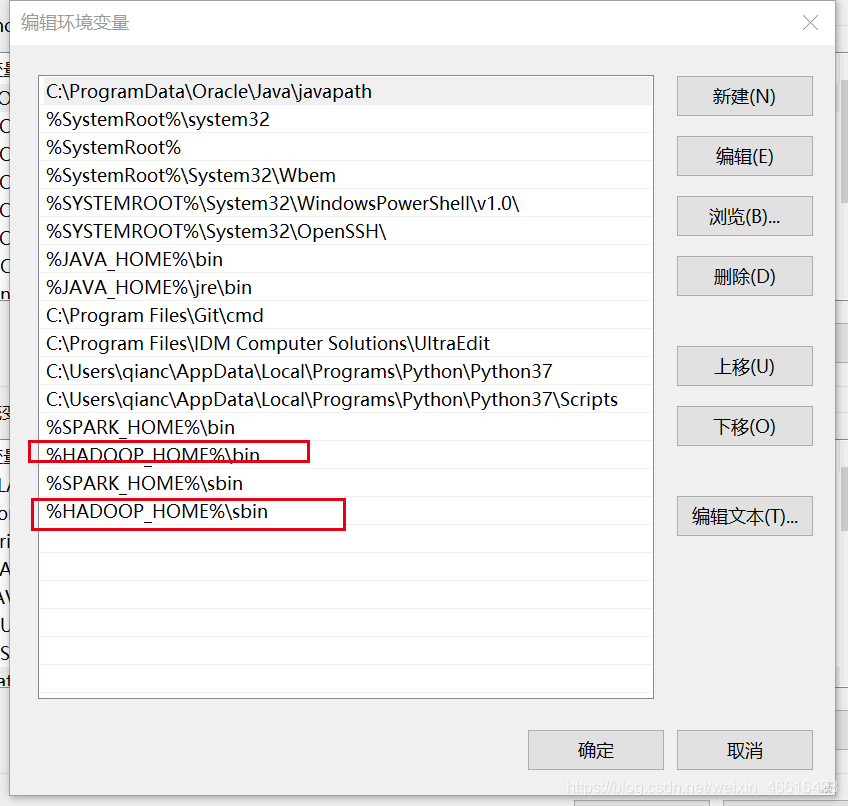
sbin目录没有可以不进行配置
做到这里其实差不多配置好了
但是我发现启动python脚本的时候发现有报错
报错的原因是因为pycharm找不到spark的位置,需要初始化
有两种结局方式
方式1:
在脚本上面加这两句
import findspark
findspark.init()
方式2:
在相应的脚本上
点击edit configurations
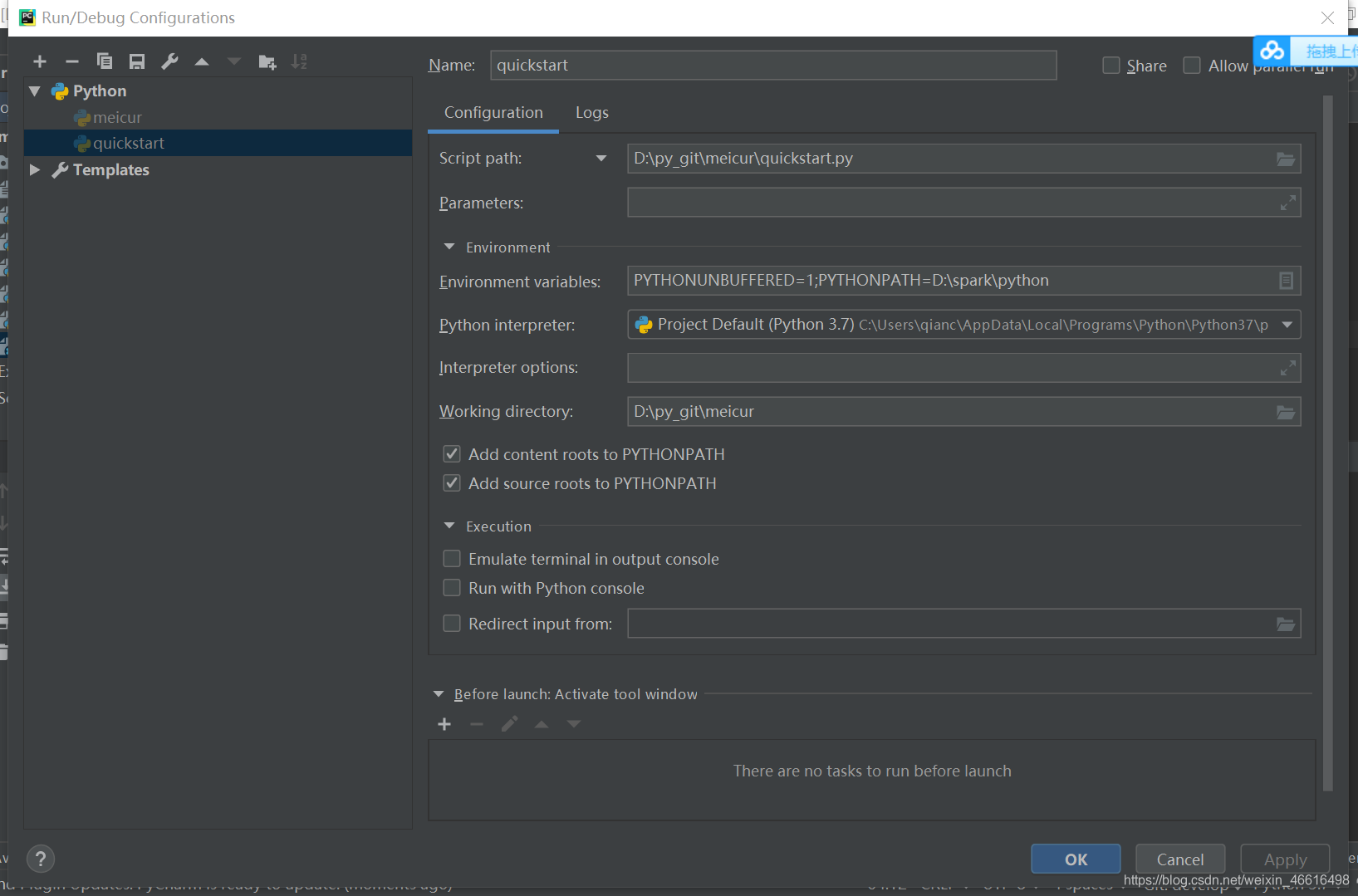
选择environment variables
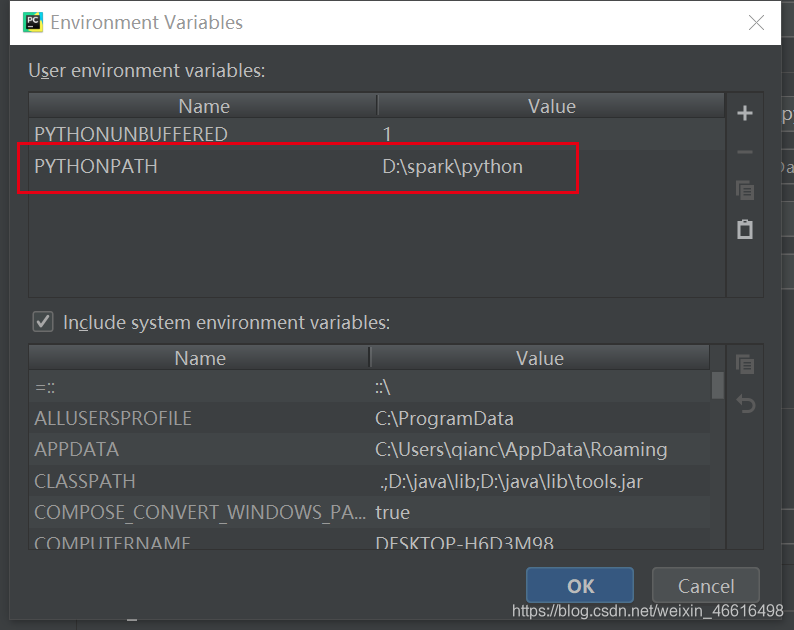 添加
添加
PYTHONPATH=D:\spark\python
值就是spark目录下的一个python文件夹
加完以后可以试着启动一下,如果有问题重启一下pycharm试一下,应该就可以了,本人亲测可用