һ��˵��
�����̳ǵ�ES�������ʼ� �� �����̳ǵ�ES����Ƶ
����dockers��es����
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
ElasticSearch����·��
Kibana����·��
������ɾ�IJ�
p105)����es��Ϣ
����ElasticSearch�е�Get������http://192.168.218.128:9200/_cat/nodes���Ǽ��ΪGET /_cat/nodes,
GET /_cat/nodes:�鿴���нڵ�
GET /_cat/health:�鿴es����״��
GET /_cat/master:�鿴���ڵ�
GET/_cat/indicies:�鿴�������� ,�ȼ���mysql���ݿ��show databases;
p106)����&���ĵ�
���������������͡��������ĵ� ����� ���ݿ⡪�����ݱ�����������
�ڿ�����put�������post:
PUT customer/external/1 :��customer�����µ�external�����±���1������
POST customer/external/1 :��customer�����µ�external�����±���1������
http://192.168.56.10:9200/customer/external/1
{
"name":"John Doe"
}
��PUT��POST����
POST�������ָ��id,���Զ�����id��ָ��id�ͻ����������,�������汾��;
- ���Բ�ָ��id,��ָ��idʱ��ԶΪ����
- ָ�����ڵ�idΪ����,���汾�Ż�������ݱ�û��������汾�ŵ������
PUT��PUT����ָ��id;����PUT��Ҫָ��id,����һ���������IJ���,��ָ��id�ᱨ����
- ����ָ��id
- �汾���ܻ�����(Put�Ƚ�ç,�����Ա����ݰ�)
p107)ʹ���ֹ��������ĵ�
PUT http://192.168.56.10:9200/customer/external/1?if_seq_no=18&if_primary_term=6
�ֹ����÷�:ͨ����
if_seq_no=1&if_primary_term=1��,�����к�ƥ���ʱ��,�Ž�����,�����ġ�
_seq_no�Dz��������ֶ�,ÿ�θ��¶���+1,�������ֹ�����
_primary_termҲ��һ�������ֶ�,������Ƭ���·���(������),�ͻ�仯
p108)�����ĵ�
Post��update:POST customer/externel/1/_update,��Ա�ԭ��������,���������ԭ������ͬ,��(version��_seq_no)�����䡣
Post����update:POST customer/externel/1,�ܻ����±��沢����version�汾��
Put���ܴ�update: PUT customer/externel/1,�ܻ����±��沢����version�汾��
p109)ɾ���ĵ�������
DELETE customer/external/1 ɾ���ĸ������ĸ������µ��ĸ��ĵ�
DELETE customer ɾ����������
��Ȼ�����൱�����ݿ��еı�,����û��ɾ�����͵IJ���
p109)ES��������������bulk
POST /customer/external/_bulk ���ĸ������ĸ���������������
POST http://192.168.56.10:9200/customer/external/_bulk
//����Ϊһ������
{"index":{"_id":"1"}}
{"name":"a"}
{"index":{"_id":"2"}}
{"name":"b"}
//ע����Post�����ʽ���ó�json��text������,���Ա���Ҫȥkibana��Dev Tools
POST /_bulk ������������ִ����������
POST /_bulk //�㿴����������������ɾ��IJ鶼����
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}
�������������,������ijһ��ִ�з���ʧ��ʱ,������������Ȼ�ܹ�����ִ��,Ҳ����˵�˴�֮���Ƕ����ġ�
���һ�������Ķ���ʧ��,������������������ʣ��Ķ�������bulk api����ʱ,�����ṩÿ��������״̬(�뷢�͵�˳����ͬ),���������Լ���Ƿ�һ��ָ���Ķ����Ƿ�ʧ���ˡ�
����Es��ѯ
p110)��������ʽ:
�����������ʽ����:GET bank/_search?q=*&sort=account_number:asc,����GET bank/_search��ʾ����bank��������Ϣ,����type��docs;q=*��ʾ��ѯ����;sort=account_number�������ֶ������ֶ�;asc��ʾ����
��uri+��������м���(��õķ�ʽ,���ַ�ʽ�����dz�ΪQuery DSL����)
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" },
{ "balance":"desc"}
]
}
��������:
took�C ���Ѷ���ms����timed_out�C �Ƿ�ʱ_shards�C ���ٷ�Ƭ��������,�Լ����ٳɹ�/ʧ�ܵ�������Ƭmax_score�C�ĵ��������ߵ÷�hits.total.value- ����ƥ���ĵ����ҵ�hits.sort- ���������key(��),û�еĻ�����score����hits._score- ��ص÷� (not applicable when using match_all)- ������1000������,���Ǹ���������㷨,ֻ����10��
111)Query DSL����
GET bank/_search
{
"query": { #��ѯ���ֶ�
"match_all": {} #��ѯ���е�����
},
"from": 0, #�ӵڼ����ĵ���ʼ��
"size": 5, #from+size��,��ɷ�ҳ����;
"_source":["balance"], #ָ��Ҫ���ص��ֶ�
"sort": [
{
"account_number": { # ���ؽ�����ĸ�������
"order": "desc" # ����
}
}
]
}
112)query/matchƥ���ѯ1
������Ƿ��ַ���,����о�ȷƥ�䡣
GET bank/_search
{
"query": {
"match": {
"account_number": 20 #����account_number=20������(�������Ǿ�ȷƥ��)
}
}
}
��ѯ���:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1, // �õ�һ��
"relation" : "eq"
},
"max_score" : 1.0, # ���÷�
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 1.0,
"_source" : { # �����ĵ���Ϣ
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "elinorratliff@scentric.com",
"city" : "Ribera",
"state" : "WA"
}
}
]
}
}
��������ַ���,�����ȫ�ļ���
GET bank/_search
{
"query": {
"match": {
"address": "mill lane"
}
}
}
# ��ѯ���Ľ����"mill lane"(�÷�9.80),��ֻ��mill��"mill road",Ҳ��ֻ��lane��"lane tol",����ģ��ƥ�䵽���Ǿ��ǵ÷ֵ�һ��
113)query/matchƥ���ѯ2
match_phrase:������ַ������м���
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road" #����˵��Ҫƥ��ֻ��mill��ֻ��road��,Ҫ���ܹ�ƥ��mill roadһ�����Ӵ�(�����"990 Mill Road")
}
}
}
�ֶ�.keyword:����ȫƥ���ϲż����ɹ�
GET bank/_search
{
"query": {
"match_phrase": {
"address".keyword: "mill road" #����˵Ҫ��"mill road"��ȫequal,����ƥ�䲻��
}
}
}
114)query/multi_math�����ֶ�ƥ�䡿
GET bank/_search
{
"query": {
"multi_match": { #ǰ���match��ָ����һ���ֶΡ�
"query": "mill road",
"fields": ["state","address"] #����state��address������mill road�ַ�����
}
}
}
#����зִʲ�ѯ,Ҳ����˵state��address������mill road��ֻ��mill��ֻ��road�ַ����Ķ���ƥ����
115)query/bool���ϲ�ѯ
- must:����ﵽmust���оٵ���������
- must_not:���벻ƥ��must_not���оٵ�����������
- should:Ӧ������should���оٵ������������������,������Ҳ����,����÷ָ���
GET bank/_search
{
"query":{
"bool":{
"must":[ #������ϲ�ѯgender=m,����address=mill������
{"match":{"address":"mill"}},
{"match":{"gender":"M"}}
]
}
}
}
GET bank/_search
{
"query": {
"bool": { #��ѯgender=m,����address=mill������,����age������38��
"must": [
{ "match": { "gender": "M" }},
{ "match": {"address": "mill"}}
],
"must_not": [
{ "match": { "age": "38" }}
]
}
}
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age": "18"
}
}
],
"should": [
{
"match": {
"lastname": "Wallace" #lastName�����Wallace������
}
}
]
}
}
}
116)query/filter��������ˡ�
- must ���÷�
- should ���÷�
- must_not �����÷�
- filter �����÷�
- �����must��shouldӰ������Ե÷�,��must_not��filterһ��,���Ǹ�������
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"filter": {
"range": {
"balance": {
"gte": "10000",
"lte": "20000"
}
}
}
}
}
}
117)query/term
- term�÷���matchһ����������һ���淶����:�ı��ֶ�text��ѯ��
match,������text�ֶ�(����age��idʲô��)ƥ����term�� - ��Ϊterm��ѯ��ʵ�Ǿ�ȷƥ��,es�洢textֵʱ�÷ִʷ�ʽ(���ַ�ʽ����ȷ),����Ҫ����textֵ,ʹ��match��
GET bank/_search
{
"query": {
"term": {
"age": "28"
}
}
}
�ġ�������
p118)�ۺϲ���
- terms:��ֵ�Ŀ����Էֲ�,��ϲ������ֶ�,������������
- avg:��ֵ�ķֲ�ƽ��
������address�а���mill�������˵�(����ֲ���ƽ�����䡢н�ʷֲ�),������ʾ��Щ�˵�����
# ע��������������!!!
GET bank/_search
{
"query": { # ��ѯ������mill��
"match": {
"address": "Mill"
}
},
"aggs": { #���ڲ�ѯ�ۺ�
"ageAgg": { # �ۺϵ�����,�����
"terms": { # ��ֵ�Ŀ����Էֲ�
"field": "age",
"size": 10
}
},
"ageAvg": {
"avg": { # ��ageֵ��ƽ��
"field": "age"
}
},
"balanceAvg": {
"avg": { # ��balance��ƽ��
"field": "balance"
}
}
},
"size": 0 # ��������
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4, // ����4��
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : { // ��һ���ۺϵĽ��
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38, # ageΪ38����2��
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
},
"ageAvg" : { // �ڶ����ۺϵĽ��
"value" : 34.0 # balance�ֶε�ƽ��ֵ��34
},
"balanceAvg" : { // �������ۺϵĽ��
"value" : 25208.0
}
}
}
�ڲ�ѯ�����˵�(����ֲ�(���һ�������ֲ�����Щ����ε���Щ�˵�ƽ��н��))
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": { # ��һ���ۺ�,���ֲ�
"field": "age",
"size": 100
},
"aggs": { # ���ڵ�һ���ۺϵĽ�����پۺ�
"ageAvg": { #ƽ��
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
{
"took" : 49,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"ageAvg" : {
"value" : 28312.918032786885 //31�����61��,ƽ��н����28312
}
},
{
"key" : 39,
"doc_count" : 60,
"ageAvg" : {
"value" : 25269.583333333332 //39�����60��,ƽ��н����25269
}
},
..............
..............
]
}
}
}
�۲����������ֲ�,������Щ�������M��ƽ��н�ʺ�F��ƽ��н���Լ��������ε�����ƽ��н��
�����������[����(ƽ��н��)]��[Ů��(ƽ��н��)]��[����ƽ��н��]��
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": { # ��age�ֲ�
"field": "age",
"size": 100
},
"aggs": { # �Ӿۺ�
"genderAgg": {
"terms": { # ��gender�ֲ�
"field": "gender.keyword" # ע������,�ı��ֶ�Ӧ����.keyword
},
"aggs": { # �Ӿۺ�
"balanceAvg": {
"avg": { # ���Ե�ƽ��
"field": "balance"
}
}
}
},
"ageBalanceAvg": {
"avg": { #age�ֲ���ƽ��(��Ů)
"field": "balance"
}
}
}
}
},
"size": 0
}
{
"took" : 119,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31, //31�����61��
"doc_count" : 61,
"genderAgg" : { //��31����Ⱥ���Ա�ֲ�
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M", //31����Ⱥ��������35��
"doc_count" : 35,
"balanceAvg" : {
"value" : 29565.628571428573 //31����Ⱥ��������35��,ƽ��н����29565
}
},
{
"key" : "F", //31����Ⱥ��Ů����26��
"doc_count" : 26,
"balanceAvg" : {
"value" : 26626.576923076922 //31����Ⱥ��Ů����26��,ƽ��н����26626
}
}
]
},
"ageBalanceAvg" : {
"value" : 28312.918032786885 //31����Ⱥ��ƽ��н��28312
}
}
]
.......//ʡ������
}
}
}
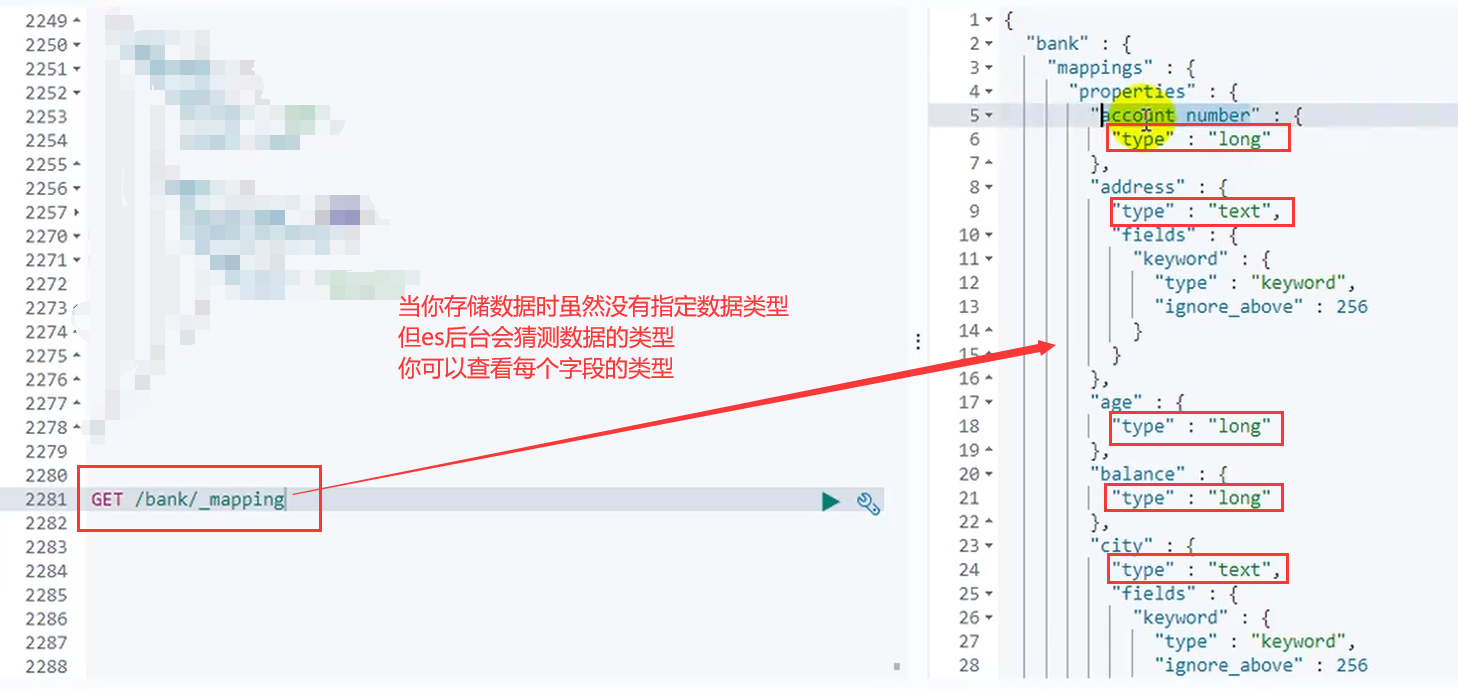
p119)��120)��121)Mapping�ֶ�ӳ��
1.��������
��ǰ���������������͡��������ĵ� ����� ���ݿ⡪�����ݱ�����������
��7.0�汾�Ժ�����"����"��˵����,�ĵ�����ֱ�Ӵ洢����������

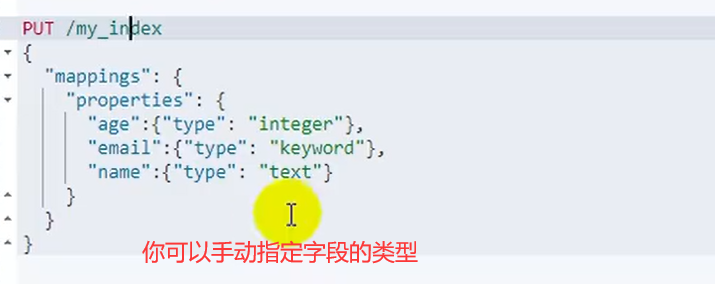
2.����Mapping�ֶ�ӳ��
3.�¼�ӳ��
������һ����age��email��name�ֶε�ӳ��,����������Ҫ�¼�һ���ֶε�ӳ��ʱ����ô��
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false #��ʾ���ֶ�ֻ��һ������洢���ֶ�,���ܱ���ȥ������
}
}
}
4.��ӳ��
���ܸ���ӳ��:�����Ѿ����ڵ��ֶ�ӳ��,���Dz��ܸ��¡����±��봴���µ�����,��������Ǩ�ơ�
�е��鷳,��Ҫ�Ļ��뿴��Ƶ:p121��ӳ��������Ǩ��
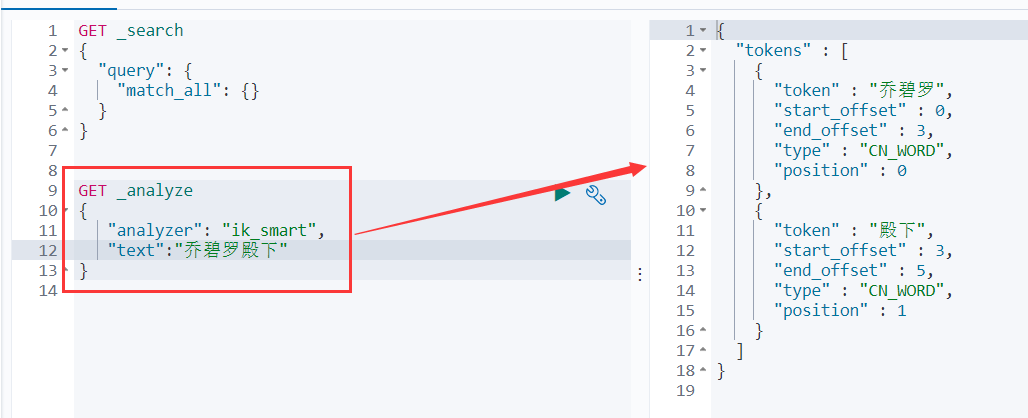
p122)�ִ�
��������linux���氲װes�ķִ�������װik�ִ�
����������Xshell5��Xftp5��ʹ��
//ʹ��Ĭ�Ϸִ�������:
GET _analyze
{
"text":"�������"
}
//ʹ��ik�ִ�������
GET _analyze
{
"analyzer": "ik_smart",
"text":"�������"
}
p123)��vagrant����
p124)ik�ִ�֮�Զ���ִ���
����װһ��nginx,���Զ���ִ�д��nginx��ij���ļ���,Ȼ����ik�ִ�����nginx��������,��ȡ���µĴʿ�
1.����docker��nginx�İ�װ�����
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf/:/etc/nginx \
-d nginx:1.10

2.�Զ���ִ�
��/mydata/nginx/html�������nginx���Զ���htmlҳ���Ŀ¼,
�������潨��һ��esĿ¼���es��ص�����,������/mydata/nginx/html/es�´���fenci.txt�����Ҫ�Զ���ķִ�,����д�ˡ��DZ��ޡ��͡��й�ȡ�
Ȼ����ik������������ȡ/mydata/nginx/html/es/fenci.txt,����ik�Ϳ��Ը���������Զ���ִʽ��зִ�
�塢SpringBoot����ES
p125)SpringBoot����Es
���鿴�����й�ȡ�ElasticSearch��p49��p53����SpringBoot����ES,�ٻ����������Ƶ��
����ڵ���������ElasticSearch�ıʼ�����д�ĺ����
p126)JavaAPI������ES1
p126����ʵ���Ͼ������й�ȡ�ElasticSearch��p18��p28����JavaAPI���������ES,����ֻ���˱�ɽһ��,û��Ҫȥ��ʲô�ʼ�
����ڵ���������ElasticSearch�ıʼ�����д�ĺ����
p127)JavaAPI������ES2
p127����ʵ���Ͼ������й�ȡ�ElasticSearch��p18��p28����JavaAPI���������ES,����ֻ���˱�ɽһ��,û��Ҫȥ��ʲô�ʼ�
����ڵ���������ElasticSearch�ıʼ�����д�ĺ����