centos安装elasticsearch
文章目录
前言
本系列学习笔记测试环境基于liunx系统搭建,系统环境为centos7.9,JDK版本为 jdk-11.0.12,elasticsearch版本为7.13.4,水平有限,欢迎指导
安装JDK
1. 下载JDK压缩包
到oracle官网下载对应JDK压缩包 : https://www.oracle.com/java/technologies/javase-jdk11-downloads.htm。
由于坑爹的oracle官网下载安装包是要登录的,经过尝试在linux下通过wget下载的包解压不成功,这里提供2种方案亲测有效:
- windows下载,再通过工具上传到linux上
- Oracle登录后下载,在下载页面复制链接地址
得到一串带有验证参数的下载链接https://download.oracle.com/otn/java/jdk/11.0.12+8/f411702ca7704a54a79ead0c2e0942a3/jdk-11.0.12_linux-x64_bin.tar.gz?AuthParam=1627264183_15c4876516638ccb3e6e09cc0fe7f0b8(失效链接,这种链接是有时效的,所以要尽快使用),再通过wget下载
2. 解压文件
创建文件夹 makdir /opt/java
解压文件
tar -zxvf jdk11.tar.gz -C /opt/java
进入java目录

3. 编辑profile文件
vim /etc/profile
在末尾添加下面内容,JAVA_HOME的值改为上面解压得到的实际目录
export JAVA_HOME=/opt/java/jdk1.8.0_291
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOMR/lib:$CLASSPATH
export JAVA_PATH=$JAVA_HOME/bin:$JRE_HOME/bin
export PATH=$PATH:$JAVA_PATH
刷新配置 source /etc/profile
4. 查看结果
java -version

安装成功
安装elasticsearch
1. 下载Elasticsearch
到官网下载对应文件并解压 https://www.elastic.co/cn/downloads/elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.4-linux-aarch64.tar.gz

2. 解压文件
tar -zxvf elasticsearch-7.13.4-linux-aarch64.tar.gz -C /opt/elasticsearch/

3. 修改配置文件
主要配置文件在config文件夹中jvm.options和elasticsearch.yml
修改jvm.options中-Xms4g和-Xmsx4g,根据自己主机内存调整大小
path.data: /opt/elasticsearch/data
path.log: /opt/elasticsearch/logs
4. 启动Elasticsearch
./bin/elasticsearch -d

不能用 root账号启动es,
创建账号 例如 elastic
启动:
报错
ElasticsearchException[Failure running machine learning native code. This could be due to running on an unsupported OS or distribution, missing OS libraries, or a problem with the temp directory. To bypass this problem by running Elasticsearch without machine learning functionality set [xpack.ml.enabled: false].]

编辑elasticsearch.yml
末尾添加:
xpack.ml.enabled: false
启动es

报错 :the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决:
discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes 至少设置一个
报错 : max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决:修改一个进程能拥有最大内存区域限制 编辑 /etc/sysctl.conf加入下面内容 ,保存后 执行 sysctl -p.
vm.max_map_count = 262144
vm.swappiness = 1
再次启动
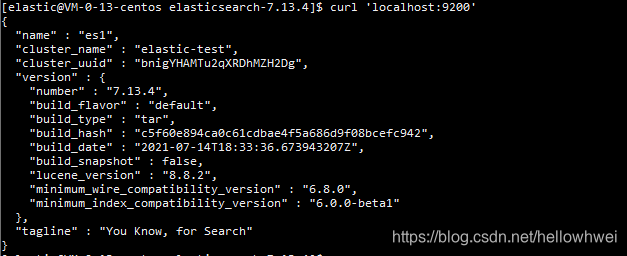
执行curl 'localhost:9200'