基于dolphinscheduler的增量数据同步至hive分区表
- 前言
- 一、创建新的hive分区表
- 二、hive分区表创建好后需要增加分区,使用shell命令创建分区
- 三、datax同步增量数据只分区中
- 四、创建定时任务
- 总结
前言
本文主要介绍dolphinsccheduler集成datax以及hive后增量数据的集成问题
提示:以下是本篇文章正文内容,下面案例可供参考
一、创建新的hive分区表
1.外部分区表sql准备
示例:创建外部表
CREATE EXTERNAL TABLE `repair_bi`(
`id` INT COMMENT 'id',
`product_order_id` STRING COMMENT '产品序列号',
`RMA_id` STRING COMMENT 'RMA单号',)
COMMENT 'This is the repair table'
partitioned by(`statis_date` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://nncluster/hivedata/repairdata/repair/'
2.创建工作流

3、将sql语句写入工作流中
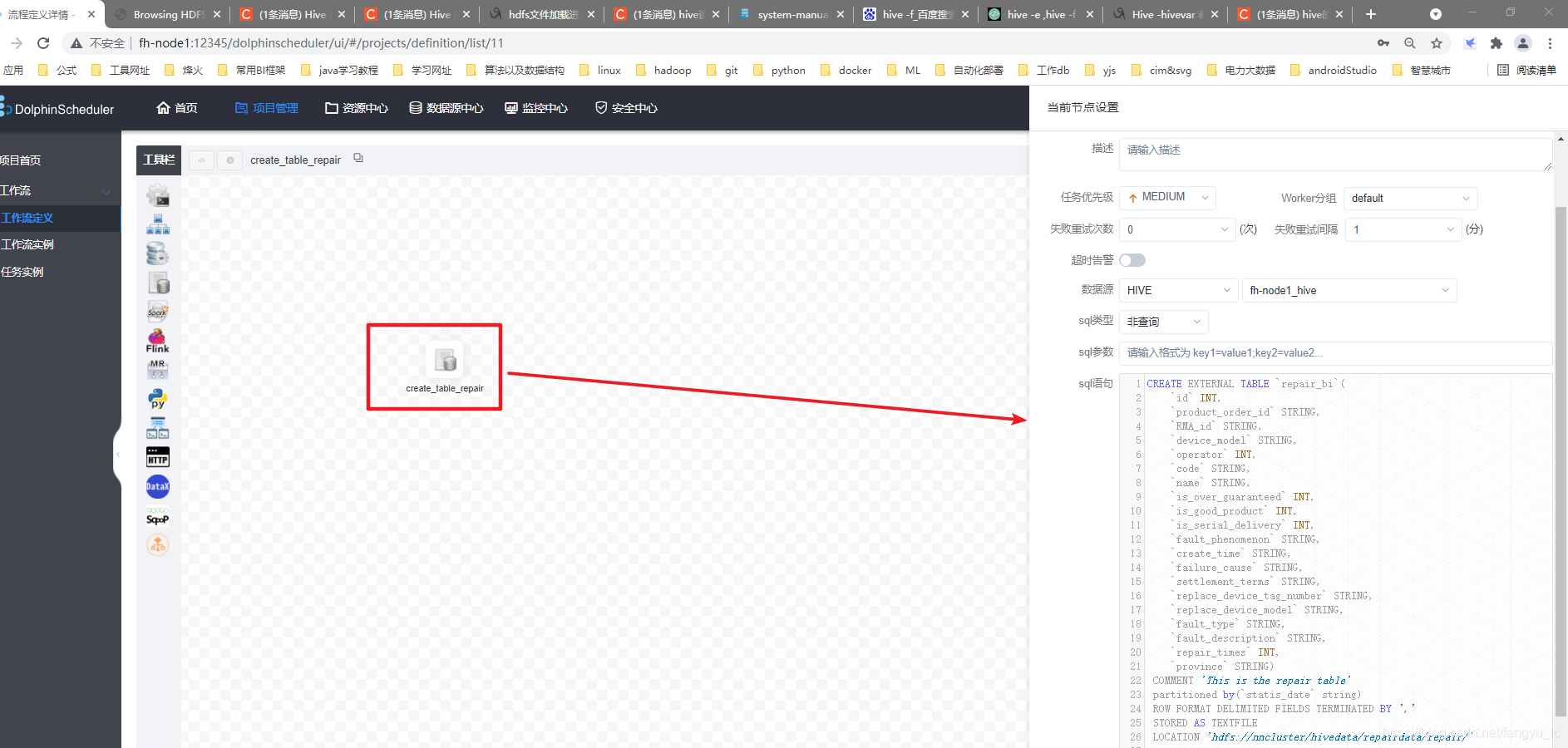
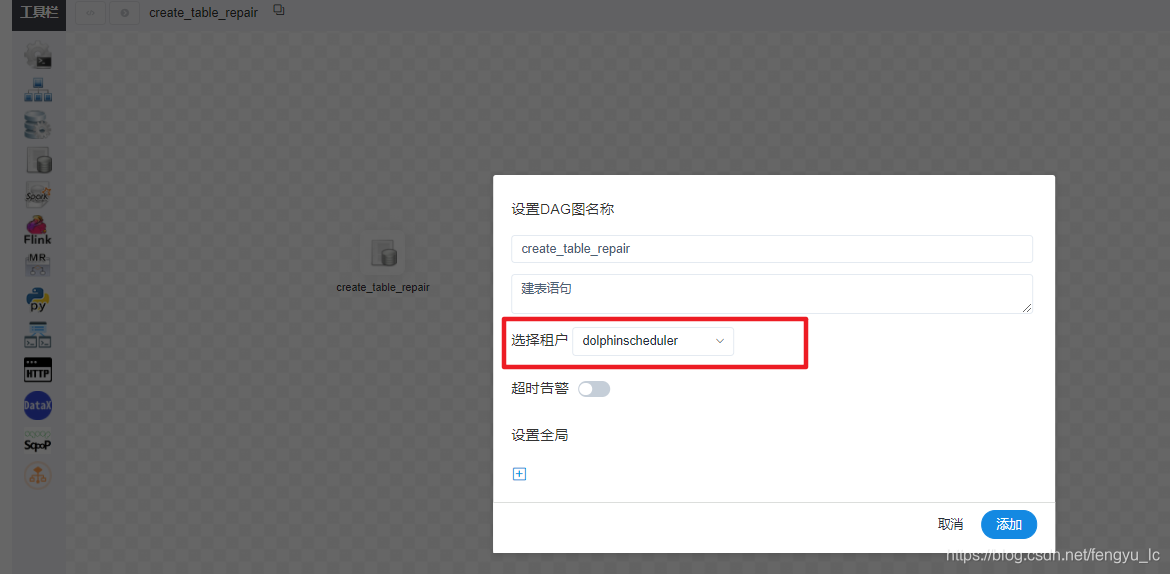
4、保存选择租户,上线运行

5、任务实例中查看运行状态,状态:成功 即创建成功,可以通过hive的beeline客户端执行如下命令查看表创建详情
show create table repair_bi;
二、hive分区表创建好后需要增加分区,使用shell命令创建分区
注:本次使用shell工作流的原因是,dolphinscheduler集成的sql组件中在定位分区文件位置时候路径会解析错误。(也可能是我自己的问题没有找到正确的使用方式,但是sql在beeline中执行确实没问题)
1、添加每天的定时增加分区任务
创建hql文件并将hql文件上传至资源中心
repair_hive.hql 内容:
alter table repair_bi
add partition(statis_date='${statis_date}')
location '/hivedata/repairdata/repair/${statis_date}';

2、配置shell命令,使用hivevar的方式提交参数
hive -hivevar statis_date='${statis_date}' -S -f
hdfs://nncluster/data/dolphinscheduler/dolphinscheduler/resources/sql/repair_partition.hql
3、配置参数:
1)增加自定义变量

2)点击保存 并增加系统变量
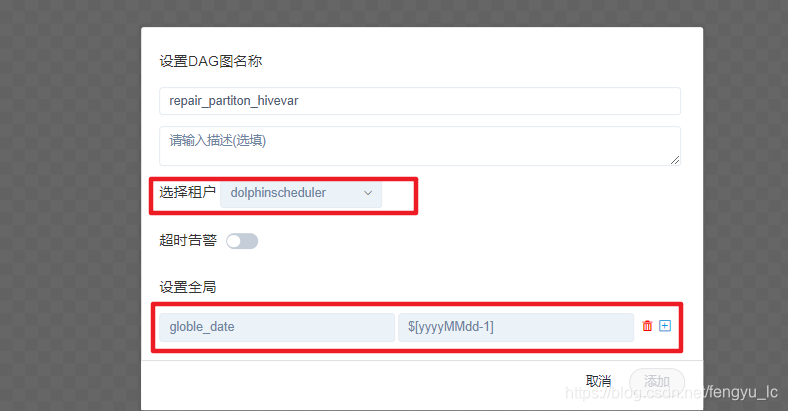
参数定义如下:
* 后 N 年:$[add_months(yyyyMMdd,12*N)]
* 前 N 年:$[add_months(yyyyMMdd,-12*N)]
* 后 N 月:$[add_months(yyyyMMdd,N)]
* 前 N 月:$[add_months(yyyyMMdd,-N)]
* 后 N 周:$[yyyyMMdd+7*N]
* 前 N 周:$[yyyyMMdd-7*N]
* 后 N 天:$[yyyyMMdd+N]
* 前 N 天:$[yyyyMMdd-N]
* 后 N 小时:$[HHmmss+N/24]
* 前 N 小时:$[HHmmss-N/24]
* 后 N 分钟:$[HHmmss+N/24/60]
* 前 N 分钟:$[HHmmss-N/24/60]
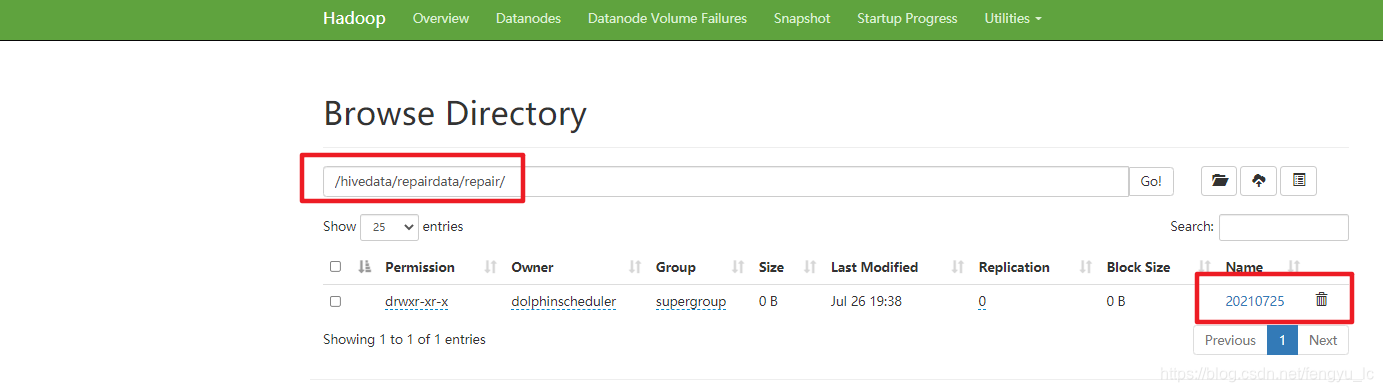
4、上线运行即可,如下即分区创建成功
三、datax同步增量数据只分区中
1、创建datax工作流

2、配置datax任务
例:
{
"job": {
"setting": {
"speed": {
"channel": 1,
"byte": 1048576
},
"errorLimit": {
"record": 1000000,
"percentage": 0.3
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "###",
"password": "###",
"splitPk": "",
"connection": [
{
"querySql": [
"select coalesce(id,0) as id,coalesce(deviceserialnumber,'') as product_order_id,coalesce(rma,'') as RMA_id from v_rep_device_for_bi WHERE createtime = date_add(curdate(),interval'-1' DAY)"
],
"jdbcUrl": [
"jdbc:mysql://10.16.3.81:3306/smartHN"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id","type":"INT"},
{"name":"product_order_id","type":"string"},
{"name":"RMA_id","type":"string"}
],
"compress": "gzip",
"defaultFS": "hdfs://node1:8020",
"fieldDelimiter": ",",
"fileName": "repair",
"fileType": "text",
"path": "/hivedata/repairdata/repair/${statis_date}",
"writeMode": "append"
}
}
}
]
}
}
3、保存,配置参数
4、上线 执行

5、数据查看
1)、文件中查看

2)sql查询(使用beeline客户端或者在dolphinshceduler中配置测试任务流查询)
四、创建定时任务
依赖关系为:分区表创建后即可形成分区目录,然后再执行datax数据集成任务
1、创建分区表定时任务
工作流定义中增加定时,编辑,定时设置为每天00:05执行增加昨天分区数据
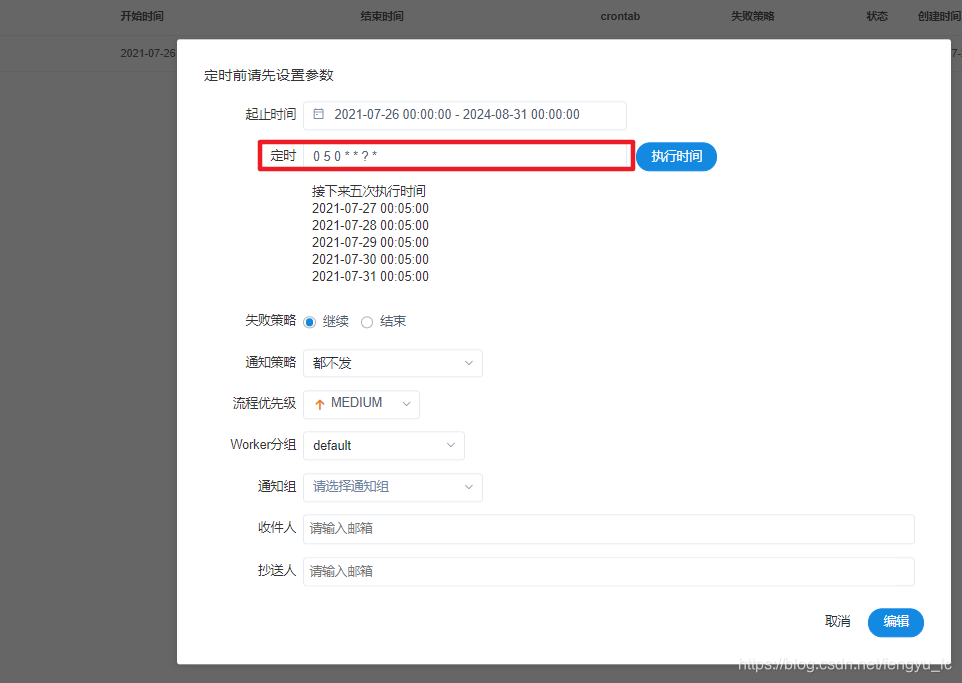

2、点击上图中右侧中间上线 即可上线分区定时任务
3、创建datax定时任务
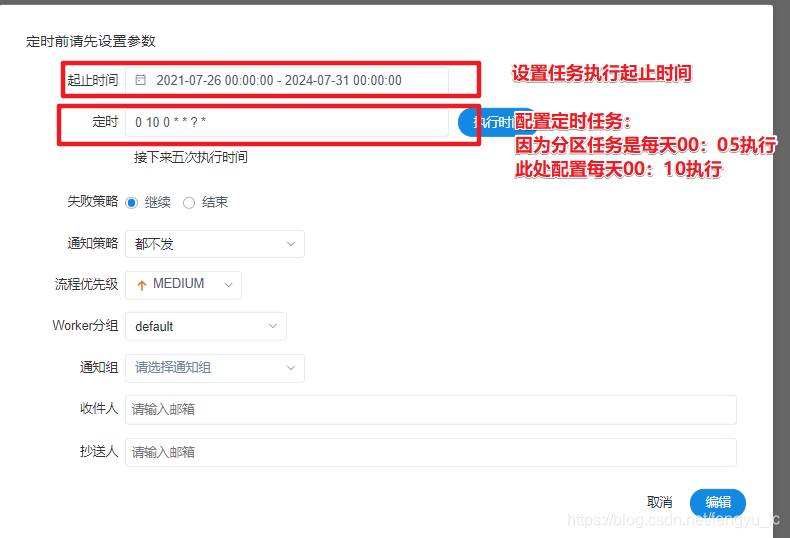
4、上线datax数据集成任务

总结
总体而言还是比较方便的实现增量数据的调度任务