前言
大家好,已经连续写了几篇elasticsearch相关的博文,今天给大家换个口味,写写大数据中数据处理以及数据查询的两大高性能利器。这篇文章我已经酝酿了好久,但是由于底层涉及到的知识点已经包含CPU的结构以及工作机制,所以用了很长时间去理解这里面的知识和逻辑,研究的越深感觉自己需要学的东西越多,痛并快乐着,终于啃下了这块硬骨头,于是总结下干货和大家分享分享。
顺便友情提示:文章末尾有福利,文章末尾有福利,文章末尾有福利!!!
正文
题外话说多了,回归正题,再说这两种高性能利器之前,先说说这两利器出现之前数据库查询和处理数据使用的是什么呢?为了方便大家理解,我把数据库查询以及处理数据的发展历程和枪械发展历程结合起来,方便大家理解。
Volcano Iterator Model - 满配的98K
下面先来说说Volcano Iterator Model(火山迭代模型)到底是什么。在这种模型中,一个查询会包含多个operator,每个operator都会实现一个接口,提供一个next()方法,该方法返回operator tree中的下一个operator。
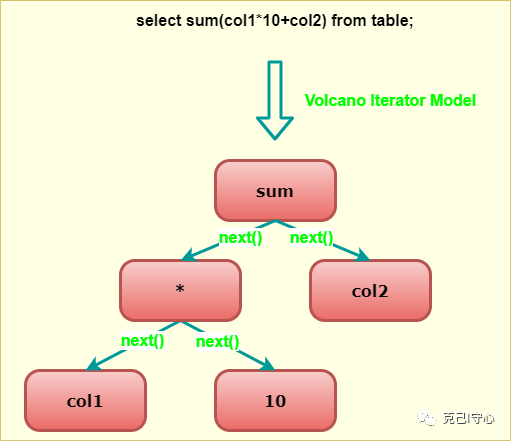
这种模型的好处就是让每一个operator都实现一个iterator接口,可以让查询引擎优雅的组装任意operator在一起。而不需要查询引擎去考虑每个operator具体的一些处理逻辑,比如数据类型、数据处理方式等。
正因为这个优点,Vocano Iterator Model也因此成为了数据库SQL执行引擎领域内20年中最流行的一种标准,RDBMS中的三座大山Oracle,SQL Server, MySQL都采用了这种模型,那这种模型的权威性就不言而喻了。所以用满配的98K来形容这种模型也名副其实,毕竟98K是栓动步枪的巅峰存在。
但是长江后浪推前浪,前浪死在沙滩上。Vocano Iterator Model在处理小规模数据的RDBMS中是神一样的存在,但是在大数据时代,Vocano Iterator Model的优势变得不明显,劣势却被无限放大,被时代无情的暴击了。那么火山迭代模型有什么劣势呢?
适配神器next()方法优势不再
在Vocano Iterator Model中,next()方法将整个数据处理链条串联起来,使得整个模型在不需要了解实现细节的前提下提供了很好的适配性。
但是这个操作是有代价的,每次next()方法调用在操作系统层面,会被编译为virtual function dispatch(虚函数派发),虽然现在的编译器在经过无数轮优化后,已经将此过程的消耗降到了很低的水平,但是还是需要调用好几个指令。这个在数据量小的时候可以忽略不计,但是在大数据的场景下,这个开销就显得高得离谱且不可接受了。
这就好比98K虽然是把极品步枪,狙击个把敌人不在话下,但是面对人海进攻的敌人还是力不从心,毕竟你再怎么快也需要拉枪栓吧。
中间数据放在内存中存取效率低下
excuse me?中间数据在内存中存取效率低下,开玩笑的吧?大数据组件绞尽脑汁要将数据加载到内存中加速查询以及处理,你在这里和我说内存存取效率低下,这不胡说八道吗?
别急,还真没胡说八道,大数据组件中将数据放到内存中加速查询和处理是事实,也是正确的选择。但是选择正确不代表没别的选择:内存的速度快是相对于磁盘的,而CPU上有一种存储组件的速度比内存快得多,那就是Register(寄存器)。所以对于CPU而言,寄存器是比内存更高效的存储介质,使用寄存器读写数据比内存高几个数量级。
说到这里又会有小伙伴发问了,既然寄存器这么快,为什么不都用寄存器而用内存呢?其实答案很简单,其实就一个字:"钱",感兴趣的小伙伴去网上比下价格就明白了,毕竟大数据处理处理需要更多的考虑性价比的问题。
在Volcano Iterator Model中,每次一个operator将数据交给下一个operator,都需要将数据写入内存缓冲中,无法利用CPU的寄存器这种性能更高的存储介质。
这就好比使用了桥夹装弹(内存)的98K,虽然发射速度比单发子弹填装快了许多,但是和弹夹以及弹鼓(CPU的三级缓存)相比却是小巫见大巫了,更不用说和弹链(寄存器)相比了。
Loop Unrolling(循环展开)和SIMD(单指令多数据流)
最后一点,现代的编译器和CPU在编译和执行?简单(此处划重点然后说三遍,简单简单简单)?的for循环时,性能非常地高。
编译器通常可以自动对for循环进行unrolling,并且还会生成SIMD指令以在每次CPU指令执行时处理多条数据。CPU也包含一些特性,比如?instructions pipeline(指令集流水线,让CPU满载运行,提高效率),cache prefetching(缓存预取,这也是CPU三级缓存存在的意义)?等,可以让for循环的执行性能更高。
然而这些优化特性都无法在复杂的函数调用场景中施展(对应上面的简单),比如Volcano Iterator Model。
上面提到的4种CPU以及编译器的优化方式每种都值得好好学习下,我也努力的理解了许久才算摸到点门路,大家感兴趣的可以去自学下,受限于篇幅以及本文的重点我就不在这里展开了,大家有需要的话可以后续再讨论。
这就好比98K再怎么优化也是一个枪管,子弹也得一颗一颗的发射,此时突然出现了多管的加特林,先不管射速光看枪管的数量就问你虚不虚?
利刃出鞘 - 两挺加特林面世

上面说到了Volcano Iterator Model的优缺点以及在面对大数据场景下的劣势,发现问题了,下一步就是解决问题了,在众多的解决方案中,有两个方案脱颖而出,就是今天的主角:Vectorization(向量化执行)和?Runtime Code Generation(运行时代码生成),下面就看看这双子星是如何破解Volcano Iterator Model的三个困局的?
Runtime Code Generation - 使用了弹链的正宗加特林
先来看看Runtime Code Generation是怎么破局的?
-
首先,Runtime Code Generation在运行时进行代码生成,可以将代码简化,将多个函数封装在一个方法内,减少虚函数的派发,增加了执行效率;另外还可以去掉多余的分支,大大减少了CPU分支预测相关的开销,进一步增加了效率。对于枪支来说,就等于增加了连发的功能,由步枪变成了机枪
-
其次,由于Runtime Code Generation后将多个函数封装在一起,所以在方法执行过程中多个函数之间的中间结果是可以缓存在寄存器中的,这对于CPU来说简直是再爽不过了,高效的数据存取使得运行效率稳稳的提升。对于枪支来说,在有连发功能以后,又增加了高效率的弹链,射击能力进一步加强了
-
最后,由于Runtime Code Generation在处理多条数据时使用了循环,所以很多功能简单的函数可以享受到Loop Unrolling(循环展开)的红利;另外由于简化了代码生成逻辑,消除了很多分支,所以Runtime Code Generation能更好地将多个操作融合在一起,从而可以充分利用 CPU 执行单元以及pipeline(流水线),代码可以在指令级别并行执行,充分利用了CPU的并发能力。对于枪支来说,就等于单枪管变成了多枪管
综上所述,在Runtime Code Generation的眼花缭乱的操作后,一挺使用了弹链的正宗加特林就诞生了,YYDS!!!
Vectorization - 使用了弹鼓的弱化版加特林
再来看看齐名的Vectorization是如何破局的?
-
首先,不同于Runtime Code Generation的代码调用级别减少虚函数的派发,Vectorization是针对一批数据来进行一次函数调用,即从数据调用级别减少虚函数的派发。这种处理方式很适合于列式存储的数据,如parquet和clickhouse等。对于枪支来说,Vectorization也解决了连发的问题,只是和Runtime Code Generation使用了不用的方式。
-
其次,针对于中间数据的存放,Vectorization的表现不如Runtime Code Generation,因为它涉及向CPU缓存读取和写入临时向量。如果L2缓存容纳不下临时数据,那么Vectorization将面临和Volcano Iterator Model同样的问题。对于枪支来说,在有连发功能以后,又增加了效率也不错的弹鼓,射击能力也加强了不少
-
最后,Vectorization由于在处理批量数据的时候使用到了循环,所以自然也会享受到Loop Unrolling(循环展开)的红利;另外由于Vectorization批量处理数据,所以更容易利用 CPU 的?SIMD 功能,代码可以在数据级别并行执行,同样充分利用了CPU的并发能力。对于枪支来说,也等于单枪管变成了多枪管
综上所述,在Vectorization的眼花缭乱的操作后,一挺使用了弹鼓的弱化版的加特林也诞生了。
虽然在某些地方做的不如Runtime Code Generation,但是在某些场景下,如处理列式数据存储或者在列式数据库中,其性能以及实现成本反而比Runtime Code Generation更好。
结语
上面说了两种性能优化利器的原理以及特点,接下来大家可能就要问这两个利器到底是怎么使用的,只能二选一还是能合二为一呢?下面就讲述下spark以及clickhouse的两种实现方案来说明下到底该怎么使用这两者:
spark
spark作为当前主流的大数据处理框架,其使用方式具有一定的代表性,归纳而言就是尽量使用Runtime Code Generation,对于无法使用Runtime Code Generation的实现,则使用Vectorization来处理。即主Runtime Code Generation,辅Vectorization。
Whole-Stage Code Generation
这是spark中Runtime Code Generation的实现。从Spark2开始,Spark第二代Tungsten引擎引入的新技术:whole-stage code generation。
通过该技术,SQL语句编译后的operator-tree中,每个operator执行时就不是自己来执行逻辑了,而是通过whole-stage code generation技术,动态生成代码。
如果只是一个简单的查询,那么Spark会尽可能就生成一个stage,并且将所有操作打包到一起。但是如果是复杂的操作,就可能会生成多个stage。
Vectorization
对于很多简单的数据查询或者处理操作,whole-stage code generation技术都可以很好地优化其性能。但是有一些特殊的复杂操作,却无法很好的使用该技术,此时就会使用到Vectorization技术,如parquet文件扫描、csv文件解析等,或者是跟其他第三方技术进行整合。
clickhouse
clickhouse作为标准的列式存储数据库,在数据库层面具有一定的代表性。由于clickhouse是列式数据库。天生很容易支持Vectorization处理。所以clickhouse的原则就是主要使用Vectorization,同时初步提供了有限的Runtime Code Generation。即主Vectorization,辅Runtime Code Generation。
Vectorization
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
Runtime Code Generation
ClickHouse实现了Expression级别的runtime codegen,动态地根据当前SQL直接生成代码,然后编译执行。这个和Spark1.X时候的处理方式是一致的
从上面的使用方式来看,当前的组件基本上都是双子星联袂配合演出,各自发挥优势,一个主导,一个辅助,相辅相成。相信这也会是未来一段时间内的通用使用方式。有了这双子星的加成,未来大数据的执行效率会越来越高。
花絮
最后今天打破惯例,直接来揭秘封面图片的答案吧:
玩过魔兽世界的兄弟姐妹们肯定知道这把剑:萨拉迈尼之剑,这把武器原来是两把:沙拉托尔(shalla‘tor暗影撕裂者)和埃雷梅尼(ellamayne暗影掠夺者)由上古之战时期一对双胞胎战士手中的剑。由吉安娜赠予瓦里安,并在瓦里安击杀奥妮克希亚时,机缘巧合合二为一。此后,瓦里安可以自由地将萨拉迈尼在一把双手大剑和两把单手剑之间转换。瓦王也就可以在武器战和狂暴战之间自由切换,无往不利。
这正如高性能的双子星一样,组合和配合的方式很多,但是不论如何组合,都会在大数据查询与处理的场景下熠熠生辉,成为大数据高性能处理的左膀右臂!
最最后,笔者长期关注大数据通用技术,通用原理以及NOSQL数据库的技术架构以及使用。如果大家感觉笔者写的还不错,麻烦大家多多点赞和分享转发,也许你的朋友也喜欢。
最后挂个公众号二维码,欢迎大家关注。

福利
这次真的是最后了,感谢大家长久以来的支持,结合本文的内容发点福利吧,分享一波spark最新版的学习资料:
需要的小伙伴们在公众号里回复:spark,我会在看到消息的第一时间内分享给大家,最后再次感谢各位兄弟姐妹们!!!