大数据概述
1. 大数据的4V特征
什么是大数据?这个问题对于不同的行业来说答案有可能不同,其就如盲人摸象一般,不同的人所接触不同行业对于大数据的理解都不一样,大数据的特征还存在一定的争议,但按照普遍被接受的有4个特征:
- 数据量(Volume)
- 速度(Velocity)
- 多样性,复杂性(Variety)
- 基于高度分析的新价值(Value)
这四个特征称之为大数据的4V特征。
2. 大数据带来的技术变革
技术驱动
-
存储方式:
文件存储 => 分布式存储
大数据有数据量大的特点,对应的我们的存储方式会从文件存储变为分布式存储。分布式存储的方式可以将大的文件拆分成若干个block(块),不同的块存放到不同的地方。为了提高可靠性,相对应的我们还需要保存每个块的副本,一旦某些块的服务挂了这些副本还会继续提供服务。 -
计算方式:
单机节点计算 => 分布式计算
存储方式变化对应的我们计算方式也需要从原本的单机方式变为分布式计算。将一个计算作业拆分到若干个服务进行分布式计算,最后将结果进行聚合。 -
数据库:
RDBMS => NoSQL
传统的应用和服务基本上是基于关系型数据库来存放数据的,对于大数据来说存储可以存放到NoSQL中 -
网络:
跨节点的传输数据比较依赖于网络,所以这里网络建议使用万兆的网络。
商业驱动
??大数据实际归根结底是服务与我们所在行业的业务中的。对于商业来说,我们需要从大数据中分析出其所带来的价值,在商业驱动下,大数据需要结合我们公司的实际业务创造出其实际的价值。
3. 大数据现存的模式
- 手握大数据、没有大数据思维
- 没有大数据、有大数据思维
- 既有大数据、又有大数据思维
??我们现有的大数据现存模式主要有以上3种,有的公司手里掌握大数据但是没有大数据思维,这种公司可以依托外部公司来让手里的数据发挥价值。有的公司有大数据思维,他们掌握大数据相关技术但是手里没有大数据,这种公司和第一种是相辅相成的他们可以服务于有大数据的公司对其提供技术支撑。还有的公司既有大数据又有大数据思维,典型的就是我们现在众所周知的哪些互联网大厂。
4. 大数据的技术概念
??我们以货船运输货物为例,假如有一条河和一艘货船,我们需要把一批货物从河的一岸发送的另一岸。当货物较少的时候这艘船可以一次性运输完成,如果此时货物增加,现有的货船已不足以一次运完所有的货物,如果想要快速运完货物,其中一种方法就是加大船体容积。相对应的,对于数据处理来说也是如此。当处理大量数据的时候,现有的机器不能短时间处理完成,我们可以采取提升机器的性能(加磁盘、升级CPU、内存等升级机器硬件的操作)来加速我们对于数据的处理。但是对于机器其实并不可以无限的升级其硬件,就好像船体容积不能无限的扩大一样。这个时候我们就可以采用第二种方式――并行运输。我们可以采用多个原先一样大的小船,大家一起同时运输货物,这就是并行运行处理数据。
??在船的运输过程中,我们首先是将货物搬到船上之后才是货物的运输,这个过程就好比对数据的采集、存储和处理。
对比上面的例子我们对大数据的技术进行衍生,就有以下四点:
- 数据的采集
- 数据处理/分析/挖掘
- 数据存储
- 数据可视化
大数据在技术架构上带来的挑战
- 对现有数据库管理技术的挑战
- 经典数据库技术并没有考虑数据的多类别
- 实时性的技术挑战
- 网络架构、数据中心、运维的挑战
- 数据隐私
- 数据源复杂多样
如何对大数据进行存储和分析
对应系统的瓶颈有:存储容量、读写速度、计算效率等等。
Google对大数据提出了一些技术:
-
MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。 -
BigTable
Bigtable分布式数据存储系统是Google为其内部海量的结构化数据开发的云存储技术,是Google的第三项云计算关键技术,是所有云时代分布式存储系统的开发蓝本,已经在超过60个Google的产品和项目上得到了应用。
Bigtable的设计是为了能可靠地处理PB级的海量数据,使其能够部署在千台机器上 。Bigtable具有高可靠性、高性能、可伸缩等特性,借鉴了并行数据库和内存数据库的一些特性,但Bigtable提供了一个完全不同接口。Bigtable不支持完整的关系数据模型,而是为用户提供了简单的数据模型,使客户可以动态控制数据的分布和格式。 -
GFS
GFS 也就是 Google File System,Google公司为了存储海量搜索数据而设计的专用文件系统。GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务。
谷歌的这3项技术奠定了后续大数据处理的一个基础,但是Google只发表了技术论文,并没有开放源代码,一个模仿Google大数据技术的开源实现来了――Hadoop!
大数据的典型应用
下图列出了一些应用场景,从上到下复杂程度递增

还可以应用以下场景,从上到下时效性越来越高

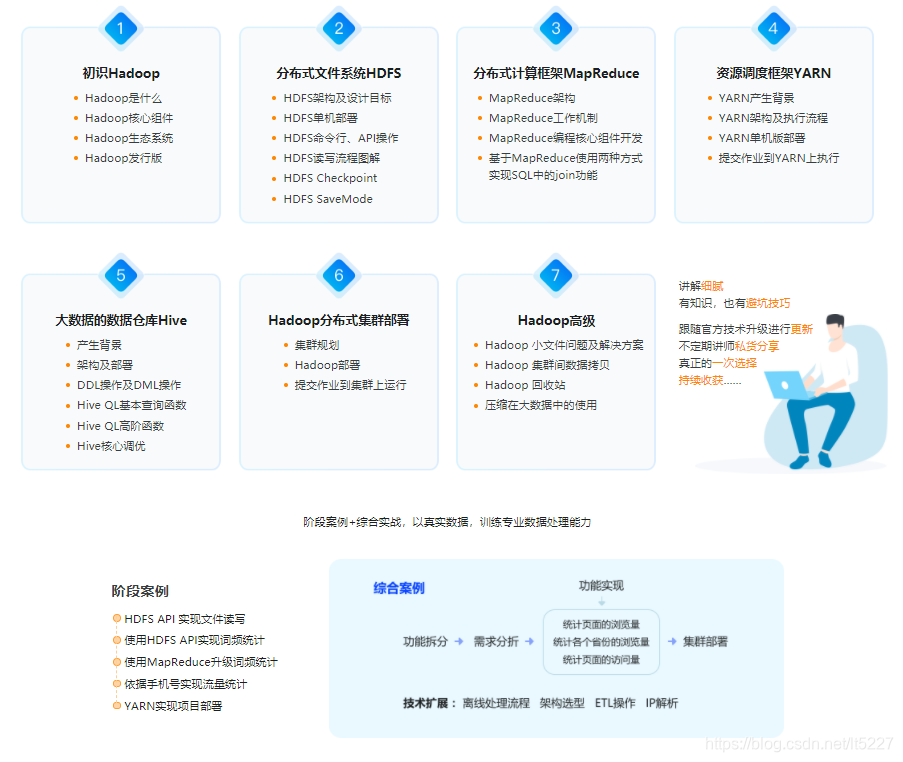
Hadoop学习课程推荐:
课程链接