ǰ��
һ��Zookeeper ����
1��Zookeeper ����
zookeeper��һ����Դ�ķֲ�ʽ��,Ϊ�ֲ�ʽ����ṩЭ�������Apache��Ŀ
2��Zookeeper ��������
Zookeeper�����ģʽ�Ƕ�������:�ǨC�����ڹ۲���ģʽ��Ƶķֲ�ʽ����������,������洢������Ҷ����ĵ�����,Ȼ����ܹ۲��ߵ�ע��,һ����Щ���ݵ�״̬�����仯,Zookeeper�ͽ�����֪ͨ�Ѿ���Zookeeper��ע�����Щ�۲���������Ӧ�ķ�Ӧ��Ҳ����˵Zookeeper =�ļ�ϵͳ+֪ͨ����
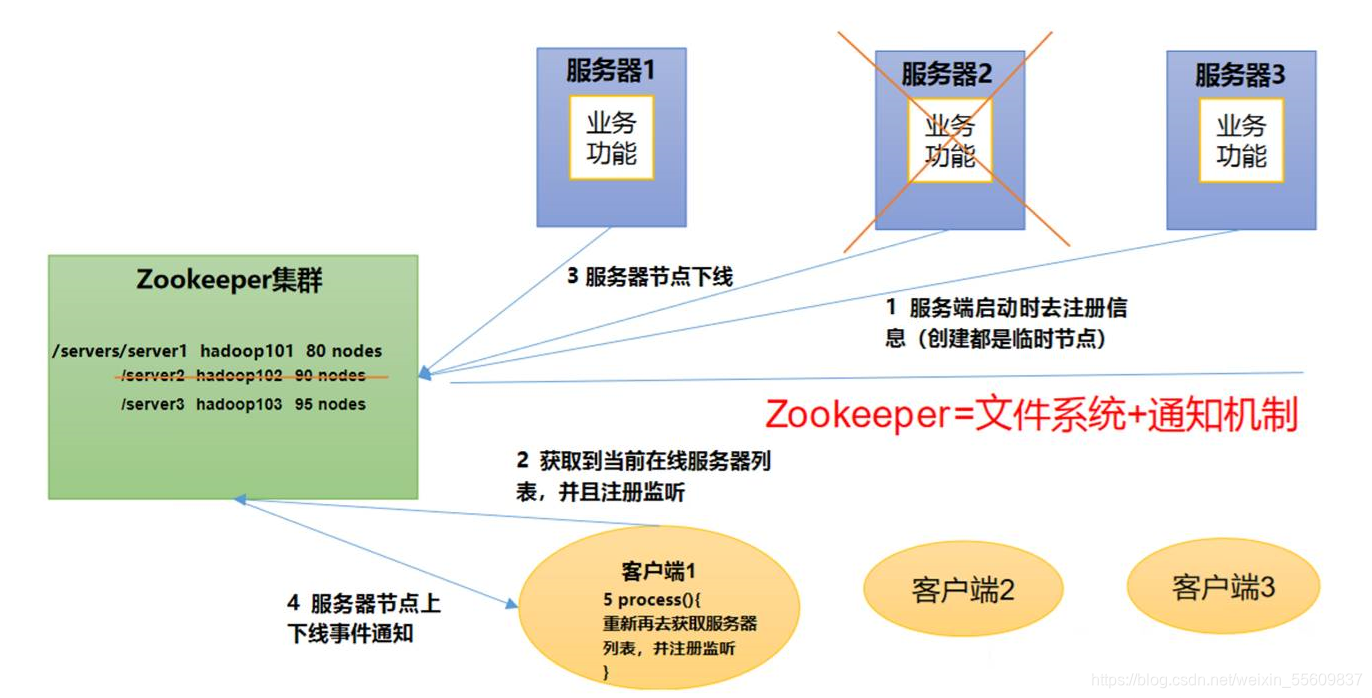
3��Zookeeper �ص�
- Zookeeper: һ���쵼��(Leader) ,���������(Follower) ��ɵļ�Ⱥ
- Zookeepe��Ⱥ��ֻҪ�а������Ͻڵ���,Zookeeper��Ⱥ����������������Zookeeper�ʺϰ�װ����̨������
- ȫ������һ��:ÿ��Server����һ����ͬ�����ݸ���,Client�������ӵ��ĸ�Server,���ݶ���һ�µ�
- ��������˳��ִ��,����ͬһ��Client�ĸ��������䷢��˳������ִ��,���Ƚ��ȳ�
- ���ݸ���ԭ����,һ �����ݸ���Ҫô�ɹ�,Ҫôʧ��
- ʵʱ��,��һ��ʱ�䷶Χ��,Client�ܶ�����������
4��Zookeeper ���ݽṹ
ZooKeeper����ģ�͵Ľṹ��Linux�ļ�ϵͳ������,�����Ͽ��Կ�����һ����,ÿ���ڵ����һ��ZNode��ÿ.һ�� ZNodeĬ�� �ܹ��洢1MB������,ÿ��ZNode������ͨ����·��Ψһ��ʶ
- ͳһ��������
�ڷֲ�ʽ������,������Ҫ��Ӧ��/�������ͳһ����,����ʶ������: IP������ס,����������ס
5��Zookeeper Ӧ�ó���
�ṩ�ķ������: ͳһ�� ������ͳһ���ù����� ͳһ��Ⱥ�������������ڵ㶯̬�����ߡ������ؾ����
- ͳһ��������
�ڷֲ�ʽ������,������Ҫ��Ӧ��/�������ͳһ����,����ʶ������: IP������ס,����������ס - ͳһ���ù���
- �ֲ�ʽ������,�����ļ�ͬ���dz�������һ��Ҫ��һ����Ⱥ��,���нڵ��������Ϣ�ǨC�µ�,����Kafka��Ⱥ���������ļ��ĺ�,ϣ���ܹ�����ͬ���������ڵ���
- ZooKeeper����ʵ��ʵʱ��ؽڵ�״̬�仯���ɽ��ڵ���Ϣд��ZooKeeper.�ϵ�һ��ZNode���������ZNode�ɻ�ȡ����ʵʱ״̬�仯
- ��������̬������
�ͻ�����ʵʱ���쵽�����������ߵı仯 - �����ؾ���
��Zookeeper�м�¼ÿ̨�������ķ�����,�÷��������ٵķ�����ȥ�������µĿͻ�������
6��Zookeeper ѡ�ٻ���
��һ������ѡ�ٻ���
�� ������1����,����һ��ѡ�١�������1Ͷ�Լ�һƱ����ʱ������1Ʊ��һƱ, ������������(3Ʊ),ѡ�������,������1״̬����ΪLOOKING;
�� ������2����,�ٷ���һ��ѡ�١�������1��2�ֱ�Ͷ�Լ�һƱ������ѡƱ��Ϣ:��ʱ������1���ַ�����2��myid���Լ�ĿǰͶƱ�ƾٵ�( ������1)��,����ѡƱΪ�ƾٷ�����2����ʱ������1Ʊ��0Ʊ,������2Ʊ��2Ʊ,û�а������Ͻ��,ѡ�������,������1,2״̬����L00KING
�� ������3����,����һ��ѡ�١���ʱ������1��2�������ѡƱΪ������3���˴�ͶƱ���:������1Ϊ0Ʊ,������2Ϊ0Ʊ,������3Ϊ3Ʊ����ʱ������3��Ʊ���Ѿ���������,������3��ѡLeader��������1,2����״̬ΪFOLLOWING,������3����״̬ΪLEADING; .
�� ������4����,����һ��ѡ�١���ʱ������1,2,3�Ѿ�����L00KING״̬,�������ѡƱ��Ϣ������ѡƱ��Ϣ���:������3Ϊ3Ʊ,������4Ϊ1Ʊ����ʱ������4���Ӷ���,����ѡƱ��ϢΪ������3,������״̬ΪFOLLOWING;
�� ������5����,ͬ4һ����С�ܡ�
�ǵ�һ������ѡ�ٻ���
�� ��ZooKeeper��Ⱥ�е�һ̨���������������������֮һʱ,�ͻῪʼ����Leaderѡ��:
1)��������ʼ��������
2)�����������ڼ�����Leader�������ӡ�
�� ����һ̨��������Leaderѡ������ʱ,��ǰ��ȺҲ���ܻᴦ����������״̬:
1)��Ⱥ�б������Ѿ�����һ��Leader.
�����Ѿ�����Leader�����,������ͼȥѡ��Leaderʱ,�ᱻ��֪��ǰ��������Leader��Ϣ,���ڸû�����˵,������Ҫ��Leader������������,������״̬ͬ������
2)��Ⱥ��ȷʵ������Leader.
����ZooKeeper��5̨���������,SID�ֱ�Ϊ1��2��3��4��5,ZXID�ֱ�Ϊ8��8�� 8��7��7,���Ҵ�ʱSIDΪ3�ķ�������Leader��ijһʱ��,3��5���������ֹ���,��˿�ʼ����Leaderѡ��
ѡ��Leader����:
1.EPOCH���ֱ��ʤ��
2.EPOCH��ͬ,����id���ʤ��
3.����id��ͬ,������id���ʤ��
SID:������ID,����Ψһ��ʶһ̨ZooKeeper��Ⱥ�еĻ���,ÿ̨���������ظ�,��myidһ��
ZXID:����ID,ZXID��һ������ID,������ʶһ�η�����״̬�ı������ijһʱ��,��Ⱥ�е�ÿ̨������8XIDֵ��һ����ȫһ��,���ZooKeeper���������ڿͻ���"�������Ĵ������ٶ��йء�
Epoch:ÿ��Leader���ڵĴ���,û��Leaderʱͬһ��ͶƱ�����е���ʱ��ֵ����ͬ�ġ�ÿͶ��һ��Ʊ������ݾͻ�����
����Kafka ����
1.Ϊʲô��Ҫ��Ϣ�ж�(MQ)
��Ҫԭ���������ڸ߲���������,ͬ����������������,���������ᷢ����������������������������ݿ�,������������,��������̻߳�ѻ�����,�Ӷ����� too many connection ����,����ѩ��ЧӦ��
����ʹ����Ϣ����,ͨ���첽��������,�Ӷ�����ϵͳ��ѹ������Ϣ���г�Ӧ�����첽����,��������,Ӧ�ý���,��ϢͨѶ�ȳ�����
��ǰ�Ƚϳ����� MQ �м���� ActiveMQ��RabbitMQ��RocketMQ��Kafka ��
2.ʹ����Ϣ���еĺô�
�� ����
�������������չ�������ߵĴ�������,ֻҪȷ����������ͬ���Ľӿ�Լ����
�� �ɻָ���
ϵͳ��һ�������ʧЧʱ,����Ӱ�쵽����ϵͳ����Ϣ���н����˽��̼����϶�,���Լ�ʹһ��������Ϣ�Ľ��̹ҵ�,��������е���Ϣ��Ȼ������ϵͳ�ָ�������
�� ����
�����ڿ��ƺ��Ż�����������ϵͳ���ٶ�,���������Ϣ��������Ϣ�Ĵ����ٶȲ�һ�µ������
�� ����� & ��ֵ��������
�ڷ����������������,Ӧ����Ȼ��Ҫ������������,����������ͻ�������������������Ϊ���ܴ��������ֵ����Ϊ����Ͷ����Դ��ʱ���������Ǿ���˷ѡ�ʹ����Ϣ�����ܹ�ʹ�ؼ������סͻ���ķ���ѹ��,��������Ϊͻ���ij����ɵ��������ȫ������
�� �첽ͨ��
�ܶ�ʱ��,�û�����Ҳ����Ҫ����������Ϣ����Ϣ�����ṩ���첽��������,�����û���һ����Ϣ�������,��������������������������з��������Ϣ�ͷŶ���,Ȼ������Ҫ��ʱ����ȥ�������ǡ�
3.��Ϣ���е�����ģʽ
�� ��Ե�ģʽ(һ��һ,������������ȡ����,��Ϣ�յ�����Ϣ���)
��Ϣ������������Ϣ���͵���Ϣ������,Ȼ����Ϣ�����ߴ���Ϣ������ȡ������������Ϣ����Ϣ�������Ժ�,��Ϣ�����в����д洢,������Ϣ�����߲��������ѵ��Ѿ������ѵ���Ϣ����Ϣ����֧�ִ��ڶ��������,���Ƕ�һ����Ϣ����,ֻ����һ�������߿�������
�� ����/����ģʽ(һ�Զ�,�ֽй۲���ģʽ,��������������֮�������Ϣ)
��Ϣ������(����)����Ϣ������ topic ��,ͬʱ�ж����Ϣ������(����)���Ѹ���Ϣ���͵�Ե㷽ʽ��ͬ,������ topic ����Ϣ�ᱻ���ж��������ѡ�
����/����ģʽ�Ƕ�������һ��һ�Զ��������ϵ,ʹ��ÿ��һ������(Ŀ�����)��״̬�����ı�,���������������Ķ���(�۲��߶���)����õ�֪ͨ���Զ�����
4.Kafka ����
Kafka ��һ���ֲ�ʽ�Ļ��ڷ���/����ģʽ����Ϣ����(MQ,Message Queue),��ҪӦ���ڴ�����ʵʱ��������
5.Kafka ���
Kafka ������� Linkedin ��˾����,��һ���ֲ�ʽ��֧�ַ�����(partition)���ั����(replica),���� Zookeeper Э���ķֲ�ʽ��Ϣ�м��ϵͳ,�����������Ծ��ǿ���ʵʱ�Ĵ������������������������,������� hadoop ��������ϵͳ�����ӳٵ�ʵʱϵͳ��Spark/Flink ��ʽ��������,nginx ������־,��Ϣ����ȵ�,�� scala ���Ա�д,
Linkedin �� 2010 �깱���� Apache ����Ტ��Ϊ������Դ��Ŀ
6.Kafka ������
�� �������������ӳ�
Kafka ÿ����Դ�����ʮ������Ϣ,�����ӳ����ֻ�м����롣ÿ�� topic ���Էֶ�� Partition,Consumer Group �� Partition �������Ѳ���,��߸��ؾ�������������������
�� ����չ��
kafka ��Ⱥ֧������չ
�� �־��ԡ��ɿ���
��Ϣ���־û������ش���,����֧�����ݱ��ݷ�ֹ���ݶ�ʧ
�� �ݴ���
������Ⱥ�нڵ�ʧ��(�ั�������,����������Ϊ n,������ n-1 ���ڵ�ʧ��)
�� �߲���
֧����ǧ���ͻ���ͬʱ��д
7.Kafka ϵͳ�ܹ�
�� Broker
һ̨ kafka ����������һ�� broker��һ����Ⱥ�ɶ�� broker ��ɡ�һ�� broker �������ɶ�� topic��
�� Topic
��������Ϊһ������,�����ߺ�����������Ķ���һ�� topic��
���������ݿ�ı������� ES �� index
�����ϲ�ͬ topic ����Ϣ�ֿ��洢
�� Partition
Ϊ��ʵ����չ��,һ���dz���� topic ���Էֲ������ broker(��������)��,һ�� topic ���Էָ�Ϊһ������ partition,ÿ�� partition ��һ������Ķ��С�Kafka ֻ��֤ partition �ڵļ�¼�������,������֤ topic �в�ͬ partition ��˳��
ÿ�� topic ������һ�� partition,�������߲������ݵ�ʱ��,����ݷ������ѡ�����,Ȼ����Ϣ�ӵ�ָ���ķ����Ķ���ĩβ��
Partation ����·�ɹ���:
1.ָ���� patition,��ֱ��ʹ��;
2.δָ�� patition ��ָ�� key(�൱����Ϣ��ij������),ͨ���� key �� value ���� hash ȡģ,ѡ��һ�� patition;
3.patition �� key ��δָ��,ʹ����ѯѡ��һ�� patition��
ÿ����Ϣ������һ�������ı��,���ڱ�ʶ��Ϣ��ƫ����,��ʶ˳��� 0 ��ʼ��
ÿ�� partition �е�����ʹ�ö�� segment �ļ��洢��
��� topic �ж�� partition,��������ʱ�Ͳ��ܱ�֤���ݵ�˳���ϸ�֤��Ϣ������˳��ij�����(������Ʒ��ɱ�� �����),��Ҫ�� partition ��Ŀ��Ϊ 1��
�� broker �洢 topic �����ݡ����ij topic �� N �� partition,��Ⱥ�� N �� broker,��ôÿ�� broker �洢�� topic ��һ�� partition��
�� ���ij topic �� N �� partition,��Ⱥ�� (N+M) �� broker,��ô������ N �� broker �洢 topic ��һ�� partition, ʣ�µ� M �� broker ���洢�� topic �� partition ���ݡ�
�� ���ij topic �� N �� partition,��Ⱥ�� broker ��Ŀ���� N ��,��ôһ�� broker �洢�� topic ��һ������ partition����ʵ������������,����������������ķ���,������������� Kafka ��Ⱥ���ݲ����⡣
������ԭ��
�� �����ڼ�Ⱥ����չ,ÿ��Partition����ͨ����������Ӧ�����ڵĻ���,��һ��topic�ֿ����ж��Partition���,���������Ⱥ�Ϳ�����Ӧ�����С��������;
�� ������߲���,��Ϊ������PartitionΪ��λ��д�ˡ�
�� Leader
ÿ�� partition �ж������,�������ҽ���һ����Ϊ Leader,Leader �ǵ�ǰ�������ݵĶ�д�� partition��
�� Follower
Follower ���� Leader,����д����ͨ�� Leader ·��,���ݱ����㲥������ Follower,Follower �� Leader ��������ͬ����Follower ֻ���𱸷�,���������ݵĶ�д��
��� Leader ����,��� Follower ��ѡ�ٳ�һ���µ� Leader��
�� Follower �ҵ�����ס����ͬ��̫��,Leader ������ Follower �� ISR(Leader ά����һ���� Leader ����ͬ���� Follower ����) �б���ɾ��,���´���һ�� Follower��
�� Replica
����,Ϊ��֤��Ⱥ�е�ij���ڵ㷢������ʱ,�ýڵ��ϵ� partition ���ݲ���ʧ,�� kafka ��Ȼ�ܹ���������,kafka �ṩ�˸�������,һ�� topic ��ÿ�������������ɸ�����,һ�� leader �����ɸ� follower��
�� Producer
���������ݵķ�����,�ý�ɫ����Ϣ������ Kafka �� topic �С�
broker ���յ������߷��͵���Ϣ��,broker ������Ϣ�ӵ���ǰ���������ݵ� segment �ļ��С�
�����߷��͵���Ϣ,�洢��һ�� partition ��,������Ҳ����ָ�����ݴ洢�� partition��
�� Consumer
�����߿��Դ� broker �ж�ȡ���ݡ������߿������Ѷ�� topic �е����ݡ�
�� Consumer Group(CG)
��������,�ɶ�� consumer ��ɡ�
���е������߶�����ij����������,���������������ϵ�һ�������ߡ���Ϊÿ��������ָ������,����ָ������������Ĭ�ϵ��顣
������������е�һ��ȥ����ijһ�� Topic ������,���Ը����������ݵ�����������
����������ÿ�������߸������Ѳ�ͬ����������,һ������ֻ����һ����������������,��ֹ���ݱ��ظ���ȡ��
��������֮�以��Ӱ�졣
�� offset ƫ����
����Ψһ�ı�ʶһ����Ϣ��
ƫ����������ȡ���ݵ�λ��,�������̰߳�ȫ������,������ͨ��ƫ�����������´ζ�ȡ����Ϣ(������λ��)��
��Ϣ������֮��,����������ɾ��,�������ҵ��Ϳ����ظ�ʹ�� Kafka ����Ϣ��
ijһ��ҵ��Ҳ����ͨ����ƫ�����ﵽ���¶�ȡ��Ϣ��Ŀ��,ƫ�������û����ơ�
��Ϣ���ջ��ǻᱻɾ����,Ĭ����������Ϊ 1 ��(7*24Сʱ)��
? Zookeeper
Kafka ͨ�� Zookeeper ���洢��Ⱥ�� meta ��Ϣ��
���� consumer �����ѹ����п��ܻ���ֶϵ�崻��ȹ���,consumer �ָ���,��Ҫ�ӹ���ǰ��λ�õļ�������,���� consumer ��Ҫʵʱ��¼�Լ����ѵ����ĸ� offset,�Ա���ϻָ���������ѡ�
Kafka 0.9 �汾֮ǰ,consumer Ĭ�Ͻ� offset ������ Zookeeper ��;�� 0.9 �汾��ʼ,consumer Ĭ�Ͻ� offset ������ Kafka һ�����õ� topic ��,�� topic Ϊ __consumer_offsets��
����Kafka �ܹ�����
1.Kafka �������̼��ļ��洢����
? Kafka ����Ϣ���� topic ���з����,������������Ϣ,������������Ϣ,�������� topic �ġ�
? topic �����ϵĸ���,�� partition �������ϵĸ���,ÿ�� partition ��Ӧ��һ�� log �ļ�,�� log �ļ��д洢�ľ��� producer ���������ݡ�Producer ���������ݻᱻ�����ӵ��� log �ļ�ĩ��,��ÿ�����ݶ����Լ��� offset�����������е�ÿ��������,����ʵʱ��¼�Լ����ѵ����ĸ� offset,�Ա�����ָ�ʱ,���ϴε�λ�ü������ѡ�
? ������������������Ϣ����ӵ� log �ļ�ĩβ,Ϊ��ֹ log �ļ����������ݶ�λЧ�ʵ���,Kafka ��ȡ�˷�Ƭ����������,��ÿ�� partition ��Ϊ��� segment��ÿ�� segment ��Ӧ�����ļ�:��.index�� �ļ��� ��.log�� �ļ�����Щ�ļ�λ��һ���ļ�����,���ļ��е���������Ϊ:topic����+������š�����,test ��� topic ����������, �����Ӧ���ļ���Ϊ test-0��test-1��test-2��
? index �� log �ļ��Ե�ǰ segment �ĵ�һ����Ϣ�� offset ������
? ��.index�� �ļ��洢������������Ϣ,��.log�� �ļ��洢����������,�����ļ��е�Ԫ����ָ���Ӧ�����ļ��� message ������ƫ�Ƶ�ַ��
2.���ݿɿ��Ա�֤
Ϊ��֤ producer ���͵�����,�ܿɿ��ķ��͵�ָ���� topic,topic ��ÿ�� partition �յ� producer ���͵����ݺ�, ����Ҫ�� producer ���� ack(acknowledgement ȷ���յ�),��� producer �յ� ack,�ͻ������һ�ֵķ���,�������·�������
3.����һ��������
LEO:ָ����ÿ���������� offset;
HW:ָ�����������ܼ��������� offset,���и�������С�� LEO��
(1)follower ����
follower �������Ϻ�ᱻ��ʱ�߳� ISR(Leader ά����һ���� Leader ����ͬ���� Follower ����),���� follower �ָ���,follower ���ȡ���ش��̼�¼���ϴε� HW,���� log �ļ����� HW �IJ��ֽ�ȡ��,�� HW ��ʼ�� leader ����ͬ�����ȸ� follower �� LEO ���ڵ��ڸ� Partition �� HW,�� follower �� leader ֮��,�Ϳ������¼��� ISR �ˡ�
(2)leader ����
leader ��������֮��,��� ISR ��ѡ��һ���µ� leader, ֮��,Ϊ��֤�������֮�������һ����,����� follower ���Ƚ����Ե� log �ļ����� HW �IJ��ֽص�,Ȼ����µ� leader ͬ�����ݡ�
ע:��ֻ�ܱ�֤����֮�������һ����,�����ܱ�֤���ݲ���ʧ���߲��ظ�
4.ack Ӧ�����
����ijЩ��̫��Ҫ������,�����ݵĿɿ���Ҫ���Ǻܸ�,�ܹ��������ݵ�������ʧ,����û��Ҫ�� ISR �е� follower ȫ�����ճɹ������� Kafka Ϊ�û��ṩ�����ֿɿ��Լ���,�û����ݶԿɿ��Ժ��ӳٵ�Ҫ�����Ȩ��ѡ��
�� producer �� leader ��������ʱ,����ͨ�� request.required.acks �������������ݿɿ��Եļ���:
��0:����ζ��producer����ȴ�����broker��ȷ�϶�����������һ����Ϣ��������������ݴ���Ч�����,�������ݿɿ���ȷ����͵ġ���broker����ʱ�п��ܶ�ʧ���ݡ�
��1(Ĭ������):����ζ��producer��ISR�е�leader�ѳɹ��յ������ݲ��õ�ȷ�Ϻ�����һ��message�������followerͬ���ɹ�֮ǰleader����,��ô���ᶪʧ���ݡ�
��-1(������all):producer��Ҫ�ȴ�ISR�е�����follower��ȷ�Ͻ��յ����ݺ����һ�η������,�ɿ�����ߡ���������� follower ͬ����ɺ�,broker ����ack ֮ǰ,leader ��������,��ô����������ظ���
���ֻ����������εݼ�,���ݿɿ������ε�����
ע:�� 0.11 �汾��ǰ��Kafka,�Դ�������Ϊ����,ֻ�ܱ�֤���ݲ���ʧ,�������������߶�������ȫ��ȥ�ء��� 0.11 ���Ժ�汾�� Kafka,������һ���ش�����:�ݵ��ԡ���ν���ݵ��Ծ���ָ Producer ������ Server ���Ͷ��ٴ��ظ�����, Server �˶�ֻ��־û�һ����