3. SparkSQL���ݵļ����뱣��
3.1 ͨ�õļ��غͱ��淽ʽ
spark.read.load �Ǽ������ݵ�ͨ�÷���
df.write.save �DZ������ݵ�ͨ�÷���
3.1.1 ��������
1)readֱ�Ӽ�������
spark.read.json("/opt/module/spark-local/people.json")
2)formatָ��������������
spark.read.format("json").load("/opt/module/spark-local/people.json")
format("��"):ָ�����ص���������,����"csv"����jdbc������json������orc������parquet"��"textFile��
load("��"):��"csv"����jdbc������json������orc������parquet"��"textFile"��ʽ����Ҫ����������ݵ�·��
option(����"):��"jdbc"��ʽ����Ҫ����JDBC��Ӧ����,url��user��password��dbtable
3)���ļ���ֱ������SQL
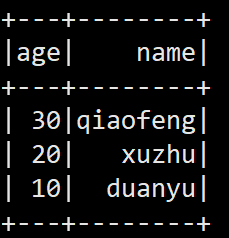
spark.sql("select * from json.`/opt/module/spark-local/people.json`").show
���:
3.1.2 ��������
1)writeֱ�ӱ�������
scala> df.write.
csv jdbc json orc parquet textFile�� ��
�������ݵ���ز�����д�����������С���:textFile�贫��������ݵ�·��,jdbc�贫��JDBC��ز�����
# Ĭ�ϱ����ʽΪparquet
scala> df.write.save("/opt/module/spark-local/output")
# ����ָ��Ϊ�����ʽ,ֱ�ӱ���,����Ҫ�ٵ���save��
scala> df.write.json("/opt/module/spark-local/output")
2)formatָ��������������
df.write.format("��")[.option("��")].save("��")
format("��"):ָ���������������,����"csv"����jdbc������json������orc������parquet"��"textFile����
save ("��"):��"csv"����orc������parquet"��"textFile"��ʽ����Ҫ���뱣�����ݵ�·����
option(����"):��"jdbc"��ʽ����Ҫ����JDBC��Ӧ����,url��user��password��dbtable
3)�ļ�����ѡ��
�����������ʹ�� SaveMode, ����ָ����δ�������,ʹ��mode()���������á���һ�����Ҫ: ��Щ SaveMode ����û�м�����, Ҳ����ԭ�Ӳ�����SaveMode��һ��ö����,���еij�������:
| Scala/Java | Any | Language Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | ��error��(default) | ����ļ��Ѿ��������׳��쳣 |
| SaveMode.Append | ��append�� | ����ļ��Ѿ��������� |
| SaveMode.Overwrite | ��overwrite�� | ����ļ��Ѿ������� |
| SaveMode.Ignore | ��ignore�� | ����ļ��Ѿ���������� |
ʹ��ָ��formatָ���������ͽ��б���
df.write.mode("append").json("/opt/module/spark-local/output")
3.1.3 Ĭ������Դ
Spark SQL��Ĭ������ԴΪParquet��ʽ������ԴΪParquet�ļ�ʱ,Spark SQL���Է����ִ�����еIJ���,����Ҫʹ��format����������spark.sql.sources.default,����Ĭ������Դ��ʽ��
1)��������
val df = spark.read.load("/opt/module/spark-local/examples/src/main/resources/users.parquet").show

2)��������
var df = spark.read.json("/opt/module/spark-local/people.json")
df.write.mode("append").save("/opt/module/spark-local/output")
3.2 JSON�ļ�
Spark SQL �ܹ��Զ��Ʋ� JSON���ݼ��Ľṹ,����������Ϊһ��Dataset[Row]. ����ͨ��SparkSession.read.json()ȥ����һ�� һ��JSON �ļ���
1)������ʽת��
import spark.implicits._
2)����JSON�ļ�
val path = "/opt/module/spark-local/people.json"
val peopleDF = spark.read.json(path)
3)������ʱ��
peopleDF.createOrReplaceTempView("people")
4)���ݲ�ѯ
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
3.3 MySQL
Spark SQL����ͨ��JDBC�ӹ�ϵ�����ݿ��ж�ȡ���ݵķ�ʽ����DataFrame,ͨ����DataFrameһϵ�еļ����,�����Խ�������д�ع�ϵ�����ݿ��С�
���ʹ��spark-shell����,��������shellʱָ����ص����ݿ�����·�����߽���ص����ݿ������ŵ�spark����·���¡�
bin/spark-shell
�Cjars mysql-connector-java-5.1.27-bin.jar
��Idea��ͨ��JDBC��Mysql���в���
3.3.1 ͨ��jdbc��MySQL���ж�д����
/**
* ͨ��jdbc��MySQL���ж�д����
*/
object SparkSQL01_MySQL {
def main(args: Array[String]): Unit = {
//���������ļ�����
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_MySQL")
//����SparkSession����
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//��MySql���ݿ��ж�ȡ����
//��ʽ1 ͨ�õ�load������ȡ
spark.read.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/test")
.option("driver ", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "user")
.load().show()
//��ʽ2 ͨ�õ�load������ȡ ������һ����ʽ
spark.read.format("jdbc")
.options(
Map(
"url" -> "jdbc:mysql://hadoop102:3306/test",
"driver" -> "com.mysql.jdbc.Driver",
"user" -> "root",
"password" -> "000000",
"dbtable" -> "user"
)
)
.load().show()
//��ʽ3 ʹ��jdbc������ȡ
val properties: Properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "000000")
spark.read.jdbc("jdbc:mysql://hadoop102:3306/test", "user", properties).show()
//��MySql���ݿ���д����
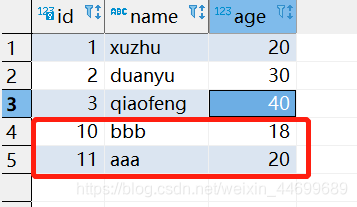
val rdd: RDD[User] = spark.sparkContext.makeRDD(List(User("aaa", 20), User("bbb", 18)))
//��RDDת��ΪDF
val df: DataFrame = rdd.toDF()
//��RDDת��ΪDS
val ds: Dataset[User] = rdd.toDS()
ds.write.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/test")
.option("driver ", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "user")
.mode(SaveMode.Append)
.save()
//�ͷ���Դ
spark.stop()
}
}
case class User(name: String, age: Int)
���:
��:
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1| xuzhu| 20|
| 2| duanyu| 30|
| 3|qiaofeng| 40|
+---+--------+---+
д:
3.3.2 ��JDBC���
3.4 Hive
Apache Hive �� Hadoop �ϵ� SQL ����,Spark SQL����ʱ������ Hive ֧��,Ҳ���Բ�������
���� Hive ֧�ֵ� Spark SQL ����֧�� Hive �����ʡ�UDF (�û��Զ��庯��)�Լ� Hive ��ѯ����(HiveQL/HQL)�ȡ���Ҫǿ����һ����,���Ҫ�� Spark SQL �а���Hive �Ŀ�,������Ҫ���Ȱ�װ Hive��һ����˵,��û����ڱ���Spark SQLʱ����Hive֧��,�����Ϳ���ʹ����Щ�����ˡ���������ص��Ƕ����ư汾�� Spark,��Ӧ���Ѿ��ڱ���ʱ������ Hive ֧�֡�
��Ҫ�� Spark SQL ���ӵ�һ������õ� Hive ��,������ hive-site.xml ���Ƶ� Spark�������ļ�Ŀ¼��($SPARK_HOME/conf)����ʹû�в���� Hive,Spark SQL Ҳ��������,��Ҫע�����,�����û�в����Hive,Spark SQL ���ڵ�ǰ�Ĺ���Ŀ¼�д������Լ��� Hive Ԫ���ݲֿ�,���� metastore_db������,����ʹ�ò���õ�Hive,����㳢��ʹ�� HiveQL �е� CREATE TABLE (���� CREATE EXTERNAL TABLE)�����������,��Щ���ᱻ������Ĭ�ϵ��ļ�ϵͳ�е� /user/hive/warehouse Ŀ¼��(������ classpath ������õ� hdfs-site.xml,Ĭ�ϵ��ļ�ϵͳ���� HDFS,������DZ����ļ�ϵͳ)��
spark-shellĬ����Hive֧�ֵ�;��������Ĭ�ϲ�֧�ֵ�,��Ҫ�ֶ�ָ��(��һ����������)��
3.4.1 ʹ����ǶHive
���ʹ�� Spark ��Ƕ�� Hive, ��ʲô��������, ֱ��ʹ�ü���.
Hive ��Ԫ���ݴ洢�� derby ��, �ֿ��ַ:$SPARK_HOME/spark-warehouse
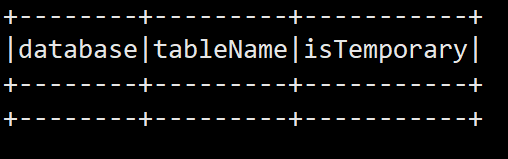
spark.sql("show tables").show
spark.sql("create table aa(id int)") # ����
spark.sql("insert into aa values(100)") #��������
spark.sql("select * from aa").show #��ӡ���
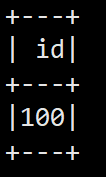
3.4.2 ʹ���ⲿHive
���SparkҪ�ӹ�Hive�ⲿ�Ѿ�����õ�Hive,��Ҫͨ�����¼������衣
ȷ��ԭ��Hive������������
��Ҫ��hive-site.xml������spark��conf/Ŀ¼��
cp /opt/module/hive/conf/hive-site.xml /opt/module/spark-local/conf/
�����ǰhive-site.xml�ļ���,���ù�Tez�����Ϣ,ע�͵�
��Mysql������copy��Spark��jars/Ŀ¼��
cp /opt/software/mysql-connector-java-5.1.48.jar /opt/module/spark-local/jars
��Ҫ��ǰ����hive����,hive/bin/hiveservices.sh start
������ʲ���hdfs,�����core-site.xml��hdfs-site.xml������conf/Ŀ¼
�ٴ�ִ�в�ѯ��,���Կ�����ѯ�����ⲿ��hive�еı�
3.4.3 ����Spark SQL CLI
Spark SQLCLI���Ժܷ�����ڱ�������HiveԪ���ݷ����Լ���������ִ�в�ѯ������SparkĿ¼��ִ��������������Spark SQ LCLI,ֱ��ִ��SQL���,����Hive���ڡ�
bin/spark-sql
3.4.4 �������Hive
1)��������
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
2)����hive-site.xml��resourcesĿ¼
3)�������
object SparkSQL02_Hive {
def main(args: Array[String]): Unit = {
//���������ļ�����
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL02_Hive")
//����SparkSession����(���Ӷ�Hive��֧��)_
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(conf).getOrCreate()
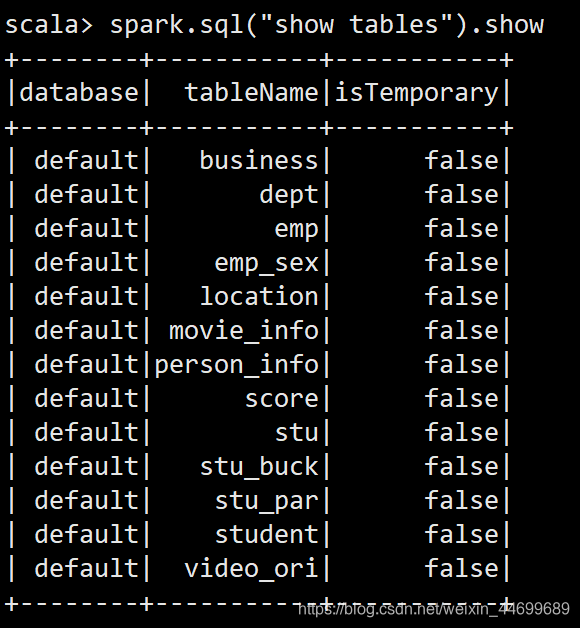
spark.sql("show tables").show()
//�ͷ���Դ
spark.stop()
}
}
���:
+--------+-----------+-----------+
|database| tableName|isTemporary|
+--------+-----------+-----------+
| default| business| false|
| default| dept| false|
| default| emp| false|
| default| emp_sex| false|
| default| location| false|
| default| movie_info| false|
| default|person_info| false|
| default| score| false|
| default| stu| false|
| default| stu_buck| false|
| default| stu_par| false|
| default| student| false|
| default| video_ori| false|
+--------+-----------+-----------+
4. ��Ŀʵս
4.1 ������
�������Spark-sql�������е����ݾ����� Hive,������Hive�д�����,���������ݡ�һ����3�ű�: 1���û���Ϊ��,1�ų��б�,1 �Ų�Ʒ����
�������:
CREATE TABLE `user_visit_action`(
`date` string,
`user_id` bigint,
`session_id` string,
`page_id` bigint,
`action_time` string,
`search_keyword` string,
`click_category_id` bigint,
`click_product_id` bigint,
`order_category_ids` string,
`order_product_ids` string,
`pay_category_ids` string,
`pay_product_ids` string,
`city_id` bigint)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/user_visit_action.txt' into table sparkpractice.user_visit_action;
CREATE TABLE `product_info`(
`product_id` bigint,
`product_name` string,
`extend_info` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/product_info.txt' into table sparkpractice.product_info;
CREATE TABLE `city_info`(
`city_id` bigint,
`city_name` string,
`area` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/city_info.txt' into table sparkpractice.city_info;
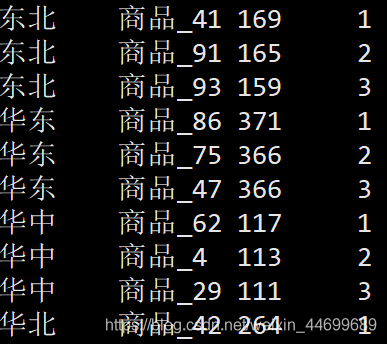
4.2.1 ����:��������������ƷTop3
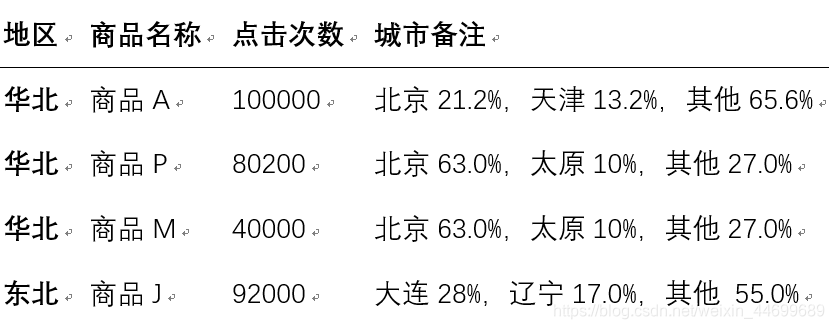
�����������Ʒ�Ǵӵ������ά��������,�����������ǰ����������Ʒ,����ע��ÿ����Ʒ����Ҫ�����еķֲ�����,��������������������ʾ��
����:
4.2.2 ˼·����
ʹ�� sql �����,�������ӵ�����,����ʹ�� udf �� udaf
��ѯ�������еĵ����¼,���� city_info ������,�õ�ÿ���������ڵĵ���,�� Product_info �����ӵõ���Ʒ����
���յ�������Ʒ���Ʒ���,ͳ�Ƴ�ÿ����Ʒ��ÿ���������ܵ������
ÿ�������ڰ��յ��������������
ֻȡǰ����,���ѽ�����������ݿ���
���б�ע��Ҫ�Զ��� UDAF ����
4.2.3 ����ʵ��
1)ͨ��SQLʵ�����������������������ǰ3
1.1)���û���Ϊ����,��ѯ���е����¼,����city_info,product_info��������
select
c.area,
p.product_name
from
user_visit_action a
join
city_info c
on
a.city_id = c.city_id
join
product_info p
on
a.click_product_id = p.product_id
where
a.click_product_id != -1
limit 10
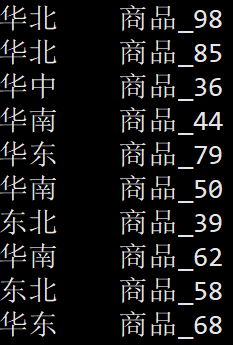
1.2)���յ�������Ʒ�����ƽ��з���,ͳ�Ƴ�ÿ������ÿ����Ʒ�ĵ������
select
t1.area,
t1.product_name,
count(*) as product_click_count
from
(
select
c.area,
p.product_name
from
user_visit_action a
join
city_info c
on
a.city_id = c.city_id
join
product_info p
on
a.click_product_id = p.product_id
where
a.click_product_id != -1
)t1
group by t1.area,t1.product_name
limit 10
1.3)���ÿ������,����Ʒ��������н�������
select
t2.area,
t2.product_name,
t2.product_click_count,
row_number() over(partition by t2.area order by t2.product_click_count desc) cn
from
(
select
t1.area,
t1.product_name,
count(*) as product_click_count
from
(
select
c.area,
p.product_name
from
user_visit_action a
join
city_info c
on
a.city_id = c.city_id
join
product_info p
on
a.click_product_id = p.product_id
where
a.click_product_id != -1
)t1
group by t1.area,t1.product_name
)t2
limit 30
���:
1.4)ȡ��ǰ������ǰ3��
select
t3.area,
t3.product_name,
t3.product_click_count,
t3.cn
from
(
select
t2.area,
t2.product_name,
t2.product_click_count,
row_number() over(partition by t2.area order by t2.product_click_count desc) cn
from
(
select
t1.area,
t1.product_name,
count(*) as product_click_count
from
(
select
c.area,
p.product_name
from
user_visit_action a
join
city_info c
on
a.city_id = c.city_id
join
product_info p
on
a.click_product_id = p.product_id
where
a.click_product_id != -1
)t1
group by t1.area,t1.product_name
)t2
)t3
where t3.cn <= 3
limit 10
���: