Hadoop--来自 尚硅谷 笔记
Hadoop的安装(集群虐我千万遍,我待集群如初恋~)
前面虚拟机的安装过程我们就直接省略了;
新手建议多安装几遍,我已经卸载安装不知道n遍了,马上给我整吐啦~呕~~~。
打开终端:在命令行中输入(root用户下进行)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
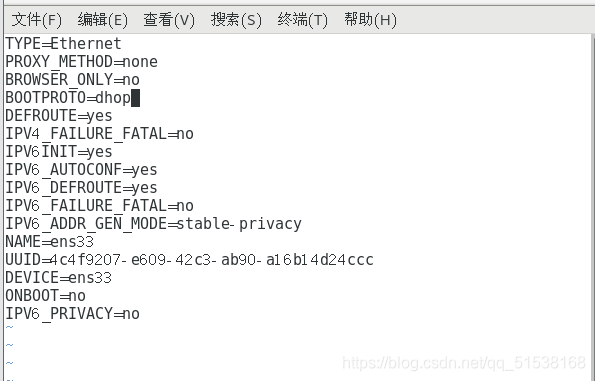
修改:BOOTPROTO=DHOP为static
有的用户可能会出现ONBOOT=no,调成yes即可
在下面增加:
IPADDR=
GATEWAY=
DNS1=
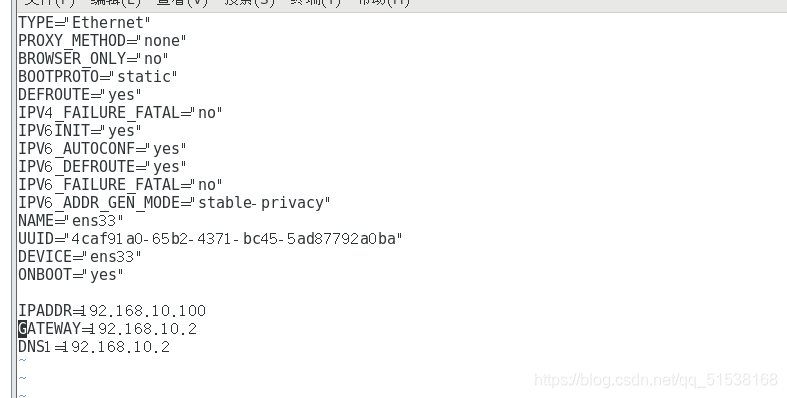
保存退出
命令行输入:
vim /etc/hosts
加入
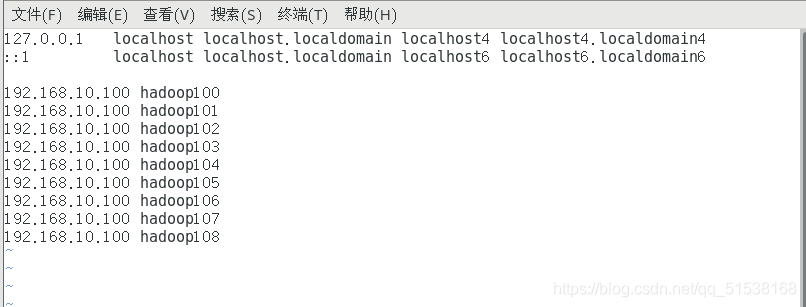
保存。reboot重启,用root账户再次进入
输入:
ifconfig
检查网络环境,看ip地址是否有错误

输入
ping www.baidu.com

做到这里基本上都可以成功,自己没成功的话可以尝试卸载重新安装
配置Xshell ,选择协议SSH,端口号22
切换到root用户,检查网络是否畅通
下载软藏
yum install -y epel-release
如果有进程睡眠
kill -9 进程号
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld.service
赋予普通用户权限
vim /etc/sudoers

进入/opt目录
创建module software
sudo mkdir module
sudo mkdir software
移动到用户目录
sudo chown jialan:jialan module/ software/
检测已安装的JDK
rpm -qa | grep -i java
卸载安装的JDK(切换到root用户)
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
用上一句检测是否删完
重启
reboot
克隆虚拟机(略)
用Xftp上传jar包
解压缩
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置JDK环境变量
sudo vim /etc/profile.d/my_env.sh
添加
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
让新的环境变量生效
source /etc/profile
测试JDK是否安装成功
java
安装hadoop
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
可以使用pwd获取路径
接着打开配置文件
sudo vim /etc/profile.d/my_env.sh
再最后添加
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
再次使新的环境变量生效
source /etc/profile
输入
hadoop
Hadoop运行模式
1.本地模式
2.伪分布式模式
3.完全分布式模式
搭建完全分布式
首先我们在hadoop102配置好了java 和 hadoop 下面直接通过脚本分发在hadoop103 hadoop104上省去刚才的那些步骤、
在hdaoop102 ,103 ,104上/opt中都存在module 和 sofrware 目录
在hadoop102上通过脚本拷贝到103上(我的用户名为jialan)
scp -r /opt/module/jdk1.8.0_212 jialan@hadoop103:/opt/module
在103上通过脚本拉到自己的目录上
scp -r jialan@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
在103上将102上的拷贝到104上
scp -r jialan@hadoop102:/opt/module/* jialan@hadoop104:/opt/module/
rsync 远程同步工具
rsync是复制不同的,scp相同不相同都会进行复制;
rsync -av $pdir/$fname $user@$host:$pdir/$fname
xsync 集群分发脚本
sudo ./bin/xsync /etc/profile.d/my_env.sh
ssh免密登录
ssh-keygen -t rsa
免密到hadoop103
ssh-copy-id hadoop103
集群配置:
核心配置文件:
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 jialan -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>ajialan</value>
</property>
</configuration>
配置hdfs.site.xml
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
配置yarn.site.xml
vim yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
配置mapred.site.xml
vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
在集群上分发脚本
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
群起集群
vim /opt/module/hadoop3.1.3/etc/hadoop/workers
增加
hadoop102
hadoop103
hadoop104
同步所有结点配置文件
xsync /opt/module/hadoop-3.1.3/etc
群起集群,第一次进行初始化
hdfs namenode -format
启动hdfs
sbin/start-dfs.sh
在Hadoop103上启动yarn
sbin/start-yarn.sh
查看集群部署情况
jps
进行集群测试
hadoop fs -mkdir /input
上传小文件
hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input

上传大文件
hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
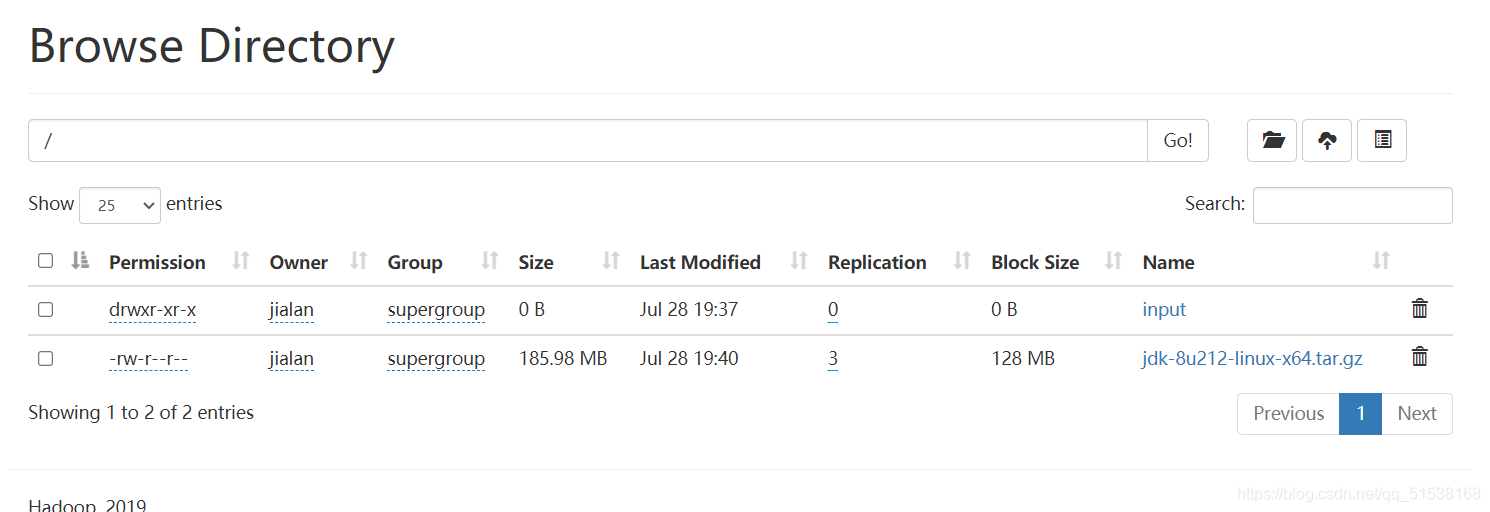
查看hdfs文件存储路径
pwd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1436128598-192.168.10.102-1610603650062/current/finalized/subdir0/subdir0
执行wordcount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
配置历史服务器
vim mapred-site.xml
添加
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
分发
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
启动历史服务器
mapred --daemon start historyserver
配置日志聚集功能
vim yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
分发配置
xsync $HADOOP_HOME/etc/hadoop/yarnsite.xml
在hadoop103上关闭,启动
sbin/stop-yarn.sh
mapred --daemon stop historyserver
start-yarn.sh
mapred --daemon start historyserver
在hadoop102上删除HDFS已经存在的文件
hadoop fs -rm -r /output
执行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
集群的整体启动和停止
HDFS
start-dfs.sh/stop-dfs.sh
YARN
start-yarn.sh/stop-yarn.sh
各个服务器逐一启动与停止
HDFS
hdfs --daemon start/stop namenode/datanode/secondarynamenode
YARN
yarn --daemon start/stop resourcemanager/nodemanager