spark��鼰spark����ԭ���Ϳ��������
spark���
Spark��һ�ֻ����ڴ�Ŀ��١�ͨ�á�����չ�Ĵ����ݷ����������档
�Ǽ��ݴ�ѧ��������УAMPʵ����(Algorithms, Machines, and People Lab)������ͨ���ڴ沢�м�����
Spark�õ����ڶ�����ݹ�˾��֧��,��Щ��˾����Hortonworks��IBM��Intel��Cloudera��MapR��Pivotal���ٶȡ������Ѷ��������Я�̡��ſ���������ǰ�ٶȵ�Spark��Ӧ���ڴ�������ֱ��š��ٶȴ����ݵ�ҵ��;��������GraphX�����˴��ģ��ͼ�����ͼ�ھ�ϵͳ,ʵ���˺ܶ�����ϵͳ���Ƽ��㷨;��ѶSpark��Ⱥ�ﵽ8000̨�Ĺ�ģ,�ǵ�ǰ��֪������������Spark��Ⱥ��
�汾��ʷ
hadoop�ԱȰ汾��ʷ
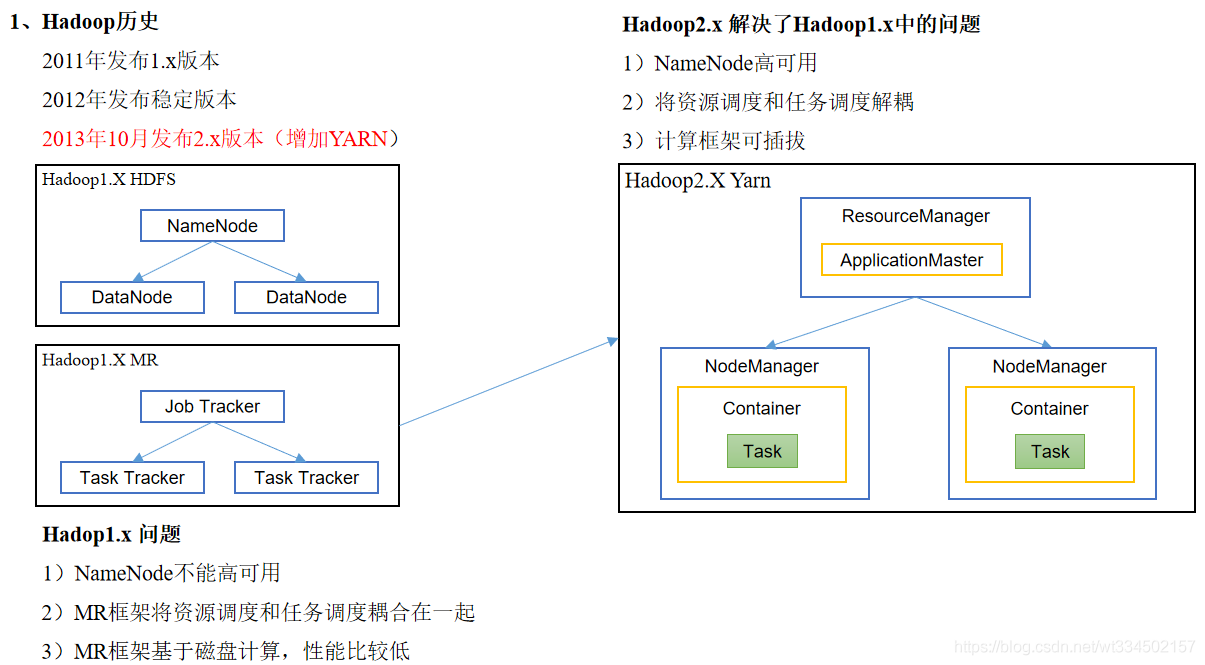
spark�ԱȰ汾��ʷ
spark�Ա�MapReduce���
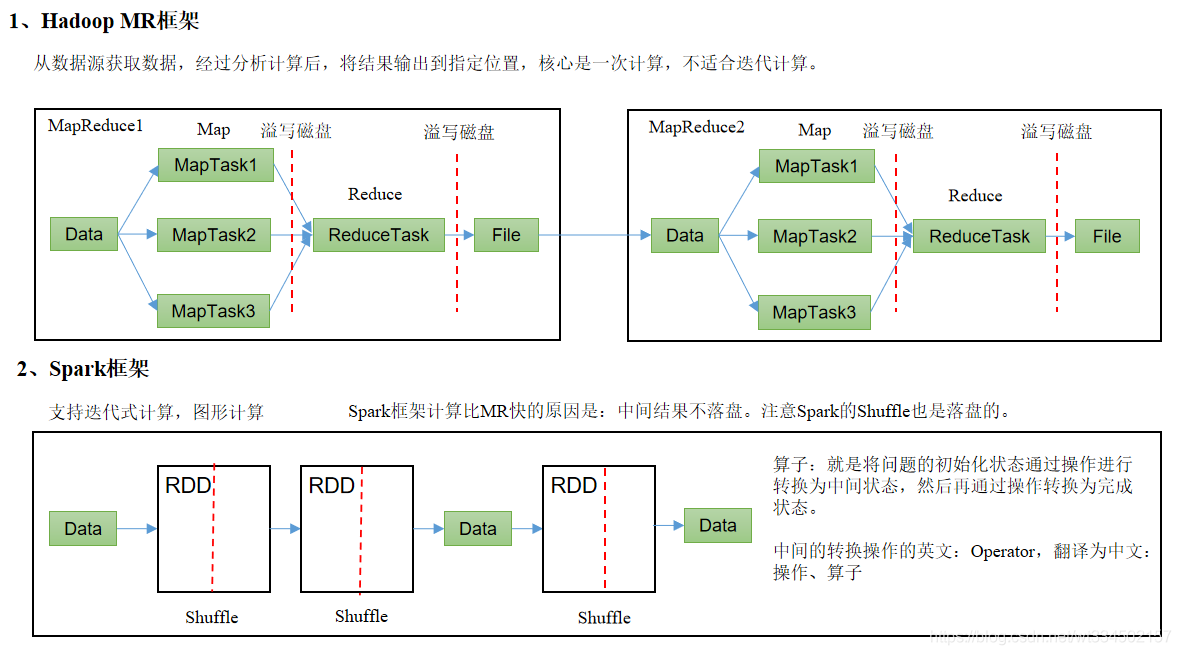
RDD:�����Էֲ�ʽ���ݼ�( Resiliennt Distributed Datasets )
spark����ģ��
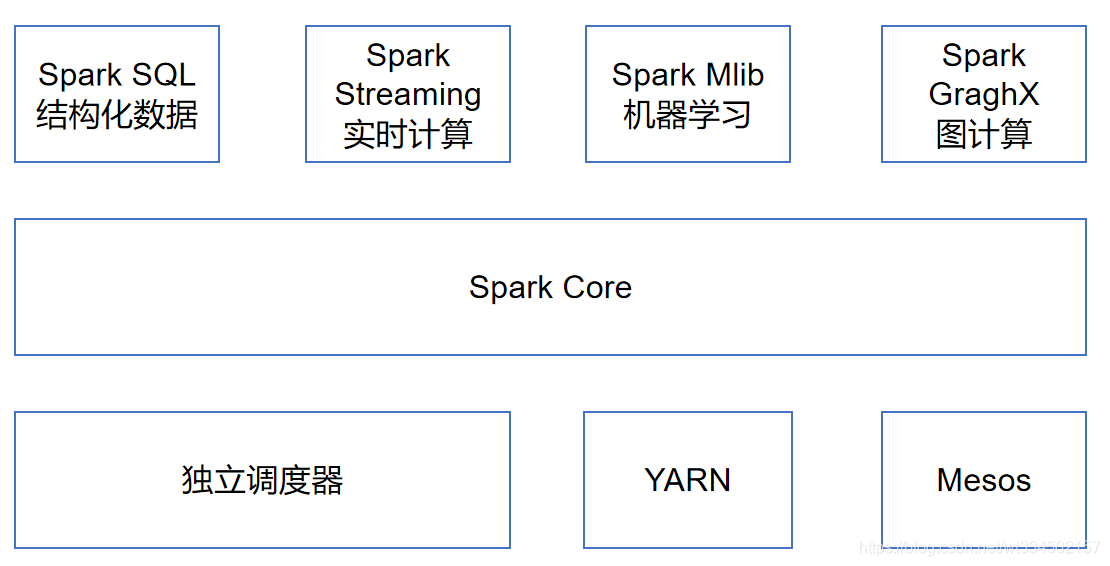
Spark Core:ʵ����Spark�Ļ�������,����������ȡ��ڴ����������ָ�����洢ϵͳ������ģ�顣Spark Core�л������˶Ե��Էֲ�ʽ���ݼ�(Resilient Distributed DataSet,���RDD)��API���塣
Spark SQL:��Spark���������ṹ�����ݵij������ͨ��Spark SQL,���ǿ���ʹ�� SQL����Apache Hive�汾��HQL����ѯ���ݡ�Spark SQL֧�ֶ�������Դ,����Hive����Parquet�Լ�JSON�ȡ�
Spark Streaming:��Spark�ṩ�Ķ�ʵʱ���ݽ�����ʽ�����������ṩ������������������API,������Spark Core�е� RDD API�߶ȶ�Ӧ��
Spark MLlib:�ṩ�����Ļ���ѧϰ���ܵij���⡣�������ࡢ�ع顢���ࡢЭͬ���˵�,���ṩ��ģ������������ ����ȶ����֧�ֹ��ܡ�
Spark GraphX:��Ҫ����ͼ�β��м����ͼ�ھ�ϵͳ�������
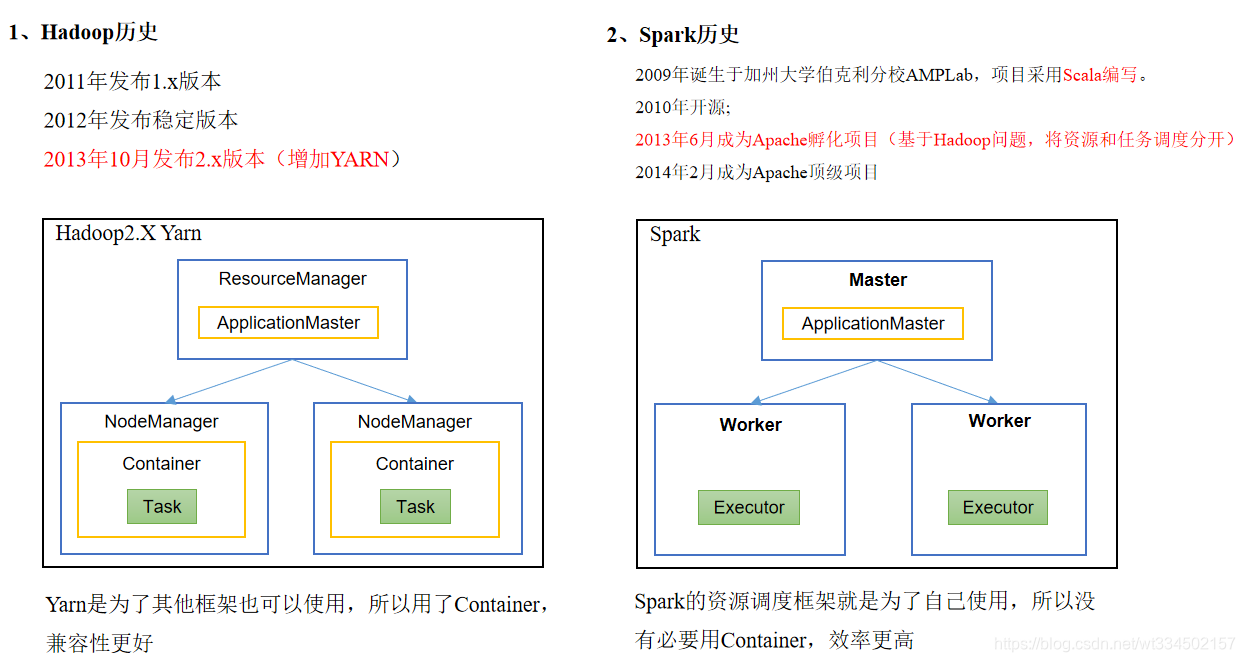
��Ⱥ������:Spark���Ϊ���Ը�Ч����һ������ڵ㵽��ǧ������ڵ�֮���������㡣Ϊ��ʵ��������Ҫ��,ͬʱ�����������,Spark֧���ڸ��ּ�Ⱥ������(Cluster Manager)������,����Hadoop YARN��Apache Mesos,�Լ�Spark�Դ���һ����������,����������������
spark�ص�
�����ٶȿ�:
��Hadoop��MapReduce���,Spark�����ڴ������Ҫ��100������,����Ӳ�̵�����ҲҪ��10�����ϡ�Sparkʵ���˸�Ч��DAGִ������,����ͨ�������ڴ�����Ч������������������м����Ǵ������ڴ���
�����Ժ�:
Spark֧��Java��Python��Scala��API,��֧�ֳ���80�ָ��㷨,ʹ�û����Կ��ٹ�����ͬ��Ӧ�á�����Spark֧�ֽ���ʽ��Python��Scala��Shell,���Էdz����������ЩShell��ʹ��Spark��Ⱥ����֤�������ķ���
ͨ����ǿ:
Spark�ṩ��ͳһ�Ľ��������Spark��������,����ʽ��ѯ(Spark SQL)��ʵʱ������(Spark Streaming)������ѧϰ(Spark MLlib)��ͼ����(GraphX)����Щ��ͬ���͵Ĵ�����������ͬһ��Ӧ������ʹ�á������˿�����ά���������ɱ��Ͳ���ƽ̨�������ɱ�
������:
Spark���Էdz�������������Ŀ�Դ��Ʒ�����ںϡ�����,Spark����ʹ��Hadoop��YARN��Apache Mesos��Ϊ������Դ�����͵�����,���ҿ��Դ�������Hadoop֧�ֵ�����,����HDFS��HBase�ȡ�������Ѿ�����Hadoop��Ⱥ���û��ر���Ҫ,��Ϊ����Ҫ���κ�����Ǩ�ƾͿ���ʹ��Spark��ǿ��������
spark����
Spark����ģʽ
����Spark��Ⱥ�����Ϸ�Ϊ����ģʽ:����ģʽ�뼯Ⱥģʽ
������ֲ�ʽ��ܶ�֧�ֵ���ģʽ,���㿪���ߵ��Կ�ܵ����л���������������������,������ʹ�õ���ģʽ�����,����ֱ�Ӱ��ռ�Ⱥģʽ����Spark��Ⱥ��
������ϸ�о���SparkĿǰ֧�ֵIJ���ģʽ��
Localģʽ
�ڱ��ز���Spark����,�Ƚ��ʺϼ��˽�sparkĿ¼�ṹ,��Ϥ�����ļ�,����һ��demoʾ���ȵ��Գ�����
Standaloneģʽ
Spark�Դ����������ģʽ,���spark����֮���ڲ�Э������,������spark�������������
YARNģʽ
Sparkʹ��Hadoop��YARN���������Դ���������,����������spark���ⲿ�Խ�Э����
Mesosģʽ
Sparkʹ��Mesosƽ̨������Դ������ĵ��ȡ�Spark�ͻ���ֱ������Mesos;����Ҫ�����Spark��Ⱥ��
( Mesos��һ����Ⱥ����ƽ̨�� ��������Ϊ��һ�ֲַ�ʽϵͳ��kernel, ����Ⱥ��Դ�ķ���, �������Դָ����CPU��Դ, �ڴ���Դ, �洢��Դ, ������Դ�ȡ� ��Mesos��������Spark, Storm, Hadoop, Marathon�ȶ���Framework )
spark����
Localģʽ����ʹ�ý���
���ذ�װ��:���� -> Download -> release archives -> spark-2.1.1 -> spark-2.1.1-bin-hadoop2.7.tgz ����
��ѹSpark��װ��
wangting@ops01:/opt/software >tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
Ŀ¼����
wangting@ops01:/opt/software >cd /opt/module/
wangting@ops01:/opt/module >mv spark-2.1.1-bin-hadoop2.7 spark-local
Ŀ¼�ṹ
wangting@ops01:/opt/module >cd spark-local/
wangting@ops01:/opt/module/spark-local >
wangting@ops01:/opt/module/spark-local >ll
total 104
drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 bin
drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 conf
drwxr-xr-x 5 wangting wangting 4096 Apr 26 2017 data
drwxr-xr-x 4 wangting wangting 4096 Apr 26 2017 examples
drwxr-xr-x 2 wangting wangting 12288 Apr 26 2017 jars
-rw-r--r-- 1 wangting wangting 17811 Apr 26 2017 LICENSE
drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 licenses
-rw-r--r-- 1 wangting wangting 24645 Apr 26 2017 NOTICE
drwxr-xr-x 8 wangting wangting 4096 Apr 26 2017 python
drwxr-xr-x 3 wangting wangting 4096 Apr 26 2017 R
-rw-r--r-- 1 wangting wangting 3817 Apr 26 2017 README.md
-rw-r--r-- 1 wangting wangting 128 Apr 26 2017 RELEASE
drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 sbin
drwxr-xr-x 2 wangting wangting 4096 Apr 26 2017 yarn
�ٷ�demoʾ����Բ����Pi
wangting@ops01:/opt/module/spark-local >bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[4] /opt/module/spark-local/examples/jars/spark-examples_2.11-2.1.1.jar 20
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/07/22 10:52:01 INFO SparkContext: Running Spark version 2.1.1
21/07/22 10:52:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/07/22 10:52:02 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-cee9f744-b8dd-4c75-83be-3884f3b4425b
21/07/22 10:52:02 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
21/07/22 10:52:02 INFO SparkEnv: Registering OutputCommitCoordinator
21/07/22 10:52:02 INFO Utils: Successfully started service 'SparkUI' on port 4040.
21/07/22 10:52:02 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://11.8.37.50:4040
21/07/22 10:52:02 INFO SparkContext: Added JAR file:/opt/module/spark-local/examples/jars/spark-examples_2.11-2.1.1.jar at spark://11.8.37.50:46388/jars/spark-examples_2.11-2.1.1.jar with timestamp 1626922322910
21/07/22 10:52:02 INFO Executor: Starting executor ID driver on host localhost
21/07/22 10:52:04 INFO Executor: Fetching spark://11.8.37.50:46388/jars/spark-examples_2.11-2.1.1.jar with timestamp 1626922322910
21/07/22 10:52:04 INFO TransportClientFactory: Successfully created connection to /11.8.37.50:46388 after 28 ms (0 ms spent in bootstraps)
21/07/22 10:52:04 INFO Utils: Fetching spark://11.8.37.50:46388/jars/spark-examples_2.11-2.1.1.jar to /tmp/spark-86795505-2fa5-4e6e-9331-f26233e462b2/userFiles-174c50ee-3aff-4523-a89b-17910dcd467e/fetchFileTemp632487868763480019.tmp
21/07/22 10:52:04 INFO Executor: Adding file:/tmp/spark-86795505-2fa5-4e6e-9331-f26233e462b2/userFiles-174c50ee-3aff-4523-a89b-17910dcd467e/spark-examples_2.11-2.1.1.jar to class loader
21/07/22 10:52:05 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.386012 s
Pi is roughly 3.140143570071785 # <<<<<<< ������
21/07/22 10:52:05 INFO SparkUI: Stopped Spark web UI at http://11.8.37.50:4040
21/07/22 10:52:05 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/07/22 10:52:05 INFO MemoryStore: MemoryStore cleared
21/07/22 10:52:05 INFO BlockManager: BlockManager stopped
21/07/22 10:52:05 INFO BlockManagerMaster: BlockManagerMaster stopped
21/07/22 10:52:05 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/07/22 10:52:05 INFO SparkContext: Successfully stopped SparkContext
21/07/22 10:52:05 INFO ShutdownHookManager: Shutdown hook called
21/07/22 10:52:05 INFO ShutdownHookManager: Deleting directory /tmp/spark-86795505-2fa5-4e6e-9331-f26233e462b2
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[4] /opt/module/spark-local/examples/jars/spark-examples_2.11-2.1.1.jar 20
�Cclass:��ʾҪִ�г���jar��������
�Cmaster local[2]
(1)local: û��ָ���߳���,�����м��㶼������һ���̵߳���,û���κβ��м���
(2)local[K]:ָ��ʹ��K��Core�����м���,����local[4]��������4��Core��ִ��
(3)local[*]: �Զ�����CPU�����������߳���������CPU��4��,Spark�����Զ�����4���̼߳���
spark-examples_2.11-2.1.1.jar:Ҫ���еij���jar��
20 :Ҫ���г����������� ( ����Բ���ʦеĴ���,�������Խ��,ȷ��Խ�� , ����ֻ��Ӧ��ʾ�����崫��)
�ٷ�wordcountʾ��
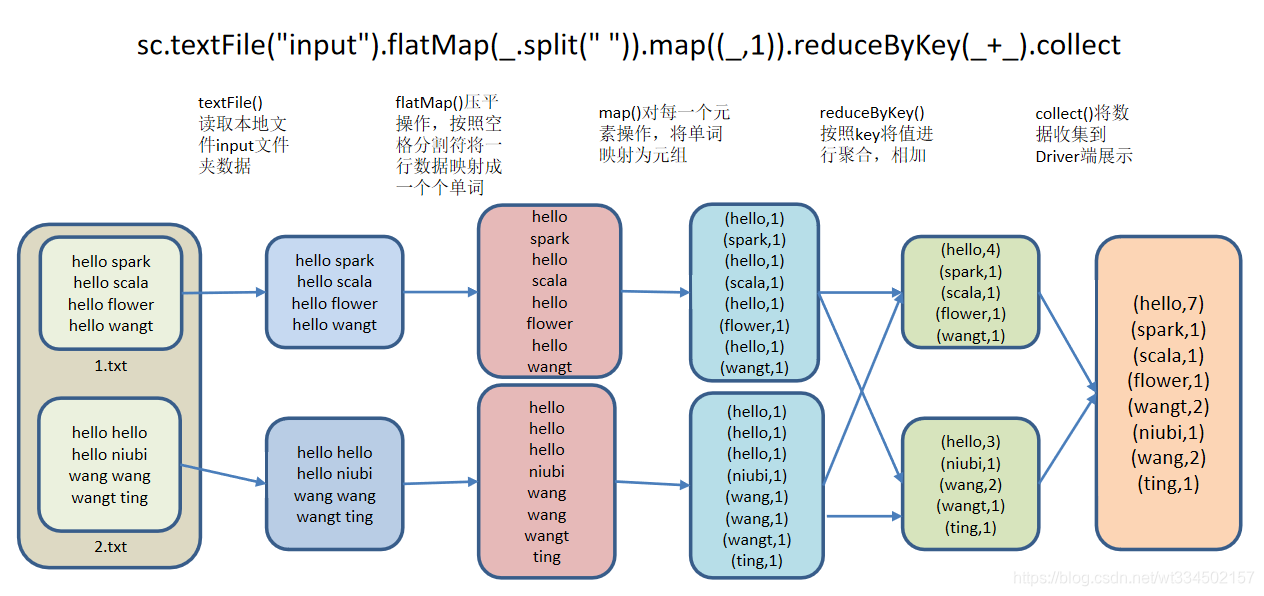
wordcount��ʵ�ֶ���ļ���,���ɵ����ܼƴ���,ͳ�ƴ�Ƶ
����ʵ��Ŀ¼���ļ�
wangting@ops01:/opt/module/spark-local >mkdir input
wangting@ops01:/opt/module/spark-local >cd input/
wangting@ops01:/opt/module/spark-local/input >echo "hello spark" >> 1.txt
wangting@ops01:/opt/module/spark-local/input >echo "hello scala" >> 1.txt
wangting@ops01:/opt/module/spark-local/input >echo "hello flower" >> 1.txt
wangting@ops01:/opt/module/spark-local/input >echo "hello wangt" >> 1.txt
wangting@ops01:/opt/module/spark-local/input >echo "hello hello" >> 2.txt
wangting@ops01:/opt/module/spark-local/input >echo "hello niubi" >> 2.txt
wangting@ops01:/opt/module/spark-local/input >echo "wang wang" >> 2.txt
wangting@ops01:/opt/module/spark-local/input >echo "wangt ting" >> 2.txt
wangting@ops01:/opt/module/spark-local/input >cat 1.txt
hello spark
hello scala
hello flower
hello wangt
wangting@ops01:/opt/module/spark-local/input >cat 2.txt
hello hello
hello niubi
wang wang
wangt ting
����spark-shell������
wangting@ops01:/opt/module/spark-local/input >cd ..
wangting@ops01:/opt/module/spark-local >bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/07/22 11:01:03 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/07/22 11:01:09 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
21/07/22 11:01:09 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
21/07/22 11:01:10 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://11.8.37.50:4040
Spark context available as 'sc' (master = local[*], app id = local-1626922864098).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
��ע�⡿:
- spark-submit��spark-shellֻ������ִ�е�����;��
- spark-submit,�ǽ�jar�ϴ�����Ⱥ,ִ��Spark����;
- spark-shell,�൱�������й���,����Ҳ��һ��Application;
- ����spark-shellʱ,�Ὺ��һ��SparkSubmit�Ľ���,�˿�Ϊ4040,��application��weiUI�Ķ˿ں�,�����б�����������̶˿ڴ��,�������˳�����̶˿�ͬʱҲ����չرա�
ִ��wordcount����
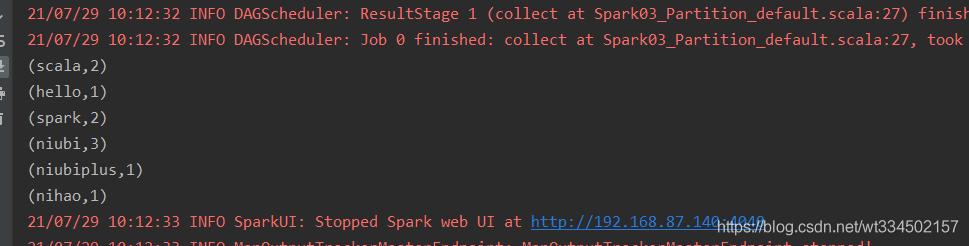
scala> sc.textFile("/opt/module/spark-local/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((ting,1), (scala,1), (hello,7), (flower,1), (spark,1), (niubi,1), (wangt,2), (wang,2))
��˵����:( �����в���ʱtab�����Բ�ȫ )
def textFile(path: String,minPartitions: Int): org.apache.spark.rdd.RDD[String]
textFile() -> ��ȡ�����ļ�input�ļ�������
def flatMap[U](f: String => TraversableOnce[U])(implicit evidence$4: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
flatMap() -> ѹƽ����,���տո�ָ����һ������ӳ���һ��������
def map[U](f: String => U)(implicit evidence$3: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
map() -> ��ÿһ��Ԫ�ز���,������ӳ��ΪԪ��
def reduceByKey(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
reduceByKey() -> ����key��ֵ���оۺ�,���
def collect[U](f: PartialFunction[(String, Int),U](implicit evidence$29: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U] def collect():Array[(String,Int)]
collect() -> �������ռ���Driver��չʾ
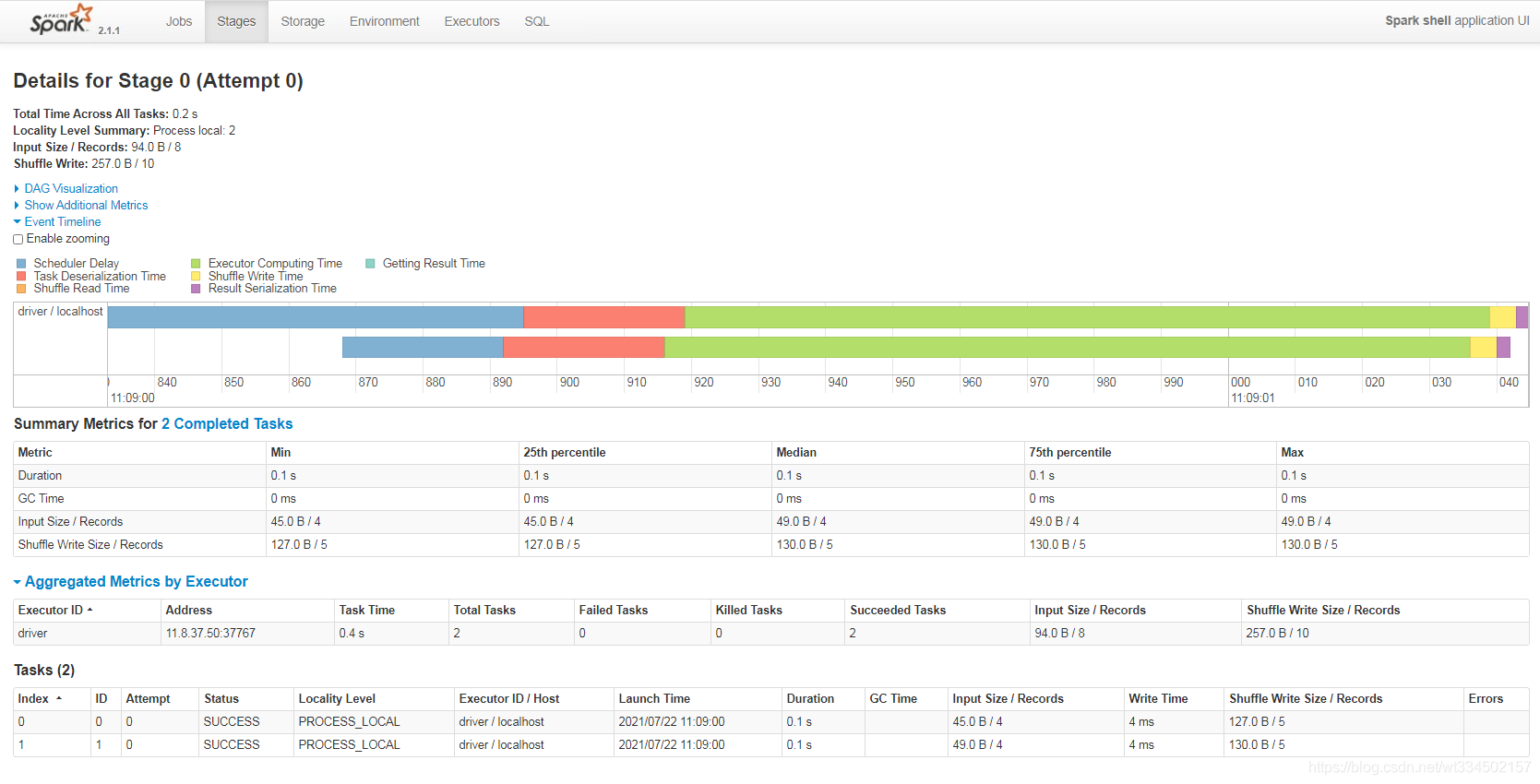
ҳ��鿴
�����Ӧ��job���Կ�������ϸ����Ϣ
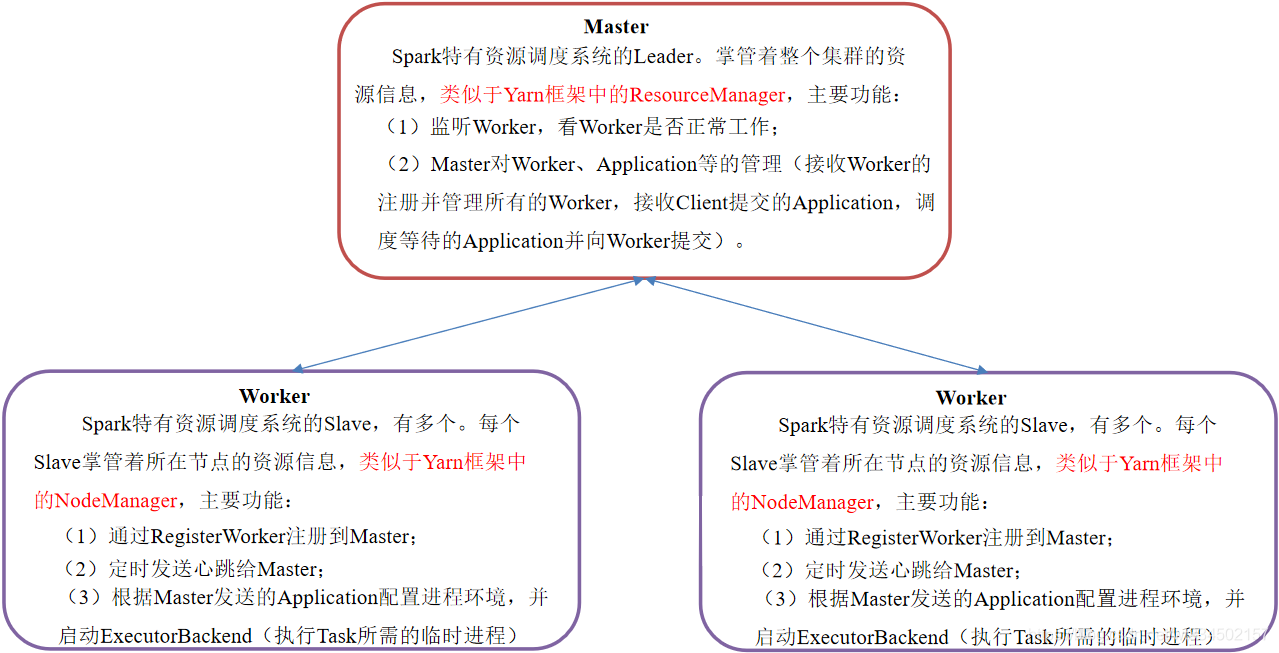
��Ⱥ��ɫ����
Master & Worker
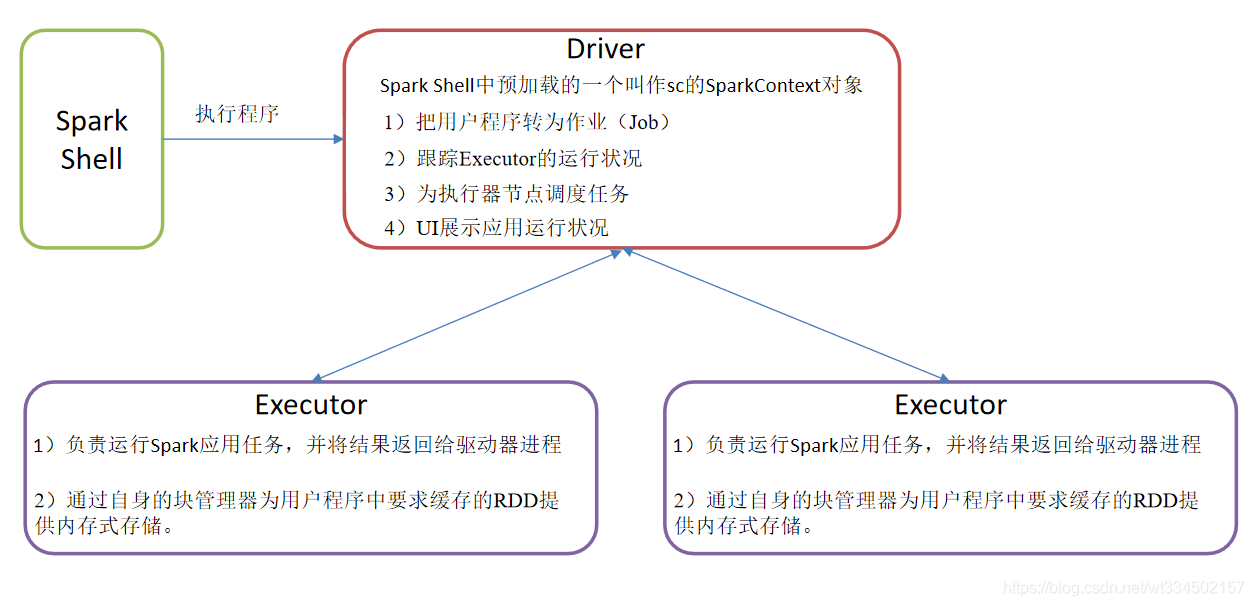
Driver & Executor
��ע�⡿:
-
Master��Worker��Spark���ػ�����,��Spark���ض�ģʽ����������������Ľ��̡�
-
Driver��Executor����ʱ����,���о��������ύ��Spark��Ⱥ�ŻῪ���ij���
Standaloneģʽ����ʹ�ý���
Standaloneģʽ��Spark�Դ�����Դ��������,����һ����Master + Slave���ɵ�Spark��Ⱥ,Spark�����ڼ�Ⱥ�С�
���Ҫ��Hadoop�е�Standalone�������������Standalone��ָֻ��Spark���һ����Ⱥ,����Ҫ���������Ŀ�ܡ��������Yarn��Mesos��˵��
�����滮(3̨����):
ops01 11.8.37.50 master|worker
ops02 11.8.36.63 worker
ops03 11.8.36.76 worker
ops04 11.8.36.86 worker
��ע�⡿:����Ϣ������/etc/hosts���������ļ���
wangting@ops01:/opt/module >cat /etc/hosts
127.0.0.1 ydt-cisp-ops01
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
11.16.0.176 rancher.mydomain.com
11.8.38.123 www.tongtongcf.com
11.8.37.50 ops01
11.8.36.63 ops02
11.8.36.76 ops03
11.8.38.86 ops04
11.8.38.82 jpserver ydt-dmcp-jpserver
wangting@ops01:/opt/module >
��ѹ��װ��
wangting@ops01:/opt/software >tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
Ŀ¼����
wangting@ops01:/opt/software >mv /opt/module/spark-2.1.1-bin-hadoop2.7 /opt/module/spark-standalone
�����ļ�Ŀ¼
wangting@ops01:/opt/software >cd /opt/module/spark-standalone/conf/
wangting@ops01:/opt/module/spark-standalone/conf >
wangting@ops01:/opt/module/spark-standalone/conf >ll
total 32
-rw-r--r-- 1 wangting wangting 987 Apr 26 2017 docker.properties.template
-rw-r--r-- 1 wangting wangting 1105 Apr 26 2017 fairscheduler.xml.template
-rw-r--r-- 1 wangting wangting 2025 Apr 26 2017 log4j.properties.template
-rw-r--r-- 1 wangting wangting 7313 Apr 26 2017 metrics.properties.template
-rw-r--r-- 1 wangting wangting 865 Apr 26 2017 slaves.template
-rw-r--r-- 1 wangting wangting 1292 Apr 26 2017 spark-defaults.conf.template
-rwxr-xr-x 1 wangting wangting 3960 Apr 26 2017 spark-env.sh.template
��slaves���ö��弯Ⱥ
wangting@ops01:/opt/module/spark-standalone/conf >mv slaves.template slaves
wangting@ops01:/opt/module/spark-standalone/conf >vim slaves
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
ops01
ops02
ops03
ops04
��spark-env.sh�ļ�,����master�ڵ�
wangting@ops01:/opt/module/spark-standalone/conf >mv spark-env.sh.template spark-env.sh
wangting@ops01:/opt/module/spark-standalone/conf >vim spark-env.sh
SPARK_MASTER_HOST=ops01
SPARK_MASTER_PORT=7077
�ַ�spark-standaloneĿ¼�����ڵ�
wangting@ops01:/opt/module >scp -r spark-standalone ops02:/opt/module/
wangting@ops01:/opt/module >scp -r spark-standalone ops03:/opt/module/
wangting@ops01:/opt/module >scp -r spark-standalone ops04:/opt/module/
���8080�˿ں�spark����
# ����spark-shell��ͬʱ����8080�˿�-> ǰ��ҳ�� ; �����ȿ��Ƿ��б�ռ��
wangting@ops01:/home/wangting >sudo netstat -tnlpu|grep 8080
wangting@ops01:/home/wangting >
wangting@ops01:/home/wangting >jps -l | grep spark
wangting@ops01:/home/wangting >
����spark-standalone��Ⱥ
wangting@ops01:/home/wangting >cd /opt/module/spark-standalone/
wangting@ops01:/opt/module/spark-standalone >sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.master.Master-1-ops01.out
ops04: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops04.out
ops03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops03.out
ops01: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops01.out
ops02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops02.out
ops04: failed to launch: nice -n 0 /opt/module/spark-standalone/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://ops01:7077
ops04: JAVA_HOME is not set
ops04: full log in /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops04.out
wangting@ops01:/opt/module/spark-standalone >
wangting@ops01:/opt/module/spark-standalone >sudo netstat -tnlpu|grep 8080
tcp6 0 0 :::8080 :::* LISTEN 57689/java
wangting@ops01:/opt/module/spark-standalone >jps -l | grep spark
57809 org.apache.spark.deploy.worker.Worker
57689 org.apache.spark.deploy.master.Master
wangting@ops01:/opt/module/spark-standalone >
����JAVA_HOME is not set
������Ȼ�ɹ�����,����������Ⱥʱ,��ʾ��ops04���� : ops04: JAVA_HOME is not set
���ops04������
wangting@ops04:/opt/module/spark-standalone >echo $JAVA_HOME
/usr/java8_64/jdk1.8.0_101
wangting@ops04:/opt/module/spark-standalone >vim sbin/spark-config.sh
export JAVA_HOME=/usr/java8_64/jdk1.8.0_101
���master: ops01��������
wangting@ops01:/opt/module/spark-standalone >sbin/stop-all.sh
ops01: stopping org.apache.spark.deploy.worker.Worker
ops03: stopping org.apache.spark.deploy.worker.Worker
ops04: no org.apache.spark.deploy.worker.Worker to stop
ops02: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master
wangting@ops01:/opt/module/spark-standalone >
wangting@ops01:/opt/module/spark-standalone >sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.master.Master-1-ops01.out
ops01: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops01.out
ops03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops03.out
ops04: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops04.out
ops02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.worker.Worker-1-ops02.out
wangting@ops01:/opt/module/spark-standalone >
֮ǰ����ʾ�Ѿ�������
������鿴����
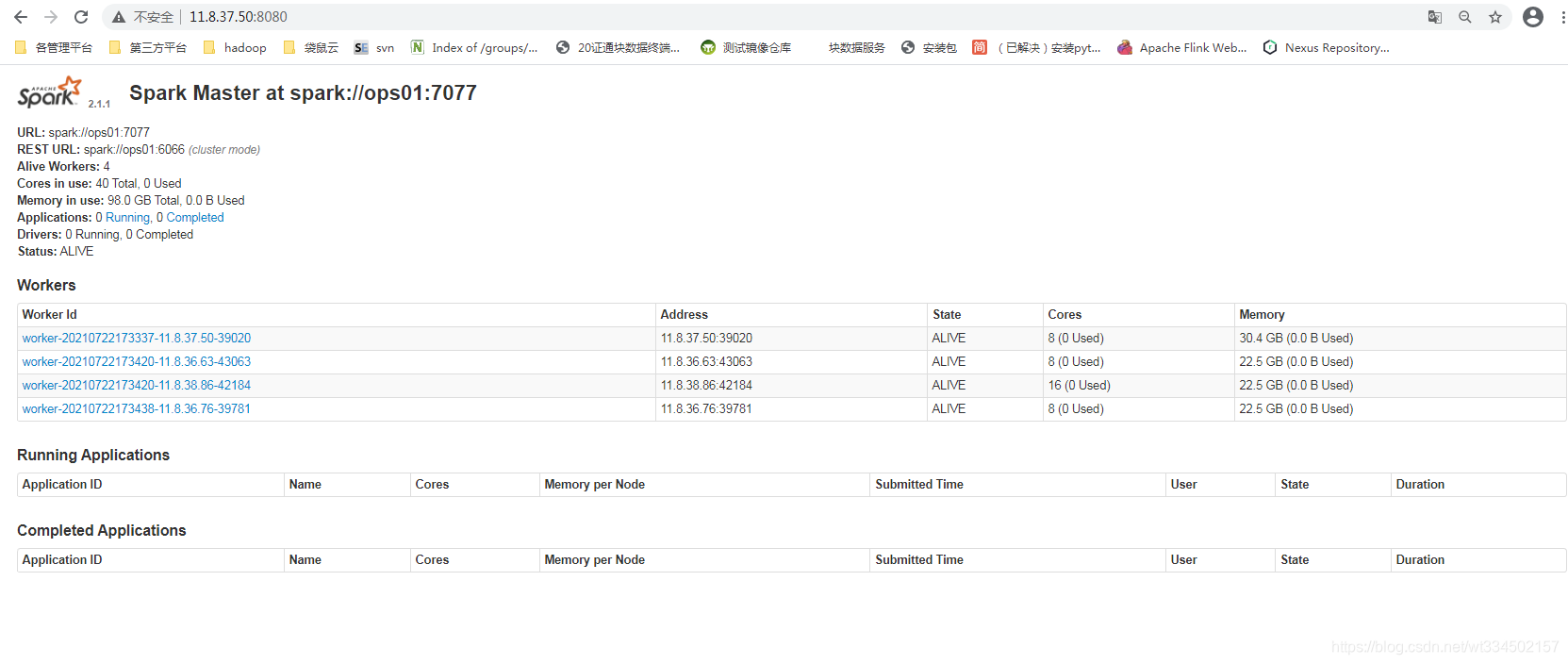
�ٷ�demoʾ����Բ����Pi
wangting@ops01:/opt/module/spark-standalone >bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://ops01:7077 /opt/module/spark-standalone/examples/jars/spark-examples_2.11-2.1.1.jar 20
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/07/23 15:13:39 INFO SparkContext: Running Spark version 2.1.1
21/07/23 15:13:39 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/07/23 15:13:39 INFO SecurityManager: Changing view acls to: wangting
21/07/23 15:13:39 INFO SecurityManager: Changing modify acls to: wangting
21/07/23 15:13:39 INFO SecurityManager: Changing view acls groups to:
21/07/23 15:13:39 INFO SecurityManager: Changing modify acls groups to:
21/07/23 15:13:44 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
21/07/23 15:13:44 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.824153 s
Pi is roughly 3.1423635711817854 # <<< ������
21/07/23 15:13:44 INFO SparkUI: Stopped Spark web UI at http://11.8.37.50:4040
21/07/23 15:13:44 INFO StandaloneSchedulerBackend: Shutting down all executors
21/07/23 15:13:44 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
21/07/23 15:13:44 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/07/23 15:13:44 INFO MemoryStore: MemoryStore cleared
21/07/23 15:13:44 INFO BlockManager: BlockManager stopped
21/07/23 15:13:44 INFO BlockManagerMaster: BlockManagerMaster stopped
21/07/23 15:13:44 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/07/23 15:13:44 INFO SparkContext: Successfully stopped SparkContext
21/07/23 15:13:44 INFO ShutdownHookManager: Shutdown hook called
21/07/23 15:13:44 INFO ShutdownHookManager: Deleting directory /tmp/spark-6547bdc7-5117-4c44-8f14-4328fa38ace6
ҳ��鿴����״̬
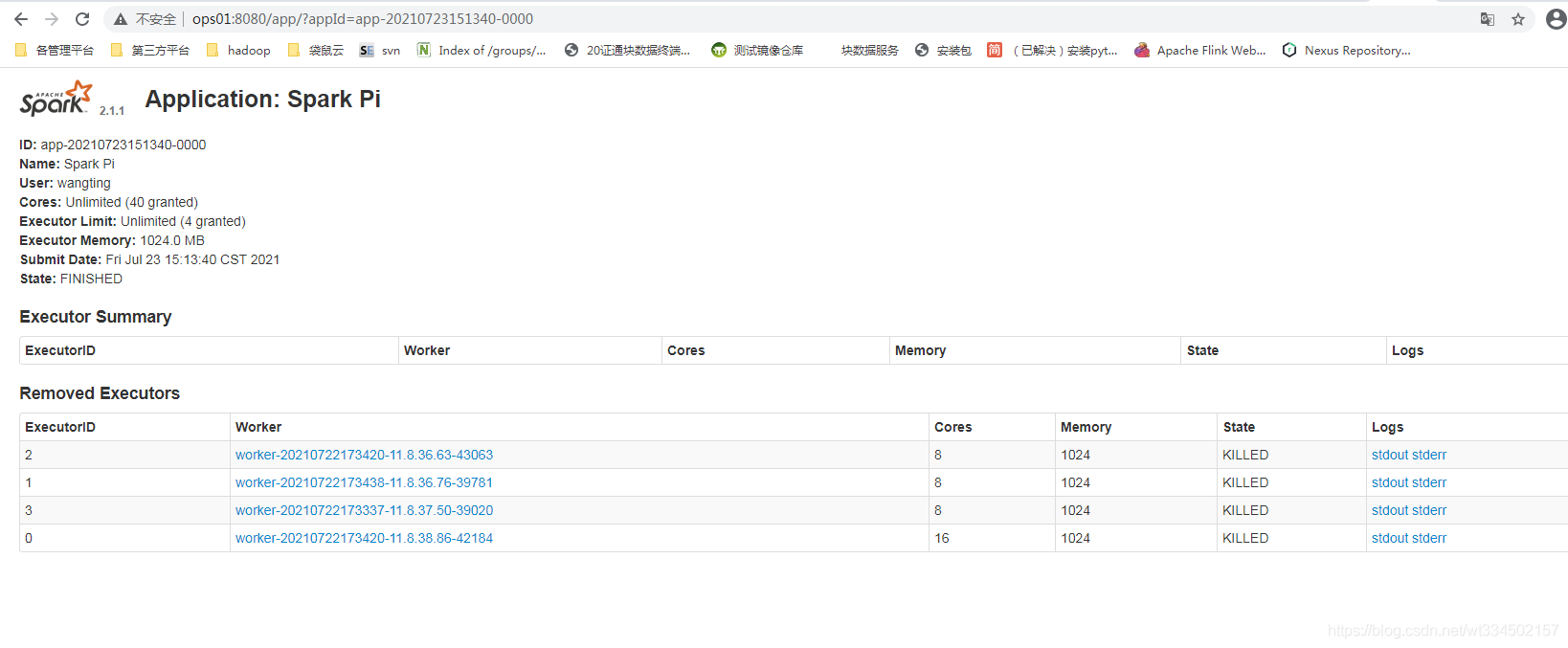
ָ����Դִ������
wangting@ops01:/opt/module/spark-standalone >bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://ops01:7077 --executor-memory 8G --total-executor-cores 4 /opt/module/spark-standalone/examples/jars/spark-examples_2.11-2.1.1.jar 20
wangting@ops01:/opt/module/spark-standalone >
ҳ��鿴������״̬��Դ�仯
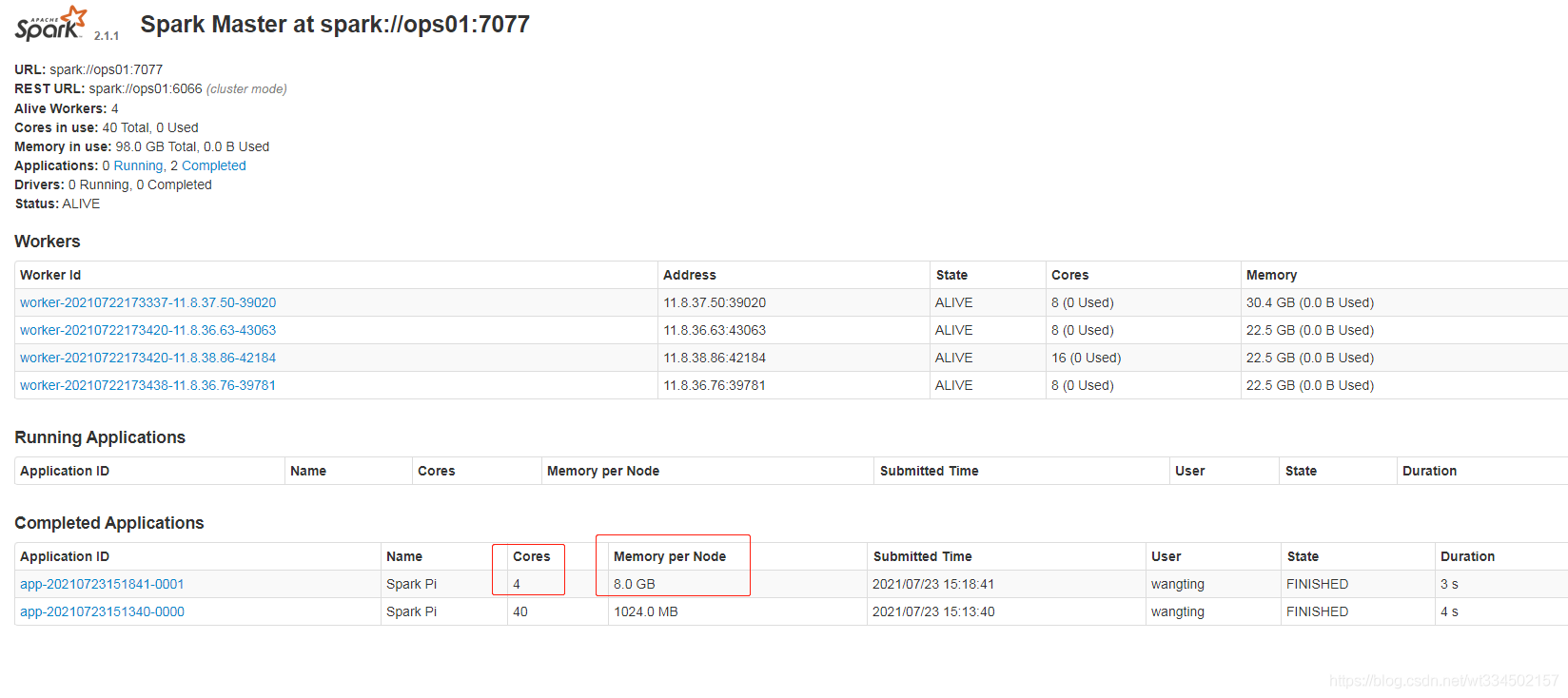
������ʷ����
��ע�⡿: Ĭ���Ѿ���װ��hdfs����,���û����Ҫ�ȴ����һ��,���������Ϊ��ʵ����Կ���ʹ��local�漴��;����Ⱥ��Ĭ���Ѿ��߱���hdfs��Ⱥ������
����spark-shellֹͣ����,hadoop102:4040ҳ��Ϳ�������ʷ������������,���Կ���ʱ��������ʷ��������¼�����������
wangting@ops01:/opt/module/spark-standalone >cd conf/
# �������ļ�
wangting@ops01:/opt/module/spark-standalone/conf >mv spark-defaults.conf.template spark-defaults.conf
wangting@ops01:/opt/module/spark-standalone/conf >
wangting@ops01:/opt/module/spark-standalone/conf >vim spark-defaults.conf
#
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ops01:8020/directory
# ��hdfs������/directoryĿ¼
wangting@ops01:/opt/module/spark-standalone/conf >hdfs dfs -ls /
2021-07-23 15:24:45,730 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 15 items
drwxr-xr-x - wangting supergroup 0 2021-03-17 11:44 /20210317
drwxr-xr-x - wangting supergroup 0 2021-03-19 10:51 /20210319
drwxr-xr-x - wangting supergroup 0 2021-04-24 17:05 /flume
-rw-r--r-- 3 wangting supergroup 338075860 2021-03-12 11:50 /hadoop-3.1.3.tar.gz
drwxr-xr-x - wangting supergroup 0 2021-05-13 15:31 /hbase
drwxr-xr-x - wangting supergroup 0 2021-05-26 16:56 /origin_data
drwxr-xr-x - wangting supergroup 0 2021-06-10 10:31 /spark-history
drwxr-xr-x - wangting supergroup 0 2021-06-10 10:39 /spark-jars
drwxr-xr-x - wangting supergroup 0 2021-06-10 11:11 /student
drwxr-xr-x - wangting supergroup 0 2021-04-04 11:07 /test.db
drwxr-xr-x - wangting supergroup 0 2021-03-19 11:14 /testgetmerge
drwxr-xr-x - wangting supergroup 0 2021-04-10 16:23 /tez
drwx------ - wangting supergroup 0 2021-04-02 15:14 /tmp
drwxr-xr-x - wangting supergroup 0 2021-04-02 15:25 /user
drwxr-xr-x - wangting supergroup 0 2021-06-10 11:43 /warehouse
wangting@ops01:/opt/module/spark-standalone/conf >hdfs dfs -mkdir /directory
2021-07-23 15:25:14,573 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
wangting@ops01:/opt/module/spark-standalone/conf >hdfs dfs -ls / | grep directory
drwxr-xr-x - wangting supergroup 0 2021-07-23 15:25 /directory
# ��spark-env����
wangting@ops01:/opt/module/spark-standalone/conf >vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://ops01:8020/directory
-Dspark.history.retainedApplications=30"
wangting@ops01:/opt/module/spark-standalone/conf >
# �ַ������ļ�
wangting@ops01:/opt/module/spark-standalone/conf >scp spark-env.sh spark-defaults.conf ops02:/opt/module/spark-standalone/conf/
wangting@ops01:/opt/module/spark-standalone/conf >scp spark-env.sh spark-defaults.conf ops03:/opt/module/spark-standalone/conf/
wangting@ops01:/opt/module/spark-standalone/conf >scp spark-env.sh spark-defaults.conf ops04:/opt/module/spark-standalone/conf/
# ������ʷ����
wangting@ops01:/opt/module/spark-standalone >sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/module/spark-standalone/logs/spark-wangting-org.apache.spark.deploy.history.HistoryServer-1-ops01.out
wangting@ops01:/opt/module/spark-standalone >
# �ٴ�ִ��һ������
wangting@ops01:/opt/module/spark-standalone >bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://ops01:7077 --executor-memory 8G --total-executor-cores 4 /opt/module/spark-standalone/examples/jars/spark-examples_2.11-2.1.1.jar 20
ͨ��ip:18080������ʷ����ҳ��
http://11.8.37.50:18080/
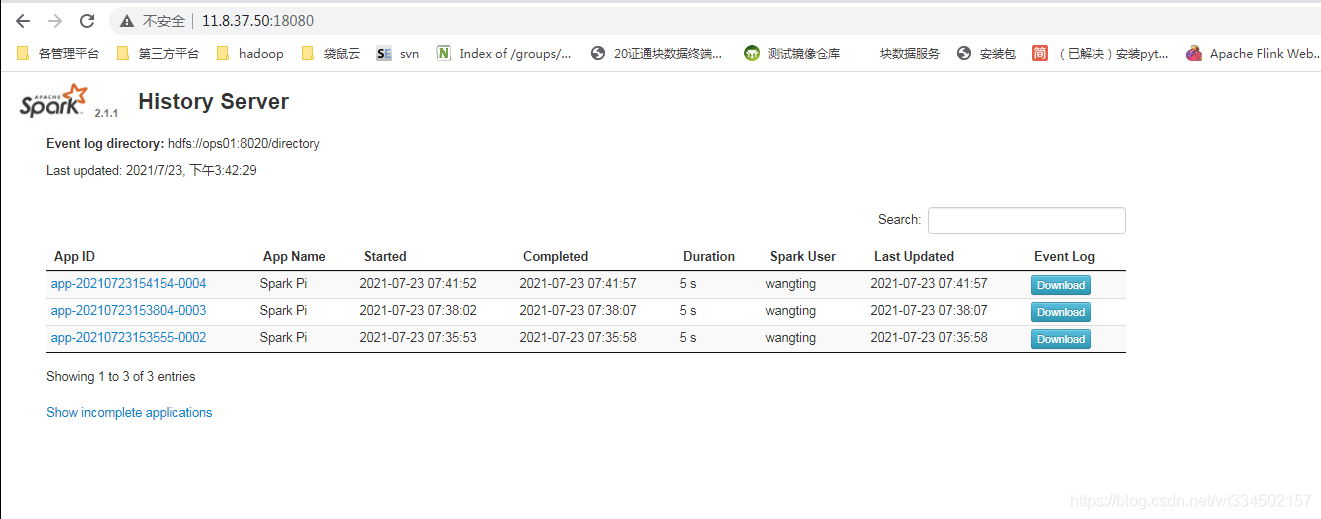
��Ϊ����standalone��ʵ��ʹ��,�ݲ����Ǹ߿�����ز���,�߿���ʡ��,��ʽ����һ����ڼ�������ʹ��yarnģʽΪ��,������mesosģʽ
Yarnģʽ����ʹ�ý���
yarnģʽ ��Ҫ��ǰ��hadoop��Ⱥ,hdfs�Լ�yarn��Ⱥ;��֮ǰ����������д������ʽ :��hadoop���ܲ����ĵ���
| ���� | ops01(8C32G) | ops02(8C24G) | ops03(8C24G) | ops04(8C24G) | version |
|---|---|---|---|---|---|
| Hdfs | NameNode | Datanode | SecondaryNameNode | Datanode | 3.1.3 |
| Yarn | NodeManager | ReSourceManager / NodeManager | NodeManager | NodeManager | 3.1.3 |
| MapReduce | �� JobHistoryServer | �� | �� | �� | 3.1.3 |
ֹͣStandaloneģʽ�µ�spark��Ⱥ
wangting@ops01:/opt/module/spark-standalone >sbin/stop-all.sh
ops01: stopping org.apache.spark.deploy.worker.Worker
ops04: stopping org.apache.spark.deploy.worker.Worker
ops03: stopping org.apache.spark.deploy.worker.Worker
ops02: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master
wangting@ops01:/opt/module/spark-standalone >
��ѹspark��������
wangting@ops01:/opt/module/spark-standalone >cd /opt/software/
wangting@ops01:/opt/software >tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
wangting@ops01:/opt/software >cd /opt/module/
wangting@ops01:/opt/module >mv spark-2.1.1-bin-hadoop2.7 spark-yarn
wangting@ops01:/opt/module >cd spark-yarn/
������spark-env
�������������:YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop ( ����hadoop��װ����·�� )
wangting@ops01:/opt/module/spark-yarn >cd conf/
wangting@ops01:/opt/module/spark-yarn/conf >mv spark-env.sh.template spark-env.sh
wangting@ops01:/opt/module/spark-yarn/conf >vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
����HDFS��YARN
ȷ��������HDFS�Լ�YARN��Ⱥ(��hadoop/sbin/Ŀ¼������)
��һ��ÿ��������һ��,ȡ�����Լ����ز���������,ÿ�������master���ĸ���������
wangting@ops01:/opt/module/hadoop-3.1.3 >sbin/start-dfs.sh
Starting namenodes on [ops01]
Starting datanodes
Starting secondary namenodes [ops03]
wangting@ops02:/opt/module/hadoop-3.1.3/sbin >./start-yarn.sh
Starting resourcemanager
Starting nodemanagers
�ٷ�demoʾ����Բ����Pi
wangting@ops01:/opt/module/spark-yarn >bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
/opt/module/spark-yarn/examples/jars/spark-examples_2.11-2.1.1.jar \
20
2021-07-26 11:41:56,166 INFO spark.SparkContext: Running Spark version 2.1.1
2021-07-26 11:41:56,606 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2021-07-26 11:41:56,784 INFO spark.SecurityManager: Changing view acls to: wangting
2021-07-26 11:41:56,784 INFO spark.SecurityManager: Changing modify acls to: wangting
2021-07-26 11:41:56,785 INFO spark.SecurityManager: Changing view acls groups to:
2021-07-26 11:41:56,786 INFO spark.SecurityManager: Changing modify acls groups to:
2021-07-26 11:41:56,786 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(wangting); groups with view permissions: Set(); users with modify permissions: Set(wangting); groups with modify permissions: Set()
2021-07-26 11:42:21,960 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 0.933 s
2021-07-26 11:42:21,965 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.150791 s
Pi is roughly 3.139429569714785 # <<< ������
2021-07-26 11:42:21,976 INFO server.ServerConnector: Stopped Spark@61edc883{HTTP/1.1}{0.0.0.0:4040}
2021-07-26 11:42:21,977 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6063d80a{/stages/stage/kill,null,UNAVAILABLE,@Spark}
2021-07-26 11:42:21,977 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5ae76500{/jobs/job/kill,null,UNAVAILABLE,@Spark}
2021-07-26 11:42:22,010 INFO cluster.YarnClientSchedulerBackend: Stopped
2021-07-26 11:42:22,015 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2021-07-26 11:42:22,027 INFO memory.MemoryStore: MemoryStore cleared
2021-07-26 11:42:22,027 INFO storage.BlockManager: BlockManager stopped
2021-07-26 11:42:22,033 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2021-07-26 11:42:22,037 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2021-07-26 11:42:22,038 INFO spark.SparkContext: Successfully stopped SparkContext
2021-07-26 11:42:22,040 INFO util.ShutdownHookManager: Shutdown hook called
2021-07-26 11:42:22,041 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-d3cf3aec-be6f-41f0-a950-4521641e6179
�鿴��Ⱥyarn resourcemanager 8088�˿�
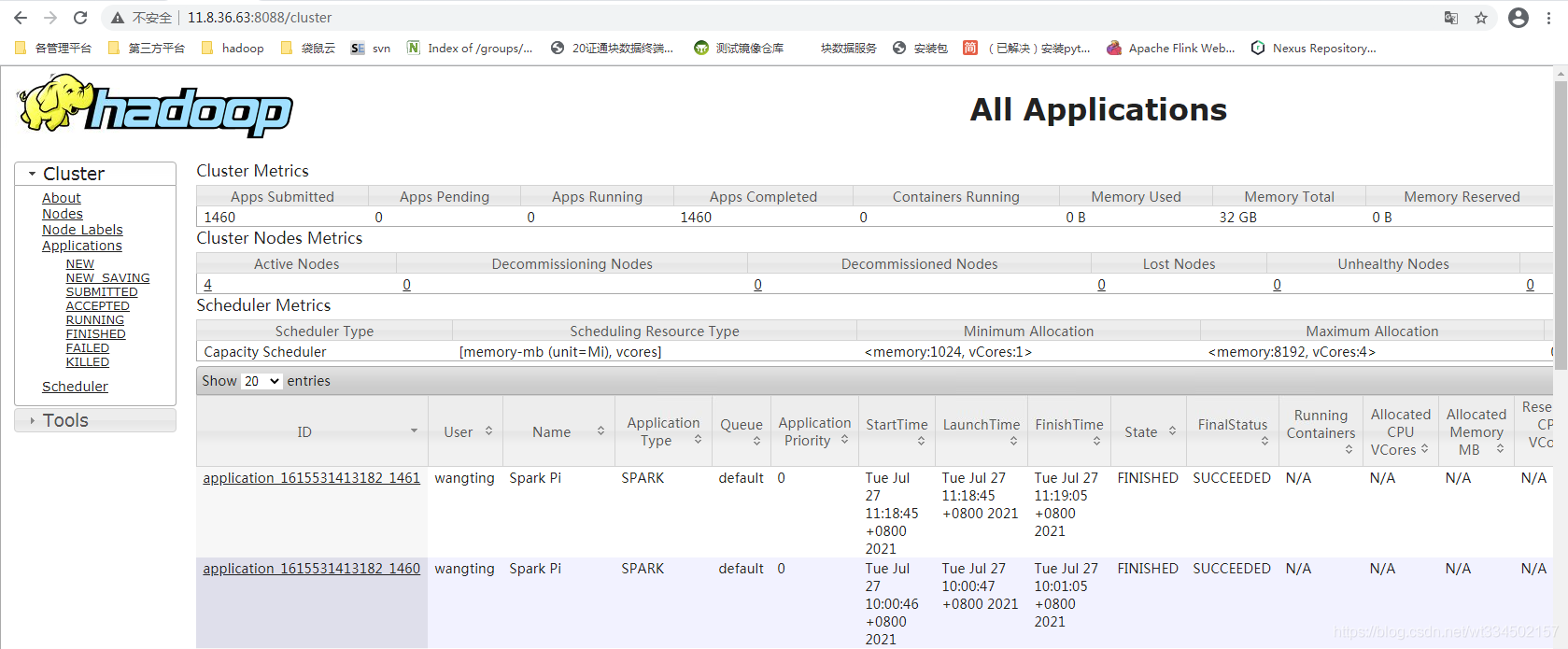
���Կ�����ʷ��ҵ��¼
spark-yarn��������
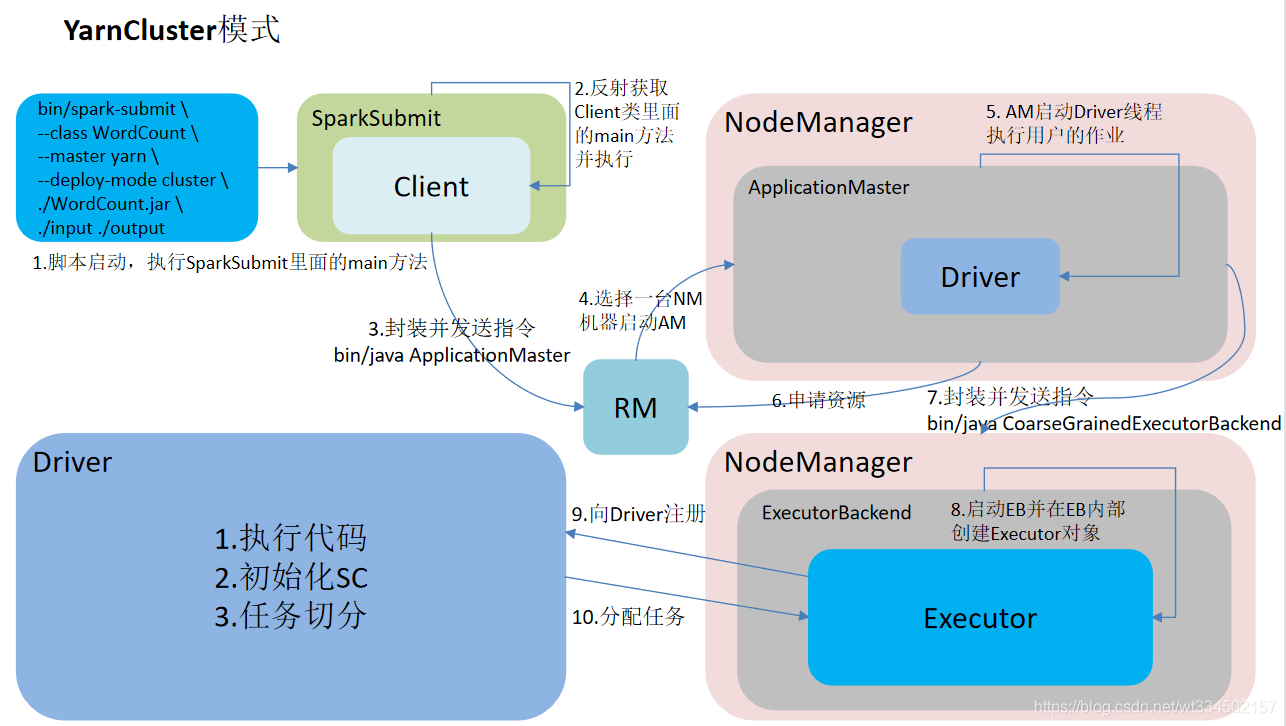
Spark��yarn-client��yarn-cluster����ģʽ,��Ҫ��������:Driver��������нڵ㡣
yarn-client:Driver���������ڿͻ���,�����ڽ���������,ϣ����������app�������
yarn-cluster:Driver������������ResourceManager������APPMaster����������������
�ͻ���ģʽ
wangting@ops01:/opt/module/spark-yarn >bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10
�ڿ���̨�������ֱ�ӿ���������
Clientģʽ��������

��Ⱥģʽ
wangting@ops01:/opt/module/spark-yarn >bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10
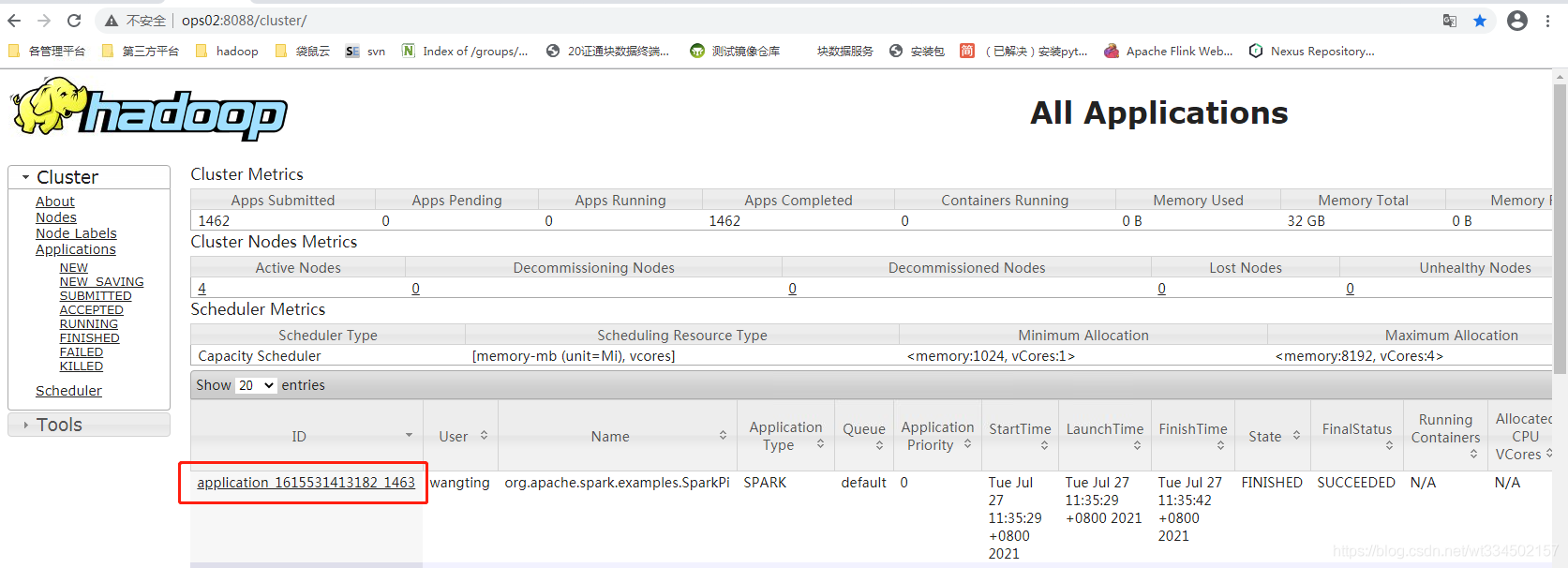
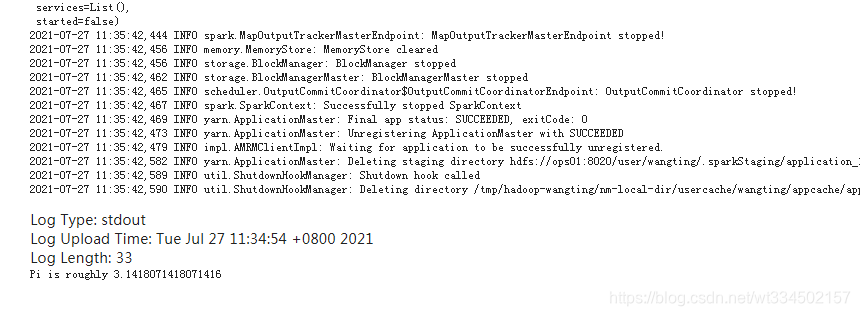
���ȥ����,����־������ǿ��Կ������յ�Pi���
Clusterģʽ��������
����sparkģʽ�Ա�( ������mesos )
| ģʽ | Spark��װ������ | �������Ľ��� | ������ |
|---|---|---|---|
| Localģʽ | 1 | �� | Spark |
| Standaloneģʽ | 3 | Master��Worker | Spark |
| Yarnģʽ | 1 | �������� Yarn��HDFS | Hadoop |
Spark�˿�����
1)Spark��ʷ�������˿ں�:18080 (�����Hadoop��ʷ�������˿ں�:19888)
2)Spark Master Web�˿ں�:8080(�����Hadoop��NameNode Web�˿ں�:9870(50070))
3)Spark Master�ڲ�ͨ�ŷ���˿ں�:7077 (�����Hadoop��8020 ( 9000 )�˿�)
4)Spark�鿴��ǰSpark-shell������������˿ں�:4040
5)Hadoop YARN������������鿴�˿ں�:8088
���ؿ�������+wordcount����
�Ȱ�װidea�����������,��װjava������scala������idea����maven�����ȵ�������,�����аٶȡ�
? Spark Shell���ڲ��Ժ���֤���ǵij���ʱʹ�õĽ϶�,������������,ͨ������IDE�б��Ƴ���,Ȼ����Jar��,Ȼ���ύ����Ⱥ,��õ��Ǵ���һ��Maven��Ŀ,����Maven������Jar����������
�����
1)����һ��Maven��Ŀ
2)��һЩwordcount�ز�
3)������Ŀ����
pom.xml�ļ�
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wangting</groupId>
<artifactId>spark_wt_test</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<finalName>WordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
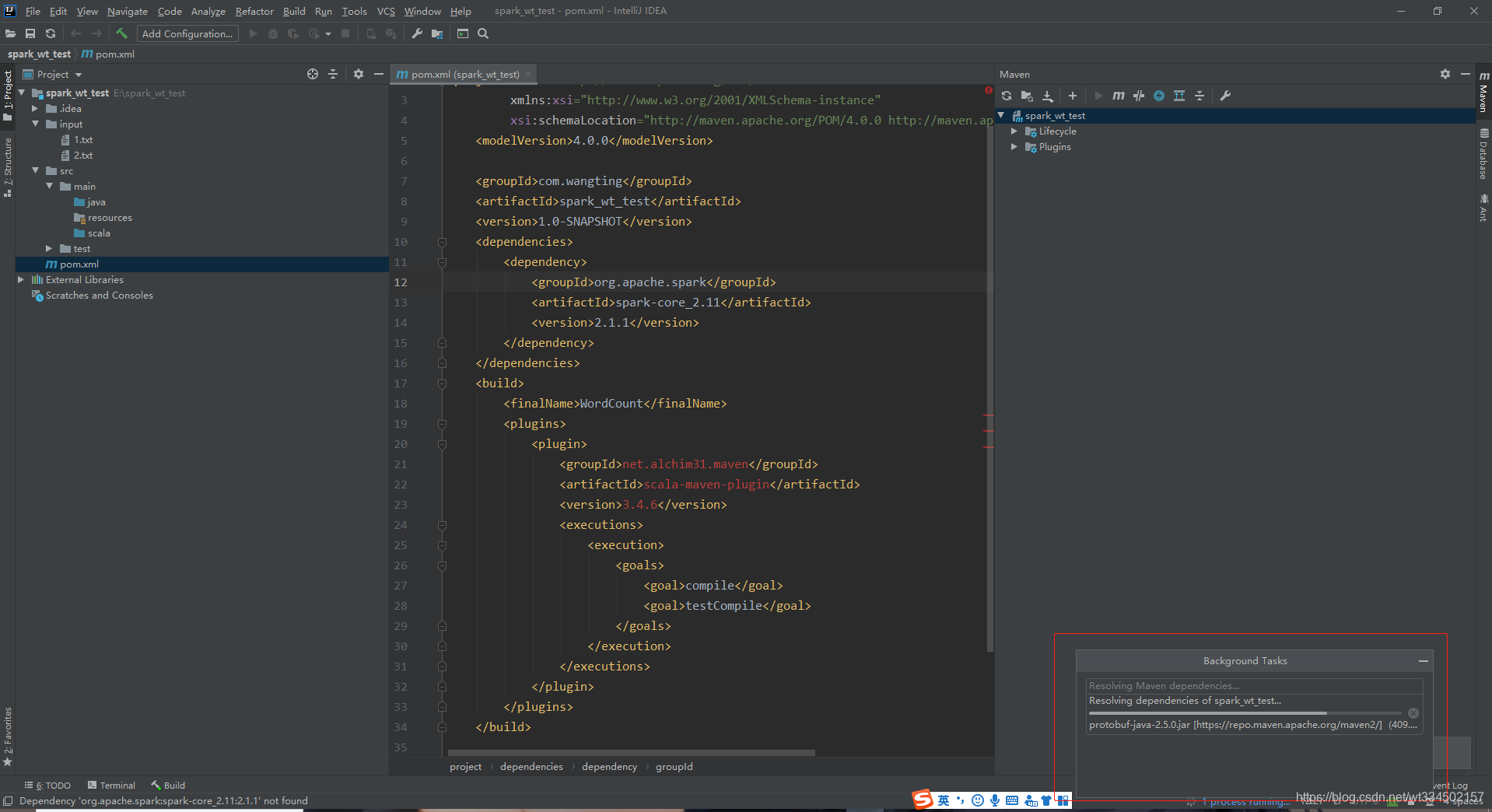
��ע�⡿:
- �½�����ĿΪmaven��Ŀ,��Ŀ���ƿ��Զ���
- ����ĿĿ¼���½�inputĿ¼,��inputĿ¼���½�1.txt ; 2.txt ������������Դ
? 1.txt
hello niubi
nihao niubiplus
scala niubi
spark niubi scala spark
? 2.txt
hello wangting
nihao wang
scala ting
spark wangting scala spark
- ��pom.xml�м�������ú�,����ұߵ�maven�������,��ʱ�����һ�����������Ĺ���,���ĵȴ��������
- ��src/main�д���scalaĿ¼,�Ҽ�mark directory as �ij�root,��ɫ��java��ͬ
- ��scala���½�һ��package: com.wangting.spark ;��������Զ���
- ��com.wangting.spark �����½�һ��Scala class ; ����Ϊ:WordCount,����ΪObject
package com.wangting.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//����SparkConf�����ļ�
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//����SparkContext����
val sc: SparkContext = new SparkContext(conf)
//sc.textFile("").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
//��ȡ�ⲿ�ļ�
val textRDD: RDD[String] = sc.textFile("E:\\spark_wt_test\\input\\1.txt")
//�Զ�ȡ�������ݽ����и���б�ƽ������
val flatMapRDD: RDD[String] = textRDD.flatMap(_.split(" "))
//�����ݼ��е����ݽ��нṹ��ת�� ---����
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))
//����ͬ�ĵ��� ���ֵĴ������л���
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
//��ִ�еĽṹ�����ռ�
val res: Array[(String, Int)] = reduceRDD.collect()
res.foreach(println)
/* //����SparkConf�����ļ�
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//����SparkContext����
val sc: SparkContext = new SparkContext(conf)
//һ�д���㶨
sc.textFile(args(0)).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile(args(1))
*/
//�ͷ���Դ
sc.stop()
}
}
xml���Ӵ��package����
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>com.wangting.spark.WordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
ע��plugin���÷���λ�� build - plugins - plugin
��������
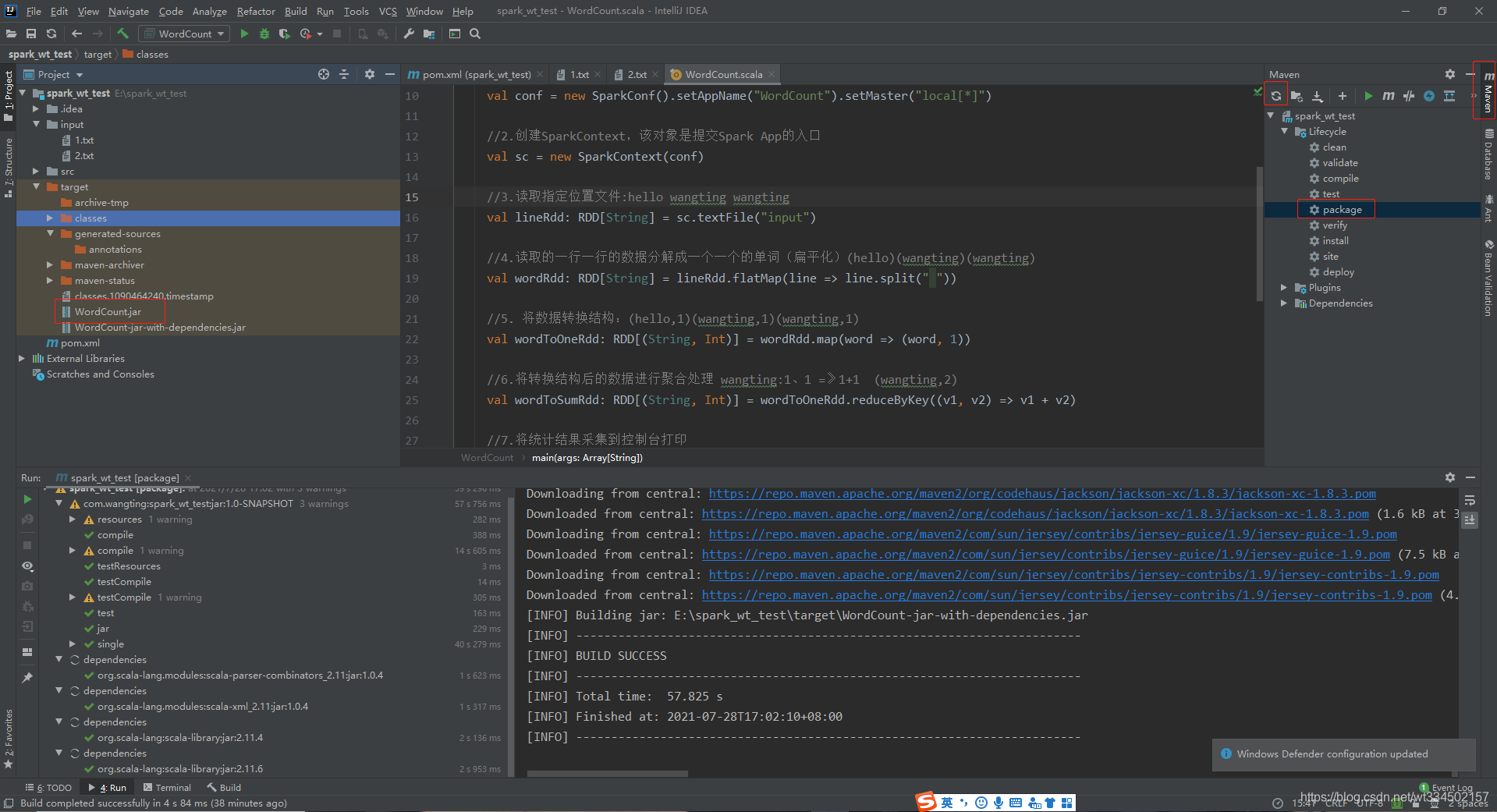
��ע�⡿:
����ֻ��һ��������������,ÿһ��ʵ�ʳ����б�Ȼ�Dz�һ����,����ֻ������Ϥ�����Ĺ��̾�����Щ����
-
��idea������maven����
-
����һ��maven��Ŀ
-
��Ŀ�п��Դ���һ��inputĿ¼,��дһЩ�ز����ȥhdfs��ȡ���������Դ���
-
��src/main��Ҳ����һ������ͬjava��Ŀ¼scala( Sources Root )
-
ע��pom�ļ��е�������������,���������������Ϸ������ҵ�maven,�㿪�ҵ���һ�����Ƹ��µİ�ť,��ȥ������ȥ���ص�����
-
���Ѵ���ά������������scala����
-
��������maven�е�Lifecycleѡ��,ʹ��package���
-
�����ɺ�,����ĿĿ¼�»���һ��targetĿ¼;��������Ϊpom�ж����:WordCount,����û�����������һ��WordCount.jar��
-
����jar��������������,ȥ����jar��,�������������������
����Դ��
1.��������spark-2.1.1Դ��zip��,��ѹ������
2.��idea�������ctrl�㷽���ȹ�������Դ��ʱ,����ʾDownload Sources / ChooseSources
3.ѡ��ChooseSources ,��·��ѡ����ѡ���ѹ��sparkԴ��Ŀ¼·��
4.������Ӧ·����,���ok���뼴���
����ִ�в��ְ汾��������
��汾����,�����������ϵͳ��Windows,����ڳ�����ʹ����Hadoop��صĶ���,����д���ļ���HDFS,������������쳣
21/07/29 10:07:41 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76)
at org.apache.hadoop.mapred.FileInputFormat.setInputPaths(FileInputFormat.java:362)
at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$29.apply(SparkContext.scala:1013)
at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$29.apply(SparkContext.scala:1013)
at org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:179)
at org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:179)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.rdd.HadoopRDD.getJobConf(HadoopRDD.scala:179)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:198)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
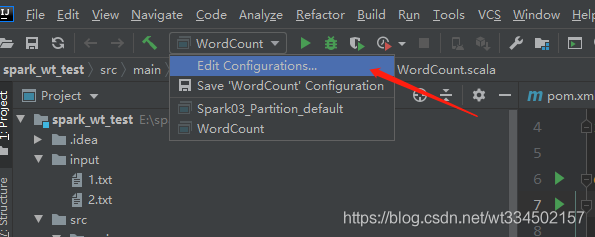
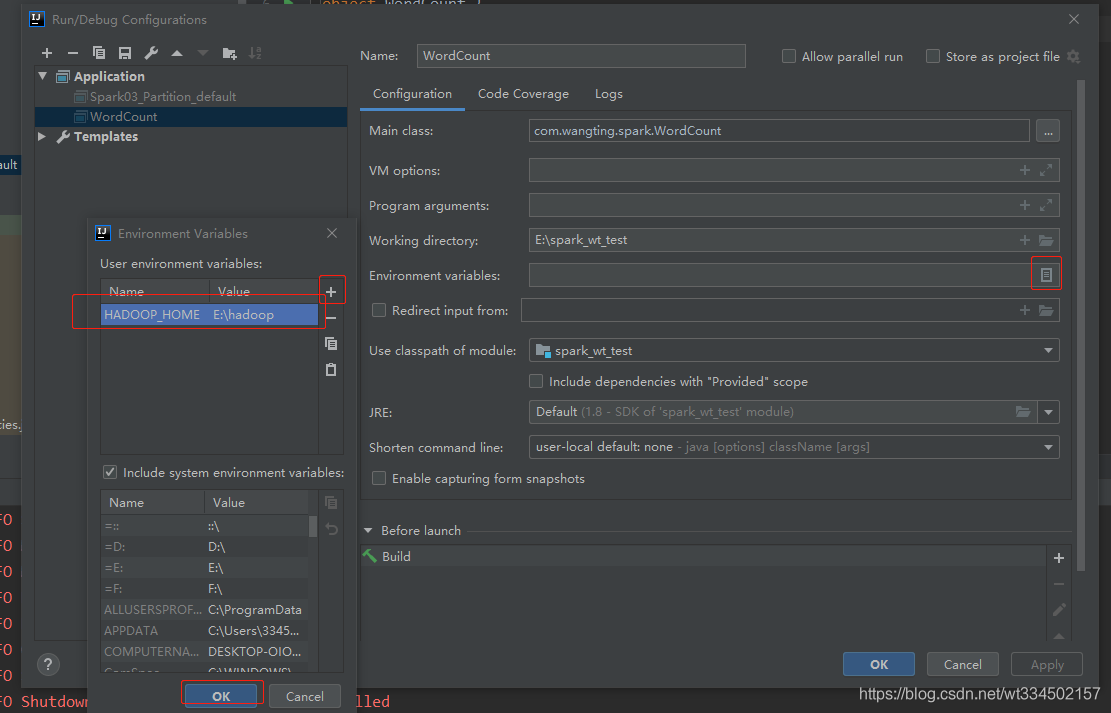
��ע�⡿:ֻ��Ҫ����������һ������,ʵ��·���Ƿ���hadoop�����ؽ�Ҫ,��֤���������,�������߹�ȥ����,��Ϊʵ�ʴ������ʱ,���ñ��صľ�̬�ļ�
�����������˻���������: