ElasticSearch���
Elasticsearch����Java���������ǵ�ǰ�����еĿ�Դ����ҵ���������档 �ܹ��ﵽʵʱ����,�ȶ�,�ɿ�,����,��װʹ�÷��㡣
�ͻ���֧��Java��.NET(C#)��PHP��Python��Ruby�ȶ������ԡ�
Ӧ�ó���
�����ǰٶ��������Ĵ���,�̳���������Ʒ�ؼ��ֵȶ���ͨ��ES��������ȥ���IJ�ѯ��
ElasticSearch��Lucene
Lucene���Ա���Ϊ������Ϊֹ���Ƚ���������õġ�������ȫ�����������(�� ��)
Luceneȱ��:
- 1)ֻ����Java��Ŀ��ʹ��,����Ҫ��jar���ķ�ʽֱ�Ӽ�����Ŀ��.
- 2)ʹ�÷dz�����-���������������������뷱��
- 3)��֧�ּ�Ⱥ����-�������ݲ�ͬ��(��֧�ִ�����Ŀ)
- 4)�����������̫��Ͳ���,�������Ӧ������ͬһ��������,��ͬռ��Ӳ ��.���ÿռ���.
���ǿ��������ES�ǻ���Lucene��ʵ�ֵķֲ�ʽ��������,���Lucene��˵,ES�Ĺ��ܸ���ǿ��,�ɲ����Ե�api���Ӽ�
����ES vs Solr�Ƚ�
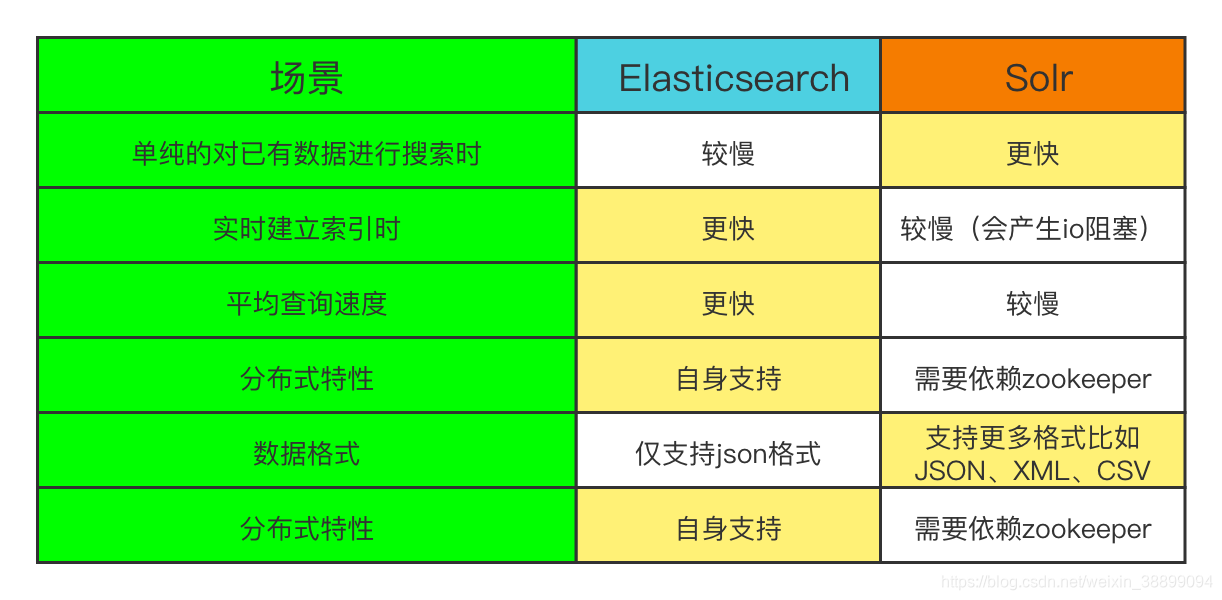
ES ȫ�ļ����ͷִ�ԭ��
ȫ�ļ���:
�����ڴ��������Ͳ�ѯ�����Ĺ�����,�����������һ���ı�����,�����ؼ������ı���λ�úͳ��ִ����������ڲ�ѯʱ,ͬ�����������йؼ���,���ݹؼ�������ȥ������(��������),��ȥ��ȡ��Ӧ��������ϸ��Ϣ��
�ִ�ԭ���ǻ��ڵ���������
������������:
�������� -> ���ݷִ�(��¼�ı�λ��,�ͳ��ִ���) -> ��������ֵȥ�� -> ��������
��ѯ��������:
�������� -> ���ݷִ� -> ���ݴ�����ȡ index�±� -> ��ѯ��������
��������: ���ݴ���Ѱ��index��
ͨ�������Ǹ���indexȥ��ѯ���ݡ�
�������ElasticSearch
ElasticSearch���Կ���һ�����ݿ�,һ���ǹ�ϵ�����ݿ�,����֧�ֵ����ݸ�ʽ��json����Ҳ���Լ����ӻ��ͻ���,����Ҳ����ͨ��api�ʹ��������е��á�
ES ��ϵ�����ݿ�

ES����İ�װ������
��װ
ע: ES�Ƕ��ڴ�Ҫ��Ƚϸߵ�,Ĭ����1G,���������ݻ���ص��ڴ�
ES����ʹ��root�û�������,����ʹ����ͨ�û�����װ������Ϊ�˰�ȫ������ʹ��root�û�������
��̨��������ʽ ./Ŀ���ļ� -d
��������ص��� elasticsearch-7.6.1-linux-x86_64.tar.gz
# ����·�� �ҷŵ�·���� mkdir /usr/local/es/
# ��ѹ��װ
[root@10-9-44-97 es]# tar -zvxf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/es/
# ����es����
[root@10-9-44-97 es]# groupadd es
# �����û�
[root@10-9-44-97 es]# useradd esuser
# �����û�����
[root@10-9-44-97 es]# passwd esuser
# �� esuser �û����ӵ� es �û���
[root@10-9-44-97 es]# usermod -G es esuser
[root@10-9-44-97 es]# chown -R esuser /usr/local/es/*
#����Ȩ��
[root@10-9-44-97 es]# visudo
#��root ALL=(ALL) ALL һ������
#���� esuser �û� ����:
esuser ALL=(ALL) ALL
#�л��� esuser�û�
[root@10-9-44-97 es]# su esuser
[esuser@10-9-44-97 es]$
#������־����ļ�
[esuser@10-9-44-97 es]$ mkdir �\p /usr/local/es/elasticsearch�\7.6.1/log
#�������ݴ���ļ�
[esuser@10-9-44-97 es]$ mkdir �\p /usr/local/es/elasticsearch�\7.6.1/data
[esuser@10-9-44-97 es]$ cd /usr/local/es/elasticsearch�\7.6.1/config
[esuser@10-9-44-97 es]$ vim elasticsearch.yml
elasticsearch.yml �����ļ�
�������õĶ��ִ���,ֱ��ճ�����ܻ���ڸ�ʽ����
# ======================== Elasticsearch Configuration =========================
# es������ģ��
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# ��Ⱥ����
cluster.name: es-tx
#
# ------------------------------------ Node ------------------------------------
# �����Լ��ڵ�����
node.name: node-tx-1
#
# Add custom attributes to the node:
# �Զ���Ľڵ�����
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
# ������ݵ�Ŀ¼·��(���λ��֮���ö��Ÿ���):
path.data: /usr/local/es/elasticsearch�\7.6.1/data
#
# Path to log files:
# ��־�ļ�
path.logs: /usr/local/es/elasticsearch�\7.6.1/log
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
# �����Ƿ������ڴ� es���ڴ��ռ�û��Ǵ�� ��������ڴ��л����dz�����
#bootstrap.memory_lock: true
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
# ���ð�ַΪָ��IP��ַ(IPv4��IPv6):
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
# ���ö˿ں�
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
# ��Ⱥ�ķ�����
discovery.seed_hosts: ["������ip"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
# ��Ⱥ��ʼ���ڵ�
cluster.initial_master_nodes: ["node����"]
#�Ƿ�֧�ֿ���,Ĭ��Ϊfalse
http.cors.enabled: true
#��������������,Ĭ��Ϊ*,��ʾ֧����������,�������ֻ������ijЩ��վ�ܷ���,��ô����ʹ���������ʽ������ֻ�������ص�ַ�� /https?:\/\/localhost(:[0-9]+)?/
http.cors.allow�\origin: "*"
��jvm.option
�����Լ��������ڴ��С������jvm���ڴ��С��esĬ�϶Ѵ�С��1g,���������Դ�Ƚϳ�ԣ,���Ե�����2g��
vim /usr/local/es/elasticsearch�\7.6.1/config/jvm.options
�\Xms2g
�\Xmx2g
����ES����
#ֱ�Ӻ�̨���� binĿ¼�� elasticsearch
[esuser@10-9-44-97 es]$ ./usr/local/es/elasticsearch-7.6.1/bin/elasticsearch -d
#���������ǿ��Բ�ѯ�º�̨
[esuser@10-9-44-97 elasticsearch-7.6.1]$ ps -ef |grep elasticsearch
esuser 44951 1 19 15:00 pts/0 00:00:17 /usr/local/es/elasticsearch-7.6.1/jdk/bin/java -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dio.netty.allocator.numDirectArenas=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.locale.providers=COMPAT -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Djava.io.tmpdir=/tmp/elasticsearch-6367305308402663350 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=data -XX:ErrorFile=logs/hs_err_pid%p.log -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m -XX:MaxDirectMemorySize=268435456 -Des.path.home=/usr/local/es/elasticsearch-7.6.1 -Des.path.conf=/usr/local/es/elasticsearch-7.6.1/config -Des.distribution.flavor=default -Des.distribution.type=tar -Des.bundled_jdk=true -cp /usr/local/es/elasticsearch-7.6.1/lib/* org.elasticsearch.bootstrap.Elasticsearch -d
esuser 45014 44951 0 15:00 pts/0 00:00:00 /usr/local/es/elasticsearch-7.6.1/modules/x-pack-ml/platform/linux-x86_64/bin/controller
esuser 46836 44424 0 15:01 pts/0 00:00:00 grep --color=auto elasti
�Լ��ķ������˿ں�һ��Ҫ����Ӧ�Ķ˿�,����http.port: 9200 ����Ҫ�ѷ�������Ӧ�˿�Ҳ��,һ�㰢���ƺ���Ѷ�ƶ������ڰ�ȫ�������ö˿�,Ҳ����ͨ������linux����ǽ����ʽ��
�˿ڴ� ���Է��� http://������ip:�˿�/
���ܿ��������Լ� es��һЩ��Ϣ
{
"name" : "xt-node1",
"cluster_name" : "xt-es",
"cluster_uuid" : "_na_",
"version" : {
"number" : "7.6.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b",
"build_date" : "2020-02-29T00:15:25.529771Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
����������
������Ϣ����:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
**ԭ��:**��������ڴ�̫С
ÿ�������������ֶ�ִ���¡�
- ִ����������
- �༭ /etc/sysctl.conf,
- ��������:vm.max_map_count=262144
- �����,ִ��:sysctl �\p
���ܻᱣ��ʧ��:
������sysctl: cannot stat /proc/sys/�Cp: No such file or directory
#����취
1�� modprobe br_netfilter
2�� ls /proc/sys/net/bridge
#�����ִ���¾Ϳ�����
3�� sysctl -p
ע��: ����ES��ʱ����� Permission denied
ԭ��:����ΪȨ������,
#���û���Ȩ
chown -R �������û��� �ļ�·��
chown -R esuser /usr/local/es/elasticsearch-7.6.1
��ע:���������֮��,��������xshell��Ч��
Kibana�ͻ��� - Elasticsearch���ӻ�����
Ϊ�˸��õIJ���elasticsearch,���ǰ�װ��Kibana�ͻ��ˡ�
��װ
ѡ��·�� /usr/local/es
��ѹ tar -zxvf kibana-X.X.X-linux-x86_64.tar.gz
���ǿ���ȥ��װ���ļ�Ŀ¼�� config��
���� kibana.yml
vi kibana.yml
# ��ǰes���ӻ��ͻ��˷���Ķ˿�
server.port: 5601
# ������ip �������� 0.0.0.0
server.host: "������ip"
# ������es�ķ�����
elasticsearch.hosts: ["http://es������ip:�˿�"]
����
ȷ���˿ڿ�����,����kibana,��Ȼ�ᱨ�˿ڴ���
# ����
./bin/kibana
�����ʽ
���� http://ip:�˿�/
�������ҳ���֤��kibana�ͻ��������ɹ���,��������Ҳ���õ�������ӻ�����ȥ��һЩ��ֱ�۵����ݲ�����
��ҿ��������������,��ʲô���ʻ�ӭ����~
��������,����������Լ���ͬʱ,����ϸ������ķ���,��л��λ���ߵ�:�������ղ�������,����һ�����~