背景
数据需求,要求计算各个维度下的用户数,并将数据落在目标表中,结果需要支持任意维度的筛选。
维度包括:平台(platform),是否新用户(is_new),年龄(age),人生阶段(life_stage),城市类型(city_class),省份名称(province_name),使用年限(use_age),当前APP版本(app_version_final),启动播放(start_play)。 启动播放维度涵盖:启动用户,播放用户,启动无播放用户,播放无启动用户。
数据举例:
| platform | is_new | age | life_stage | city_class | province_name | use_age | app_version_final | start_play | device_id |
|---|---|---|---|---|---|---|---|---|---|
| gphone | 0 | - | - | - | - | 1 | 9.12.6 | 播放用户 | 2 |
| gphone | 0 | 19-24岁 | 中学生 | C | 青海省 | 10 | 9.12.6 | 启动用户 | 3 |
| gphone | 0 | 36-40岁 | - | A- | 广东省 | 78 | 9.12.6 | 播放用户 | 6 |
| iphone | 0 | 31-35岁 | - | A- | 江苏省 | 726 | 9.12.6 | 启动用户 | 7 |
| iphone | 0 | 31-35岁 | 工作 | C | 江苏省 | 184 | 9.12.6 | 启动用户 | 8 |
| iphone | 0 | 31-35岁 | 工作 | D | 湖南省 | 849 | 9.12.6 | 启动用户 | 9 |
| iphone | 0 | 0-18岁 | 中学生 | A | 广东省 | - | 9.12.6 | 播放用户 | 10 |
| iphone | 0 | 0-18岁 | 中学生 | A | 广东省 | - | 9.12.6 | 播放无启动用户 | 10 |
| iphone | 0 | 31-35岁 | 工作 | A- | 辽宁省 | 199 | 9.7.0 | 启动用户 | 11 |
| iphone | 0 | 31-35岁 | 工作 | C | 湖北省 | 496 | 9.12.6 | 启动用户 | 12 |
| gphone | 0 | 36-40岁 | 工作 | D | 安徽省 | - | 9.12.0 | 启动用户 | 13 |
| gphone | 0 | - | - | - | - | - | 9.12.0 | 启动用户 | 14 |
| gphone | 0 | - | - | - | - | - | 9.12.0 | 启动无播放用户 | 14 |
| gphone | 0 | 36-40岁 | - | D | 黑龙江省 | 21 | 9.12.6 | 播放用户 | 19 |
| gphone | 0 | - | - | - | - | 4 | 9.12.6 | 启动用户 | 20 |
| iphone | 0 | 25-30岁 | 工作 | E | 贵州省 | 1093 | 9.5.8 | 播放用户 | 1 |
| iphone | 0 | 25-30岁 | 工作 | E | 贵州省 | 1093 | 9.5.8 | 播放无启动用户 | 1 |
分析需求之后,思考应该使用with cube语法,以实现支持任意维度的筛选,但是维度很多,使用with cube之后可能会出现数据量很大的情况,做测试后发现可以运行。
分析数据来源,base_data_tbl包含了除去start_play以外的所有数据,做一次join即可。
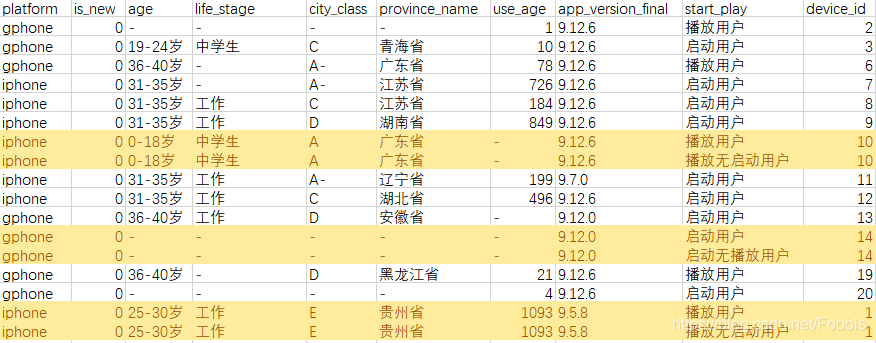
warning:除去启动播放这个维度,其他维度都是没有重叠的数据的,也就是一个用户不可能又属于新用户又不属于新用户,但是一个用户可能既是播放用户,也是播放无启动用户,所以加入这个维度之后,需要在with cube的聚合字段中加入distinct,才能保证数据的正确性
如下图标黄数据所示:
代码分析
首先按照我们最基础的思路写一下代码
WITH demo2 AS --创建临时表demo2,处理start_play维度信息,为join做准备
(
SELECT device_id
,'有启动无播放' AS start_play
FROM data_source_tbl
WHERE vv is null
AND start_num is not null
UNION ALL
SELECT device_id
,'有播放无启动' AS start_play
FROM data_source_tbl
WHERE vv is not null
AND start_num is null
UNION ALL
SELECT device_id
,'启动用户' AS start_play
FROM data_source_tbl
WHERE (vv is null AND start_num is not null) or (vv is not null AND start_num is not null)
UNION ALL
SELECT device_id
,'播放用户' AS start_play
FROM data_source_tbl
WHERE (vv is not null AND start_num is null) or (vv is not null AND start_num is not null)
)
INSERT OVERWRITE TABLE 目标表 partition(dt='2021-07-24')
SELECT nvl(A.platform,'ALL') AS platform
,nvl(A.is_new,'ALL') AS is_new
,nvl(A.age,'ALL') AS age
,nvl(A.life_stage,'ALL') AS life_stage
,nvl(A.city_class,'ALL') AS city_class
,nvl(A.province_name,'ALL') AS province_name
,nvl(A.use_age,'ALL') AS use_age
,nvl(A.app_version_final,'ALL') AS app_version_final
,nvl(B.start_play,'ALL') AS start_play
,COUNT(distinct A.device_id) AS dau -- 所有字段使用nvl是为了最终建表完成后做查询时候的清晰显示
FROM
( -- 这个子查询是为了将除了start_play以外的数据进行去重,使用了group by所有字段的方法
SELECT nvl(A.platform,'-') AS platform
,nvl(A.is_new,'-') AS is_new
,nvl(A.age,'-') AS age
,nvl(A.life_stage,'-') AS life_stage
,nvl(A.city_class,'-') AS city_class
,nvl(A.province_name,'-') AS province_name
,nvl(A.use_age,'-') AS use_age
,nvl(A.app_version_final,'-') AS app_version_final
,nvl(A.device_id,'-') AS device_id
FROM base_data_tbl A
WHERE A.dt='2021-07-24'
GROUP BY platform
,is_new
,age
,life_stage
,city_class
,province_name
,use_age
,app_version_final
,device_id
) A
LEFT JOIN demo2 B ON A.device_id = B.device_id
GROUP BY platform
,is_new
,age
,life_stage
,city_class
,province_name
,use_age
,app_version_final
,start_play WITH cube
这段代码看上去没有问题,但是运行就会发现,在一个reduce阶段会卡在76%不动,查了一下原因,发现是一个reducer要处理过多地distinct数据了,处理速度很慢,我等了4个小时,代码都没跑完…
这时候我尝试更改配置项优化,不是一个reduce不行么,我配置成10个,发现还是慢,我最后配了40个,代码如下:
-- 在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
-- 有数据倾斜的时候进行负载均衡(默认是 false)
set hive.groupby.skewindata = true;
-- 必须设置,否则无法开启这么大的grouping sets
SET hive.new.job.grouping.set.cardinality=1024;
-- 设置map和reduce的数量
set mapred.reduce.tasks=40;
set mapred.map.tasks= 9;
其余代码不变,再次运行3个小时可以跑出结果,但是还是太慢了,想要刷数据的话一天才能刷几次,不太行
代码优化
下一步就需要进行代码层面的优化了,能否将distinct去掉?
最常见的使用group by代替distinct方法在当前场景下不能使用,因为是在做with cube聚合
那就把不写distinct可能出错的情景拿出来,然后过滤掉就可以了
这里详细解释一下:为什么当前结果不用distinct会有问题?因为start_play这个筛选维度一个用户可能对应多个元素,在我们进行join操作之后,可能有一个用户存在多行的可能,例如出现
868894031715839 1 NULL 2021-07-20 播放用户
868894031715839 2 NULL 2021-07-20 有播放无登录
这样两条数据,在进行with cube计算的时候,如果不进行处理,计算结果就会有误。
例如我在做platform维度和is_new维度的聚合,其他维度设置为nvl中的默认值ALL,如果不处理,start_play维度中的ALL就对应着很多重复数据,所以我们要将这种可能性进行过滤
我第一次尝试是不写with cube,直接手写所有可能,然后发现不太现实,因为可能性太多了,写两页都写不完。第二次尝试成功了,代码如下
use qube_pps;
--在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
--有数据倾斜的时候进行负载均衡(默认是 false)
set hive.groupby.skewindata = true;
SET hive.new.job.grouping.set.cardinality=1024;
WITH demo2 AS
(
-- 注意这里将ALL作为一个当前维度的标签,将所有用户设置为这个标签
select device_id, 'ALL' as start_play
from data_source_tbl
union all
SELECT device_id
,'有启动无播放' AS start_play
FROM data_source_tbl
WHERE vv is null
AND start_num is not null
UNION ALL
SELECT device_id
,'有播放无启动' AS start_play
FROM data_source_tbl
WHERE vv is not null
AND start_num is null
UNION ALL
SELECT device_id
,'启动用户' AS start_play
FROM data_source_tbl
WHERE (vv is null AND start_num is not null) or (vv is not null AND start_num is not null)
UNION ALL
SELECT device_id
,'播放用户' AS start_play
FROM data_source_tbl
WHERE (vv is not null AND start_num is null) or (vv is not null AND start_num is not null)
)
INSERT OVERWRITE TABLE 目标表 partition(dt='2021-07-24')
select * from (
SELECT nvl(A.platform,'ALL') AS platform
,nvl(A.is_new,'ALL') AS is_new
,nvl(A.age,'ALL') AS age
,nvl(A.life_stage,'ALL') AS life_stage
,nvl(A.city_class,'ALL') AS city_class
,nvl(A.province_name,'ALL') AS province_name
,nvl(A.use_age,'ALL') AS use_age
,nvl(A.app_version_final,'ALL') AS app_version_final
,nvl(A.start_play,'ERR') AS start_play -- 一遇到start_play为ERR的情况就过滤掉,为了不让数据不全,上面临时表中加上了ALL字段以保证最终结果的正确性
,COUNT(A.device_id) AS dau
FROM
(
SELECT nvl(A.platform,'-') AS platform
,nvl(A.is_new,'-') AS is_new
,nvl(A.age,'-') AS age
,nvl(A.life_stage,'-') AS life_stage
,nvl(A.city_class,'-') AS city_class
,nvl(A.province_name,'-') AS province_name
,nvl(A.use_age,'-') AS use_age
,nvl(A.app_version_final,'-') AS app_version_final
,nvl(A.device_id,'-') AS device_id
,nvl(B.start_play,'-') as start_play
FROM base_data_tbl A
left join demo2 B on B.device_id=A.device_id
WHERE A.dt='2021-07-24'
) A
GROUP BY platform
,is_new
,age
,life_stage
,city_class
,province_name
,use_age
,app_version_final
,start_play
WITH cube
) t where start_play!='ERR' -- 过滤操作
最终代码运行时间为20-40分钟,极大优化了效率。
总结
通过对with cube的深入理解,删去了distinct造成的性能瓶颈,分析问题产生的原因然后进行了性能优化
