Kafka的学习与使用
一、Kafka简介
定义:
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。既然是消息队列,那么Kafka也就拥有消息队列的相应的特性了。
特点:
- 分区式(预分区)、分布式、多副本、多订阅者
- 消息持久化、高吞吐、分布式消费
- 消息传递模式:发布者kafkaProducer -kafka server-订阅者kafkaConsumer模式
- 耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能。
- 异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可。
- 高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。
架构理解:
- Producer:消息生产者,向Kafka中发布消息的角色。
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
- Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
二、生产者Producer
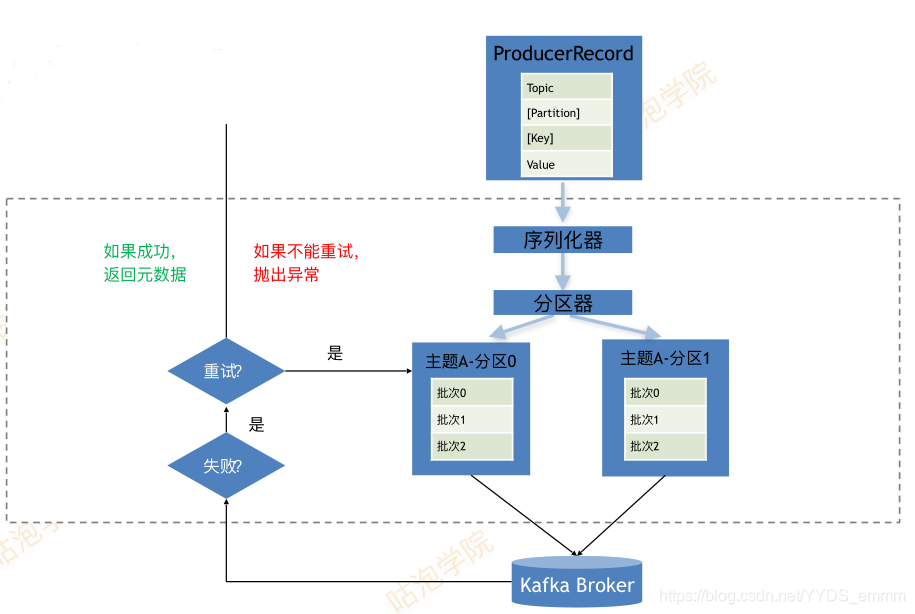
序列化器
- 内置序列列化器?(int/long/float/double/byte/string)
一般将message组织成标准的json字符串进行传递 - 自定义序列列化器?(实现org.apache.kafka.common.serialization.Serializer接?)
主题
- 一个Topic类似于hadoop中的一个文件
分区
- 创建消息时,指定分区
- 使?用默认的分区器?:DefaultPartitioner
key存在:hash(key) % numPartition
key不不存在:采?用round-robin算法,每个分区机会均等 - 自定义分区器
- 类似于hadoop中的block
- ???分区数量不超过集群数量
- 单分区内消息有序,分区内不能保证有序。如果需要消息绝对有序,分区数设置为1
顺序性和可靠性
- 顺序保证
max.in.flight.requests.per.connection = 1 :当前包未确认就不不能发送下?一个包从?而实现有序性 - 可靠性
acks = [0,1,all] : 不确认 / leader broker确认 / 所有相关的borker都确认
三、消费者Consumer
消费过程
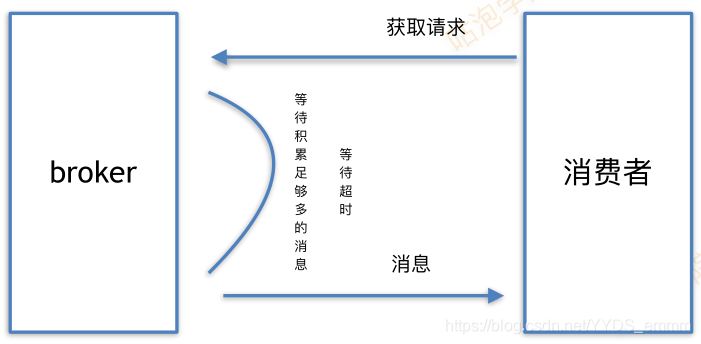
- fetch.min.bytes:获取最小字节数
- fetch.max.wait.ms:最长等待时间
- max.partition.fetch.bytes (从每个分区获取的最大字节数 )
- max.message.size: (borker能接收的最大消息字节数即单条消息的大小)如果单条消息比从分区获取的最大字节数大,那么将会照成一条数据也接收不到。
订阅主题
一个消费者可以同时订阅多个主题
- 订阅固定的topic
consumer.subscribe(Collections.singletonList(“gp_topic”)) - 动态订阅topic
consumer.subscribe(“gp.*”)
四、具体案例
4.1 JAVA写生产者、SPARK写消费者
生产者:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class KafkaKB12_01Producer {
public static void main(String[] args) throws IOException, ExecutionException, InterruptedException {
Properties config = new Properties();
//连接
config.setProperty("bootstrap.servers","192.168.64.180:9092");
//容错
config.setProperty("retries","2");
config.setProperty("acks","-1");
//批处理:满足一个都会推送消息
config.setProperty("batch.size","128"); //达到指定字节
config.setProperty("linger.ms","100"); //达到指定时间
//消息键值的序列化
config.setProperty("key.serializer","org.apache.kafka.common.serialization.LongSerializer");
config.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<Long,String> producer = new KafkaProducer<Long, String>(config);
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
long count = 0;
final String TOPIC ="kb12_01"; //发送的主题
final int PATITION =0; //指定主题的分区
while (true){
String input = reader.readLine();
if (input.equalsIgnoreCase("exit")){
break;
}
ProducerRecord<Long,String> record
= new ProducerRecord<Long, String>(TOPIC,PATITION,++count,input);
RecordMetadata rmd = producer.send(record).get();
System.out.println(rmd.topic()+"\t"+rmd.partition()+"\t"+rmd.offset()+"\t"+count+":"+input);
}
reader.close();
producer.close();
}
}
消费者:
import java.time.Duration
import java.util
import java.util.Properties
import org.apache.kafka.clients.consumer.KafkaConsumer
object kafkaKB12Consumer {
def main(args: Array[String]): Unit = {
val config = new Properties()
config.setProperty("bootstrap.servers","192.168.64.180:9092")
config.setProperty("key.deserializer","org.apache.kafka.common.serialization.LongDeserializer")
config.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
config.setProperty("group.id","kafka_kb12_02")
config.setProperty("enable.auto.commit","true")
config.setProperty("auto.offset.reset","earliest") //最早消息开始读
val topics = util.Arrays.asList("kb12_01")
val consumer:KafkaConsumer[Long,String] = new KafkaConsumer(config)
consumer.subscribe(topics)
try{
while (true){
//阻塞读取:5秒
consumer.poll(Duration.ofSeconds(5)).records("kb12_01").forEach(e=>{
println(s"${e.key()}\t${e.value()}")
})
}
}finally {
consumer.close()
}
}
}
42JAVA写生成者、SPARKSTREAM写消费者
生产者
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
public class KB12StockProducer {
public static void main(String[] args) {
//模拟股票的交易记录
//Long交易比数 Float该笔交易的金额
final Properties CONF = new Properties();
CONF.setProperty("bootstrap.servers","192.168.64.180:9092");
CONF.setProperty("key.serializer","org.apache.kafka.common.serialization.LongSerializer");
CONF.setProperty("value.serializer","org.apache.kafka.common.serialization.FloatSerializer");
CONF.setProperty("acks","1");
CONF.setProperty("retries","2");
CONF.setProperty("batch.size","10"); //达到指定字节
CONF.setProperty("linger.ms","500"); //达到指定时间
final String TOPIC= "stock_01";
final int PATITION= 0;
final KafkaProducer<Long, Float> producer = new KafkaProducer<>(CONF);
Random rand = new Random();
long count =0;
try{
while (true){
float value = 100 *rand.nextFloat();
Future<RecordMetadata> send = producer
.send(new ProducerRecord<Long, Float>(TOPIC, PATITION, ++count, value));
try {
RecordMetadata rmd = send.get();
System.out.println(rmd.topic()+"\t"+rmd.partition()+"\t"+rmd.offset()+"\t"+count+":"+value);
TimeUnit.MICROSECONDS.sleep(20+rand.nextInt(980));
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}finally {
producer.close();
}
}
}
消费者
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object StockSparkStream {
def main(args: Array[String]): Unit = {
//微批处理
val CONF = mutable.Map[String,String]()
CONF.put("bootstrap.servers","192.168.64.180:9092")
CONF.put("group.id","stock_kb12")
CONF.put("key.deserializer","org.apache.kafka.common.serialization.LongDeserializer")
CONF.put("value.deserializer","org.apache.kafka.common.serialization.FloatDeserializer")
CONF.put("enable.auto.commit","true")
CONF.put("auto.offset.reset","earliest")
val TOPICS = Array("stock_01")
val conf = new SparkConf().setMaster("local[*]").setAppName("kb12_stock")
//以时间作为数据粒度的控制手段每三秒
val context = new StreamingContext(conf,Seconds(3))
//LocationStrategies.PreferBrokers =>面向单节点:spark和kafka再同一个节点
/**
* LocationStrategies.PreferConsistent =>面向集群 :
* Master + n个workers(executor进程)
* 优先将 executor 启动在 kafka broker 节点上 减少数据迁移
*/
/**生产者发送记录键类型和值类型
* ConsumerStrategies.Subscribe[keyType,valueType]
* 主题列表 kafka消费端配置
* (topics:Iterable[String],conf:map[String,String])
*/
val stream: InputDStream[ConsumerRecord[Long,Float]] = KafkaUtils.createDirectStream(context,
LocationStrategies.PreferBrokers,
ConsumerStrategies.Subscribe[Long,Float](TOPICS, CONF))
stream.foreachRDD(rdd=>{
val value = rdd.map(_.value()).collect()
val avg = value.sum/value.size
println(s"${value.mkString(",")}\t$avg")
})
context.start()
context.awaitTermination()
}
}