一提到大数据,人们就会想到Hadoop,然而,最近又有个Spark似乎成了后起之秀,也变得很火,似乎比Hadoop更具优势,更有前景。那么这两种相爱相杀的技术,又存在什么区别和联系呢?
Spark
Spark是什么?
Spark是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLlib用于机器学习,Spark GraphX用于图计算。
Spark主要用于大数据的计算,而Hadoop以后主要用于大数据的存储(比如HDFS、Hive、HBase等),以及资源调度(Yarn)。
Spark整体架构
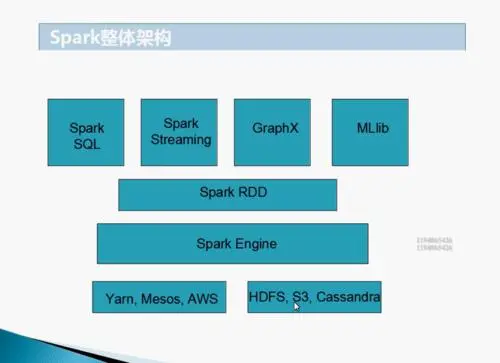
Spark的特点:
速度快:Spark基于内存进行计算(当然也有部分计算基于磁盘,比如shuffle)。
容易上手开发:Spark的基于RDD的计算模型,比Hadoop的基于Map-Reduce的计算模型要更加易于理解,更加易于上手开发,实现各种复杂功能,比如二次排序、topn等复杂操作时,更加便捷。
超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务。
集成Hadoop:Spark并不是要成为一个大数据领域的“独裁者”,一个人霸占大数据领域所有的“地盘”,而是与Hadoop进行了高度的集成,两者可以完美的配合使用。Hadoop的HDFS、Hive、HBase负责存储,YARN负责资源调度;Spark复杂大数据计算。实际上,Hadoop+Spark的组合,是一种“double win”的组合。
极高的活跃度:Spark目前是Apache基金会的顶级项目,全世界有大量的优秀工程师是Spark的committer。并且世界上很多顶级的IT公司都在大规模地使用Spark。
Hadoop是什么??
Hadoop是项目的总称。主要是由HDFS和MapReduce组成。HDFS是Google File System(GFS)的开源实现。MapReduce是Google MapReduce的开源实现。 具体而言,Apache Hadoop软件库是一个允许使用简单编程模型跨计算机集群处理大型数据集合的框架,其设计的初衷是将单个服务器扩展成上千个机器组成的一个集群为大数据提供计算服务,其中每个机器都提供本地计算和存储服务。
Hadoop的核心:
1.HDFS和MapReduce是Hadoop的两大核心。通过HDFS来实现对分布式储存的底层支持,达到高速并行读写与大容量的储存扩展。
2.通过MapReduce实现对分布式任务进行处理程序支持,保证高速分区处理数据。
MapReduce的计算模型分为Map和Reduce两个过程。在日常经验里,我们统计数据需要分类,分类越细、参与统计的人数越多,计算的时间就越短,这就是Map的形象比喻,在大数据计算中,成百上千台机器同时读取目标文件的各个部分,然后对每个部分的统计量进行计算,Map就是负责这一工作的;而Reduce就是对分类计数之后的合计,是大数据计算的第二阶段。可见,数据的计算过程就是在HDFS基础上进行分类汇总。
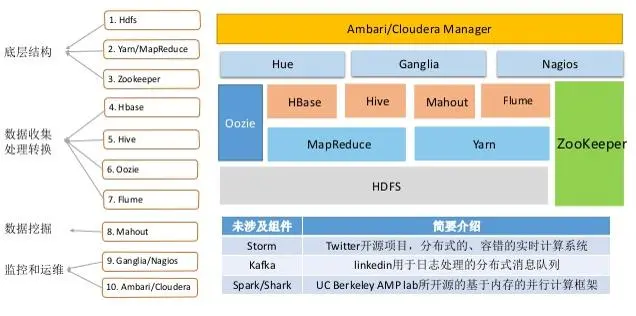
HDFS把节点分成两类:NameNode和DataNode。NameNode是唯一的,程序与之通信,然后从DataNode上存取文件。这些操作是透明的,与普通的文件系统API没有区别。
MapReduce则是JobTracker节点为主,分配工作以及负责和用户程序通信。
HADOOP和Spark的关系?
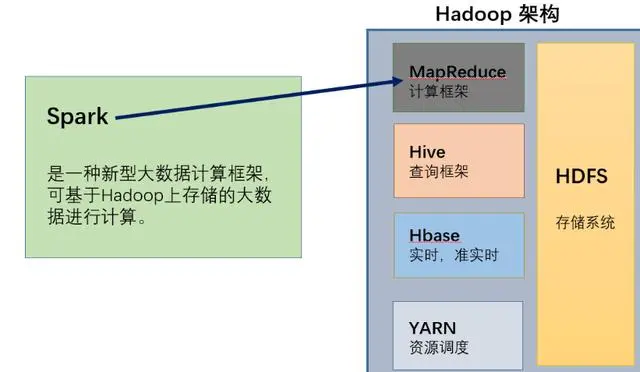
?
如上图所示,Hadoop和 Spark两者都是大数据框架,但是各自存在的目的不尽相同。Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储, 也有计算处理的功能。Spark,则是一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储。
Spark和Hadoop的区别和比较:
1.原理比较:
Hadoop和Spark都是并行计算,两者都是用MR模型进行计算
Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束;
Spark用户提交的任务称为application,一个application对应一个SparkContext,app中存在多个job,每触发一次action操作就会产生一个job。这些job可以并行或串行执行,每个job中有多个stage,stage是shuffle过程中DAGScheduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset,由TaskScheduler分发到各个executor中执行;executor的生命周期是和app一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算。
2.数据的存储和处理:
hadoop:
Hadoop实质上更多是一个分布式系统基础架构: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,同时还会索引和跟踪这些数据,大幅度提升大数据处理和分析效率。Hadoop 可以独立完成数据的存储和处理工作,因为其除了提供HDFS分布式数据存储功能,还提供MapReduce数据处理功能。
spark:
Spark 是一个专门用来对那些分布式存储的大数据进行处理的工具,没有提供文件管理系统,自身不会进行数据的存储。它必须和其他的分布式文件系统进行集成才能运作。可以选择Hadoop的HDFS,也可以选择其他平台。
3.处理速度:
hadoop:
Hadoop是磁盘级计算,计算时需要在磁盘中读取数据;其采用的是MapReduce的逻辑,把数据进行切片计算用这种方式来处理大量的离线数据.
spark:
Spark,它会在内存中以接近“实时”的时间完成所有的数据分析。Spark的批处理速度比MapReduce快近10倍,内存中的数据分析速度则快近100倍。
4.恢复性:
hadoop:
Hadoop将每次处理后的数据写入磁盘中,对应对系统错误具有天生优势。
spark:
Spark的数据对象存储在弹性分布式数据集(RDD:)中。“这些数据对象既可放在内存,也可以放在磁盘,所以RDD也提供完整的灾难恢复功能。
5.处理数据:
hadoop:
Hadoop适合处理静态数据,对于迭代式流式数据的处理能力差;
spark:
Spark通过在内存中缓存处理的数据,提高了处理流式数据和迭代式数据的性能;
6.中间结果:
hadoop:
Hadoop中中间结果存放在HDFS中,每次MR都需要刷写-调用,
spark:
而Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作