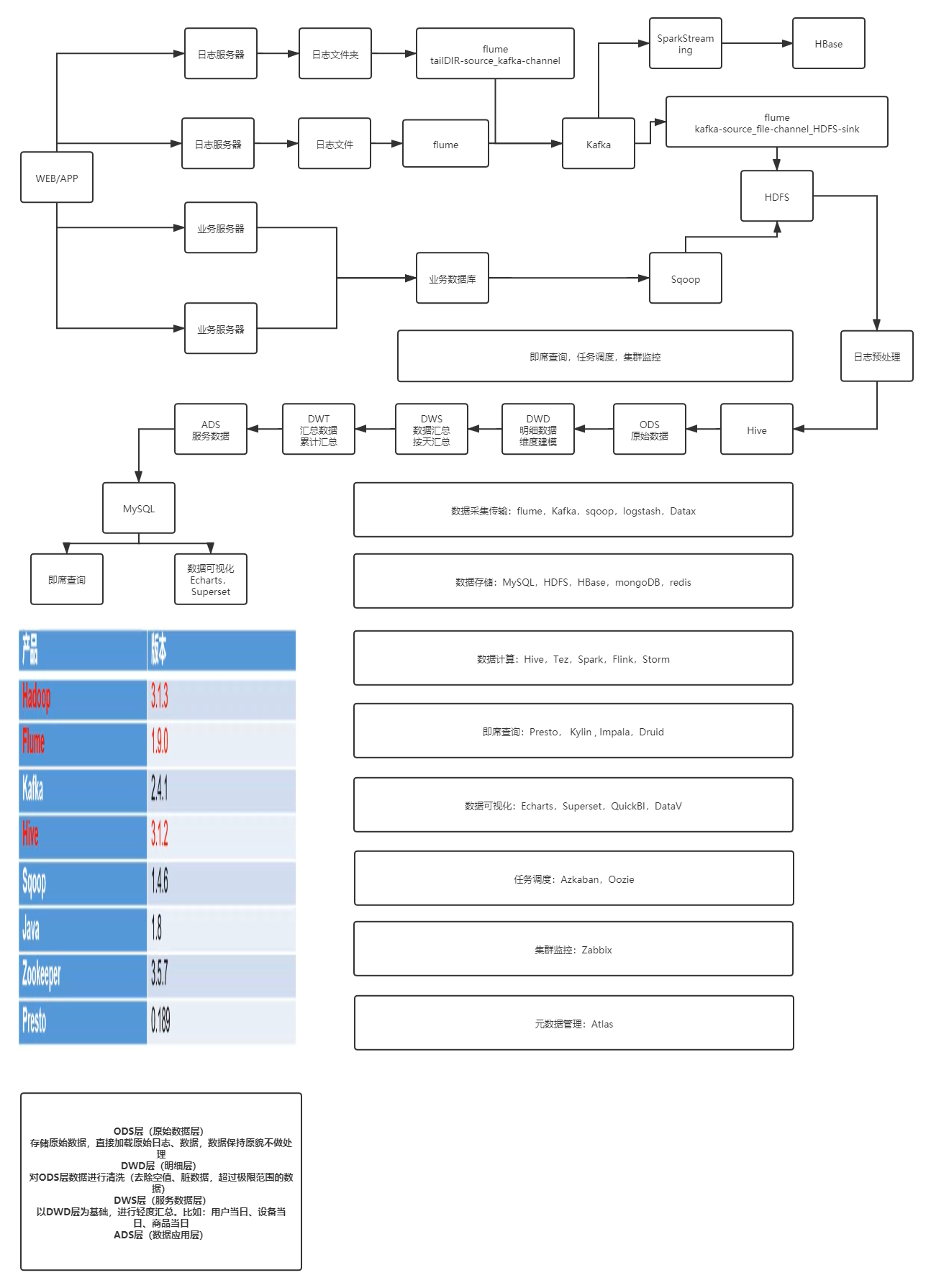
##��־�ɼ�ģ��
1:��־��Դ:web��app�����־���ռ�����־������
2:ʹ��flume��tailDIR�����־�������ϵ���־�ļ���,ʹ��Kafka channel����,
(�˹��̿��Զ���־����һ����־Ԥ����,���˵�json��ʽ����������Ҫ�ֶ�Ϊ�յ�����)
3:��ʹ��flume��Kafka source�Cfile channel�CHDFS sink,����־�ռ���ָ���ļ���
(�ڿ������ӹ�����,����־�е�ʱ����õ�head��,�Ա�֤�ϴ���HDFS�ϵ�����ʱ���ȷ��)
4:�������õ�����ӳ�䵽hive��ODS��
##���ֲַ����
tipΪʲôҪ�ֲ�:
1:(�Ѹ��������),�����ӵ�����ֽ�ɶ�����,ÿһ��ֻ���������˵������,��������Ķ�λ
2:(�����ظ��Ŀ���),����ҵ��淶�����ֽ��зֲ�,�ܹ������൱����ظ�����,���Ӽ������ĸ�����
3:(����),����ʵ������ͳ�����ݽ��,�����ÿ�����Ա�Ӵ�����������
1:ODS��(ԭʼ���ݲ�):���ԭʼ����,ֱ�Ӽ�����־����,���Բ�������,������־����ԭò(flume�������־����,sqoop�����ҵ������)
2:DWD��(��ϸ���ݲ�):��ODS�����ݽ��н���(��ODS���һ����json��ʽ�ַ�����ֳ���Ӧ�ֶ�),��ϴ,ȥ����ֵ,������,������ҵ��Ҫ��,����ҵ��Χ������,����,������ϸ����,һ�����ݴ���һ��ҵ����Ϊ
3:DWS��(���ݷ����):��DWD��Ϊ����,�����ݽ�����Ȼ���,�ṩ�����ľۺϳɶ�
4:DWT��(���������):��DWSΪ����,��ҵ�����������л��ֲ�����
5:ADS ��(����Ӧ�ò�):Ϊ����ϵͳ��ϯ��ѯ,���ݿ��ӻ��ṩ����
��������