一、背景
Flink是很火的数据流处理框架,它有什么特点,在业务又是如何应用的呢?本文将会从以下介绍Flink相关
首先,Flink的应用场景
其次,Flink有什么特点
第三,怎么快速run一个job,运行时情况是什么样的
第四,Flink内部是怎么实现的
带着这样的问题,我们开始Flink学习
在实际场景中,我们有很多流处理框架可以选择,它们各有优势,但相比flink劣势很明显。
Spark
Flink是一个流处理框架,和他相似的还有Java系列的Spark,它是Flink之前流行的框架,是基于RDD计算模型的,是一个批处理系统。
- 优势
- Spark容错性强:
因为是批处理,所以可以很好的处理容错,比如一批数据会批量发往某节点,如果这批数据都出错了,它们的副本还可以在别的机器执行
- Spark容错性强:
- 劣势
- 表达粒度粗
但是Spark是批处理系统,只是可以提供近似流式的能力,而Flink是流批一体的系统,整体都是基于流处理设计的,因此Spark有其弊端:因为批处理的表达粒度太粗,无法方便处理JOIN和state状态管理问题
- 表达粒度粗
Storm
是一个基于内存的流处理系统
- 优势
- 容错性强
Storm使用上游数据备份和消息确认的机制来保障消息在失败之后会重新处理。消息确认原理:每个操作都会把前一次的操作处理消息的确认信息返回。Topology的数据源备份它生成的所有数据记录。当所有数据记录的处理确认信息收到,备份即会被安全拆除。失败后,如果不是所有的消息处理确认信息收到,那数据记录会被数据源数据替换。这保障了没有数据丢失,但数据结果会有重复,这就是at-least once传输机制。
Storm采用取巧的办法完成了容错性,对每个源数据记录仅仅要求几个字节存储空间来跟踪确认消息。
- 容错性强
- 劣势
- 不支持exactly once
纯数据记录消息确认架构,尽管性能不错,但不能保证exactly once消息传输机制,所有应用开发者需要处理重复数据。 - 吞吐量低,容易反压
Storm存在低吞吐量和流控问题,因为消息确认机制在反压下经常误认为失败。
- 不支持exactly once
StreamTools
这是go的一个流处理框架,可以很方便地搭建架构
- 优势
- 组装拓扑图能力
可以在页面上通过连线组装上下游节点,毕竟流处理就是分成很多步骤,我们依照步骤执行嘛 - 各node有隔离内聚性
(node内部业务内聚)并且已经封装了一些node,比如join,map,fromFile等实现 - 有webUI方便拖拽调试
可以看实时数据 - 有webLog
方便debug日志
其实webUI和webLog都是通过webSocket实现的,webServer会实时把后端各节点的QPS,消息和日志通过UI和Log两个socket接口向前端传输
- 组装拓扑图能力
- 劣势
- 单机,没有分布式的支持
- 不支持可靠的状态管理
- 没有灵活可靠的算子
二、Flink特点
分布式
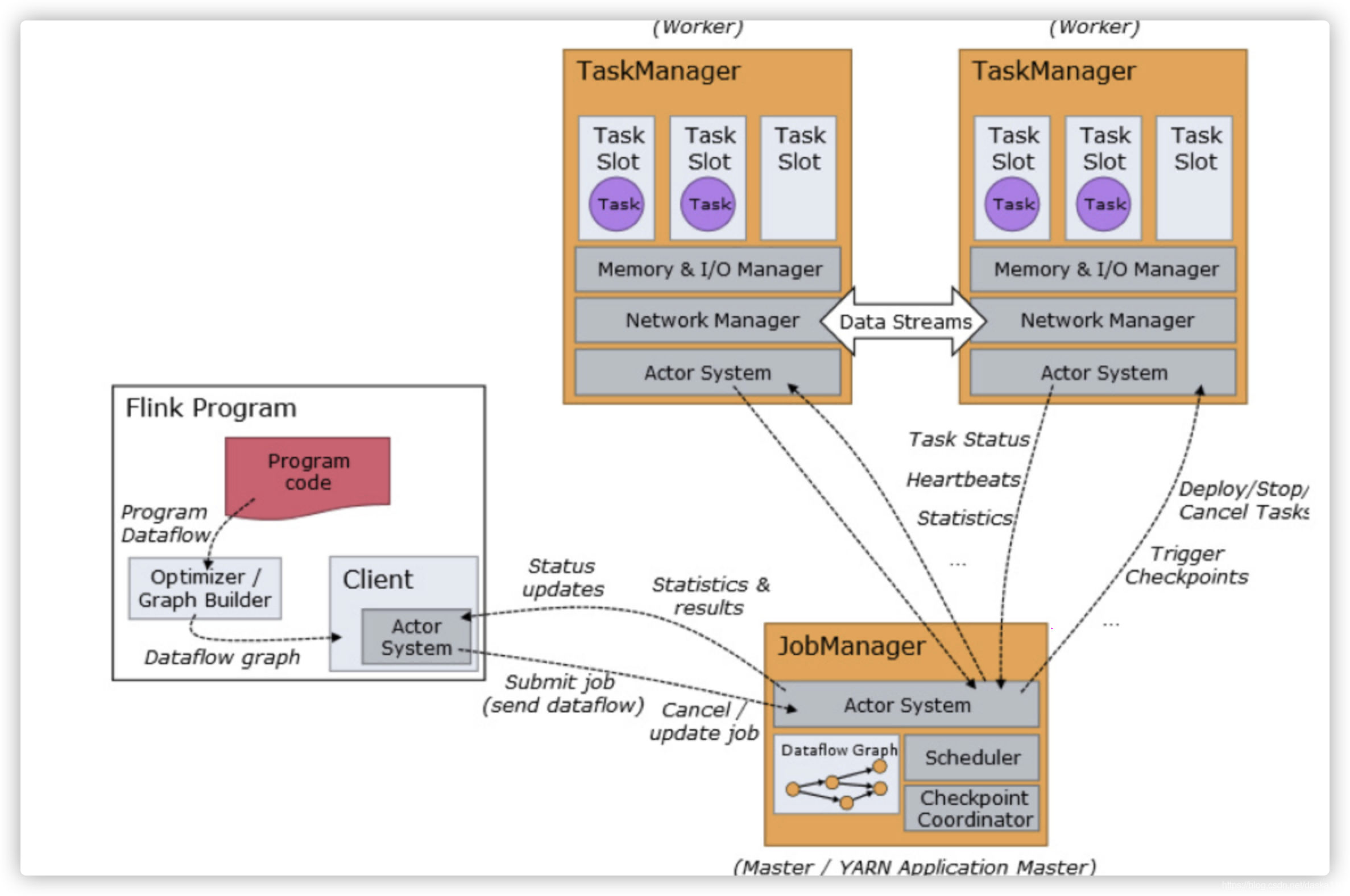 - 主从架构
- 主从架构
分为JobManager和TaskManager,JM负责接收client提交的job,做任务分发,和协调各TM的checkPoint以便保证分布式状态一致
- 并行处理
job会被并行地在各TaskManager上执行
好用的算子
- filter,split,window,union,join等,使我们更专注业务逻辑,有靠谱的轮子可用
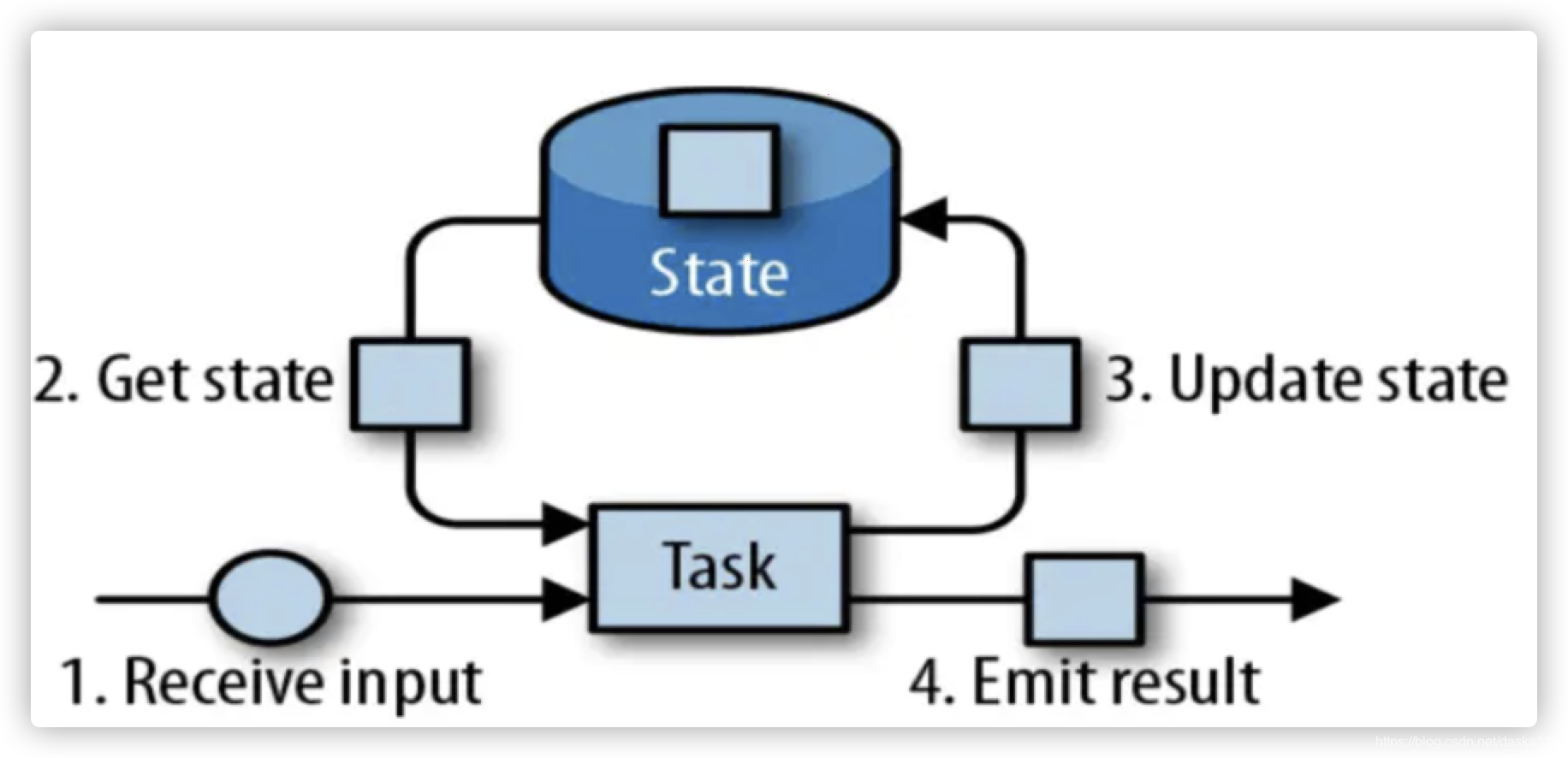
状态管理
- 基于memory、rocksdb与disk
乱序处理
基于EventTime和WaterMark可以给各个数据打水印,避免数据乱序
- 背景
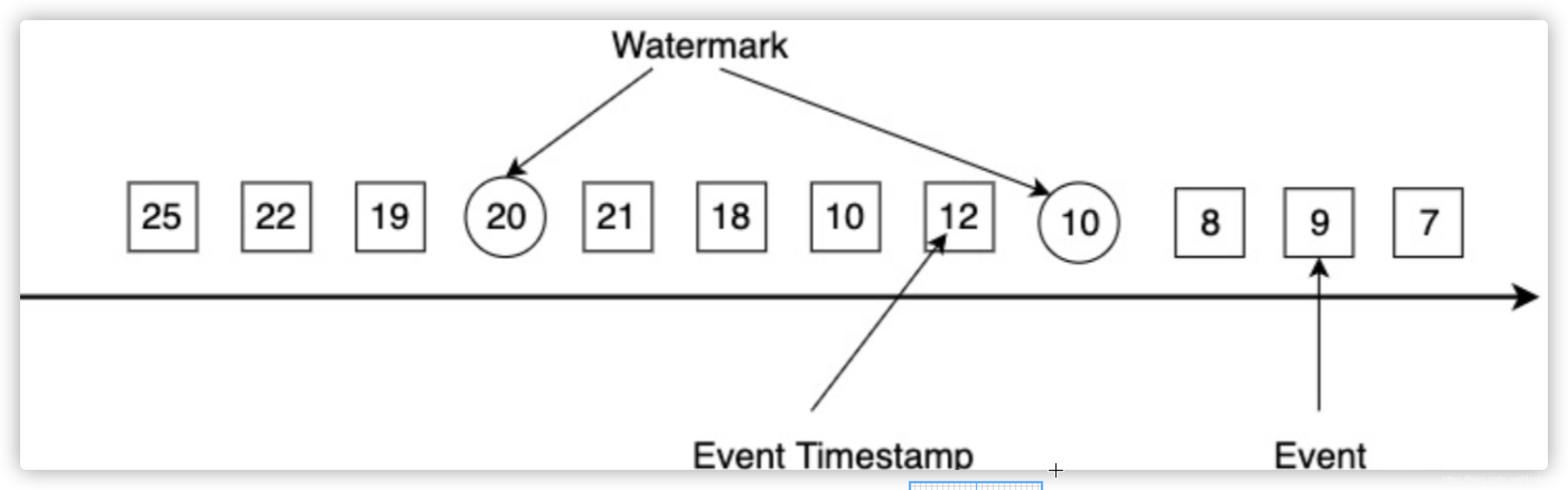
对于“晚到”的数据,我们不能无限期的等待(否则内存就爆了),所以需要有一个机制,来触发,当某个时机到来时,必须把一批window里的数据要扔出内存做计算了 - WaterMark是什么
那这种机制其实就是WaterMark,就是当我们收到waterMark后,就意味着在waterMark之前的数据都曾到达了(即使后面还有延迟的数据),我们就可以计算了
WaterMark就是在数据流(下图中的方框)中,Flink自己插入了一个“名为WaterMark的数据“(如下图中的圆框), 它代表了一个时间(即假设时间戳为T的waterMark后续到来的数据的eventTime都大于T,相当于一个“时间的里程碑“似的东西)
- 怎么使用EventTime+WaterMark呢
EventTime到底咋用呢,就是程序指定EventTime和waterMark就行了, 其中EventTime可以自己赋值一个自认为有意义的值,一般都是用“数据业务内容中的时间戳”(这样才有解决数据按业务时间排序的意义) - 优劣势
优点就是能解决乱序,但缺点就是有一定的内存维护开销(毕竟要等水印到了才能触发嘛,水印没到的时候就要在内存缓存一下) - 迟到数据的处理
通过设置AllowLateness,可以设置迟到数据最晚能迟到多久
生态成熟
- 各种source-connector和sink-connector
- 大厂背书,社区强大
灵活使用方式
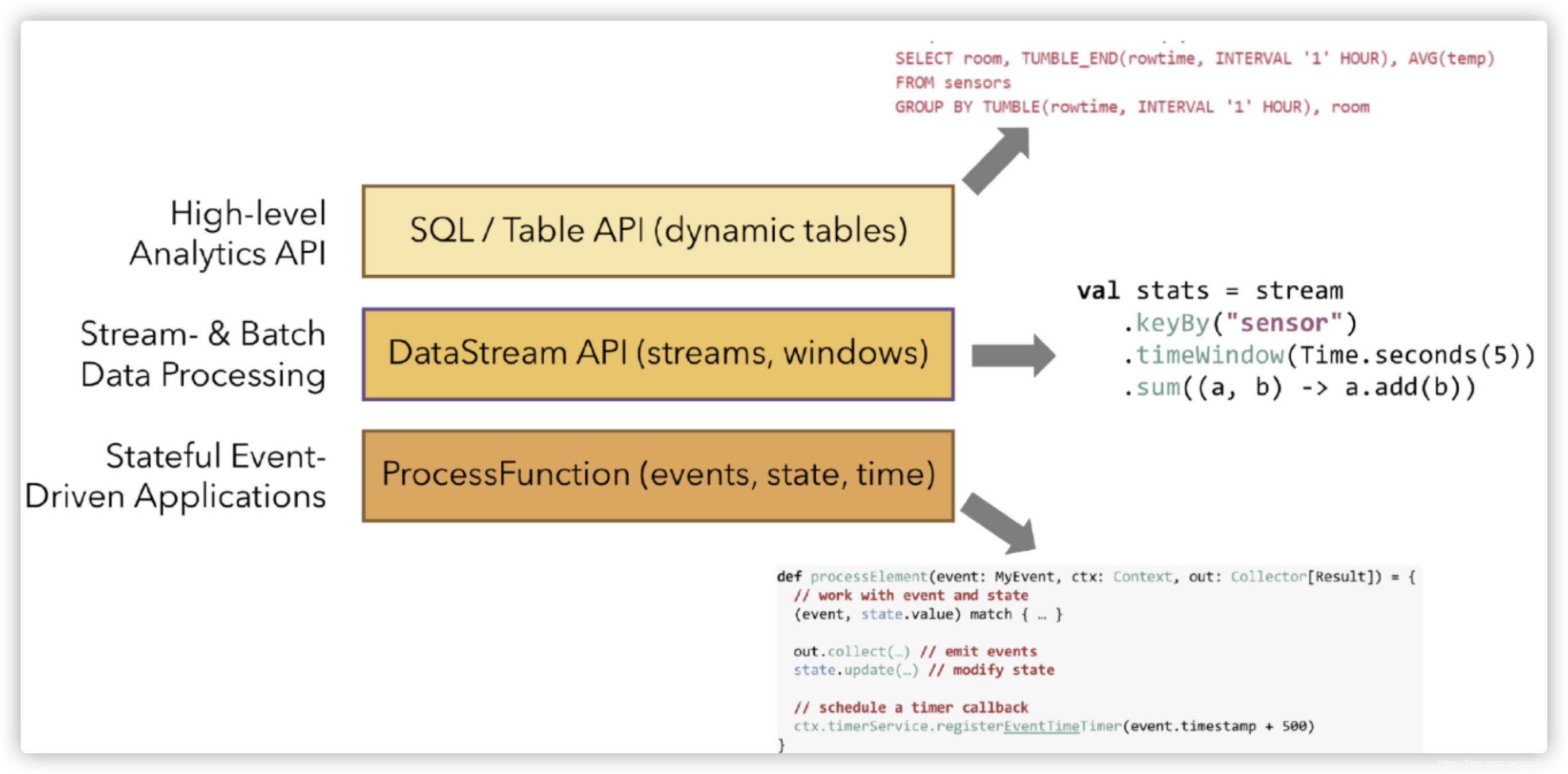
- 底层的ProcessFunciton,用Java/Scala
- 中层的DataStreamAPI,用Java/Scala
- 高层的SQL或TableAPI,用SQL开发,更接近业务语言
三、快速上手
我们将从一个wordCount开始
pom配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flinktest</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.13.1</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
java代码
package com.demo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WordCount {
public static void main(String[] args) throws Exception {
//定义socket的端口号
int port;
try {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port");
} catch (Exception e) {
System.err.println("没有指定port参数,使用默认值9000");
port = 9000;
}
//获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//连接socket获取输入的数据
DataStreamSource<String> text = env.socketTextStream("127.0.0.1", port, "\n");
//计算数据
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) throws Exception {
String[] splits = value.split("\\s");
for (String word : splits) {
out.collect(new WordWithCount(word, 1L));
}
}
})//打平操作,把每行的单词转为<word,count>类型的数据
.keyBy("word")//针对相同的word数据进行分组
.timeWindow(Time.seconds(2), Time.seconds(1))//指定计算数据的窗口大小和滑动窗口大小
.sum("count");
//把数据打印到控制台
windowCount.print()
.setParallelism(1);//使用一个并行度
//注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行
env.execute("streaming word count");
}
/**
* 主要为了存储单词以及单词出现的次数
*/
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {
}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}
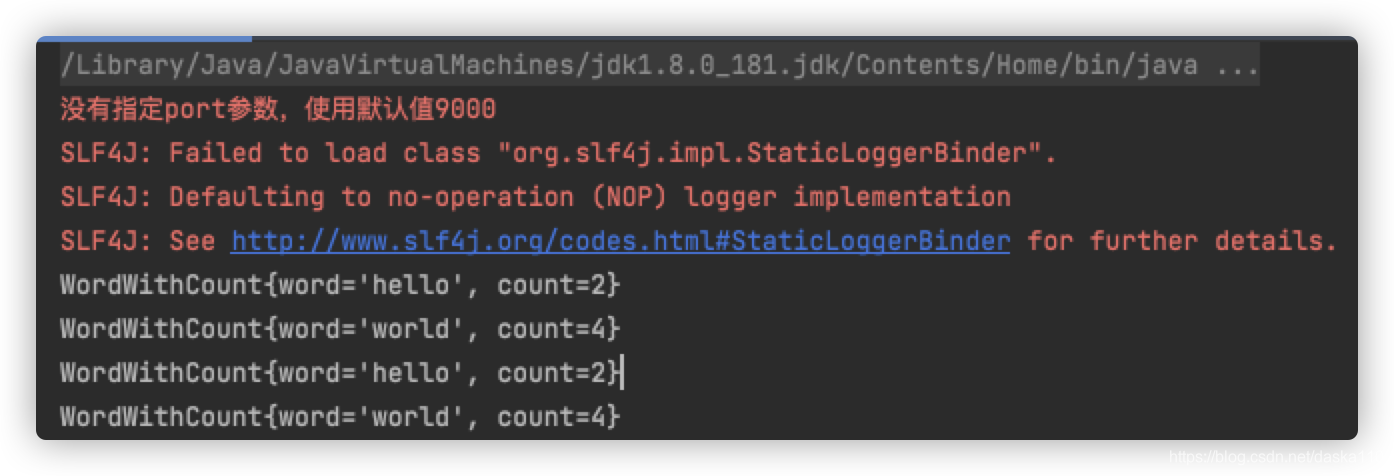
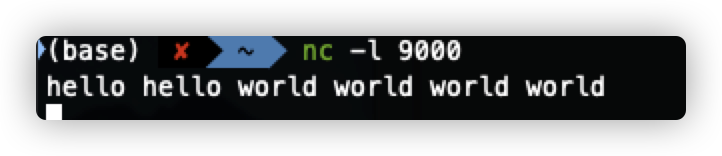
运行效果
- 打开socket端口,并输入source数据
- 产生sink结果