一文带你入门flink sql
写在前面
本次实战主要是通过Flink SQL Client消费kafka的实时消息,再用各种SQL操作对数据进行查询统计。
环境准备
具体的环境安装过程就不在这里写了,网上很多资料,大家自己查阅按照就好了。我说下我本地的环境:
- flink 1.12.4
- mysql 8.0.25
- kafka 2.8.0
另外就是,本次示例需要用到以下几个jar包:
flink-sql-connector-kafka_2.11-1.12.4.jar
flink-connector-jdbc_2.11-1.12.4.jar
mysql-connector-java-5.1.48.jar
把他们拷贝到flink安装目录lib目录下。
flink输出的结果,会落到一张mysql的表,也就是我们的sink表,这个表要提前建好。
CREATE TABLE `pvuv_sink` (
`dt` varchar(100) DEFAULT NULL,
`pv` bigint DEFAULT NULL,
`uv` bigint DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
三个字段分别表示时间,pv值和uv值。
正文
先启动flink以及flink sql的客户端。
$ ./bin/start-cluster.sh
$ .bin/sql-client.sh embedded
这样就开启了一个sql client的客户端。
接着在客户端执行下面这段sql,这相当于启动了一个source table进行监听我们的输入数据流。
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
ts TIMESTAMP(3)
) WITH (
'connector.type' = 'kafka', -- 使用 kafka connector
'connector.version' = 'universal', -- kafka 版本,universal 支持 0.11 以上的版本
'connector.topic' = 'user', -- kafka topic
'connector.startup-mode' = 'earliest-offset', -- 从起始 offset 开始读取
'connector.properties.0.key' = 'zookeeper.connect', -- 连接信息
'connector.properties.0.value' = 'localhost:2181',
'connector.properties.1.key' = 'bootstrap.servers',
'connector.properties.1.value' = 'localhost:9092',
'update-mode' = 'append',
'format.type' = 'json', -- 数据源格式为 json
'format.derive-schema' = 'true' -- 从 DDL schema 确定 json 解析规则
);
执行成功的话,会返回:
[INFO] Table has been created
解释下这段sql,flink会帮我们创建一张表,这个表的数据来源于kafka的消息,对应的topic是user,数据的格式是json。其它的信息都好理解,不做过多解释了。执行成功后,就开启监听了。
我们可以select下,看看表的情况:
因为还没有输入数据,所以表是空的。
然后执行sink sql,也就是输出数据的表,这个表前面我们提前建好了,在flink sql这里配置下:
CREATE TABLE pvuv_sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/flink-test',
'connector.table' = 'pvuv_sink',
'connector.username' = 'root',
'connector.password' = '11111111',
'connector.write.flush.max-rows' = '1'
);
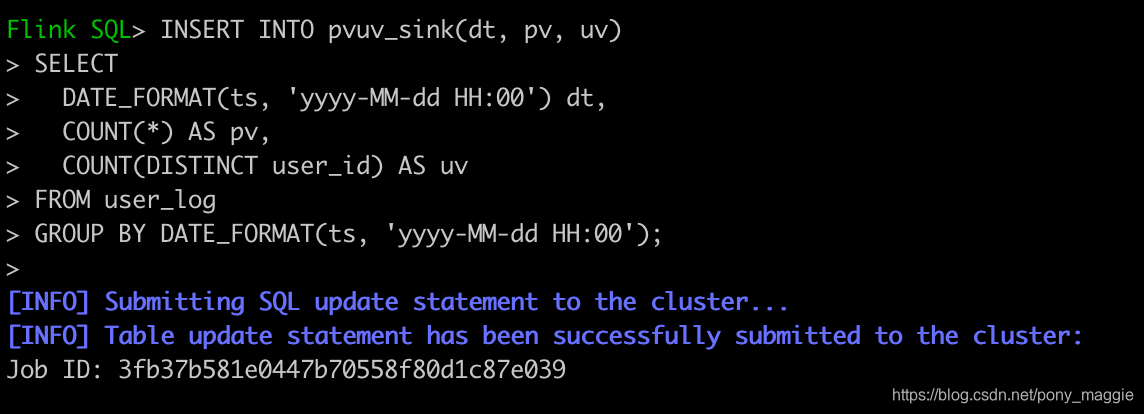
然后编写计算逻辑,逻辑比较简单,统计每个小时的pv和uv。
INSERT INTO pvuv_sink(dt, pv, uv)
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv
FROM user_log
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00');
执行后,flink就会启动一个job在后台执行。
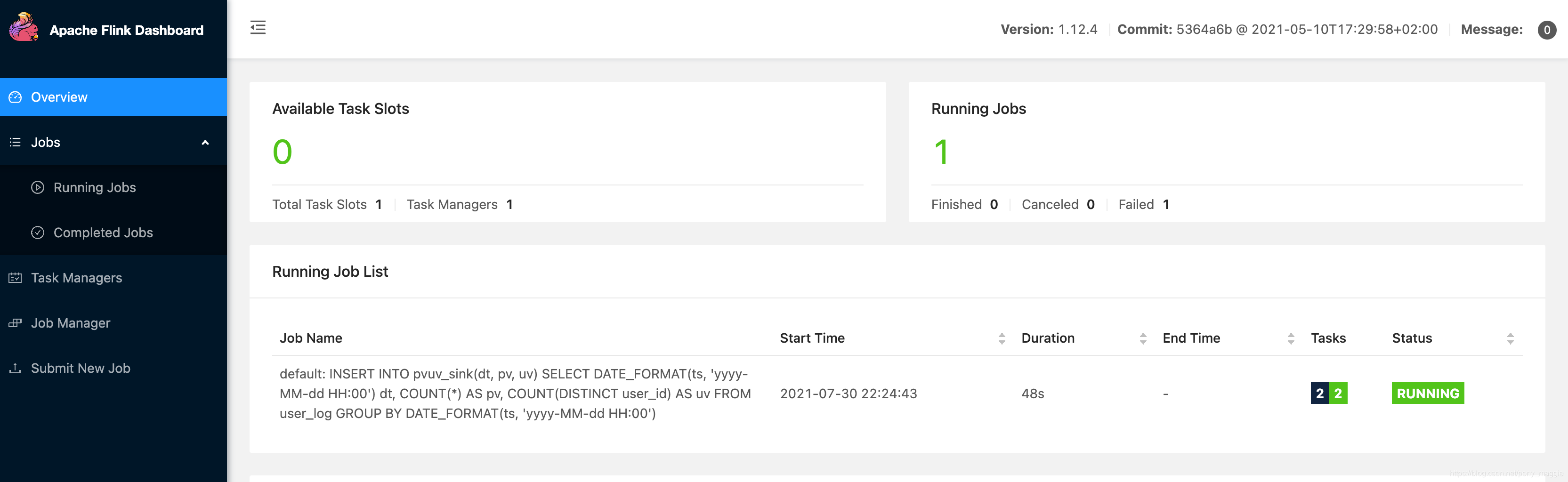
我们可以通过
http://localhost:8081/#/overview
这个地址看到任务的详细情况。
然后我们在本地启动一个kafka的服务,然后再启动一个producer模拟发送数据。
kafka是基于zookeeper的,启动kafka之前,需要先启动zookeeper
/usr/local/Cellar/kafka/2.8.0/bin/zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties &
启动kafka
/usr/local/Cellar/kafka/2.8.0/bin/kafka-server-start /usr/local/etc/kafka/server.properties &
查看启动是否成功
创建topic,注意和上面source table的配置保持一致。
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic user
启动一个控制台的生产者,
kafka-console-producer --broker-list localhost:9092 --topic user
发送两条消息试试:
{"user_id": "543462", "item_id":"1715", "category_id": "1464116", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}
{"user_id": "662867", "item_id":"2244074", "category_id": "1575622", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}
去mysql看下pvuv_sink表,发现已经有数据了。

遇到的一些问题
在运行flink sql的时候踩过一些坑,这里列举下帮大家避坑。
错误一
java.lang.NoSuchMethodError: 'boolean org.apache.flink.table.api.TableColumn.isGenerated()'
这个是因为flink-jdbc的版本搞错了导致的。
错误二
Flink SQL> INSERT INTO pvuv_sink(dt, pv, uv)
> SELECT
> DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt,
> COUNT(*) AS pv,
> COUNT(DISTINCT user_id) AS uv
> FROM user_log
> GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00');
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.NoClassDefFoundError: org/apache/kafka/common/serialization/ByteArrayDeserializer
这个是因为我一开始用错了lib,应该是
flink-sql-connector-kafka_2.11-1.12.4.jar
而不是
flink-connector-kafka_2.12-1.12.4.jar
错误三
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassCastException: class org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.MissingNode cannot be cast to class org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode (org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.MissingNode and org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode are in unnamed module of loader 'app')
参考
- https://blog.csdn.net/boling_cavalry/article/details/106038219
- https://issues.apache.org/jira/browse/FLINK-19995