说明:该博客对应的Elasticsearch 的版本为7.8.0;测试工具为postman
概念:Bucket可以理解为一个桶,符合要求的放入一个桶中,相当于mysql中的groupBy
本篇博客主要针对于terms aggs, filter aggs,histogram aggs,range aggs,date aggs五个关键字展开.
一,创建索引数据,参考Elasticsearch(三)--Metric(指标)
?二,Terms Aggregation (术语聚合)
terms聚合应该是一个类型的字段keyword或适合桶聚合的任何其他数据类型。为了使用它,text您需要启用?fielddata。
默认情况下,terms聚合将返回按 排序的前十个术语的桶doc_count。可以通过设置size参数来更改此默认行为。
{
"aggs":{
"term_goodType":{
"terms":{
"field":"goodType",
"size":3, //返回排序后的前三个桶(默认情况下,桶
//按doc_count降序排列)
"order":{
"_count":"asc" //按照每个桶内文档的个数进行升序排列
}
}
}
}
}运行结果

注意:关于排序的介绍
?1,内置排序
_count:按文档数排序
_key:按词项的字符串值的字母顺序排序
2,按单值指标子聚合(由聚合名称标识)对存储桶进行排序
3,按多值指标子聚合(由聚合名称标识)对存储桶进行排序
按单值指标子聚合(由聚合名称标识)对存储桶进行排序
{
"aggs":{
"term_goodType":{
"terms":{
"field":"goodType",
//"size":3,
"order":{
"in_bucket_max_goodPrice":"desc" //对该聚合名称进行降序排序
}
},
"aggs":{
"in_bucket_max_goodPrice":{ //聚合名称的具体实现
"max":{
"field":"goodPrice"
}
}
}
}
}
}?运行结果

?
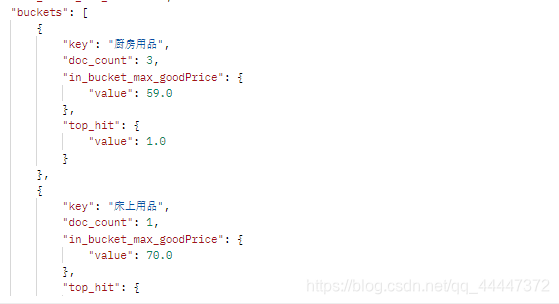
按多值指标子聚合(由聚合名称标识)对存储桶进行排序
{
"aggs":{
"term_goodType":{
"terms":{
"field":"goodType",
//"size":3,
"order":{
"in_bucket_max_goodPrice":"desc", //先按照每个桶内该字段的最大值降序排列
"top_hit":"desc" //最大值相同的再按照相关度得分降序排列
}
},
"aggs":{
"in_bucket_max_goodPrice":{
"max":{
"field":"goodPrice"
}
},
"top_hit":{
"max": {
"script": {"source": "_score"}
}
}
}
}
}
}?运行结果
?
?三,Filter Aggregation(过滤聚合)
Filter Aggregation?和?Filters Aggregation:多桶聚合,其中每个桶包含与查询匹配的文档
Filter Aggreagtion 只能指定一个过滤条件,响应也只是单个桶。如果想要只对多个特定值进行聚合,需要使用 Filter Aggreagtion 只能进行多次请求。而使用 Filters Aggreagation 就可以解决上述的问题,它可以指定多个过滤条件,也是说可以对多个特定值进行聚合。
3.1过滤获取goodType为手机数码的桶,并求该桶平均值
{
"aggs" : {
"goodType_select_one" : {
"filter" : { "term": { "goodType": "手机数码" } },
"aggs" : {
"avg_price" : { "avg" : { "field" : "goodPrice" }
}
}
}
}
}?运行结果
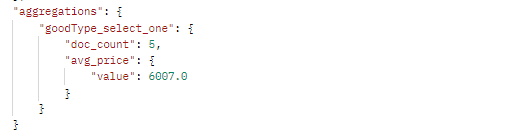
?3.2过滤获取goodType为手机数码或者goodName为男士外套的桶
{
"aggs":{
"buckets":{
"filters":{
"filters":{
"goodNameBucket":{
"match":{
"goodName":"男士外套"
}
},
"goodTypeBucket":{
"match":{
"goodType":"手机数码"
}
}
}
}
}
}
}?运行结果

?
?四,Histogram Aggregation(直方图聚合)
? ? ? 概念:基于多桶值源的聚合,可应用于从文档中提取的数值或数值范围值。它动态地在值上构建固定大小(又名间隔)的桶。例如,如果文档有一个包含价格(数字)的字段,我们可以配置此聚合以动态构建具有间隔的存储桶5(在价格的情况下,它可能代表 5 美元)。当聚合执行时,每个文档的 price 字段将被评估,并将向下舍入到最接近的存储桶 - 例如,如果价格是32,存储桶大小是,5则舍入将产生30,因此文档将“落入”与 key 关联的存储桶30
?4.1根据价格区间为10000分桶,同时如果桶中没有文档就不显示桶
最小文件数(指定匹配的桶中至少含有的文档数目):min_doc_count
{
"aggs":{
"histogram_goodPrice_10000":{
"histogram":{ //聚合的类型
"field":"goodPrice", //对该字段进行分组
"interval":"10000", //间隔为10000
"min_doc_count":1 //返回的桶里面至少有1个文档
}
}
}
}?运行结果

?
?五,Range Aggregation (范围聚合)
?用户自定义一组范围,每个范围代表一个桶.在聚合过程中,将从每个文档中提取的值根据每个存储区范围进行检查,并将相关/匹配文档“存储”到每个桶内.此聚合包括每个范围的from值并排除该to值
{
"aggs":{
"goodPrice_range":{ //聚合名字(自定义)
"range":{ //聚合类型
"field":"goodPrice", //该字段进行分组
"ranges":[ //自定义分组范围
{
"to":"89" //[*-89.0) 排除89
},
{
"from":"89", //[89-4000000) 排除4000000
"to":"4000000"
},
{
"from":"4000000" //[4000000-*)
}
]
}
}
}
}运行结果
 ??
??
可以为每个范围自定义键
{
"aggs":{
"goodPrice_range":{
"range":{
"field":"goodPrice",
"ranges":[
{
"key":"group1",
"to":"89"
},
{
"key":"group2",
"from":"89",
"to":"4000000"
},
{
"key":"group3",
"from":"4000000"
}
]
}
}
}
}?运行结果

将文档“存储”到不同的存储桶中,并且计算每个价格范围内的价格统计信息?
{
"aggs":{
"groupby_goodPrice":{
"range":{ //进行分组
"field":"goodPrice", //字段为goodPrice
"ranges":[
{
"key":"group1",
"to":"100"
},
{
"key":"group2",
"from":"100",
"to":"4000000"
},
{
"key":"group3",
"from":"4000000"
}
]
},
"aggs":{ //对分桶后的每个桶执行聚合操作
"goodPrice_stats":{
"stats":{
"field":"goodPrice"
}
}
}
}
}
}运行结果

?六,Date Aggregation(日期聚合)
Date Histogram Aggregation(日期直方图聚合):?类似于普通的?histogram,但它只能与日期或日期范围值一起使用;像直方图,数值四舍五入下来到最接近的水桶。例如,如果间隔是一个日历日,2020-01-03T07:00:01Z则四舍五入为?2020-01-03T00:00:00Z
日历间隔:
使用calendar_interval参数配置(不支持多个数量2d)minute,?1m?--hour,?1h--day,?1d--week,?1w--month,?1M--quarter,?1q--year,?1y
固定间隔
通过fixed_interval参数配置。
固定间隔的可接受单位是:毫秒 (?ms)--秒 (?s)--分钟 (?m)--小时 (?h)--天 (?d)
{
"aggs" : {
"sales_time" : {
"date_histogram" : {
"field" : "sellTime",
"interval" : "1M",
"format" : "yyyy-MM-dd"
}
}
}
}?Date Range Aggregation(日期范围聚合):专用于日期值的范围聚合。此聚合与正常范围?聚合之间的主要区别在于?,from和to值可以用?日期数学表达式表示,并且还可以指定返回from和to响应字段的日期格式。请注意,此聚合包括每个范围的from值并排除该to值。
{
"aggs": {
"range": {
"date_range": {
"field": "sellTime",
"format": "MM-yyyy",
"ranges": [
{ "to": "now-10M/M" },
{ "from": "now-10M/M" }
]
}
}
}
}?