��Ŀ��Ҫ
֮ǰ�����Ѿ�ͨ����̬���������ݷֵ���������Ҫ��λ��,Ϊ�˷���������ݵĽ��ⷽ��,���Խ��������ǿ������ñ�����Ϣ���е�����,Ȼ��ͨ����̬�����ķ���,�����ݷ�����Ӧ��kafka���������hbase��ά�ȱ���:
//������Ϣ��:
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '��Դ��',
`operate_type` varchar(200) NOT NULL COMMENT '�������� insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '������� hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '�����(����)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '����ֶ�',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '�����ֶ�',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '������չ',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
//��Դ������ָ����ʵ������ά�ȱ�;
//����kafka,���������������;����HBase,��������Ƕ�Ӧ�ı�;
//����ֶξ���ָ������Ҫ������ֶ�
//�����ֶξ���ָ����������ֶ�(����HBase����rowKey)
//������չ����ָENGINE=InnoDB DEFAULT CHARSET=utf8���;
�����ԭ�����ñ�table_process�е�����,�����ɹ�֮��,����ҵ�����ݺͶ�Ӧ��IDEA����,���ɶ�Ӧ�ı�:
���� Sink ֮����ҵ�����ݵ� Kafka ����
//���ñ�����Ժ�,��Ӧ���������kafka���������;
//������:
dwd_cart_info
dwd_comment_info
dwd_coupon_use
dwd_display_log
dwd_favor_info
dwd_order_detail
dwd_order_detail_activity
dwd_order_detail_coupon
dwd_order_info
dwd_order_info_update
dwd_order_refund_info
dwd_page_log
dwd_payment_info
dwd_refund_payment
dwd_start_log
����Sink֮����ά�����ݵ�Hbase����:
GMALL0709_REALTIME | DIM_ACTIVITY_INFO | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_ACTIVITY_RULE | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_ACTIVITY_SKU | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_BASE_CATEGORY1 | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_BASE_CATEGORY2 | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_BASE_CATEGORY3 | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_BASE_DIC | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_BASE_PROVINCE | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_BASE_REGION | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_BASE_TRADEMARK | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_COUPON_INFO | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_COUPON_RANGE | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_FINANCIAL_SKU_COST | TABLE | | | | | | false | null |
| | GMALL0709_REALTIME | DIM_SKU_INFO | TABLE | | | | | | false | 4 |
| | GMALL0709_REALTIME | DIM_SPU_INFO | TABLE | | | | | | false | 3 |
| | GMALL0709_REALTIME | DIM_USER_INFO | TABLE | | | | | | false | 3 |
+------------+---------------------+-------------------------+---------------+----------+------------+----------------------------+-----------
����Ӧ������kafka��Phoenix�п�����Щ����Ϣ,������Щ������������ʹ��,������֮���ܸ��õĿ�������̬����֮���Ч��,��Щ�������ά�ȱ������ݶ�Ӧ�ľ���Sql���ݿ���gmall0709�еĸ���ҵ�������������;(���и������������Ѿ��������ñ��е��ֶ�������Ϣ�����˹���,Ҳ����Щ������Ϣ��MySql���ݿ��е�ҵ�������DZ���һ�µ�)
DWM��ҵ�����
�õ�����־�������ݡ�ά�����ݺ���ʵ���ݺ�,�����Ͼ������ODS��DWD��DIM������,����������DWM��������,��ôΪʲô��ҪDWM��ôһ���м����?
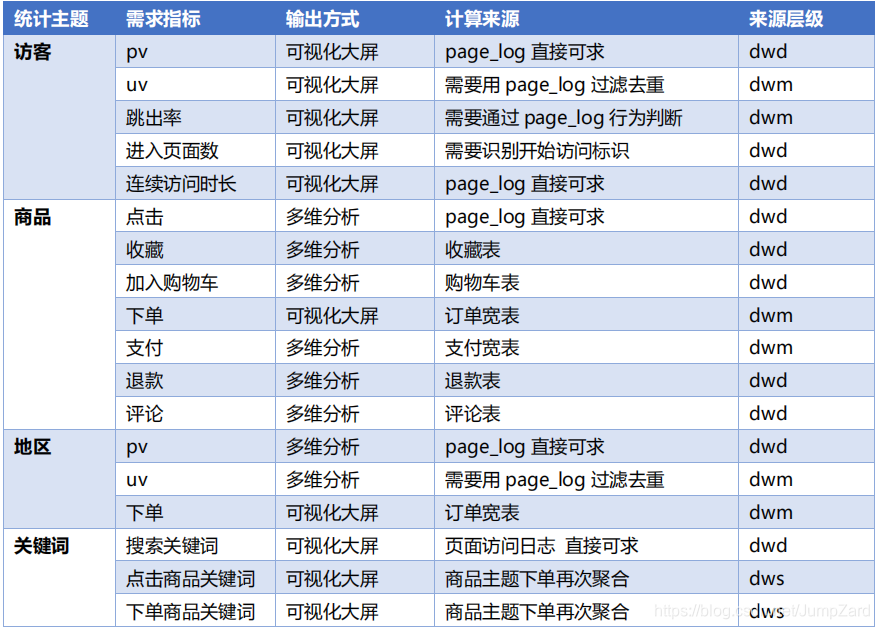
������DWS������������һ�����˼·,��ô����������Ҫ������Ҫ��ά�ȱ�����ʵ�����������,Ȼ���ٿ�ʼά�ȿ���������(�����漰��ά�Ƚ�ģ����,����������OLAP��ͬ��OLTP��һ����������,OLTPͨ����ʽ��ģ,��OLAP��ͨ��ά�Ƚ�ģ���γ��������,�Ӷ���ɺ��������ݷ�������)��DWM������þ��ǽ�����DWD��DWS��֮���һ�����ɲ�,������һ�㲻�DZ�Ҫ��,ֻ��Ϊ�˸���һ��������ҵ������,���ҵ���Ǻܸ���,Ҳ����ֱ�Ӵ�dwd������ݷ���DWS��;�ṹ������ʾ:
DWM��ҵ�����ʵ�֨CUV����
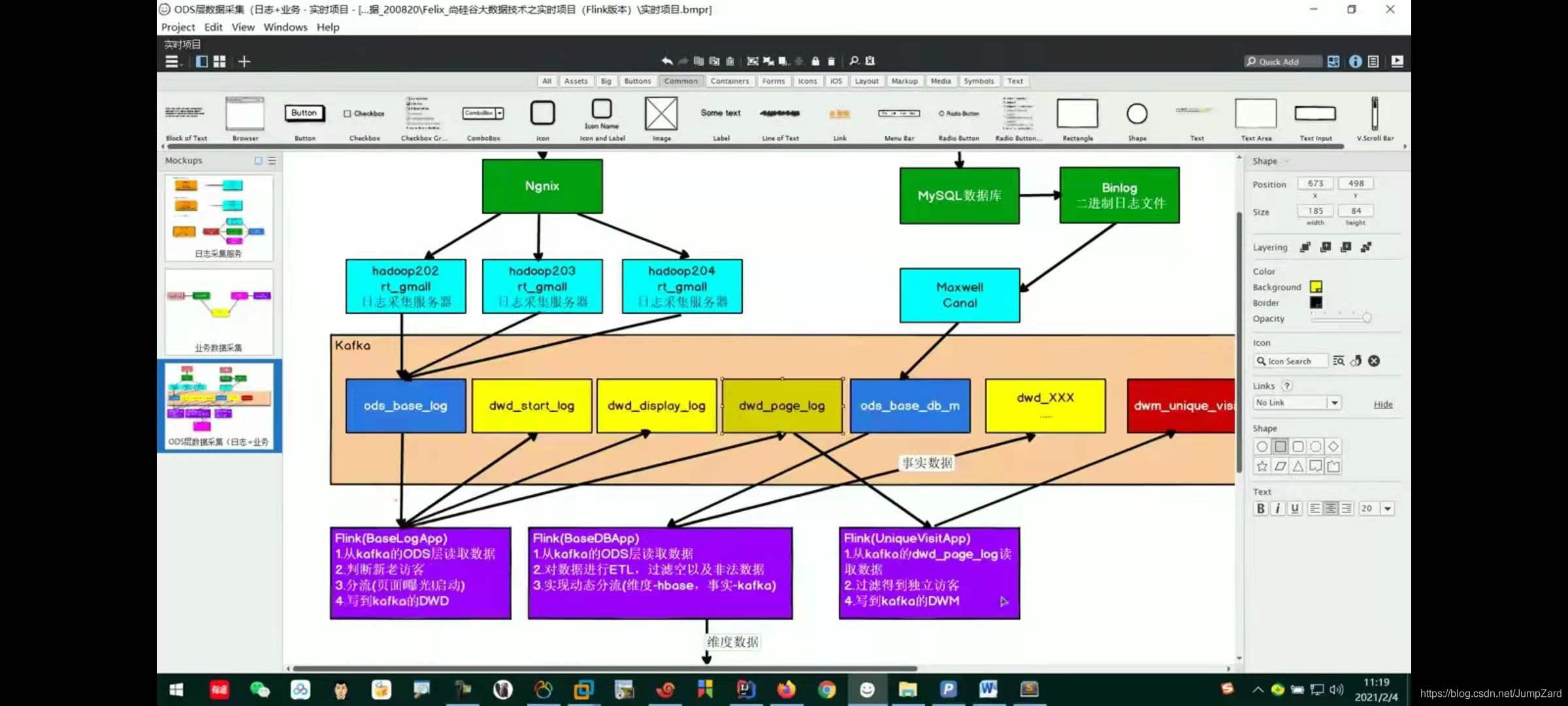
���������˼·
//UV,ȫ���� Unique Visitor,�������ÿ�,����ʵʱ������,Ҳ���Գ�Ϊ DAU(Daily Active User),��ÿ�ջ�Ծ�û�,��Ϊʵʱ�����е� uv ͨ����ָ���յķÿ�����
��ô��δ��û���Ϊ��־��ʶ������յķÿ�,��ô������:
? ��һ,��ʶ����÷ÿʹĵ�һ��ҳ��,��ʾ����ÿͿ�ʼ�������ǵ�Ӧ��
? ���,���ڷÿͿ�����һ���ж�ν���Ӧ��,��������Ҫ��һ��ķ�Χ�ڽ���ȥ��
//���Ĺ���˼·:
? ������ keyby ���� mid ���з���,ÿ���ʾ��ǰ�豸�ķ������
? �����ʹ�� keystate ״̬,��¼�û�����ʱ��,ʵ�� RichFilterFunction ��ɹ���
? ��д open ����������ʼ��״̬
? ��д filter �������й���
? ����ֱ��ɸ�� last_page_id ��Ϊ�յ��ֶ�,��ΪֻҪ����һҳ,˵��������������û��������ҳ�档
? ״̬������¼�û��Ľ���ʱ��,ֻҪ��� lastVisitDate �ǽ���,��˵���û������Ѿ����ʹ�������ɸ���������Ϊ�ջ��߲��ǽ���,˵�����컹û���ʹ�,������
? ��Ϊ״ֵ̬��Ҫ����ɸѡ�Ƿ��������,���������¼���˽��������û������,���� enableTimeToLive �趨�� 1 ��Ĺ���ʱ��,����״̬����
//��dwd_page_log�л�ȡ����;
//Flink����dwd_page_log�����е����ݲ���uv����;
//����������ݷ��͵�dwm_unique_visit������;
//����1:�Ƿ��ܶ�ȡ����̬�����������;
//? ���� log.sh��zk��kafka
//? ���� Idea �е� BaseLogApp
//? ���� Idea �е� UniqueVisitApp
//? �鿴����̨���
//? ִ������
//jsonObjDS.print("---->");
//����2:
? ���� log.sh��zk��kafka
? ���� Idea �е� BaseLogApp
? ���� Idea �е� UniqueVisitApp
? �鿴����̨����Լ� kafka �� dwm_unique_visit ����
? ִ������
//filteredDS.print(">>>>>");
���������ڵ�һ������ʱ������һ������,�����ҿ��IJ����ҵĴ���,�ܿ��ܻ������������,������һ������,����ʵ�����ǽű��������ݵ�һ������,�ĺ�ķ�����:�������������־,�Ǿ�ֱ�����������(ҳ����־),Ȼ������ҳ����־��ȥ���ع���־;
//��ʱ�Ľ��Ӧ���� BaseLogApp����̨���������,��UniqueVisitApp����̨û���������;
//��ǰ�����ֱ��dwd_page_log���������ݵ�,�������ݳ�������dwd_page_log --> UniqueVisitApp�Ĺ�����;debug����;
//��������Ϊÿ�����ݶ���һ��"last_page_id"����,�������ݶ������˵���;
//��֮ǰBaseLogApp����־����ʱ�Ĵ���������,�ع���־��Ҳ������ҳ����־,�������ֿ���;
//������֮��,Ҳ����˳����������kafka�������;
���,�ѹ��˺�����������DWM����,�������������ݱ��浽��dwm_unique_visit������,�ȴ�������ʹ�á�
DWM��ҵ�����ʵ�֨C������ϸ����
//ʲô������:
���������û��ɹ���������վ��һ��ҳ�����˳�,���ڼ���������վ������ҳ�档�������ʾ����������������Է��ʴ�����
��ע������,���Կ������������ķÿ��Ƿ��ܺܿ�ı�����,���������������û�֮��������Ա�,����Ӧ���Ż�ǰ�������ʵĶԱ�Ҳ�ܿ����Ż��Ľ��ijɹ�
//�ж�������Ϊ:
����Ҫʶ����Щ��������Ϊ,Ҫ����Щ�����ķÿ����һ�����ʵ�ҳ��ʶ���������ôҪץס��������:
? ��ҳ�����û����ڷ��ʵĵ�һ��ҳ��,�������ͨ����ҳ���Ƿ�����һ��ҳ��(last_page_id)���ж�,��������ʾΪ��,��˵����������ÿ���η��ʵĵ�һ��ҳ�档
? �״η���֮��ܳ�һ��ʱ��(�Լ��趨),�û�û������������ҳ��ķ��ʡ�
//�жϷ���:���һ��������ʶ��ܼ�,���� last_page_id Ϊ�յľͿ����ˡ����ǵڶ������ʵ��ж�,��ʵ�е��鷳,�����ⲻ����һ�����ݾ��ܵó�����
//��,��Ҫ����ж�,Ҫ��һ�����ڵ����ݺͲ����ڵ����ݽ�������жϡ�����Ҫͨ��һ�������ڵ��������һ�����ڵ����ݡ����鷳������������Զ������,����
//��һ��ʱ�䷶Χ�ڲ����ڡ���ô���ʶ����һ��ʧЧ�������Ϊ��?
//��İ취���� Flink �Դ��� CEP ��������� CEP �dz��ʺ�ͨ���������������ʶ��ij���¼����û������¼�,�����Ͼ���һ�������¼���һ����ʱ�¼�����ϡ�
//��dwd_page_log�л�ȡ����;
//Flink����dwd_page_log�����е����ݲ�ͨ��CEP��ʽ��ѡȡ������ҳ��������;
//ѡȡ���������ݷ��͵�dwm_user_jump_detail������;
�����Flink CEP��̲��Ƿdz��˽�,���Բο��ҵ���һƪ����,������һ����̵Ľ���:
CEP���
�������˼·:�����趨���¼�ʱ���,����mid(����id)���з���,Ȼ���趨�ö�Ӧģʽ,��10����û�з���ҳ����ת����Ϊû�з���������Ϊ,�ѳ�ʱ���ֵ����ݷ����������н������;(ֻ�����һ�������ĺ����Ծ�������Ҫ����������,���Dz������������)���ⲿ�����ݴ浽dwm_user_jump_detail������,���������Ҫ��������������
����:
//���ô����еIJ�����������;���жȸ�Ϊ1;
//����zk��kk��dwm_user_jump_detail��������,Ӧ�ó���,�鿴�Ƿ������;
//jumpDS.print(">>>>>");
DWM��ҵ�����ʵ�֨C��������
������ͳ�Ʒ�������Ҫ�Ķ���,Χ�ƶ����кܶ��ά��ͳ������,�����û�����������Ʒ��Ʒ�ࡢƷ�Ƶȵȡ�
Ϊ��֮��ͳ�Ƽ�����ӷ���,���ٴ��֮��Ĺ���,������ʵʱ��������н�Χ�ƶ���������������ϳ�Ϊһ�Ŷ����Ŀ�����
�Ǿ�����Щ������Ҫ�Ͷ���������һ��?
����ʵ�ֹ�����ͼ,�������Ͷ�����ϸ������������,���û�������������Ʒ�Ʊ���Ʒ�����SPU����SKU���ȹ�������;
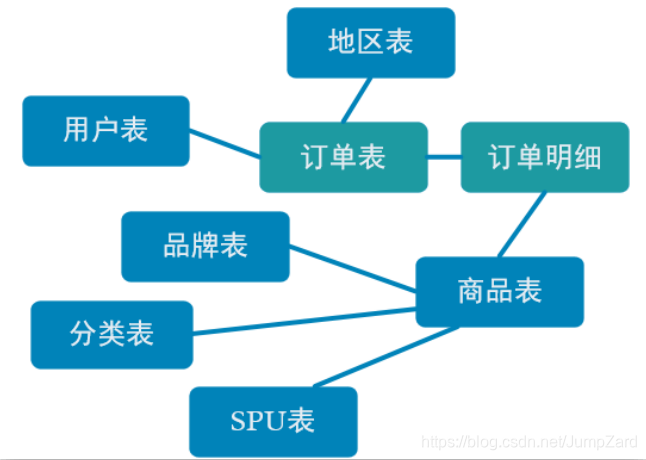
ά�ȱ�����ʵ�����й�����,���Եõ���������Ҫ������֧������;��ô����֮������ν��й�������?�������ǿ���������������ʵ���C�������Ͷ�����ϸ��;
//order_info�����ֶ�����:
CREATE TABLE `order_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '����ID',
`consignee` varchar(100) DEFAULT NULL COMMENT '�ջ���',
`consignee_tel` varchar(20) DEFAULT NULL COMMENT '�ռ��˵绰',
`total_amount` decimal(10,2) DEFAULT NULL COMMENT '�ܽ��',
`order_status` varchar(20) DEFAULT NULL COMMENT '����״̬',
`user_id` bigint(20) DEFAULT NULL COMMENT '�û�id',
`payment_way` varchar(20) DEFAULT NULL COMMENT '���ʽ',
`delivery_address` varchar(1000) DEFAULT NULL COMMENT '�ͻ���ַ',
`order_comment` varchar(200) DEFAULT NULL COMMENT '������ע',
`out_trade_no` varchar(50) DEFAULT NULL COMMENT '�������ױ��(������֧����)',
`trade_body` varchar(200) DEFAULT NULL COMMENT '��������(������֧����)',
`create_time` datetime DEFAULT NULL COMMENT '����ʱ��',
`operate_time` datetime DEFAULT NULL COMMENT '����ʱ��',
`expire_time` datetime DEFAULT NULL COMMENT 'ʧЧʱ��',
`process_status` varchar(20) DEFAULT NULL COMMENT '����״̬',
`tracking_no` varchar(100) DEFAULT NULL COMMENT '���������',
`parent_order_id` bigint(20) DEFAULT NULL COMMENT '���������',
`img_url` varchar(200) DEFAULT NULL COMMENT 'ͼƬ·��',
`province_id` int(20) DEFAULT NULL COMMENT '����',
`activity_reduce_amount` decimal(16,2) DEFAULT NULL COMMENT '�������',
`coupon_reduce_amount` decimal(16,2) DEFAULT NULL COMMENT '�Ż�ȯ',
`original_total_amount` decimal(16,2) DEFAULT NULL COMMENT 'ԭ�۽��',
`feight_fee` decimal(16,2) DEFAULT NULL COMMENT '�˷�',
`feight_fee_reduce` decimal(16,2) DEFAULT NULL COMMENT '�˷Ѽ���',
`refundable_time` datetime DEFAULT NULL COMMENT '���˿�����(ǩ�պ�30��)',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=29549 DEFAULT CHARSET=utf8 COMMENT='������ ������'
//������ϸ������������:
CREATE TABLE `order_detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '���',
`order_id` bigint(20) DEFAULT NULL COMMENT '�������',
`sku_id` bigint(20) DEFAULT NULL COMMENT 'sku_id',
`sku_name` varchar(200) DEFAULT NULL COMMENT 'sku����(����)',
`img_url` varchar(200) DEFAULT NULL COMMENT 'ͼƬ����(����)',
`order_price` decimal(10,2) DEFAULT NULL COMMENT '����۸�(�µ�ʱsku�۸�)',
`sku_num` varchar(200) DEFAULT NULL COMMENT '�������',
`create_time` datetime DEFAULT NULL COMMENT '����ʱ��',
`source_type` varchar(20) DEFAULT NULL COMMENT '��Դ����',
`source_id` bigint(20) DEFAULT NULL COMMENT '��Դ���',
`split_total_amount` decimal(16,2) DEFAULT NULL,
`split_activity_amount` decimal(16,2) DEFAULT NULL,
`split_coupon_amount` decimal(16,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=88048 DEFAULT CHARSET=utf8 COMMENT='������ϸ��'
//��������Ϊ����,һ���ǻ�����Ϣ��,һ���Ƕ�����ϸ����
//������ϸ�����ÿ�������������Ʒ��Ϣ,���綩��������Ʒ��Ӧ����������ϸ��,���ű�����һ��orderNo�ֶΡ�
�������ݿ��Դ�MySql�����ݿ��еĶ�Ӧ���л��;��Ӧ������ʵ���������ɶ�̬��������;
���,���ǿ��Դ�dwd_order_info��dwd_order_detail����������ȥ��ȡ���ǵ���ʵ����,Ȼ����й���;�������ﻹ��Ҫ����Bean Pojo��,�����������е����ݶ�Ӧ��װ,���ݸղ��ᵽ��order_id���з���,Ȼ����inner Join�ķ���,�����������е��ֶκϲ�����;
//�����Ͷ�����ϸ����;
public OrderWide(OrderInfo orderInfo, OrderDetail orderDetail){
mergeOrderInfo(orderInfo);
mergeOrderDetail(orderDetail);
}
//������������Ը�ֵ;
public void mergeOrderInfo(OrderInfo orderInfo ) {
if (orderInfo != null) {
this.order_id = orderInfo.id;
this.order_status = orderInfo.order_status;
this.create_time = orderInfo.create_time;
this.create_date = orderInfo.create_date;
this.activity_reduce_amount = orderInfo.activity_reduce_amount;
this.coupon_reduce_amount = orderInfo.coupon_reduce_amount;
this.original_total_amount = orderInfo.original_total_amount;
this.feight_fee = orderInfo.feight_fee;
this.total_amount = orderInfo.total_amount;
this.province_id = orderInfo.province_id;
this.user_id = orderInfo.user_id;
}
}
//��������ϸ������Ը�ֵ;
public void mergeOrderDetail(OrderDetail orderDetail ) {
if (orderDetail != null) {
this.detail_id = orderDetail.id;
this.sku_id = orderDetail.sku_id;
this.sku_name = orderDetail.sku_name;
this.order_price = orderDetail.order_price;
this.sku_num = orderDetail.sku_num;
this.split_activity_amount=orderDetail.split_activity_amount;
this.split_coupon_amount=orderDetail.split_coupon_amount;
this.split_total_amount=orderDetail.split_total_amount;
}
}
//����ʵ���Ͼ��ǰ���������ϲ�ΪorderWide����Ĺ���,����,���Ǿ��õ�������������ݵij���,������,����ֻ��Ҫȥ��������ά�����ݼ���,������������
//AsyncDataStream.unorderedWait����,ʵ��AsyncFunction(һ���첽����),˳��Ͱ���ͼ���˳��һ��һ����������;
ע��,�����AsyncDataStream.unorderedWait������ʵ��һ���Ż�����,��Ϊphoenix��ѯ���ݱȽ���,��������ά�ȹ�����ʱ��,�������Ż�;
������������ѡ�õ���unorderedWait,��Ϊ���ݵ�˳�������ﲢ����Ҫ;
? ����ȴ�(unorderedWait)
����������,����첽��ѯ�ٶȿ���Գ�������������,�������ܻ����һЩ,���ǻ���������֡�
? ����ȴ�(orderedWait)
�ϸ���������˳��,���Ժ��������ݼ�ʹ�����ҲҪ��ǰ������ݡ��������ܻ��һЩ
�������ҵĴ����еĹ���˳��Ϊ:
�����û�ά�� --�� ����ʡ��ά�� --������SKU��Ʒά�� --������SPUά�� --������Ʒ��ά�� --������Ʒ��ά��,ֻҪ����֮ǰ����ͼ�е�˳������������;ȫ����������֮��,������д�뵽dwm_order_wide������,�����͵õ�����������Ķ���������������;
����һ�������˼·������,��ô�ع�ͷ��,����Ӧ��Ҫ˼��һ������,���ȥ��ȡ��Щά�ȱ���������?������ʵ�������������Ѿ���kafka������л�ȡ,��ô��Щά�ȱ����ݴ�Hbase����λ����?
�������ǵķ�������,����һ����Ҫ����6��ά�ȱ�,���ǿ��Ը���ÿ��ά�ȱ�����дһ��AsyncFunction,���������ȽϷ���,����ֱ�ӷ�װҲ����һ������,����ÿ�����������������ݡ������������������������Dz�ͬ��,��ôȥ��װ��Щ������?�����õ�һ������:ģ�巽�����ģʽ;
//�����������ģ�巽�����ģʽ:
����,������Ҫ֪����Щ�����DZ䶯��:
1.����������;
2.��������;(��ͬά�ȱ������Ը�ֵ����)
��ô���ǿ�����ôȥ˼���������,��Ȼ����ֱ�ӷ�װ,��ô�������õ�ʱ����ȥʵ��������̲��ͺ���;
����˵���Dz�����������̬���ݽ��з�װ,��ֻ���������ݽ��з�װ,�������������趨Ϊ����,������ôʵ��,��Ҫʵ�ֵ�ʱ����д����;
��ôһ���������,���ǾͿ�����ʵ�ֶ�Ӧ��ά�ȱ�����ʱ��ʵ�־���Ĺ�������;
String key = getKey(obj);
//����ά�ȵ�������ά�ȱ��н��в�ѯ
JSONObject dimInfoJsonObj = DimUtil.getDimInfo(tableName, key);
//System.out.println("ά������Json��ʽ:" + dimInfoJsonObj);
if(dimInfoJsonObj != null){
//ά�ȹ��� ���е���ʵ���ݺͲ�ѯ������ά�����ݽ��й���
//����ͬ�����ó�������;
join(obj,dimInfoJsonObj);
//��ʵ�ֵ�DimAsyncFunction����첽���÷���asyncInvokeʱ,���ǿ���getKey��join���������趨Ϊ����,
//��������Ҫȥ�����Ը�ֵ��ʱ��,��ȥ��Ӧʵ������������,�������ֵ���������ͬ��;
Phoenix��ѯ
��Ϊ����ÿ�δ�Phoenix�в�ѯ�������Dz�ͬ��,�����Dz��ܰѲ�ѯ�ķ�������д����,��PhoenixUtil����:
// ��Phoenix�в�ѯ����
// select * from �� where XXX=xxx
//��������Ϊclass;
public static List queryList(String sql,Class clazz){}�ķ�������Ӧ���Dz�ȷ����,�������Ƿ�װ��List�еĶ���ҲӦ���Dz�ȷ����;д����PhoenixUtil��֮��,���������ع�ͷ����
JSONObject dimInfoJsonObj = DimUtil.getDimInfo(tableName, key);���������ʵ�ֵ�:
���뵽DimUtil����,�۲�getDimInfoNoCache����,ʵ����DimUtil�ײ�IJ�ѯ���������Ǹղ�д�õ�PhoenixUtil���queryList����,���Կ��������һ��ʵ�־���ͨ����ƴ�Ӻö�Ӧ�IJ�ѯSql���,Ȼ����Phoenixȥ��Ӧִ�в�ѯ;��ѯ�������������:
select * from dim_base_trademark where id=10 and name=zs;
��������Ҫ����һ������:
��Hbase�IJ�ѯ�ٶ��DZȽ�����,��Ҳ������ǰ�����첽���õ�һ����Ҫԭ��;����������Կ�������һ���Ż�,����·����:
//����������ʵ�ֵĹ�����,ֱ�Ӳ�ѯ�� Hbase���ⲿ����Դ�IJ�ѯ��������ʽ���������ƿ��,����������Ҫ������ʵ�ֵĻ����Ͻ���һ�����Ż�����������ʹ����·���档��·����ģʽ��һ�ַdz������İ�����仺���ģʽ���κ��������ȷ��ʻ���,��������,ֱ�ӻ�����ݷ����������δ������,��ѯ���ݿ�,ͬʱ�ѽ��д�뻺���Ա���������ʹ�á�(redis�����в�ѯ,�������������ڵ�һ�η������ݿ��IJ�ѯЧ��);
//���ֻ�������м���ע���:
//����Ҫ�����ʱ��,��Ȼ�����ݻ᳣פ�����˷���Դ��
//Ҫ����ά�������Ƿ�ᷢ���仯,��������仯Ҫ����������档
//���ﲻ���öѻ�������,��redis��;
��·����ʵ��
//����ά�ȹ�����ʱ��,�ֳ�������ͨ��id���й���,�����ṩһ������,ֻ��Ҫ��id��ֵ��Ϊ��������������
public static JSONObject getDimInfo(String tableName, String id) {
return getDimInfo(tableName, Tuple2.of("id", id));
}
//����֮��������ôһ����ԭ����ԭ��,����Ϊ��Щ��֮��������Ǹ���ID����ֶ������й���,ÿһ��Ҫ������DIW���ж���id����ֶ�(��ǰ�����ñ��оͶ������),ֻ�������id�ڸ���DIM���б�ʾ�ĺ��岻ͬ(���綩��id������id��),���Ǹ��ݲ�ͬ��id����ȡ��ͬ������;ע��,�����id��ͨ��֮ǰ��һ������getKey()��ȡ����,���������id��Ӧ�ľ��Dz�ͬ���еIJ�ͬid�ֶ�,����������ƥ����ϵ�,���õ�������ƥ�䲻��;
����,���δ�Ż�֮ǰ��getDimInfoNoCache����,getDimInfo�ж�������һ���жϹ���,��Redis���Ƿ��ж�Ӧ�Ļ�������,�����ֱ�Ӵ�redis�л�ȡ����,���û��,���Hbase�л�ȡ���ݲ��Ұ����ݵ��뵽redis��,�����key����dim+dim����+��ѯ�ֶ���������;ע��,������������ֻ����id��������,�����ں�����ɾ�����������ʱ��,Ҳֻд��id�����,������IJ�ѯ�ֶ�������id(ֻ�����Ǹ������Լ���id);
�����ﻹҪע��һ����,��redis����Phoenix�в�ѯ����������,��ֹһ��,����������صĽ����һ��List����,����List�е�ÿһ��Ԫ�ؾ��Dz�ѯ�����һ�з�װ�õ�JsonObject����;
����
? �����û�ά�ȹ���
? �� table_process ���е�����ɾ����,ִ��table_process ��ʼ����.sql(��һƪ������Ҳ������)
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '��Դ��',
`operate_type` varchar(200) NOT NULL COMMENT '�������� insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '������� hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '�����(����)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '����ֶ�',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '�����ֶ�',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '������չ',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
? ���� Maxwell��ZK��Kafka��HDFS��Hbase��Redis
? �������� Idea �е� BaseDBApp
? ��ʼ���û�ά�����ݵ� Hbase(ͨ�� Maxwell �� Bootstrap)
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202
--database gmall2021 --table user_info --client_id maxwell_1
? ���� Idea �е� OrderWideApp
? ִ��ģ������ҵ�����ݵ� jar �� ? �鿴����̨������Կ����û��������Լ��Ա�
//���Խ����������:
//��������֮��,��������������:
//>>>>>:1> OrderWide{detail_id=89087, order_id=30441, sku_id=11, order_price=8197.00, sku_num=1,
// sku_name='Apple iPhone 12 (A2404) 64GB ��ɫ ֧���ƶ���ͨ����5G ˫��˫���ֻ�', province_id=31, order_status='1001',
// user_id=1903, total_amount=8286.00, activity_reduce_amount=0.00, coupon_reduce_amount=0.00,
// original_total_amount=8266.00, feight_fee=20.00, split_feight_fee=null, split_activity_amount=null,
// split_coupon_amount=null, split_total_amount=8197.00, expire_time='null', create_time='2021-07-16 20:06:47',
// operate_time='null', create_date='null', create_hour='null', province_name='�Ĵ�', province_area_code='510000',
// province_iso_code='CN-51', province_3166_2_code='CN-SC', user_age=18, user_gender='F', spu_id=3, tm_id=2,
// category3_id=61, spu_name='Apple iPhone 12', tm_name='ƻ��', category3_name='�ֻ�'}
//���Կ���,�������ݶ���������;
//kafka�н��յ�������Ϊ:
//{"activity_reduce_amount":0.00,"category3_id":86,"category3_name":"ƽ�����","coupon_reduce_amount":0.00,
// "create_time":"2021-07-16 10:53:42","detail_id":89306,"feight_fee":7.00,"order_id":30598,
// "order_price":2899.00,"order_status":"1001","original_total_amount":5798.00,"province_3166_2_code":"CN-AH",
// "province_area_code":"340000","province_id":9,"province_iso_code":"CN-34","province_name":"����","sku_id":20,
// "sku_name":"С����E65X 65Ӣ�� ȫ���� 4K������HDR ����ң������С�� 2+8GB AI�˹�����Һ������ƽ����� L65M5-EA",
// "sku_num":2,"split_total_amount":5798.00,"spu_id":6,"spu_name":"С���� ����С�� ��������Һ��ƽ���������",
// "tm_id":5,"tm_name":"��","total_amount":5805.00,"user_age":49,"user_gender":"M","user_id":2113}
//��ʱredis�б������ά�����ݵIJ�ѯ���;һЩȱʧ�������ڽ���kafkaʱ��ɾ����(����operate_time='null', create_date='null'��);
DWM��ҵ�����ʵ�֨C֧������
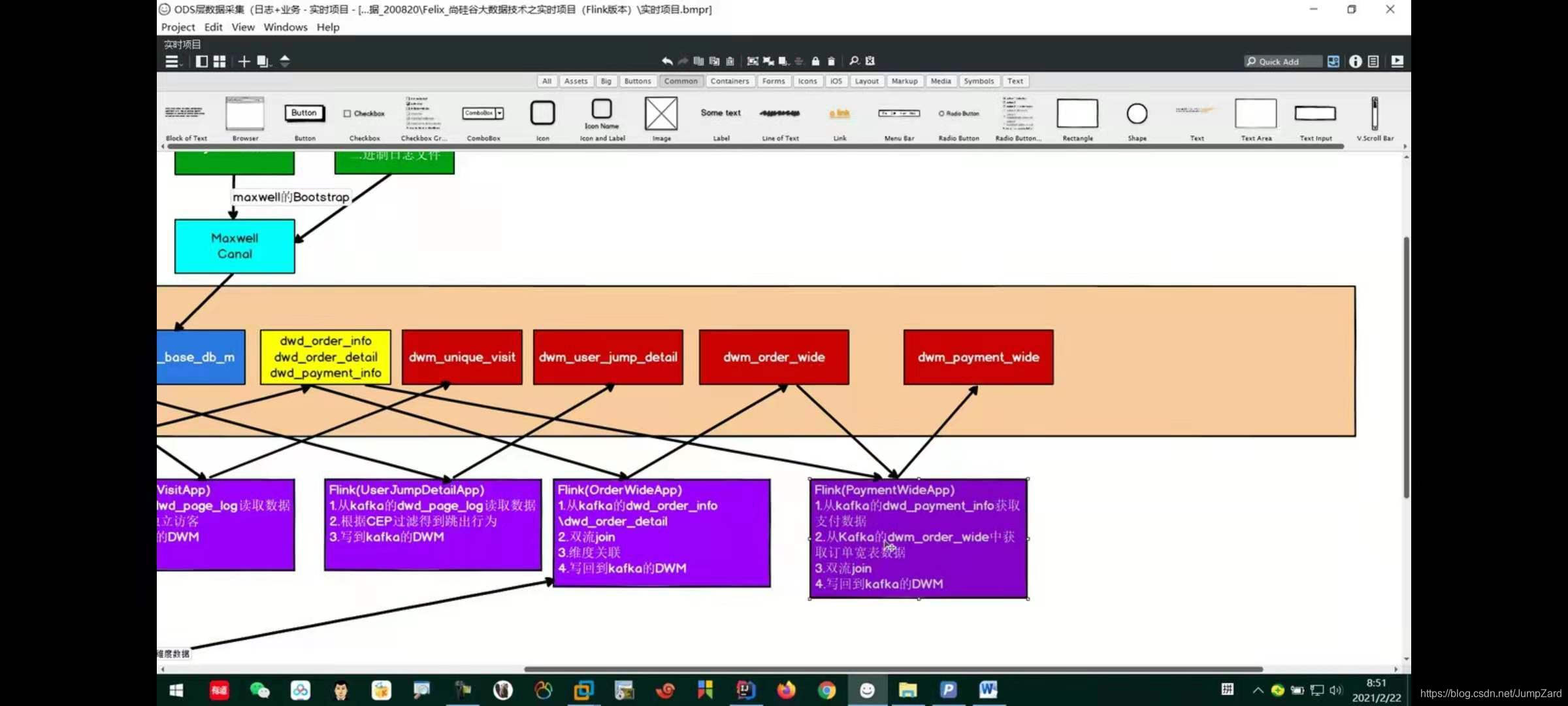
֧��������Ŀ��,����Ҫ��ԭ����֧����û�й�����������ϸ,֧�����û��ϸ�ֵ���Ʒ��,û�а취ͳ����Ʒ����֧��״�������Ա��ο����ĺ��ľ���Ҫ��֧��������Ϣ�붩����ϸ(Ҳ������Ķ�������)�����ϡ�(ͨ��odder_id���й���)
Ϊ�˸���������֧�������Ľ��,�����·��IJ��Թ�����,�Ҹ�����֧�����ղ��������Ķ�������������,�൱�ڴ˴��Ƕ�֧������һ��������չ��
�������������
? һ���ǰѶ������������Hbase��,��֧����������ʱ��ѯhbase,���൱�ڰѶ���������Ϊһ��ά�Ƚ��й�����(���������Ĺ���˼��)
? һ���������ķ�ʽ���ն�����������,Ȼ����˫��join��ʽ���кϲ�����Ϊ������֧��������һ����ʱ����Ա�����intervalJoin����������״̬ʱ��,��֤��֧������ʱ������ϸ��������״̬�С�(�����õڶ��ַ�ʽ,�����ķ�ʽ������ʵʱ����);
����Ĵ�����������Ͳ�չ��������,�Ͷ���������intervalJoin��������һ��,������Խ��������ʾ:
//����://zk��kk��maxwell��hdfs��hbase��BaseDBApp��redis;
//����BaseDBApp;OrderWideApp;��Ӧ��;
//����rt_dblog�µ�ҵ���������ɽű�;
//�����pay��roderwidr����������;
//������������:
//pay>>>>>:4> PaymentInfo{id=19914, order_id=30772, user_id=2312, total_amount=339.00,
// subject='CAREMiLLE��������С���ں� ��������ʪ�־�˿�д��� M02��õ���6����Ʒ', payment_type='1102',
// create_time='2021-07-16 13:05:40', callback_time='2021-07-16 13:06:00'}
//orderWide>>>>:4> OrderWide{detail_id=89344, order_id=30623, sku_id=17, order_price=6699.00, sku_num=1,
// sku_name='TCL 65Q10 65Ӣ�� QLEDԭɫ���ӵ���� �������� AI�����ǻ��� ����ȫ���� MEMC���� 3+32GB ƽ�����',
// province_id=24, order_status='1001', user_id=178, total_amount=6717.00, activity_reduce_amount=0.00,
// coupon_reduce_amount=0.00, original_total_amount=6699.00, feight_fee=18.00, split_feight_fee=null,
// split_activity_amount=null, split_coupon_amount=null, split_total_amount=6699.00, expire_time='null',
// create_time='2021-07-16 13:05:38', operate_time='null', create_date='null', create_hour='null',
// province_name='����', province_area_code='420000', province_iso_code='CN-42', province_3166_2_code='CN-HB',
// user_age=51, user_gender='F', spu_id=5, tm_id=4, category3_id=86,
// spu_name='TCL��Ļ˽��ӰԺ���� 4K������ AI�ǻ��� Һ��ƽ����ӻ�', tm_name='TCL', category3_name='ƽ�����'}
//����2:��������,�鿴һ��dwm_payment_wide������������;
//���ݽ��Ϊ:
//{"activity_reduce_amount":0.00,"callback_time":"2021-07-16 14:22:22","category3_id":61,"category3_name":"�ֻ�",
// "coupon_reduce_amount":0.00,"detail_id":89977,"feight_fee":7.00,"order_create_time":"2021-07-16 14:22:01",
// "order_id":31054,"order_price":1299.00,"order_status":"1001","original_total_amount":3726.00,
// "payment_create_time":"2021-07-16 14:22:02","payment_id":20006,"payment_type":"1102",
// "province_3166_2_code":"CN-GD","province_area_code":"440000","province_id":26,"province_iso_code":"CN-44",
// "province_name":"�㶫","sku_id":6,"sku_name":"Redmi 10X 4G Helio G85��Ϸо 4800�������� 5020mAh����� С��ȫ���� 128GB��洢 8GB+128GB ������ ��Ϸ�����ֻ� С�� ����",
// "sku_num":1,"split_total_amount":1299.00,"spu_id":2,"spu_name":"Redmi 10X",
// "subject":"��ܽ��i-Softto �ں첻��ɫ���ౣʪ���� �貽����ƹⴽ�� Y01���ź� �ٴ����� �貽����ƹⴽ�� ��4����Ʒ",
// "tm_id":1,"tm_name":"Redmi","total_amount":3733.00,"user_age":24,"user_gender":"F","user_id":1431}