��ʶHadoop�����ְ�װģʽ
����Ŀ¼
�ص�:�߿ɿ���(���¶�)����Ч��(�����ٶȿ�)�����ݴ���
- ps:ʹ��Hadoop�汾:
���������õ���Hadoop2.8.5,��ȻĿǰHadoop�Ѿ����µ�3.x��;��������ʼ�ձ���һ���۵㡰�þɲ����¡�,��Ϊ�Ͼ��ɰ汾��Ϊ�ȶ�(Ŀǰ��Ȼjdk�����汾Ϊ16��,�������ǻ��ǻ�ʹ��jdk8��jdk11),��������ʹ�õĸ���Hive��Hbase�ȶ���Ҫ��hadoop�汾���Ӧ,����ȥ�Ҵ�����Դ;��Ȼ�������˾�Ժ�,��˾Ҳ������ṩ����Ӧ�汾��,ֱ���þͿ��ԡ�
Hadoop
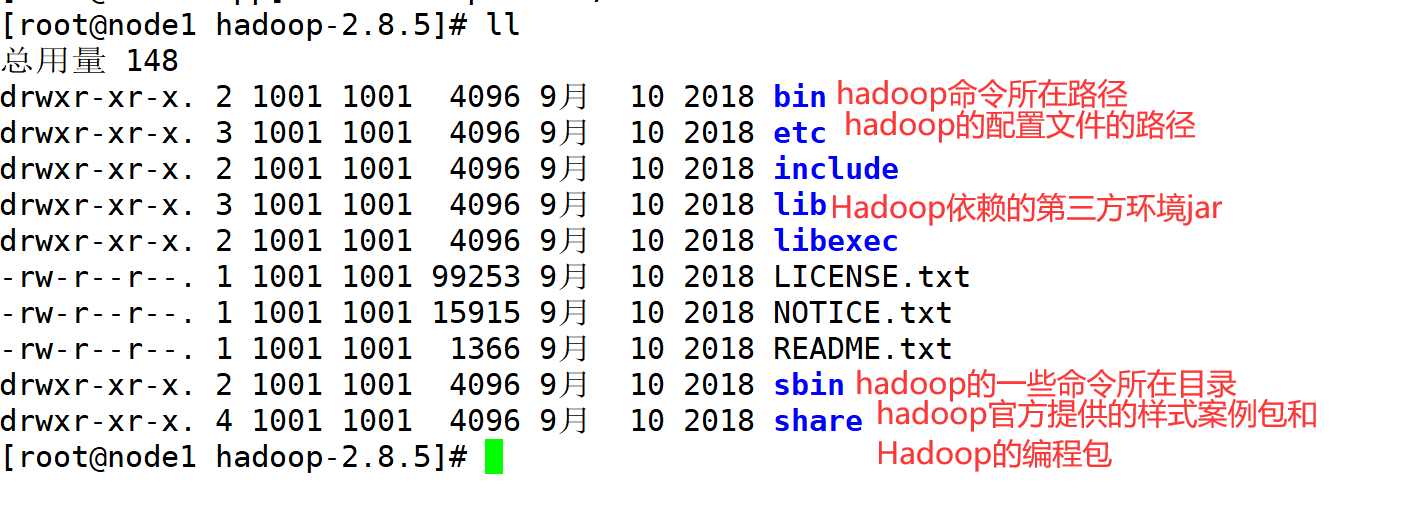
HDFS:�ֲ�ʽ�ļ�ϵͳ����Ҫ��װ
MapReduce:�ֲ�ʽ��������----����Ҫ��װ----������-----��Ҫ����ʵ��
Yarn:�ֲ�ʽ��Դ����ϵͳ----��Ҫ��װ
��װ��ʽ:
- ����ģʽ
- α�ֲ�ʽģʽ��һ̨����
- ��ȫ�ֲ�ʽ
1.����ģʽ����
(��ģʽ��:hdfs��yarn�����ʹ��,ֻ��ʹ��mapreduce-----һ��ֻ��������mapreduce)
һ��ὫĿ¼����Ϊ(/optĿ¼һ���ŵ���������)��app�·Ű�װ������,software�·ŵ�����������ѹ����
- ��ѹhadoopѹ������/opt/appĿ¼��
-
vim /etc/profile������ϵͳ��������(����Hadoop�Ļ�������:Ŀ����Ϊ���ܹ����κ�Ŀ¼�¶���ʹ��hadoop����)
export HADOOP_HOME=/opt/app/hadoop-2.8.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
source /etc/profile hadoop version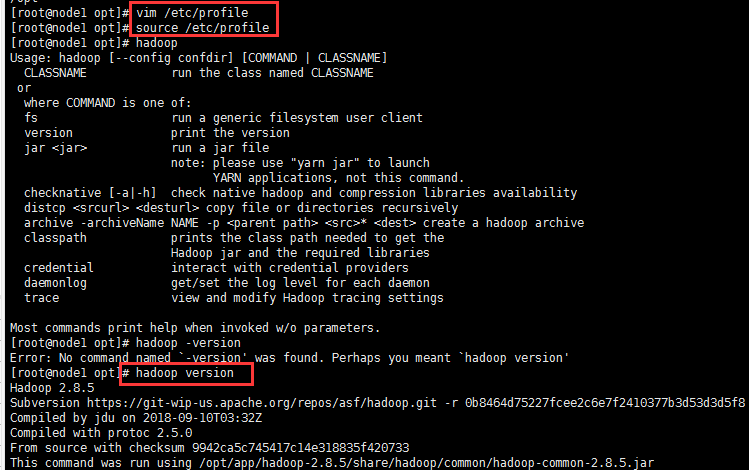
2.α�ֲ�ʽģʽ
(��ģʽ��:hadoop�����hdfs��yarn����һ̨������,��Ҫȥ�������ļ�)
ǰ��:һ������ļ���Ҫ���д洢,��̨������϶��Dz��ܴ洢����ļ���,������ǿ��Խ�����ļ��и�ɼ�������,�ֱ�ŵ���ͬ������ϡ�������ʱ������һ������:��̨�����ϴ洢���ļ�����û����ϵ,���ļ���ô��������? ��ʱ������ÿ�������ϰ�װHDFS���� ����ϵ���塱,����������������ؼ��Լ���HDFS
����ģʽ�C�ֲ�ʽ����:һ�����ڵ�,����ӽڵ�
-
��Ϥ����
-
HDFS{
? NameNode:�洢Ԫ����{�쵼,֪�����ݷŵ�����}
? DataNode:�洢����(Ա��)
? SecondaryNameNode:(����)
}
-
Yarn{
? ResourceManager (�൱��NameNode:�쵼)? NodeManager (�൱��DataNode:Ա��)
}
-
-
������
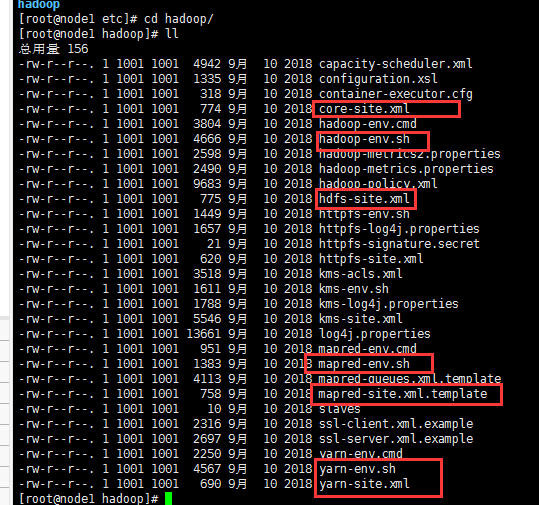
(.sh�ļ�������java������jdk����:����JAVA_HOME=/opt/app/jdk1.8)
(.xml�ļ�������Ӧ����:core(common������)��hdfs��mapred��yarn)
1.core-site.xml
<!--ָ��HDFS��namenode�ĵ�ַ ����ŵ�core-site��,���ܷ���hdfs-site.xml��,������ʹ��hdfs-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.20:9000</value>
</property>
<!--ָ��Hadoop����ʱ������ʱ�ļ��Ĵ洢Ŀ¼-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.8.5/temp</value>
</property>
2.hdfs-site.xml
<!--ָ��HDFS�и���������-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3.mapred-site.xml
<!--ͨ��yarnȥ����-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--ָ��Yarn��ResourceManager��ַ-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.20</value>
</property>
-
��ʽ��NameNode
(�൱�ڴ���core-site.xml��������tempĿ¼)
{ֻ�ܸ�ʽ��1��,�����Ҫ��ʽ���Ļ�,��ô���Խ�������temp�ļ�ɾ��}
hadoop namenode -format
-
����hdfs�����yarn����
start-dfs.sh start-yarn.sh -
������֤
namenode������ַ{http://ip:50070} yarn�ķ�����ַ{http://ip:8088}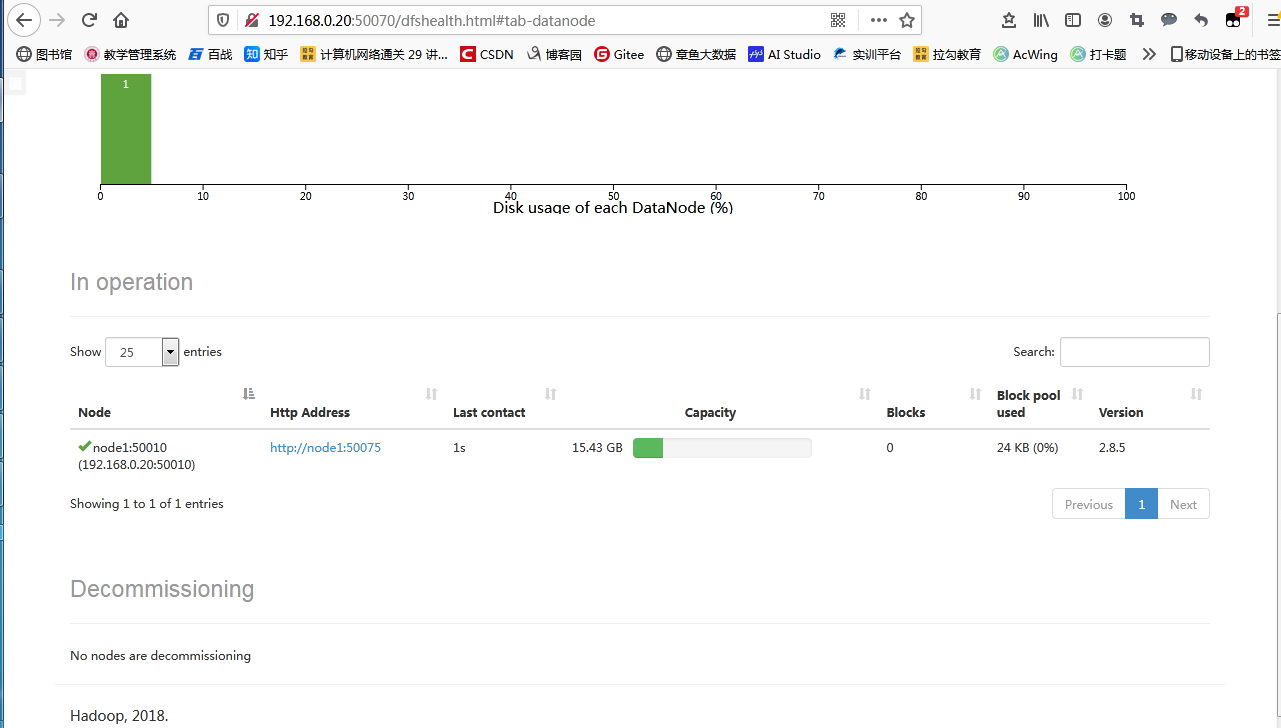
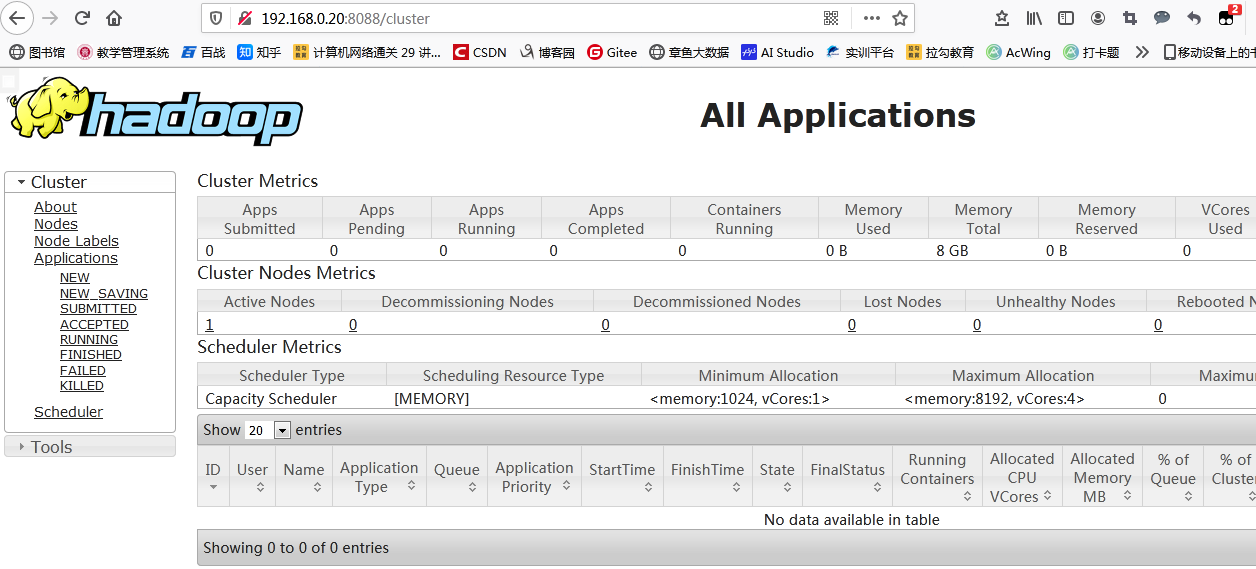
-
����
ͨ�����ַ�ʽ,��ᷢ�������������ڵ�ʱ��Ҫ������������,����Ҫ�����Ļ�,��Ѱ�ҽ����ʽ:
����SSH����Կ��¼
1.������Կ
cd ~/.ssh ssh-keygen -t rsa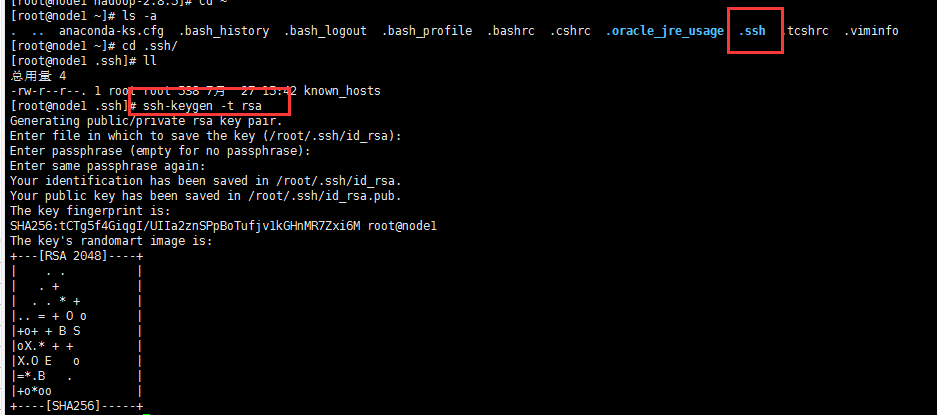
2.�����������
ssh-copy-id 192.168.0.20
3.��ȫ�ֲ�ʽ
(������3̨�ڵ���ɵļ�Ⱥ)----һ������������ʱʹ��
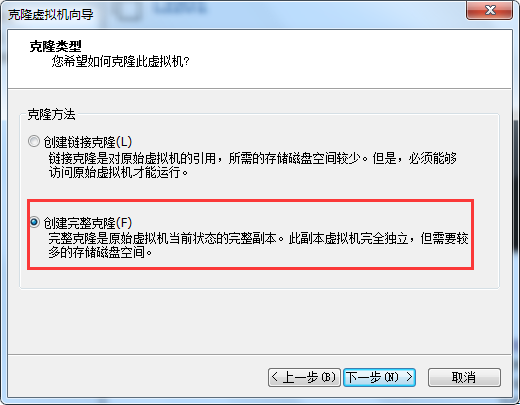
1.��Ҫ��3̨�����:ͨ����¡(����������¡)��ʽ����
2.����3̨������ľ�̬����
192.168.0.20 ��192.168.0.21��192.168.0.22
3.����3̨����������ܵ�¼
��������α�ֲ�ʽ����̸�������ܵ�¼һ��
(�ɹ�����)
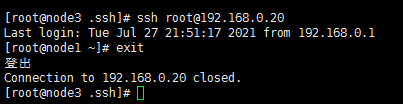
4.ͬ��ʱ��
-
��װntp
yum install -y ntp vim /etc/ntp.conf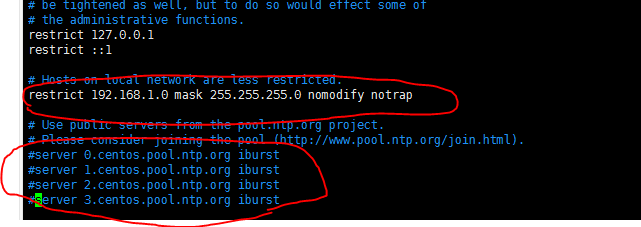
�˴���һ��ԲȦ��,�ҵ�����Ӧ��Ϊ192.168.0.0
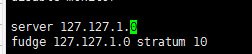
(��������ͼƬΪ��Ҫ��ntp.conf���ĺ����ӵ�)
-
��/etc/sysconfig/ntpd
���Ӵ��� SYNC_HWCLOCK=yes -
���ӳɿ�������
systemctl enable ntpd
Ȼ����node2��node3�����ö�ʱ����
crontab -e
*/1 * * * * /usr/sbin/ntpdate 192.168.0.20
ÿ��1����,ͬ��node1���������ϵ�ʱ��
5.��ʽ��ʼ��Ⱥ����

core-site.xml
<!-- ָ��HDFS��NameNode�ĵ�ַ -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!-- ָ��hadoop����ʱ�����ļ��Ĵ洢Ŀ¼ -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop/temp</value>
</property>
hdfs-site.xml
<configuration>
<!--��3̨�����ϸ�����һ��-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode��ַ-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node3:50090</value>
</property>
<!--hdfsȡ���û�Ȩ��У��-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--���Ϊtrue(Ĭ��ֵ),��namenodeҪ����뽫����datanode�ĵ�ַ����Ϊ������
���datanode���õ��������� ��ô������Բ�����д Ĭ��ֵΪtrue ���DZ������������/etc/hosts�ļ�����������ӳ��
���datanode���õ���IP ��ô��Ҫ�����ֵ��Ϊfalse ����IP�ᵱ����������������ipУ��
ע��:Ĭ�����������hadoopʹ�õ���host+hostName�����÷�ʽ datanode��Ҫ����Ϊ������
-->
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>true</value>
</property>
</configuration>
slaves
vim /opt/app/hadoop/etc/hadoop/slaves
node1
node2
node3
yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--ָ��Yarn��ResourceManager��ַ-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
mapred-site.xml
<configuration>
<!-- ָ��mr������yarn�� -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
��node1�ϸ�����hadoop�����ļ���,��ʼ���зַ�
scp -r /opt/app/hadoop-2.8.5 root@node2:/opt/app
scp -r /opt/app/hadoop-2.8.5 root@node3:/opt/app
�ǵ÷ַ���ÿ�����ǵø�ʽ��Ŷ!(�����ȸ�ʽ���ٷַ���node2��node3�ڵ���)
����ϸ�ڵĻ������������α�ֲ�ʽ���Ѿ�����ϸ��,�ڴ˾Ͳ���˵��,���ԡ������Դ���������!
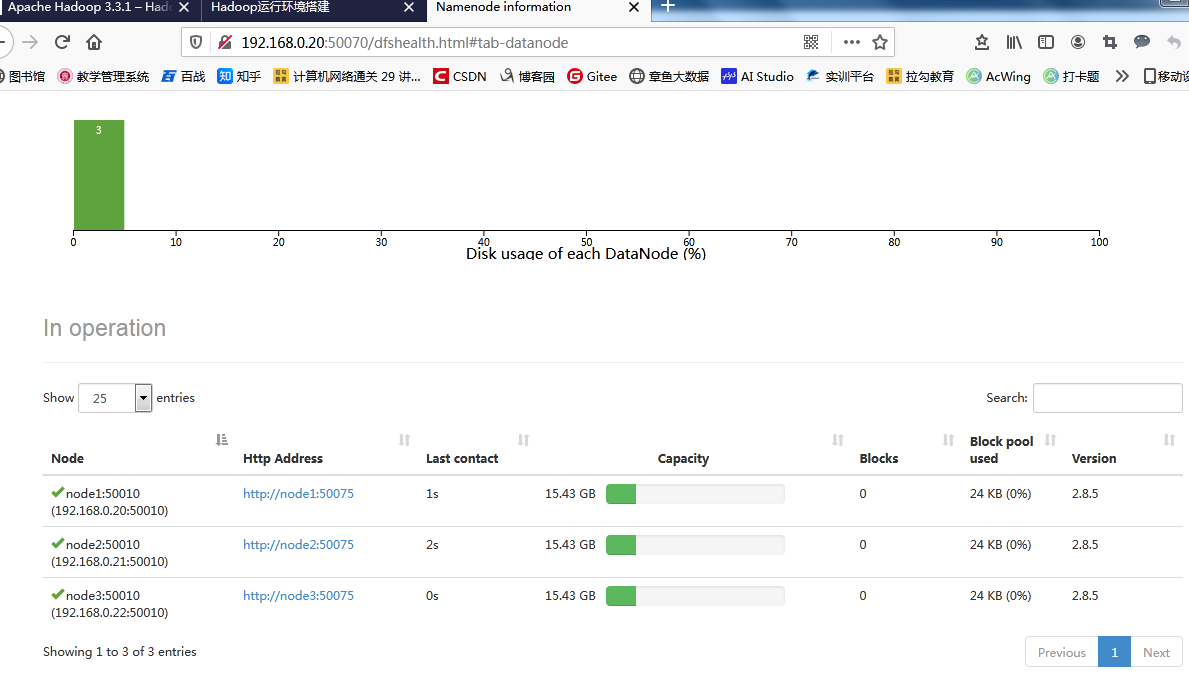
�ɹ���鿴namenode�ɹ�����,���Կ���������3��datanode�ڵ�
?