在Spark 种 有2种 数据分发方式分别是 Hash Shuffle,和BroadCast。
在Spark 种 有3种 join 方式 分别是 SoftMergeJoin, HashJoin,Nested Loop Join 。
所以一共5种join 方式(没有 BroadCast SoftMergeJoin)
为什么没有它呢
相比 SMJ,HJ 并不要求参与 Join 的两张表有序,也不需要维护两个游标来判断当前的记录位置,只要基表在 Build 阶段构建的哈希表可以放进内存,HJ 算法就可以在 Probe 阶段遍历外表,依次与哈希表进行关联当数据能以广播的形式在网络中进行分发时,说明被分发的数据,也就是基表的数据足够小,完全可以放到内存中去。这个时候,相比 NLJ、SMJ,HJ 的执行效率是最高的。因此,在可以采用 HJ 的情况下,Spark 自然就没有必要再去用 SMJ 这种前置开销比较大的方式去完成数据关联。
下面给出一个借张图可以更好观看5种join 方式
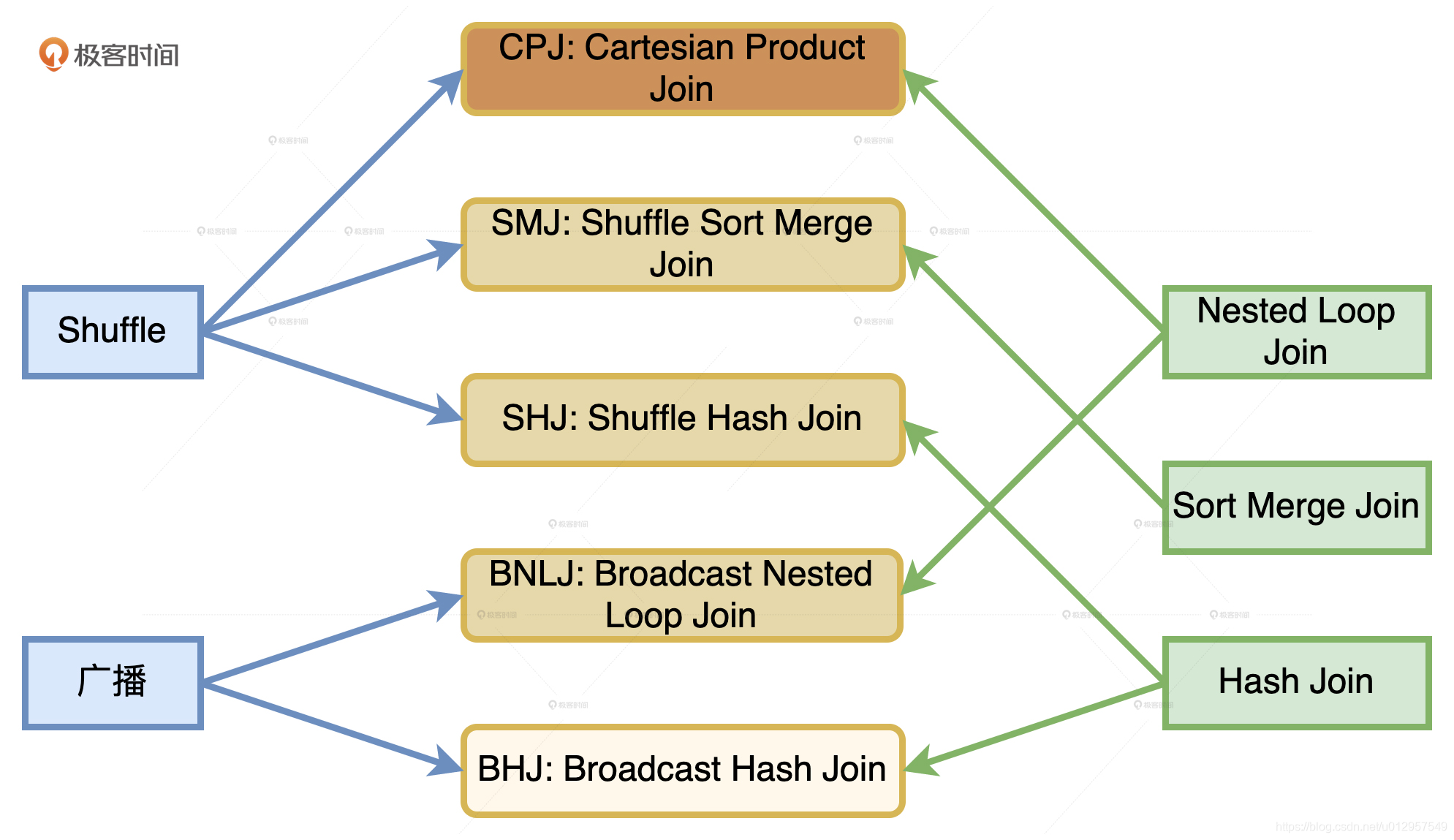
这 5 种 Join 策略,对应图中 5 个圆角矩形,从上到下颜色依次变浅,它们分别是Cartesian Product Join、Shuffle Sort Merge Join 和 Shuffle HashJoin。也就是采用Shuffle 机制实现的 NLJ、SMJ 和 HJ,以及 Broadcast Nested Loop Join和 Broadcast Hash Join。
从执行性能来说,5 种策略从上到下由弱变强。相比之下,CPJ 的执行效率是所有实现方式当中最差的,网络开销、计算开销都很大,因而在图中的颜色也是最深的。BHJ 是最好的分布式数据关联机制,网络开销和计算开销都是最小的,因而颜色也最浅.
NLJ 的工作原理
对于参与关联的两张数据表,我们通常会根据它们扮演的角色来做区分。其中,体量较大、主动扫描数据的表,我们把它称作外表或是驱动表;体量较小、被动参与数据扫描的表,我们管它叫做内表或是基表。那么,NLJ 是如何关联这两张数据表的呢?
NLJ 是采用“嵌套循环”的方式来实现关联的。也就是说,NLJ 会使用内、外两个嵌套的for 循环依次扫描外表和内表中的数据记录,判断关联条件是否满足,
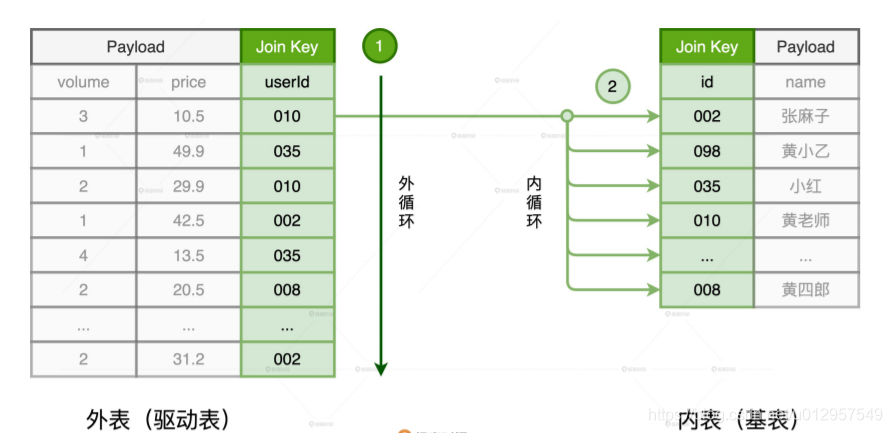
在这个过程中,外层的 for 循环负责遍历外表中的每一条数据,如图中的步骤 1 所示。而对于外表中的每一条数据记录,内层的 for 循环会逐条扫描内表的所有记录,依次判断记录的 Join Key 是否满足关联条件,如步骤 2 所示。假设,外表有 M 行数据,内表有 N 行数据,那么 NLJ 算法的计算复杂度是 O(M * N)。不得不说,尽管 NLJ 实现方式简单而又直接,但它的执行效率实在让人不敢恭维。
SMJ 的工作原理
正是因为 NLJ 极低的执行效率,所以在它推出之后没多久之后,就有人用排序、归并的算法代替 NLJ 实现了数据关联,这种算法就是 SMJ。SMJ 的思路是先排序、再归并。具体来说,就是参与 Join 的两张表先分别按照 Join Key 做升序排序。然后,SMJ 会使用两个独立的游标对排好序的两张表完成归并关联。
SMJ 刚开始工作的时候,内外表的游标都会先锚定在两张表的第一条记录上,然后再对比游标所在记录的 Join Key。对比结果以及后续操作主要分为 3 种情况:
-
外表 Join Key 等于内表 Join Key,满足关联条件,把两边的数据记录拼接并输出,然 后把外表的游标滑动到下一条记录
-
外表Join Key 小于内表 Join Key,不满足关联条件,把外表的游标滑动到下一条记录
-
外表 Join Key 大于内表 Join Key,不满足关联条件,把内表的游标滑动到下一条记录
SMJ 正是基于这 3 种情况,不停地向下滑动游标,直到某张表的游标滑到头,即宣告关联结束。对于 SMJ 中外表的每一条记录,由于内表按 Join Key 升序排序,且扫描的起始位置为游标所在位置,因此 SMJ 算法的计算复杂度为 O(M + N)。
不过,SMJ 计算复杂度的降低,仰仗的是两张表已经事先排好序。要知道,排序本身就是一项非常耗时的操作,更何况,为了完成归并关联,参与 Join 的两张表都需要排序。因此,SMJ 的计算过程我们可以用“先苦后甜”来容。苦的是要先花费时间给两张表做排序,甜的是有序表的归并关联能够享受到线性的计算复杂度。
HJ 的工作原理
考虑到 SMJ 对排序的要求比较苛刻,所以后来又有人提出了效率更高的关联算法:HJ。HJ 的设计初衷非常明确:把内表扫描的计算复杂度降低至O(1)。把一个数据集合的访问效率提升至 O(1),也只有 Hash Map 能做到了。也正因为 Join 的关联过程引入了 Hash计算,所以它叫 HJ。
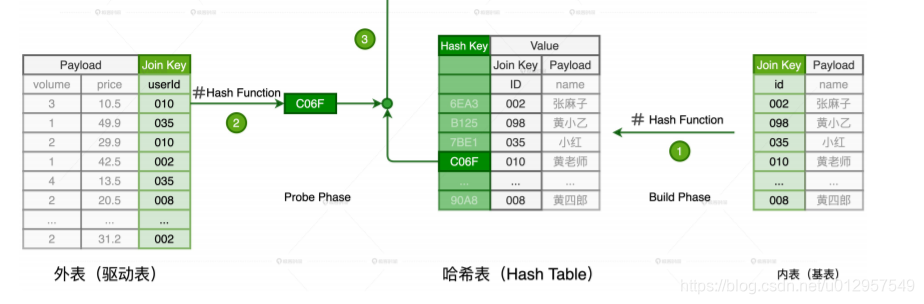
HJ 的计算分为两个阶段,分别是 Build 阶段和 Probe 阶段。在 Build 阶段,基于内表,算法使用既定的哈希函数构建哈希表,如上图的步骤 1 所示。哈希表中的 Key 是 Join Key应用(Apply)哈希函数之后的哈希值,表中的 Value 同时包含了原始的 Join Key 和Payload。在 Probe 阶段,算法遍历每一条数据记录,先是使用同样的哈希函数,以动态的方式(On The Fly)计算 Join Key 的哈希值。然后,用计算得到的哈希值去查询刚刚在 Build阶段创建好的哈希表。如果查询失败,说明该条记录与维度表中的数据不存在关联关系;如果查询成功,则继续对比两边的 Join Key。如果 Join Key 一致,就把两边的记录进行拼接并输出,从而完成数据关联。
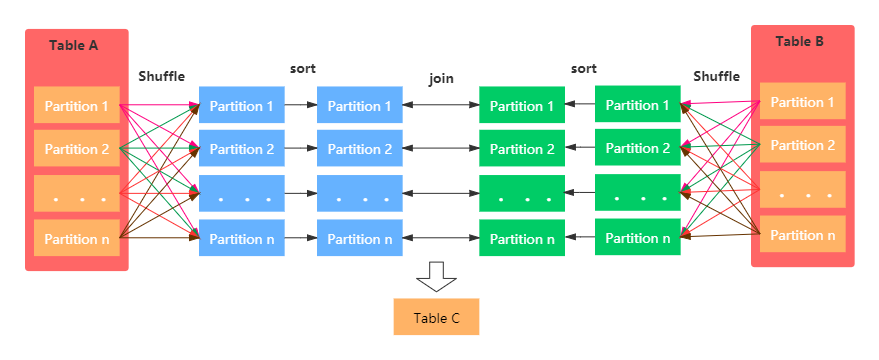
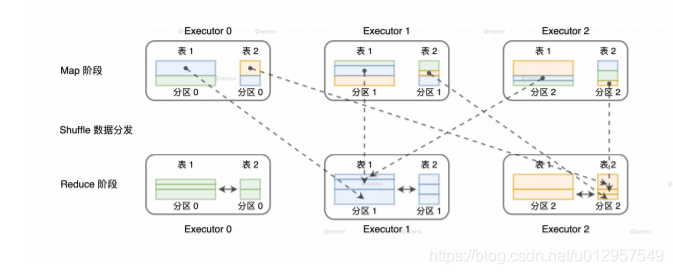
相比单机环境,分布式环境中的数据关联在计算环节依然遵循着 NLJ、SMJ 和 HJ 这 3 种实现方式,只不过是增加了网络分发这一变数。在 Spark的分布式计算环境中,数据在网络中的分发主要有两种方式,分别是 Shuffle 和广播。那么,不同的网络分发方式,对于数据关联的计算又都有哪些影响呢?如果采用 Shuffle 的分发方式来完成数据关联,那么外表和内表都需要按照 Join Key 在集群中做全量的数据分发。因为只有这样,两个数据表中 Join Key 相同的数据记录才能分配到同一个 Executor 进程,从而完成关联计算,如下图所示。
如果采用广播机制的话,情况会大有不同。在这种情况下,Spark 只需要把内表(基表)封装到广播变量,然后在全网进行分发。由于广播变量中包含了内表的全量数据,因此体量较大的外表只要“待在原地、保持不动”,就能轻松地完成关联计算,如下图所示。