Flink 社区很早就设想过将批数据看作一个有界流数据,将批处理看作流计算的一个特例,从而实现流批统一,Flink 社区的开发人员在多轮讨论后,基本敲定了Flink 未来的技术架构
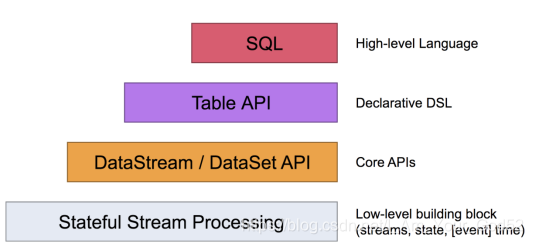
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。
Table API 是用于 Scala 和 Java 语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。
Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。这两种 API 中的查询对于批(DataSet)和流(DataStream)的输入有相同的语义,也会产生同样的计算结果。
Table API 和 SQL 两种 API 是紧密集成的,以及 DataStream 和 DataSet API。你可以在这些 API 之间,以及一些基于这些 API 的库之间轻松的切换。比如,你可以先用 CEP 从 DataStream 中做模式匹配,然后用 Table API 来分析匹配的结果;或者你可以用 SQL 来扫描、过滤、聚合一个批式的表,然后再跑一个 Gelly 图算法 来处理已经预处理好的数据。
注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。
一.核心概念
Flink 的 Table API 和 SQL 是流批统一的 API。 这意味着 Table API & SQL 在无论有限的批式输入还是无限的流式输入下,都具有相同的语义。 因为传统的关系代数以及 SQL 最开始都是为了批式处理而设计的, 关系型查询在流式场景下不如在批式场景下容易理解.
1.1动态表和连续查询
动态表(Dynamic Tables) 是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。
与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个连续查询(Continuous Query)。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。
需要注意的是,连续查询的结果在语义上总是等价于以批处理模式在输入表快照上执行的相同查询的结果。

1.将流转换为动态表。
2.在动态表上计算一个连续查询,生成一个新的动态表。
3.生成的动态表被转换回流。
1.2在流上定义表(动态表)
为了使用关系查询处理流,必须将其转换成 Table。从概念上讲,流的每条记录都被解释为对结果表的 INSERT 操作。
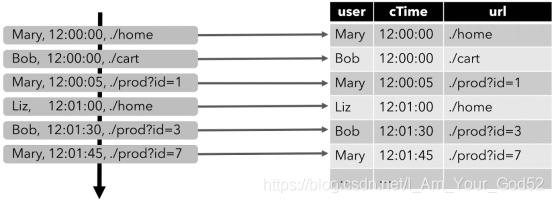
假设有如下格式的数据:
[
user: VARCHAR, // 用户名
cTime: TIMESTAMP, // 访问 URL 的时间
url: VARCHAR // 用户访问的 URL
]
下图显示了单击事件流(左侧)如何转换为表(右侧)。当插入更多的单击流记录时,结果表的数据将不断增长。
连续查询
在动态表上计算一个连续查询,并生成一个新的动态表。与批处理查询不同,连续查询从不终止,并根据其输入表上的更新更新其结果表。
在任何时候,连续查询的结果在语义上与以批处理模式在输入表快照上执行的相同查询的结果相同。

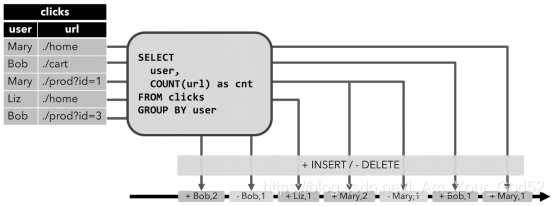
说明:
1.当查询开始,clicks 表(左侧)是空的。
2.当第一行数据被插入到 clicks 表时,查询开始计算结果表。第一行数据 [Mary,./home] 插入后,结果表(右侧,上部)由一行 [Mary, 1] 组成。
3.当第二行 [Bob, ./cart] 插入到 clicks 表时,查询会更新结果表并插入了一行新数据 [Bob, 1]。
4.第三行 [Mary, ./prod?id=1] 将产生已计算的结果行的更新,[Mary, 1] 更新成 [Mary, 2]。
5.最后,当第四行数据加入 clicks 表时,查询将第三行 [Liz, 1] 插入到结果表中。
二.Flink Table API
2.1导入需要的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
2.2基本使用:表与DataStream的混合使用

import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.$;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink01_TableApi_BasicUse {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
// 1. 创建表的执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2. 创建表: 将流转换成动态表. 表的字段名从pojo的属性名自动抽取
Table table = tableEnv.fromDataStream(waterSensorStream);
// 3. 对动态表进行查询
Table resultTable = table
.where($("id").isEqual("sensor_1"))
.select($("id"), $("ts"), $("vc"));
// 4. 把动态表转换成流
DataStream<Row> resultStream = tableEnv.toAppendStream(resultTable, Row.class);
resultStream.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.3基本使用:聚合操作
// 3. 对动态表进行查询
Table resultTable = table
.where($("vc").isGreaterOrEqual(20))
.groupBy($("id"))
.aggregate($("vc").sum().as("vc_sum"))
.select($("id"), $("vc_sum"));
// 4. 把动态表转换成流 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记
DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);
2.4表到流的转换
动态表可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。它可能是一个只有一行、不断更新的表,也可能是一个 insert-only 的表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
Append-only 流
仅通过 INSERT 操作修改的动态表可以通过输出插入的行转换为流。
Retract 流
retract 流包含两种类型的 message: add messages 和 retract messages 。通过将INSERT 操作编码为 add message、将 DELETE 操作编码为 retract message、将 UPDATE 操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,将动态表转换为 retract 流。下图显示了将动态表转换为 retract 流的过程。
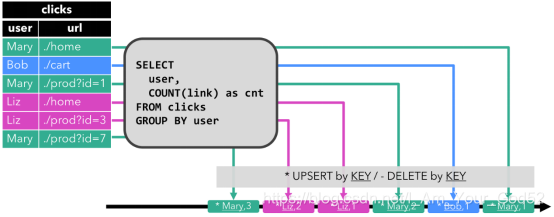
Upsert 流
upsert 流包含两种类型的 message: upsert messages 和delete messages。转换为 upsert 流的动态表需要(可能是组合的)唯一键。通过将 INSERT 和 UPDATE 操作编码为 upsert message,将 DELETE 操作编码为 delete message ,将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 upsert 流的过程。
请注意,在将动态表转换为 DataStream 时,只支持 append 流和 retract 流。
2.5通过Connector声明读入数据
前面是先得到流, 再转成动态表, 其实动态表也可以直接连接到数据
File source
// 2. 创建表
// 2.1 表的元数据信息
Schema schema = new Schema()
.field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc", DataTypes.INT());
// 2.2 连接文件, 并创建一个临时表, 其实就是一个动态表
tableEnv.connect(new FileSystem().path("input/sensor.txt"))
.withFormat(new Csv().fieldDelimiter(',').lineDelimiter("\n"))
.withSchema(schema)
.createTemporaryTable("sensor");
// 3. 做成表对象, 然后对动态表进行查询
Table sensorTable = tableEnv.from("sensor");
Table resultTable = sensorTable
.groupBy($("id"))
.select($("id"), $("id").count().as("cnt"));
// 4. 把动态表转换成流. 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记
DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);
resultStream.print();
Kafka Source
// 2. 创建表
// 2.1 表的元数据信息
Schema schema = new Schema()
.field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc", DataTypes.INT());
// 2.2 连接文件, 并创建一个临时表, 其实就是一个动态表
tableEnv
.connect(new Kafka()
.version("universal")
.topic("sensor")
.startFromLatest()
.property("group.id", "bigdata")
.property("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"))
.withFormat(new Json())
.withSchema(schema)
.createTemporaryTable("sensor");
// 3. 对动态表进行查询
Table sensorTable = tableEnv.from("sensor");
Table resultTable = sensorTable
.groupBy($("id"))
.select($("id"), $("id").count().as("cnt"));
// 4. 把动态表转换成流. 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记
DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);
resultStream.print();
2.6通过Connector声明写出数据
File Sink
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.Schema;
import static org.apache.flink.table.api.Expressions.$;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink02_TableApi_ToFileSystem {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
// 1. 创建表的执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table sensorTable = tableEnv.fromDataStream(waterSensorStream);
Table resultTable = sensorTable
.where($("id").isEqual("sensor_1") )
.select($("id"), $("ts"), $("vc"));
// 创建输出表
Schema schema = new Schema()
.field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc", DataTypes.INT());
tableEnv
.connect(new FileSystem().path("output/sensor_id.txt"))
.withFormat(new Csv().fieldDelimiter('|'))
.withSchema(schema)
.createTemporaryTable("sensor");
// 把数据写入到输出表中
resultTable.executeInsert("sensor");
}
}
Kafka Sink
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Json;
import org.apache.flink.table.descriptors.Kafka;
import org.apache.flink.table.descriptors.Schema;
import static org.apache.flink.table.api.Expressions.$;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink03_TableApi_ToKafka {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
// 1. 创建表的执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table sensorTable = tableEnv.fromDataStream(waterSensorStream);
Table resultTable = sensorTable
.where($("id").isEqual("sensor_1") )
.select($("id"), $("ts"), $("vc"));
// 创建输出表
Schema schema = new Schema()
.field("id", DataTypes.STRING())
.field("ts", DataTypes.BIGINT())
.field("vc", DataTypes.INT());
tableEnv
.connect(new Kafka()
.version("universal")
.topic("sink_sensor")
.sinkPartitionerRoundRobin()
.property("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"))
.withFormat(new Json())
.withSchema(schema)
.createTemporaryTable("sensor");
// 把数据写入到输出表中
resultTable.executeInsert("sensor");
}
}
2.7其他Connector用法
参考官方文档: https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/connect.html
三.Flink SQL
3.1基本使用
查询未注册的表
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink05_SQL_BaseUse {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 使用sql查询未注册的表
Table inputTable = tableEnv.fromDataStream(waterSensorStream);
Table resultTable = tableEnv.sqlQuery("select * from " + inputTable + " where id='sensor_1'");
tableEnv.toAppendStream(resultTable, Row.class).print();
env.execute();
}
}
查询已注册的表
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink05_SQL_BaseUse_2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 使用sql查询一个已注册的表
// 1. 从流得到一个表
Table inputTable = tableEnv.fromDataStream(waterSensorStream);
// 2. 把注册为一个临时视图
tableEnv.createTemporaryView("sensor", inputTable);
// 3. 在临时视图查询数据, 并得到一个新表
Table resultTable = tableEnv.sqlQuery("select * from sensor where id='sensor_1'");
// 4. 显示resultTable的数据
tableEnv.toAppendStream(resultTable, Row.class).print();
env.execute();
}
}
3.2Kafka到Kafka
使用sql从Kafka读数据, 并写入到Kafka中
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink05_SQL_Kafka2Kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1. 注册SourceTable: source_sensor
tableEnv.executeSql("create table source_sensor (id string, ts bigint, vc int) with("
+ "'connector' = 'kafka',"
+ "'topic' = 'topic_source_sensor',"
+ "'properties.bootstrap.servers' = 'hadoop162:9029,hadoop163:9092,hadoop164:9092',"
+ "'properties.group.id' = 'atguigu',"
+ "'scan.startup.mode' = 'latest-offset',"
+ "'format' = 'json'"
+ ")");
// 2. 注册SinkTable: sink_sensor
tableEnv.executeSql("create table sink_sensor(id string, ts bigint, vc int) with("
+ "'connector' = 'kafka',"
+ "'topic' = 'topic_sink_sensor',"
+ "'properties.bootstrap.servers' = 'hadoop162:9029,hadoop163:9092,hadoop164:9092',"
+ "'format' = 'json'"
+ ")");
// 3. 从SourceTable 查询数据, 并写入到 SinkTable
tableEnv.executeSql("insert into sink_sensor select * from source_sensor where id='sensor_1'");
}
}
四.时间属性
像窗口(在 Table API 和 SQL )这种基于时间的操作,需要有时间信息。因此,Table API 中的表就需要提供逻辑时间属性来表示时间,以及支持时间相关的操作。
4.1处理时间
DataStream 到 Table 转换时定义
处理时间属性可以在 schema 定义的时候用 .proctime 后缀来定义。时间属性一定不能定义在一个已有字段上,所以它只能定义在 schema 定义的最后
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
// 1. 创建表的执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 声明一个额外的字段来作为处理时间字段
Table sensorTable = tableEnv.fromDataStream(waterSensorStream, $("id"), $("ts"), $("vc"), $("pt").proctime());
sensorTable.print();
env.execute();
在创建表的 DDL 中定义
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink06_TableApi_ProcessTime {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 创建表的执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建表, 声明一个额外的列作为处理时间
tableEnv.executeSql("create table sensor(id string,ts bigint,vc int,pt_time as PROCTIME()) with("
+ "'connector' = 'filesystem',"
+ "'path' = 'input/sensor.txt',"
+ "'format' = 'csv'"
+ ")");
TableResult result = tableEnv.executeSql("select * from sensor");
result.print();
}
}
4.2事件时间
事件时间允许程序按照数据中包含的时间来处理,这样可以在有乱序或者晚到的数据的情况下产生一致的处理结果。它可以保证从外部存储读取数据后产生可以复现(replayable)的结果。
除此之外,事件时间可以让程序在流式和批式作业中使用同样的语法。在流式程序中的事件时间属性,在批式程序中就是一个正常的时间字段。
为了能够处理乱序的事件,并且区分正常到达和晚到的事件,Flink 需要从事件中获取事件时间并且产生 watermark(watermarks)。
DataStream 到 Table 转换时定义
事件时间属性可以用 .rowtime 后缀在定义 DataStream schema 的时候来定义。时间戳和 watermark 在这之前一定是在 DataStream 上已经定义好了。
在从 DataStream 到 Table 转换时定义事件时间属性有两种方式。取决于用 .rowtime 后缀修饰的字段名字是否是已有字段,事件时间字段可以是:
1.在 schema 的结尾追加一个新的字段
2.替换一个已经存在的字段。
不管在哪种情况下,事件时间字段都表示 DataStream 中定义的事件的时间戳。
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink07_TableApi_EventTime {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> waterSensorStream = env
.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60))
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((element, recordTimestamp) -> element.getTs())
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table table = tableEnv
// 用一个额外的字段作为事件时间属性
.fromDataStream(waterSensorStream, $("id"), $("ts"), $("vc"), $("et").rowtime());
table.execute().print();
env.execute();
}
}
// 使用已有的字段作为时间属性
.fromDataStream(waterSensorStream, $("id"), $("ts").rowtime(), $("vc"));
在创建表的 DDL 中定义
事件时间属性可以用 WATERMARK 语句在 CREATE TABLE DDL 中进行定义。WATERMARK 语句在一个已有字段上定义一个 watermark 生成表达式,同时标记这个已有字段为时间属性字段.
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @Author lizhenchao@atguigu.cn
* @Date 2021/1/11 21:43
*/
public class Flink07_TableApi_EventTime_2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 作为事件时间的字段必须是 timestamp 类型, 所以根据 long 类型的 ts 计算出来一个 t
tEnv.executeSql("create table sensor(" +
"id string," +
"ts bigint," +
"vc int, " +
"t as to_timestamp(from_unixtime(ts/1000,'yyyy-MM-dd HH:mm:ss'))," +
"watermark for t as t - interval '5' second)" +
"with("
+ "'connector' = 'filesystem',"
+ "'path' = 'input/sensor.txt',"
+ "'format' = 'csv'"
+ ")");
tEnv.sqlQuery("select * from sensor").execute().print();
}
}
说明:
1.把一个现有的列定义为一个为表标记事件时间的属性。该列的类型必须为 TIMESTAMP(3),且是 schema 中的顶层列,它也可以是一个计算列。
2.严格递增时间戳: WATERMARK FOR rowtime_column AS rowtime_column。
3.递增时间戳: WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘0.001’ SECOND。
4.有界乱序时间戳: WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘string’ timeUnit。
五.窗口(window)
时间语义,要配合窗口操作才能发挥作用。最主要的用途,当然就是开窗口然后根据时间段做计算了。
下面我们就来看看Table API和SQL中,怎么利用时间字段做窗口操作。
在Table API和SQL中,主要有两种窗口:Group Windows和Over Windows
5.1Table API中使用窗口
Group Windows
分组窗口(Group Windows)会根据时间或行计数间隔,将行聚合到有限的组(Group)中,并对每个组的数据执行一次聚合函数。
Table API中的Group Windows都是使用.window(w:GroupWindow)子句定义的,并且必须由as子句指定一个别名。为了按窗口对表进行分组,窗口的别名必须在group by子句中,像常规的分组字段一样引用。
滚动窗口
public class Flink08_TableApi_Window_1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> waterSensorStream = env
.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60))
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((element, recordTimestamp) -> element.getTs())
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table table = tableEnv
.fromDataStream(waterSensorStream, $("id"), $("ts").rowtime(), $("vc"));
table
.window(Tumble.over(lit(10).second()).on($("ts")).as("w")) // 定义滚动窗口并给窗口起一个别名
.groupBy($("id"), $("w")) // 窗口必须出现的分组字段中
.select($("id"), $("w").start(), $("w").end(), $("vc").sum())
.execute()
.print();
env.execute();
}
}
#滑动窗口
.window(Slide.over(lit(10).second()).every(lit(5).second()).on($("ts")).as("w"))
#会话窗口
.window(Session.withGap(lit(6).second()).on($("ts")).as("w"))
Over Windows
Over window聚合是标准SQL中已有的(Over子句),可以在查询的SELECT子句中定义。Over window 聚合,会针对每个输入行,计算相邻行范围内的聚合。
Table API提供了Over类,来配置Over窗口的属性。可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义Over windows。
无界的over window是使用常量指定的。也就是说,时间间隔要指定UNBOUNDED_RANGE,或者行计数间隔要指定UNBOUNDED_ROW。而有界的over window是用间隔的大小指定的。
Unbounded Over Windows
public class Flink09_TableApi_OverWindow_1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> waterSensorStream = env
.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60))
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((element, recordTimestamp) -> element.getTs())
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table table = tableEnv
.fromDataStream(waterSensorStream, $("id"), $("ts").rowtime(), $("vc"));
table
.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(UNBOUNDED_ROW).as("w"))
.select($("id"), $("ts"), $("vc").sum().over($("w")).as("sum_vc"))
.execute()
.print();
env.execute();
}
}
#使用UNBOUNDED_RANGE
.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(UNBOUNDED_RANGE).as("w"))
说明:
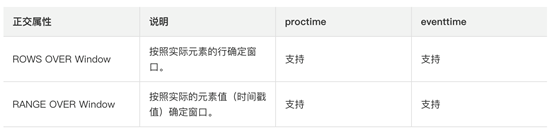
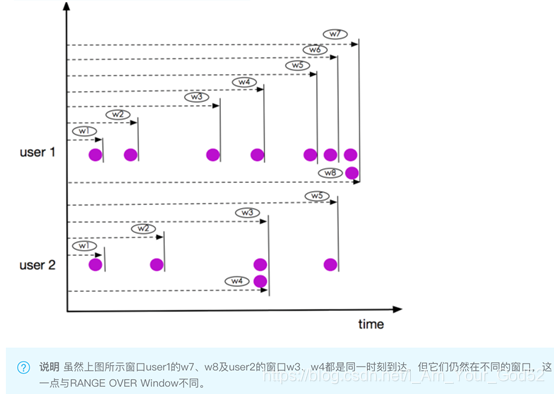
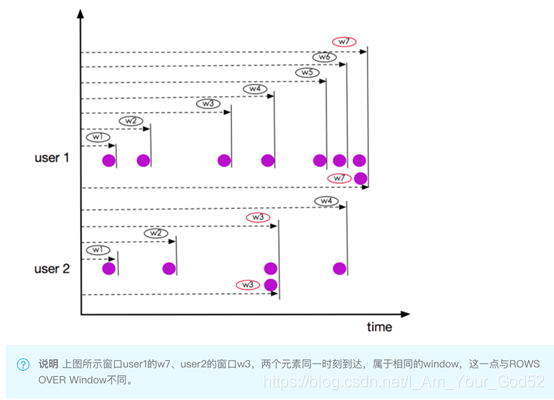
Bounded Over Windows
// 当事件时间向前算3s得到一个窗口
.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(lit(3).second()).as("w"))
// 当行向前推算2行算一个窗口
.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(rowInterval(2L)).as("w"))
5.2SQL API中使用窗口
Group Windows
SQL 查询的分组窗口是通过 GROUP BY 子句定义的。类似于使用常规 GROUP BY 语句的查询,窗口分组语句的 GROUP BY 子句中带有一个窗口函数为每个分组计算出一个结果。以下是批处理表和流处理表支持的分组窗口函数:
分组窗口函数 描述
TUMBLE(time_attr, interval) 定义一个滚动窗口。滚动窗口把行分配到有固定持续时间( interval )的不重叠的连续窗口。比如,5 分钟的滚动窗口以 5 分钟为间隔对行进行分组。滚动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。
HOP(time_attr, interval, interval) 定义一个跳跃的时间窗口(在 Table API 中称为滑动窗口)。滑动窗口有一个固定的持续时间( 第二个 interval 参数 )以及一个滑动的间隔(第一个 interval 参数 )。若滑动间隔小于窗口的持续时间,滑动窗口则会出现重叠;因此,行将会被分配到多个窗口中。比如,一个大小为 15 分组的滑动窗口,其滑动间隔为 5 分钟,将会把每一行数据分配到 3 个 15 分钟的窗口中。滑动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。
SESSION(time_attr, interval) 定义一个会话时间窗口。会话时间窗口没有一个固定的持续时间,但是它们的边界会根据 interval 所定义的不活跃时间所确定;即一个会话时间窗口在定义的间隔时间内没有时间出现,该窗口会被关闭。例如时间窗口的间隔时间是 30 分钟,当其不活跃的时间达到30分钟后,若观测到新的记录,则会启动一个新的会话时间窗口(否则该行数据会被添加到当前的窗口),且若在 30 分钟内没有观测到新纪录,这个窗口将会被关闭。会话时间窗口可以使用事件时间(批处理、流处理)或处理时间(流处理)。

StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 作为事件时间的字段必须是 timestamp 类型, 所以根据 long 类型的 ts 计算出来一个 t
tEnv.executeSql("create table sensor(" +
"id string," +
"ts bigint," +
"vc int, " +
"t as to_timestamp(from_unixtime(ts/1000,'yyyy-MM-dd HH:mm:ss'))," +
"watermark for t as t - interval '5' second)" +
"with("
+ "'connector' = 'filesystem',"
+ "'path' = 'input/sensor.txt',"
+ "'format' = 'csv'"
+ ")");
tEnv
.sqlQuery(
"SELECT id, " +
" TUMBLE_START(t, INTERVAL '1' minute) as wStart, " +
" TUMBLE_END(t, INTERVAL '1' minute) as wEnd, " +
" SUM(vc) sum_vc " +
"FROM sensor " +
"GROUP BY TUMBLE(t, INTERVAL '1' minute), id"
)
.execute()
.print();
tEnv
.sqlQuery(
"SELECT id, " +
" hop_start(t, INTERVAL '1' minute, INTERVAL '1' hour) as wStart, " +
" hop_end(t, INTERVAL '1' minute, INTERVAL '1' hour) as wEnd, " +
" SUM(vc) sum_vc " +
"FROM sensor " +
"GROUP BY hop(t, INTERVAL '1' minute, INTERVAL '1' hour), id"
)
.execute()
.print();
Over Windows
tEnv
.sqlQuery(
"select " +
"id," +
"vc," +
"sum(vc) over(partition by id order by t rows between 1 PRECEDING and current row)" +
"from sensor"
)
.execute()
.print();
tEnv
.sqlQuery(
"select " +
"id," +
"vc," +
"count(vc) over w, " +
"sum(vc) over w " +
"from sensor " +
"window w as (partition by id order by t rows between 1 PRECEDING and current row)"
)
.execute()
.print();
六.Catalog
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。 元数据也可以是持久化的,例如 Hive Metastore 中的元数据。Catalog 提供了一个统一的API,用于管理元数据,并使其可以从 Table API 和 SQL 查询语句中来访问。
前面用到Connector其实就是在使用Catalog
6.1Catalog类型
GenericInMemoryCatalog
GenericInMemoryCatalog 是基于内存实现的 Catalog,所有元数据只在 session 的生命周期内可用。
JdbcCatalog
JdbcCatalog 使得用户可以将 Flink 通过 JDBC 协议连接到关系数据库。PostgresCatalog 是当前实现的唯一一种 JDBC Catalog。
HiveCatalog
HiveCatalog 有两个用途:作为原生 Flink 元数据的持久化存储,以及作为读写现有 Hive 元数据的接口。 Flink 的 Hive 文档 提供了有关设置 HiveCatalog 以及访问现有 Hive 元数据的详细信息。
6.2HiveCatalog
导入需要的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
在hadoop162启动hive元数据
nohup hive --service metastore >/dev/null 2>&1 &
连接 Hive
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
String name = "myhive"; // Catalog 名字
String defaultDatabase = "flink_test"; // 默认数据库
String hiveConfDir = "c:/conf"; // hive配置文件的目录. 需要把hive-site.xml添加到该目录
// 1. 创建HiveCatalog
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
// 2. 注册HiveCatalog
tEnv.registerCatalog(name, hive);
// 3. 把 HiveCatalog: myhive 作为当前session的catalog
tEnv.useCatalog(name);
tEnv.useDatabase("flink_test");
tEnv.sqlQuery("select * from stu").execute().print();
七.函数(function)
Flink 允许用户在 Table API 和 SQL 中使用函数进行数据的转换。
7.1内置函数
Flink Table API和SQL给用户提供了大量的函数用于数据转换.
Scalar Functions(标量函数)
输入: 0个1个或多个
输出: 1个
Comparison Functions(比较函数)
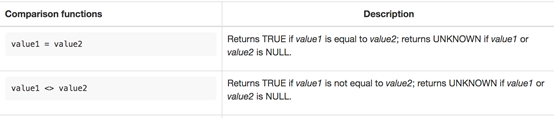
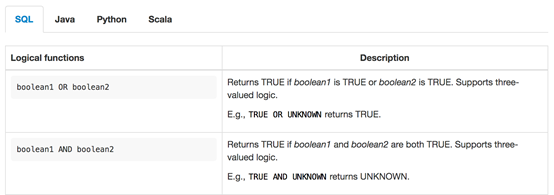
Logical Functions(逻辑函数)
Aggregate Functions(聚合函数)
其他所有内置函数
参考官网: https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/functions/systemFunctions.html
7.2自定义函数
自定义函数(UDF)是一种扩展开发机制,可以用来在查询语句里调用难以用其他方式表达的频繁使用或自定义的逻辑。
自定义函数分类:
1)标量函数(Scalar functions) 将标量值转换成一个新标量值;
2)表值函数(Table functions) 将标量值转换成新的行数据;
3)聚合函数(Aggregate functions) 将多行数据里的标量值转换成一个新标量值;
4)表值聚合函数(Table aggregate) 将多行数据里的标量值转换成新的行数据;
5)异步表值函数(Async table functions) 是异步查询外部数据系统的特殊函数。
函数用于 SQL 查询前要先经过注册;而在用于 Table API 时,函数可以先注册后调用,也可以 内联 后直接使用。
标量函数
介绍
用户定义的标量函数,可以将0、1或多个标量值,映射到新的标量值。
为了定义标量函数,必须在org.apache.flink.table.functions中扩展基类Scalar Function,并实现(一个或多个)求值(evaluation,eval)方法。标量函数的行为由求值方法决定,求值方法必须公开声明并命名为eval(直接def声明,没有override)。求值方法的参数类型和返回类型,确定了标量函数的参数和返回类型。
定义函数
// 定义一个可以把字符串转成大写标量函数
public static class ToUpperCase extends ScalarFunction {
public String eval(String s){
return s.toUpperCase();
}
}
在TableAPI中使用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> stream = env.fromElements("hello", "atguigu", "Hello");
Table table = tEnv.fromDataStream(stream, $("word"));
// 1. table api 使用方式1: 不注册直接 inline 使用
table.select(call(ToUpperCase.class, $("word")).as("word_upper")).execute().print();
// 2. table api 使用方式2: 注册后使用
// 2.1 注册函数
tEnv.createTemporaryFunction("toUpper", ToUpperCase.class);
// 2.2 使用函数
table.select(call("toUpper", $("word")).as("word_upper")).execute().print();
在SQL中使用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> stream = env.fromElements("hello", "atguigu", "Hello");
Table table = tEnv.fromDataStream(stream, $("word"));
// 1. 注册临时函数
tEnv.createTemporaryFunction("toUpper", ToUpperCase.class);
// 2. 注册临时表
tEnv.createTemporaryView("t_word", table);
// 3. 在临时表上使用自定义函数查询
tEnv.sqlQuery("select toUpper(word) word_upper from t_word").execute().print();
表值函数
介绍
跟自定义标量函数一样,自定义表值函数的输入参数也可以是 0 到多个标量。但是跟标量函数只能返回一个值不同的是,它可以返回任意多行。返回的每一行可以包含 1 到多列,如果输出行只包含 1 列,会省略结构化信息并生成标量值,这个标量值在运行阶段会隐式地包装进行里。
要定义一个表值函数,你需要扩展 org.apache.flink.table.functions 下的 TableFunction,可以通过实现多个名为 eval 的方法对求值方法进行重载。像其他函数一样,输入和输出类型也可以通过反射自动提取出来。表值函数返回的表的类型取决于 TableFunction 类的泛型参数 T,不同于标量函数,表值函数的求值方法本身不包含返回类型,而是通过 collect(T) 方法来发送要输出的行。
在 Table API 中,表值函数是通过 .joinLateral(…) 或者 .leftOuterJoinLateral(…) 来使用的。joinLateral 算子会把外表(算子左侧的表)的每一行跟跟表值函数返回的所有行(位于算子右侧)进行 (cross)join。leftOuterJoinLateral 算子也是把外表(算子左侧的表)的每一行跟表值函数返回的所有行(位于算子右侧)进行(cross)join,并且如果表值函数返回 0 行也会保留外表的这一行。
在 SQL 里面用 JOIN 或者 以 ON TRUE 为条件的 LEFT JOIN 来配合 LATERAL TABLE() 的使用。
其实就是以前的UDTF函数
定义函数
@FunctionHint(output = @DataTypeHint("ROW(word string, len int)"))
public static class Split extends TableFunction<Row> {
public void eval(String line) {
if (line.length() == 0) {
return;
}
for (String s : line.split(",")) {
// 来一个字符串, 按照逗号分割, 得到多行, 每行为这个单词和他的长度
collect(Row.of(s, s.length()));
}
}
}
在TableAPI中使用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> stream = env.fromElements("hello,atguigu,world", "aaa,bbbbb", "");
Table table = tEnv.fromDataStream(stream, $("line"));
// 1. 内联使用
table
.joinLateral(call(Split.class, $("line")))
.select($("line"), $("word"), $("len"))
.execute()
.print();
table
.leftOuterJoinLateral(call(Split.class, $("line")))
.select($("line"), $("word"), $("len"))
.execute()
.print();
// 2. 注册后使用
tEnv.createTemporaryFunction("split", Split.class);
table
.joinLateral(call("split", $("line")))
.select($("line"), $("word"), $("len"))
.execute()
.print();

在SQL中使用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> stream = env.fromElements("hello,atguigu,world", "aaa,bbbbb", "");
Table table = tEnv.fromDataStream(stream, $("line"));
// 1. 注册表
tEnv.createTemporaryView("t_word", table);
// 2. 注册函数
tEnv.createTemporaryFunction("split", Split.class);
// 3. 使用函数
// 3.1 join
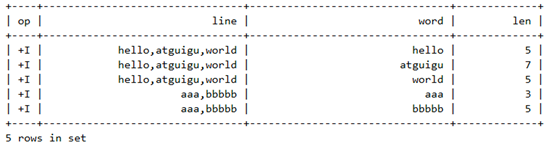
tEnv.sqlQuery("select " +
" line, word, len " +
"from t_word " +
"join lateral table(split(line)) on true").execute().print();
// 或者
tEnv.sqlQuery("select " +
" line, word, len " +
"from t_word, " +
"lateral table(split(line))").execute().print();
// 3.2 left join
tEnv.sqlQuery("select " +
" line, word, len " +
"from t_word " +
"left join lateral table(split(line)) on true").execute().print();
// 3.3 join或者left join给字段重命名
tEnv.sqlQuery("select " +
" line, new_word, new_len " +
"from t_word " +
"left join lateral table(split(line)) as T(new_word, new_len) on true").execute().print();
聚合函数
介绍
用户自定义聚合函数(User-Defined Aggregate Functions,UDAGGs)可以把一个表中的数据,聚合成一个标量值。用户定义的聚合函数,是通过继承AggregateFunction抽象类实现的。
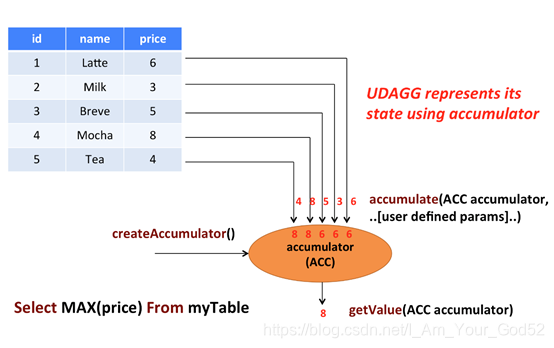
上图中显示了一个聚合的例子。
假设现在有一张表,包含了各种饮料的数据。该表由三列(id、name和price)、五行组成数据。现在我们需要找到表中所有饮料的最高价格,即执行max()聚合,结果将是一个数值。
AggregateFunction的工作原理如下。
1)首先,它需要一个累加器,用来保存聚合中间结果的数据结构(状态)。可以通过调用AggregateFunction的createAccumulator()方法创建空累加器。
2)随后,对每个输入行调用函数的accumulate()方法来更新累加器。
3)处理完所有行后,将调用函数的getValue()方法来计算并返回最终结果。
AggregationFunction要求必须实现的方法:
1)createAccumulator()
2)accumulate()
3)getValue()
除了上述方法之外,还有一些可选择实现的方法。其中一些方法,可以让系统执行查询更有效率,而另一些方法,对于某些场景是必需的。例如,如果聚合函数应用在会话窗口(session group window)的上下文中,则merge()方法是必需的。
1)retract() 在 bounded OVER 窗口中是必须实现的。
2)merge()
3)resetAccumulator() 在许多批式聚合中是必须实现的。
定义函数
定义一个计算sensor平均温度的函数
// 累加器类型
public static class VcAvgAcc {
public Integer sum = 0;
public Long count = 0L;
}
public static class VcAvg extends AggregateFunction<Double, VcAvgAcc> {
// 返回最终的计算结果
@Override
public Double getValue(VcAvgAcc accumulator) {
return accumulator.sum * 1.0 / accumulator.count;
}
// 初始化累加器
@Override
public VcAvgAcc createAccumulator() {
return new VcAvgAcc();
}
// 处理输入的值, 更新累加器
// 参数1: 累加器
// 参数2,3,...: 用户自定义的输入值
public void accumulate(VcAvgAcc acc, Integer vc) {
acc.sum += vc;
acc.count += 1L;
}
}
在Table API中使用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
Table table = tEnv.fromDataStream(waterSensorStream);
// 1. 内联使用
table
.groupBy($("id"))
.select($("id"), call(VcAvg.class, $("vc")))
.execute()
.print();
// 2. 注册后使用
tEnv.createTemporaryFunction("my_avg", VcAvg.class);
table
.groupBy($("id"))
.select($("id"), call("my_avg", $("vc")))
.execute()
.print();
在SQL中使用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
Table table = tEnv.fromDataStream(waterSensorStream);
// 在sql中使用
// 1. 注册表
tEnv.createTemporaryView("t_sensor", table);
// 2. 注册函数
tEnv.createTemporaryFunction("my_avg", VcAvg.class);
// 3. sql中使用自定义聚合函数
tEnv.sqlQuery("select id, my_avg(vc) from t_sensor group by id").execute().print();
表值聚合函数
介绍
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。
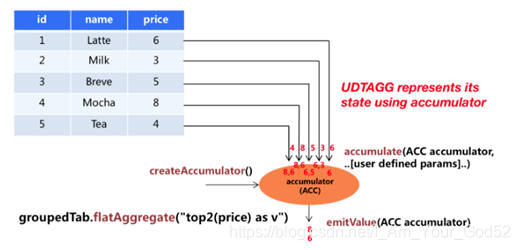
比如现在我们需要找到表中所有饮料的前2个最高价格,即执行top2()表聚合。我们需要检查5行中的每一行,得到的结果将是一个具有排序后前2个值的表。
用户定义的表聚合函数,是通过继承TableAggregateFunction抽象类来实现的。
TableAggregateFunction的工作原理如下。
1)首先,它同样需要一个累加器(Accumulator),它是保存聚合中间结果的数据结构。通过调用TableAggregateFunction的createAccumulator()方法可以创建空累加器。
2)随后,对每个输入行调用函数的accumulate()方法来更新累加器。
3)处理完所有行后,将调用函数的emitValue()方法来计算并返回最终结果。
AggregationFunction要求必须实现的方法:
1)createAccumulator()
2)accumulate()
除了上述方法之外,还有一些可选择实现的方法。
1)retract()
2)merge()
3)resetAccumulator()
4)emitValue()
5)emitUpdateWithRetract()
定义函数
接下来我们写一个自定义TableAggregateFunction,用来提取每个sensor最高的两个温度值。
// 累加器
public static class Top2Acc {
public Integer first = Integer.MIN_VALUE; // top 1
public Integer second = Integer.MIN_VALUE; // top 2
}
// Tuple2<Integer, Integer> 值和排序
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Acc> {
@Override
public Top2Acc createAccumulator() {
return new Top2Acc();
}
public void accumulate(Top2Acc acc, Integer vc) {
if (vc > acc.first) {
acc.second = acc.first;
acc.first = vc;
} else if (vc > acc.second) {
acc.second = vc;
}
}
public void emitValue(Top2Acc acc, Collector<Tuple2<Integer, Integer>> out) {
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
在Table API中使用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<WaterSensor> waterSensorStream =
env.fromElements(new WaterSensor("sensor_1", 1000L, 10),
new WaterSensor("sensor_1", 2000L, 20),
new WaterSensor("sensor_2", 3000L, 30),
new WaterSensor("sensor_1", 4000L, 40),
new WaterSensor("sensor_1", 5000L, 50),
new WaterSensor("sensor_2", 6000L, 60));
Table table = tEnv.fromDataStream(waterSensorStream);
// 1. 内联使用
table
.groupBy($("id"))
.flatAggregate(call(Top2.class, $("vc")).as("v", "rank"))
.select($("id"), $("v"), $("rank"))
.execute()
.print();
// 2. 注册后使用
tEnv.createTemporaryFunction("top2", Top2.class);
table
.groupBy($("id"))
.flatAggregate(call("top2", $("vc")).as("v", "rank"))
.select($("id"), $("v"), $("rank"))
.execute()
.print();
在SQL中使用
目前还不支持
八.SqlClient
启动换一个yarn-session, 然后启动一个sql客户端.
bin/sql-client.sh embedded
建立到Kafka的连接
下面创建一个流表从Kafka读取数据
copy 依赖到 flink的lib 目录下 flink-sql-connector-kafka_2.11-1.12.0.jar 下载地址: https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.12.0/flink-sql-connector-kafka_2.11-1.12.0.jar
create table sensor(id string, ts bigint, vc int)
with(
'connector'='kafka',
'topic'='flink_sensor',
'properties.bootstrap.servers'='hadoop162:9092',
'properties.group.id'='atguigu',
'format'='json',
'scan.startup.mode'='latest-offset'
)
从流表查询数据
select * from sensor;

向Kafka写入数据: {“id”: “sensor1”, “ts”: 1000, “vc”: 10}

建立到mysql的连接
依赖: flink-connector-jdbc_2.11-1.12.0.jar
下载地址: https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-jdbc_2.11/1.12.0/flink-connector-jdbc_2.11-1.12.0.jar
copy mysql驱动到lib目录
create table sensor(id string, ts bigint, vc int)
with(
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop162:3306/gmall',
'username'='root',
'password'='aaaaaa',
'table-name' = 'sensor'
)