版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
目录
之前详细讲解了,Zookeeper和HDFS,从下面开始来继续Hadoop系列的另外一个组件,MapReduce。
MapReduce计算模型介绍
理解MapReduce思想
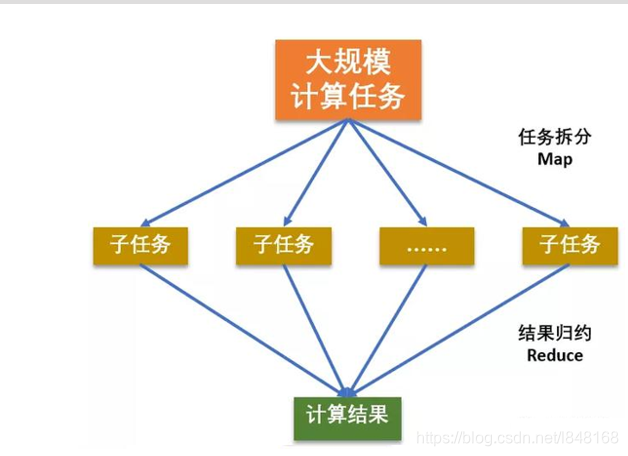
MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“ 分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
Map负责“分” ,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合” ,即对map阶段的结果进行全局汇总。
这两个阶段合起来正是MapReduce思想的体现。
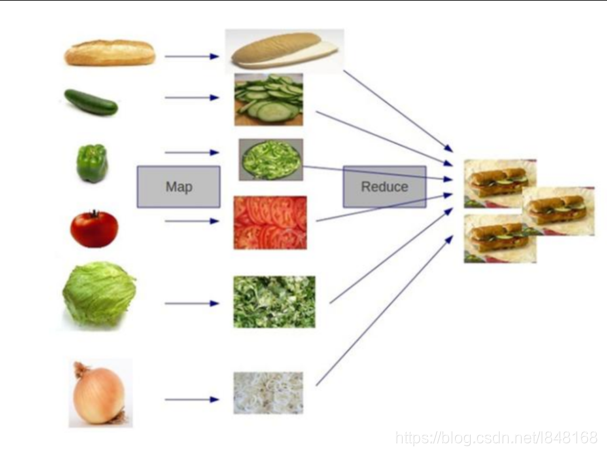
还有一个比较形象的语言解释MapReduce:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
MapReduce的运行需要由Yarn集群来提供资源调度。
Hadoop MapReduce设计构思
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop的yarn集群上。
既然是做计算的框架,那么表现形式就是有个输入(input),MapReduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output)。
对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而MapReduce就是一种简化并行计算的编程模型,降低了开发并行应用的入门门槛。
Hadoop MapReduce构思体现在如下的三个方面:
如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。并行计算
的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不
可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
构建抽象模型:Map和Reduce
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对Map的中间结果进行某种进一步的结果整理。
MapReduce中定义了如下的Mapper和Reducer两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。通过以上两个编程接口,大家可以看出
MapReduce处理的数据类型是<key,value>键值对。
统一构架,隐藏系统层细节
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划
分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程
序员隐藏了绝大多数系统层面的处理细节。
MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架。程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
MapReduce编程规范及示例编写
编程规范
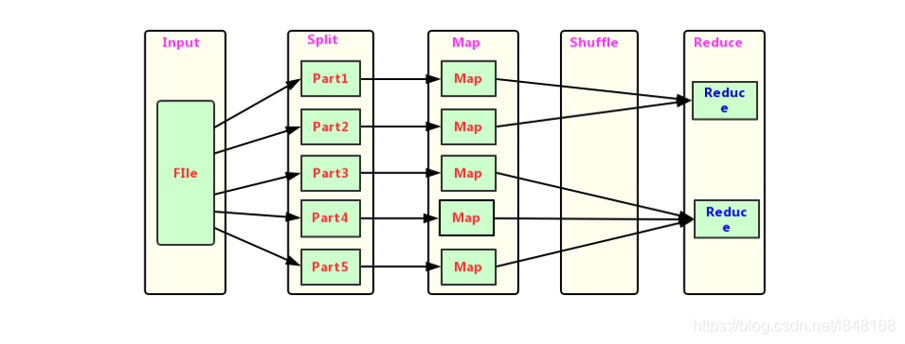
MapReduce 的开发一共有八个步骤, 其中 Map 阶段分为2个步骤,Shuffle 阶段 4 个步骤,Reduce 阶段分为2个步骤
Map阶段2个步骤
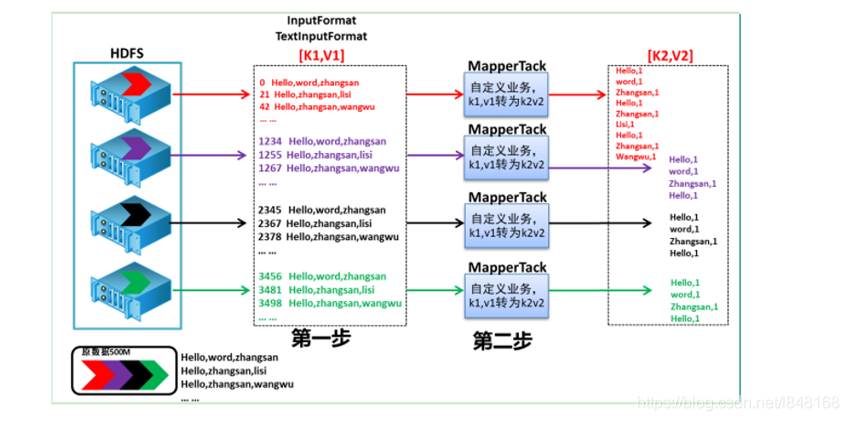
1、 设置 InputFormat 类, 读取输入文件内容,对输入文件的每一行,解析成key、value对(K1和V1)。
2、 自定义map方法,每一个键值对调用一次map方法,将第一步的K1和V1结果转换成另外的 Key-Value(K2和V2)对, 输出结果。
Shuffle 阶段 4 个步骤
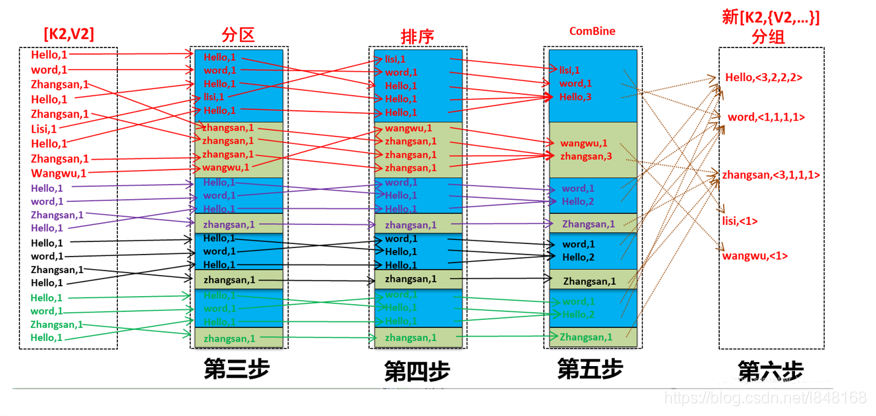
3、 对map阶段输出的k2和v2对进行分区
4、 对不同分区的数据按照相同的Key排序
5、 (可选)对数据进行局部聚合, 降低数据的网络拷贝
6、 对数据进行分组, 相同Key的Value放入一个集合中,得到K2和[V2]
Reduce 阶段 2 个步骤
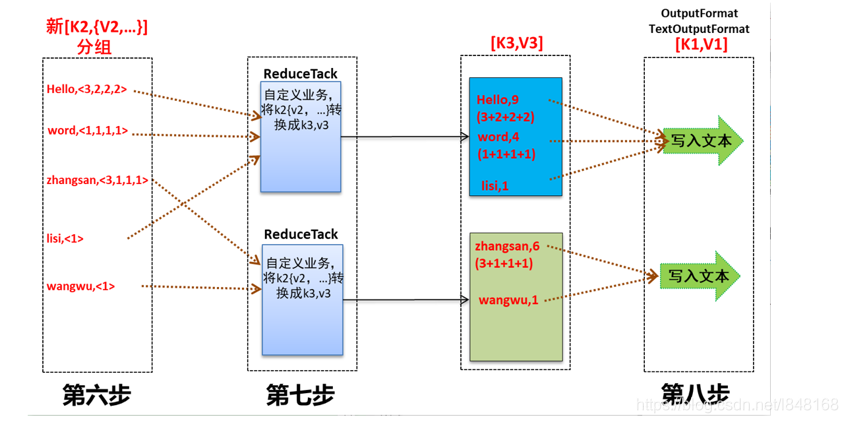
7、 对map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
8、 对多个map任务的输出进行合并、排序。编写reduce方法,在此方法中将K2和[V2]进行处理,转换成新的key、value(K3和V3)输出,并把reduce的输出保存到文件中。
编程步骤
用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
Mapper
(1) 自定义类继承Mapper类
(2) 重写自定义类中的map方法,在该方法中将K1和V1转为K2和V2
(3) 将生成的K2和V2写入上下文中
Reducer
(1) 自定义类继承Reducer类
(2) 重写Reducer中的reduce方法,在该方法中将K2和[V2]转为K3和V3
(3) 将K3和V3写入上下文中
Driver
整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
(1)定义类,编写main方法
(2)在main方法中指定以下内容:
1、创建建一个job任务对象
2、指定job所在的jar包
3、指定源文件的读取方式类和源文件的读取路径
4、指定自定义的Mapper类和K2、V2类型
5、指定自定义分区类(如果有的话)
6、指定自定义Combiner类(如果有的话)
7、指定自定义分组类(如果有的话)
8、指定自定义的Reducer类和K3、V3的数据类型
9、指定输出方式类和结果输出路径
10、将job提交到yarn集群
WordCount示例编写
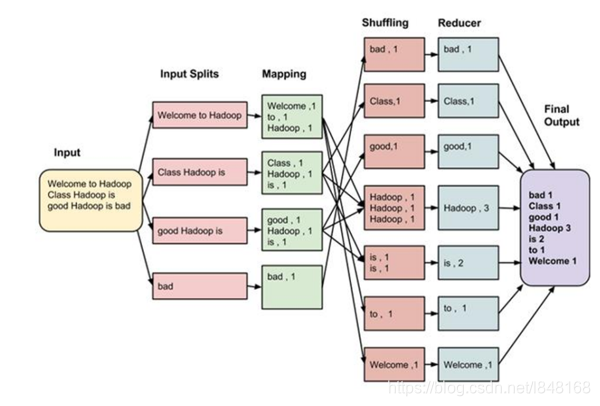
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
第一步:数据准备
1、创建一个新的文件
cd /export/server
vim wordcount.txt
2、向其中放入以下内容并保存
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
3、上传到 HDFS
hadoop fs -mkdir -p /input/wordcount
hadoop fs -put wordcount.txt /input/wordcount
第二步:代码编写
1、导入maven坐标
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>
2、定义一个mapper类
//首先要定义四个泛型的类型
//keyin: LongWritable valuein: Text
//keyout: Text valueout:IntWritable
public class WordCountMapper extends Mapper<LongWritable, Text, Text, Writable>{
//map方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words){
context.write(new Text(word), new LongWritable (1));
}
}
}
3、定义一个reducer类
public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
//生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
@Override
protected void reduce(Text key, Iterable<LongWritable > values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组kv的所有v,累加到count中
for(LongWritable value:values){
count += value.get();
}
context.write(key, new LongWritable (count));
}
}
4、定义一个Driver主类,用来描述job并提交job
public class WordCountRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1、创建建一个job任务对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "wordcount");
//2、指定job所在的jar包
job.setJarByClass(WordCountRunner.class);
//3、指定源文件的读取方式类和源文件的读取路径
job.setInputFormatClass(TextInputFormat.class); //按照行读取
//TextInputFormat.addInputPath(job, new Path("hdfs://node1:8020/input/wordcount")); //只需要指定源文件所在的目录即可
TextInputFormat.addInputPath(job, new Path("file:///E:\\input\\wordcount")); //只需要指定源文件所在的目录即可
//4、指定自定义的Mapper类和K2、V2类型
job.setMapperClass(WordCountMapper.class); //指定Mapper类
job.setMapOutputKeyClass(Text.class); //K2类型
job.setMapOutputValueClass(LongWritable.class);//V2类型
//5、指定自定义分区类(如果有的话)
//6、指定自定义分组类(如果有的话)
//7、指定自定义的Reducer类和K3、V3的数据类型
job.setReducerClass(WordCountReducer.class); //指定Reducer类
job.setOutputKeyClass(Text.class); //K3类型
job.setOutputValueClass(LongWritable.class); //V3类型
//8、指定输出方式类和结果输出路径
job.setOutputFormatClass(TextOutputFormat.class);
//TextOutputFormat.setOutputPath(job, new Path("hdfs://node1:8020/output/wordcount")); //目标目录不能存在,否则报错
TextOutputFormat.setOutputPath(job, new Path("file:///E:\\output\\wordcount")); //目标目录不能存在,否则报错
//9、将job提交到yarn集群
boolean bl = job.waitForCompletion(true); //true表示可以看到任务的执行进度
//10.退出执行进程
System.exit(bl?0:1);
}
}
MapReduce程序运行模式
本地运行模式
1、 mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
2、 而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
3、 本地模式非常便于进行业务逻辑的调试
集群运行模式
1、 将mapreduce程序提交给yarn集群,分发到很多的节点上并发执行
2、 处理的数据和输出结果应该位于hdfs文件系统
3、 提交集群的实现步骤:
(1)将Driver主类代码中的输入路径和输出路径修改为HDFS路径
TextInputFormat.addInputPath(job, new Path("hdfs://node1:8020/input/wordcount"));
TextOutputFormat.setOutputPath(job, new Path("hdfs://node1:8020/output/wordcount"));
(2)将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
hadoop jar wordcount.jar cn.itcast.WordCountDriver
结束
这篇介绍了MapReduce的基础介绍,一些高阶部分,分开来写,放在下一篇文章中。
