背景:
在开发调试阶段,发现bug后开始在服务器上查找日志,但是这个过程真的好痛苦.
一种方式是直接在服务器上tail -f 或者tail -n 直接查看,但是日志太多,不容易发现问题
另一种方式导出最近的日志到本地,打开本地编辑器一点一点查看
但是两种方式都很麻烦,有没有轻松一点的方法呢?
在这个开源的时代,一直听说elk架构,那就搭建这个日志系统,感受下这个系统的魅力吧
基本服务介绍
- 什么是elasticsearch
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎, 一切设计都是为了提高搜索的性能
1. 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
2. 实时分析的分布式搜索引擎。
3. 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
-
什么是Filebeat
go语言开发的,一个轻量级的日志收集的工具,消耗更少的cpu 和 内存。 -
什么是Logstash
Logstash 是一个轻量级、开源的服务器端数据处理管道,允许您从各种来源收集数据,进行动态转换,并将数据发送到您希望的目标
但是logstash java开发,依赖jvm,相对filebeat还是比较消耗服务器资源
主要工作过程是是 input->filter->output
获取输入, 过滤解析, 重新输出,配置比较简单
- 什么是Kibana
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。
可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。
可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
- 怎么使用?
因为logstash服务比较重,所以我们主要是通过filebeat来采集日志信息,都交给logstash,通过logstash过滤输出到elasticsearch中.
建议的服务搭建
1. 独立的es集群
2. 每个服务器上安装filebeat进行日志采集
3. 单独的logstash服务,来接收filebeat日志,过滤并输出到es中
4. 单独的kibana服务,来做数据段web页面展示
来贴张常用的架构图

安装服务
官网 https://www.elastic.co/cn/downloads/
首先我选择安装目录为
mkdir -p /usr/local/elk
服务器需要先安装 jdk环境, 版本jdk1.8 以上
1、下载安装 elasticsearch
下载elasticsearch 下载安装包,并解压
cd /usr/local/elk
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.0-linux-x86_64.tar.gz
tar xvf elasticsearch-7.6.0-linux-x86_64.tar.gz
使用默认配置,启动服务
cd /usr/local/elk/elasticsearch-7.6.0/bin
./elasticsearch -d
好吧,出师不利,刚启动遇到第一个问题,elasticsearch不允许root用户启动(后面几个服务也是不允许),所以我先创建elstic用户和组,并设置elk目录属于elstic用户组
错误显示为
java.lang.RuntimeException: can not run elasticsearch as root
解决方式
-创建elastic用户
adduser elastic
-设置密码
passwd elastic
-修改目录权限
chown -R elastic /usr/local/elk
-切换用户
su elastic
然后成功启动
可以访问elsticsearch接口试下

2、下载安装启动kibana
下载并解压
cd /usr/local/elk/
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.0-linux-x86_64.tar.gz
tar xvf kibana-7.6.0-linux-x86_64.tar.gz
修改配置,使其能够外网访问,并且配置为中文版
#vim /usr/local/elk/kibana-7.6.0-linux-x86_64/config/kibana.xml
server.port: 5601 #开启默认端口5601
server.host: “10.254.254.200” #kibana站点IP
elasticsearch.url: http://10.254.254.200:9200 #只想ES服务所在IP Port
kibana.index: “.kibana”
i18n.locale: "zh-CN"
启动kibana
nohup /usr/local/elk/kibana-7.6.0-linux-x86_64/bin/kibana -c /usr/local/elk/kibana-7.6.0-linux-x86_64/config/kibana.yml &
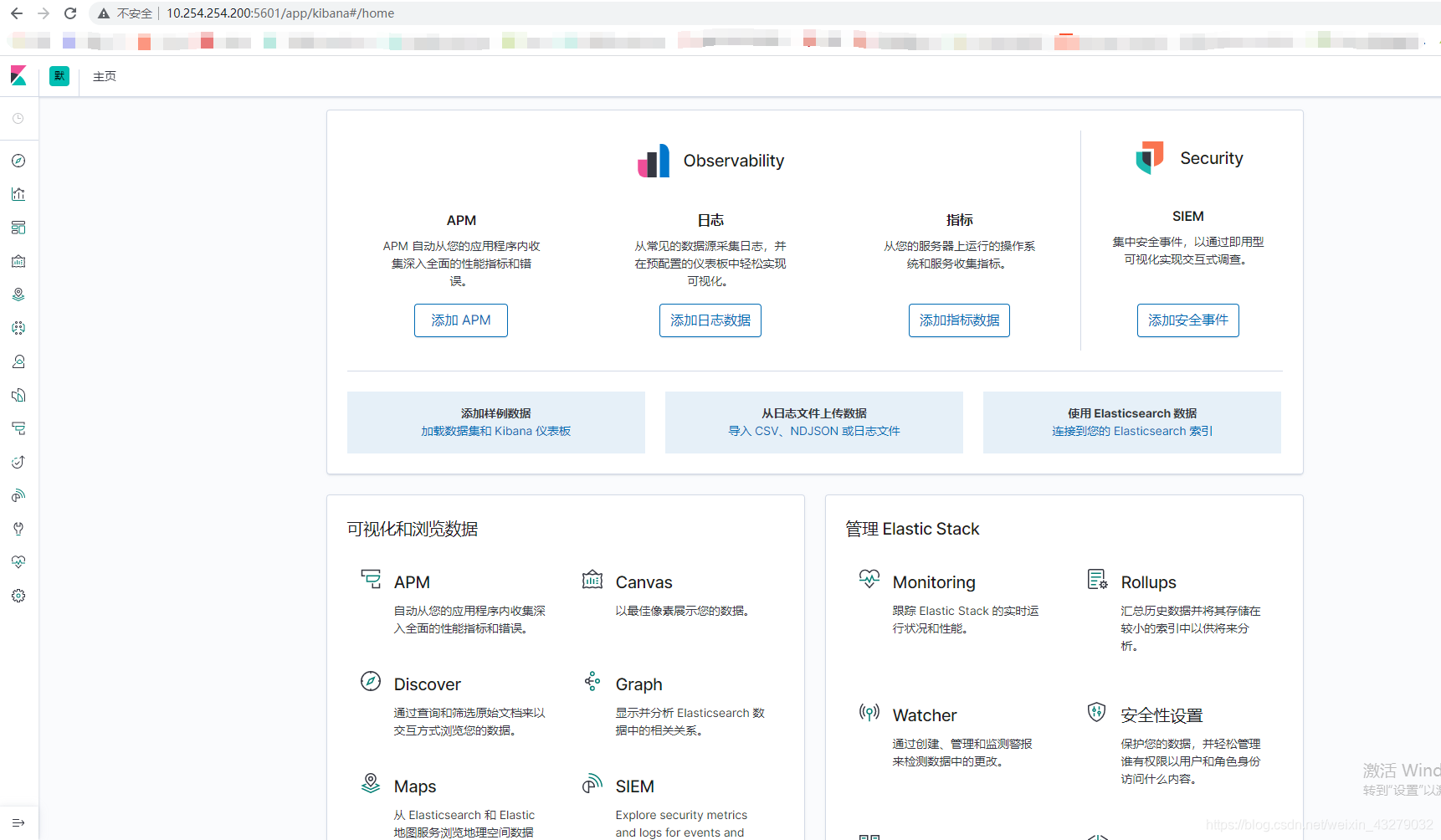
然后浏览器访问 外网ip:5601,很开心进入管理页面,并且是中文版
3 、客户端下载安装 filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.0-linux-x86_64.tar.gz
tar xvf filebeat-7.6.0-linux-x86_64.tar.gz
这里我们重点讲下filebeat的配置
通用设计是 filebeat读取日志,输出到logstash,经过logstash解析后,输出到 elasticsearch
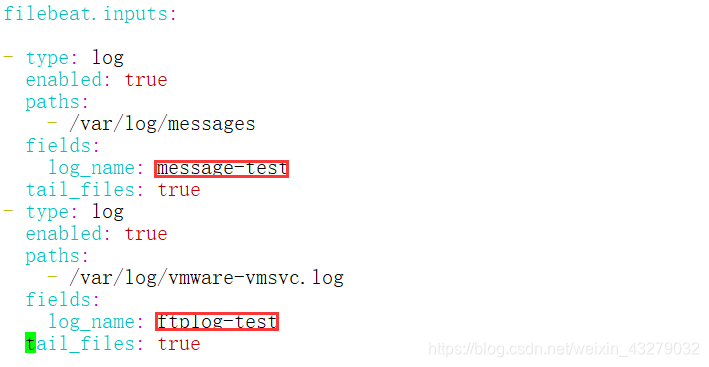
- 问题1.增么配置filebeat读取日志呢?
我们打开filebeat.xml,进行如下配置
# filebeat 输入标识
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
# 定义输入类型,为日志类型
- type: log
# Change to true to enable this input configuration.
# 开启配置
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
# 读取日志文件罗京
paths:
- /data/logs/cheetahcafe_server/test/info.log
- # 增加自定义字段
fields:
log_name: cheetahcafe-test
tail_files: true
#- c:\programdata\elasticsearch\logs\*
- type: log
enabled: true
paths:
- /data/logs/cheetahcafe_server/dev/info.log
fields:
log_name: cheetahcafe-dev
tail_files: true
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
#exclude_lines: ['^DBG']
实例:
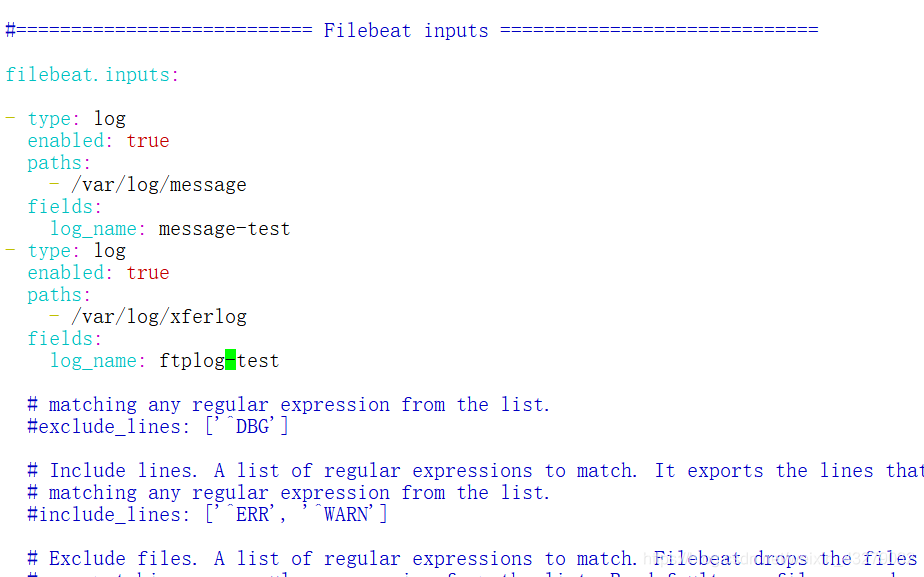
上面配置可以看到,我们配置了多个日志输入,如果有多个服务日志需要监控的化,可以采用上面这种配置,并且设置 fields字段,进行区分
- 问题2 怎么输出到 logstash中?
默认配置文件很给力,都有示例,太好用了
注释掉elasticsearch output段:

修改Logstash output段;
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
# Logstash 主机地址,我们默认本机的5044端口
hosts: ["logstashIP:5044"]
# Optional SSL. By default is off. 开启ssl
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
配置后可以进行启动filebeat
cd /usr/local/elk/filebeat-7.6.0-linux-x86_64
nohup ./filebeat -c filebeat.yml &
4、 下载安装 logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.6.0.tar.gz
tar xvf logstash-7.6.0.tar.gz
我们同样要考虑下面两个问题来进行配置
- 1.我们怎么读取日志输入?
通过filebeat把日志输入到logstash中,我们打开配置文件,进行下面配置
cd /usr/local/elk/logstash-7.6.0/config
cp logstash-sample.conf logstash.conf
vim logstash.conf
配置日志输入,beats配置
input {
beats {
# 5044是logstash的数据输入端口
port => 5044
# 是否开启ssl加密,否
ssl => false
}
}
- 2.我们输出到哪里?
我们日志输出到elasticsearch中,上面说到此时有两个filebeats输入,我们怎么进行区分呢?
此时 filebeats中的fields字段此时就有很大用处了
输出配置,输出到elasticsearch中
output {
elasticsearch {
# es的服务和端口
hosts => ["http://localhost:9200"]
# 输出到es中索引的创建格式,此时注意 {[fields][log_name]} ,这里使用了filebeats中配置的自定义属性进行区分索引
index => "%{[fields][log_name]}-%{+YYYY.MM.dd}"
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
这样我们很轻松就配置好了 logstash,下面进行启动服务
cd /usr/local/elk/logstash-7.6.0/bin
nohup ./logstash -f ../config/logstash-es.conf &
通过上面操作,我们就成功配置和启动我们的elk日志系统了
下面开心的到kibana中使用下吧
5、使用kibana
最后一步,我们来看下怎么使用吧? 浏览器访问 ip+端口,打开面板
创建索引模式
首先 我们先创建个索引模式,为了能够简单对统一索引进行合并展示
点击 管理 -> 索引模式,然后创建索引模式
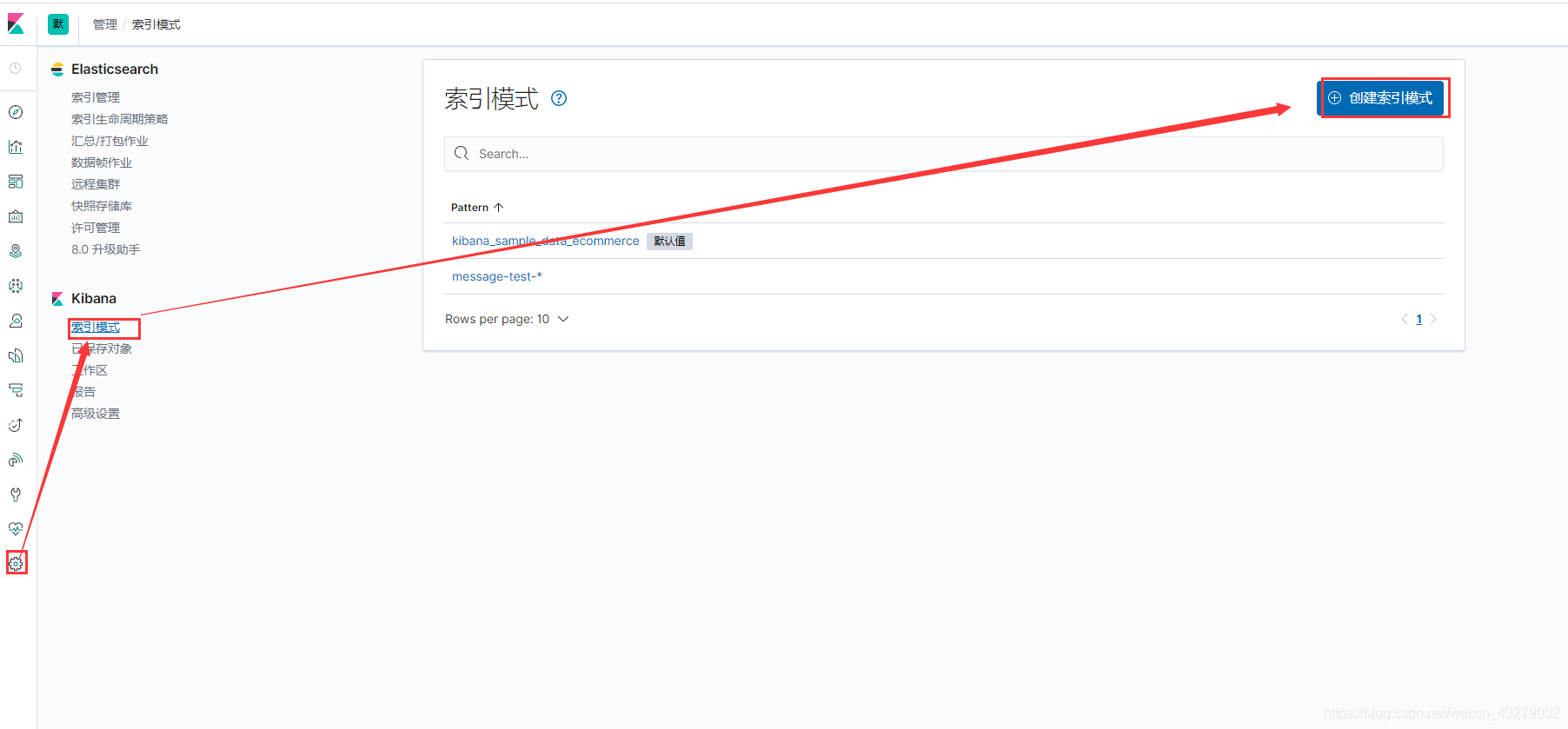
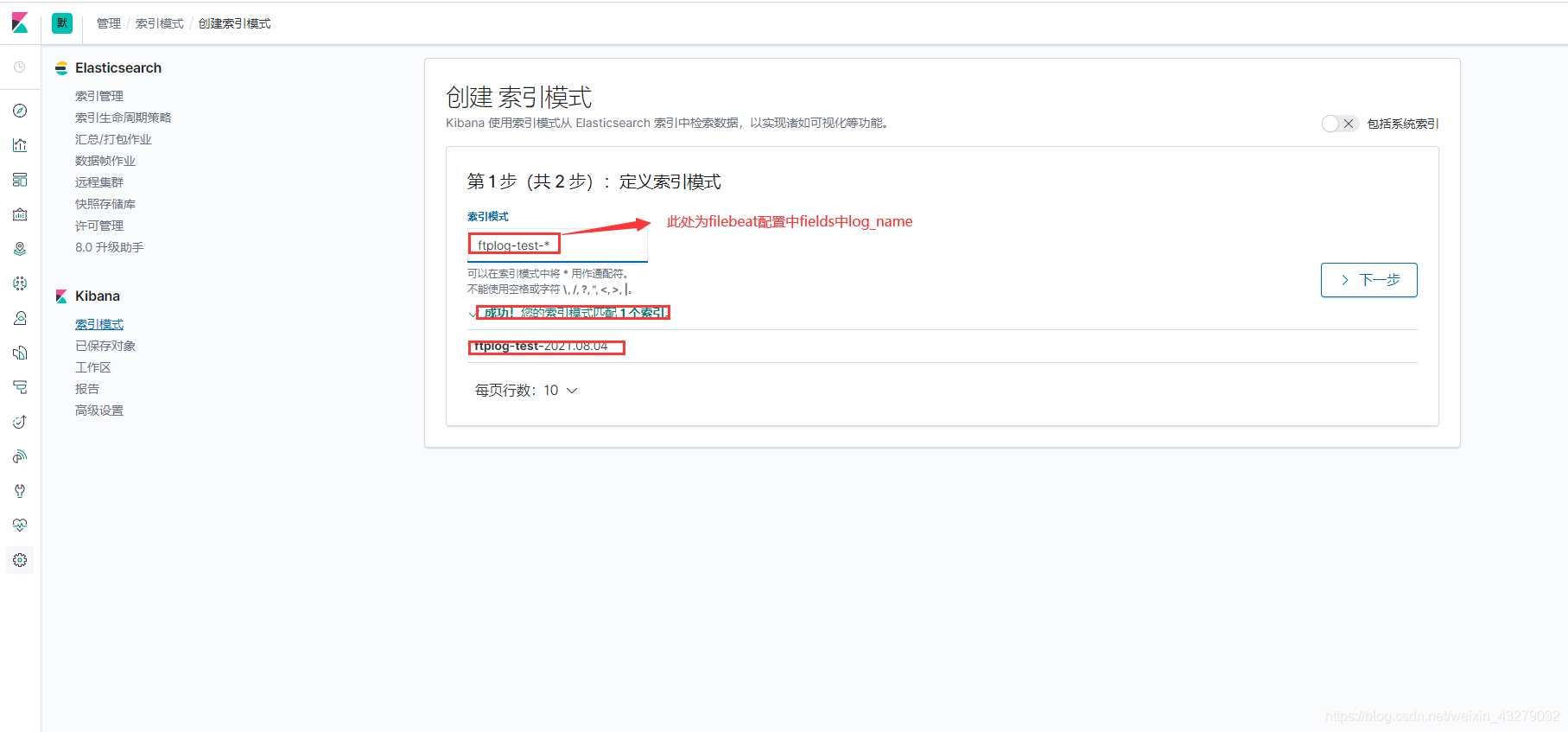
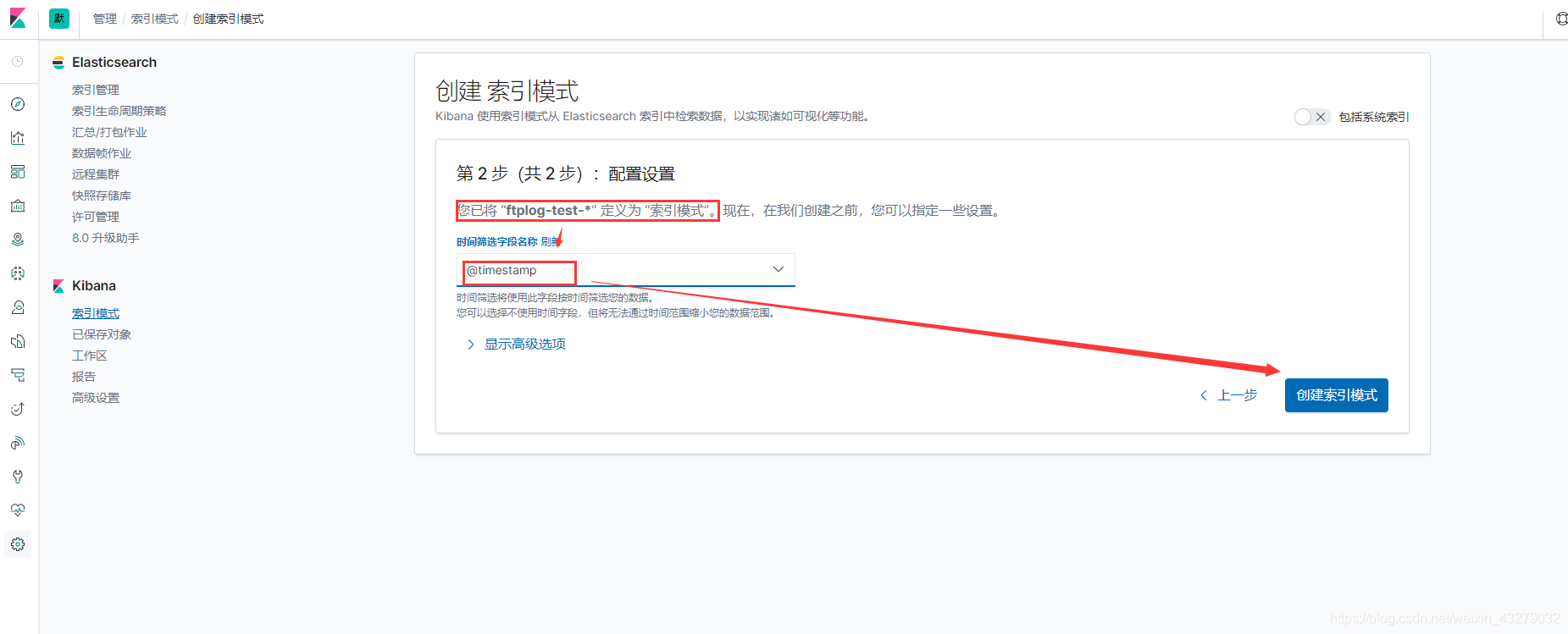
因为我们的索引是根据项目并且按天进行创建的,所以可以按照自己公司项目名来创建索引模式就行了, 很简单…
- 查看日志信息
创建好索引模式,我们就可以在 侧边栏的 “发现” 中找到想要查看的数据了, 默认查看的字段比较多,但是基本都是我们不关系的,
可以在可用字段中选择 message,只展示时间和message 就可以了,下面是展示效果
