Hive������
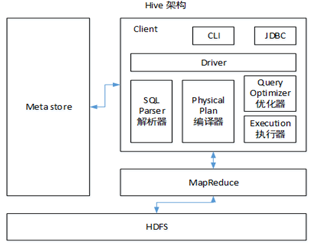
1.Hive�ļܹ�
2.Hive�����ݿ�Ƚ�
Hive �����ݿ����ӵ�����ƵIJ�ѯ����,��������֮����
1)���ݴ洢λ��
Hive �洢�� HDFS �����ݿ⽫���ݱ����ڿ��豸���߱����ļ�ϵͳ�С�
2)���ݸ���
Hive�в���������ݵĸ�д�������ݿ��е�����ͨ������Ҫ���������ĵ�,
3)ִ���ӳ�
Hive ִ���ӳٽϸߡ����ݿ��ִ���ӳٽϵ͡���Ȼ,�������������,�����ݹ�ģ��С,�����ݹ�ģ�������ݿ�Ĵ���������ʱ��,Hive�IJ��м�����Ȼ�����ֳ����ơ�
4)���ݹ�ģ
Hive֧�ֺܴ��ģ�����ݼ���;���ݿ����֧�ֵ����ݹ�ģ��С��
hive�ʹ�ͳ���ݿ�֮�������
1��дʱģʽ�Ͷ�ʱģʽ
��ͳ���ݿ���дʱģʽ,��load������,�����˖�ѯ����,��ΪԤ�Ƚ���֮����Զ��н�������,��ѹ��,������Ҳ�Ứ�Ѹ���ļ���ʱ�䡣
Hive�Ƕ�ʱģʽ,1oad data�dz�Ѹ��,��Ϊ������Ҫ��ȡ���ݽ��н���,���������ļ��ĸ��ƻ����ƶ���
**2�����ݸ�ʽ��**Hive��û�ж���ר�ŵ����ݸ�ʽ,���û�ָ��,��Ҫָ����������:�зָ���,�зָ���,�Լ���ȡ�ļ����ݵķ��������ݿ���,�洢���涨�����Լ������ݸ�ʽ���������ݶ��ᰴ��һ������֯�洢
**3�����ݸ��¡�**Hive�������Ƕ���д�ٵ�,���,��֧�ֶ����ݵĸ�д��ɾ��,���ݶ��ڼ��ص�ʱ����ȷ���õġ����ݿ��е�����ͨ������Ҫ����������
**4��ִ���ӳ١�**Hive�ڲ�ѯ���ݵ�ʱ��,��Ҫɨ��������(�����),����ӳٽϸ�,ֻ���ڴ����������Dz������ơ����ݿ��ڴ���С������ִ���ӳٽϵ͡�
5��������Hive�Ƚ���,���ʺ�ʵʱ��ѯ�����ݿ��С�
**6��ִ�С�**Hive�� Mapreduce,���ݿ��� Executor
**7������չ�ԡ�**Hive��,���ݿ��
**8�����ݹ�ģ��**Hive��,���ݿ�С
3.�ڲ������ⲿ��
1.hive�ڲ������ⲿ��������
�ڲ���:�������ݵ�hive���ڵ�hdfsĿ¼,ɾ��ʱ,Ԫ���ݺ������ļ���ɾ��
�ⲿ��:���������ݵ�hive���ڵ�hdfsĿ¼,ɾ��ʱ,ֻɾ�����ṹ��
�����ⲿ�������˵���Ӱ�ȫЩ,������֯Ҳ�������,���㹲��Դ���ݡ�
2.ʲôʱ��ʹ���ڲ���,ʲôʱ��ʹ���ⲿ��
- ÿ��ɼ���ng��־�������־,�ڴ洢��ʱ����ʹ���ⲿ��,��Ϊ��־�����Dzɼ�����ʵʱ�ɼ�������,һ������ɾ,�ָ������dz��鷳�������ⲿ���������ݵĹ�����
- ��ȡ������ҵ������,��ʵ���ⲿ�������ڲ������ⶼ����,���㱻��ɾ,�ָ�����Ҳ�Ǻܿ��,�����Ҫ���������ݺ�Ԫ���ݽ��н��յĹ���, �ǻ��ǽ���ʹ���ڲ���
- ����ͳ�Ʒ���ʱ���õ����м��,���������ʹ���ڲ���,��Ϊ��Щ���ݲ���Ҫ����,ʹ���ڲ�����Ϊ���ʡ����Һܶ�ʱ��������������ֻ��Ҫ�������3�������,���ⲿ����ʱ��ɾ������ʱ��ɾ�����ݡ�
4.������Ͱ������,ΪʲôҪ����
**������:**ԭ����һ������洢��ʱ��ֳɲ�ͬ������Ŀ¼���д洢�����˵�ǵ�������,��ô�ڱ���Ŀ¼�¾�ֻ��һ����Ŀ¼,���˵�Ƕ������,��ô�ڱ���Ŀ¼���ж��ٷ������ж��ټ���Ŀ¼�������ǵ�������,���Ƕ������,�ڱ���Ŀ¼��,�ͷ����շ���Ŀ¼���Dz���ֱ�Ӵ洢�����ļ���
**��Ͱ��:**ԭ����hashpartitioner һ��,��hive�е�һ�ű������ݽ��й��ɷ����ʱ��,���ɷ���������hashpartitioner��(��Ҫָ����Ͱ�ֶ�,ָ���ֳɶ���Ͱ)
�������ͷ�Ͱ��������˴洢�ĸ�ʽ��ͬ��,����Ҫ��������:
-
������:ϸ�����ݹ���,��Сmapreduce���� ��Ҫɨ�����������
-
��Ͱ��:���join��ѯ��Ч��,��һ�����ݻᱻ�������������Ӳ�ѯ��ʱ������Ͱ,��Ͱ�ֶξ��������ֶ�;��߲�����Ч�ʡ�
���˷���Ϊʲô��Ҫ��Ͱ?
(1) ��ø��ߵIJ�ѯ����Ч�ʡ�ͰΪ�������˶���Ľṹ,Hive�ڴ�����Щ��ѯʱ����������ṹ��
(2) ʹȡ��( sampling)����Ч���ڴ������ģ���ݼ�ʱ,�ڿ������Ė�ѯ�Ľ�,����������ݼ���һС���������������в�ѯ,������ܶ�㡣
��Ͱ����Է������и�ϸ���ȵĻ��֡���Ͱ�������߷�����ij��ֵ����hashֵ��������,��Ҫ��װname���Է�Ϊ3��Ͱ,���Ƕ�name����ֵ��hashֵ��3ȡ��,����ȡģ��������ݷ�Ͱ��
�������ͬ����,�������ݵIJ�����ʵ���ݱ��ļ��е���,��������ָ����α��,���Ƿ�Ͱ���������ݱ�����ʵ���ж�����α��
5.�ĸ�By����
1)Sort By:����������;
2)Order By:ȫ������,ֻ��һ��Reducer;
3)Distrbute By:����MR��Partition,���з���,���sort byʹ�á�
4) Cluster By:��Distribute by��Sorts by�ֶ���ͬʱ,����ʹ��Cluster by��ʽ��Cluster by���˾���Distribute by�Ĺ�������Sort by�Ĺ��ܡ���������ֻ������������,����ָ���������ΪASC����DESC��
1�� order by����ָ��desc����asc����
order by���������ȫ������,���ֻ��һ�� reducer(��� reducer����֤ȫ������),Ȼ��ֻ��һ�� Reducer,�ᵼ�µ������ģ�ϴ�ʱ,���Ľϳ��ļ���ʱ�䡣
2�� sort by����ȫ������,�������ݽ��� reducerǰ�������,���,����� sort by�������������� mapped. reduce. tasks��1,�� sort byֻ�ᱣ֤ÿ�� reducer���������,������֤ȫ������(ȫ����ʵ��:���� sortby��֤ÿ�� reducer�������,Ȼ���ڽ��� order by�鲢��ǰ�����е� reducer������е��� reducer����,ʵ��ȫ������)
3�� distribute by(��Ҫ)
distribute by�ǿ�����map����β�����ݸ� reduce�˵ġ�hive����� distribute by������,��Ӧ reduce�ĸ������зַ�,Ĭ���Dz���hash�㷨��sort byΪÿ�� reduce����һ�������ļ�������Щ�����,����Ҫ����ij���ض���Ӧ�õ��ĸ� reducer,��ͨ����Ϊ�˽��к����ľۼ�������distribute by�պÿ���������¡����, distribute by������ sort by���ʹ�á�
4�� cluster by
cluster by���� distribute by�� sort by����Ϲ��ܡ���������ֻ������������,����ָ���������ΪASC����DESC
���ʵ�����������������TopN?���ʽ
row number(0)OVER( partition by COLI order by CL2desc)rank�ȶ�COL1�н��з���,�ٶ�COL2�н���������������
6.���ں���
RANK() ������ͬʱ���ظ�,���������
DENSE_RANK() ������ͬʱ���ظ�,���������
ROW_NUMBER() �����˳�����
1) OVER():ָ�������������������ݴ��ڴ�С,������ݴ��ڴ�С���ܻ������еı���仯
2)CURRENT ROW:��ǰ��
3)n PRECEDING:��ǰn������
4) n FOLLOWING:����n������
5)UNBOUNDED:���,UNBOUNDED PRECEDING ��ʾ��ǰ������, UNBOUNDED FOLLOWING��ʾ��������յ�
6) LAG(col,n):��ǰ��n������
7)LEAD(col,n):�����n������
8) NTILE(n):����������е��зַ���ָ�����ݵ�����,�������б��,��Ŵ�1��ʼ,����ÿһ��,NTILE���ش�����������ı�š�ע��:n����Ϊint���͡�
7.�Զ���UDF��UDTF
����Ŀ���Ƿ��Զ����UDF��UDTF����,�Լ������Ǵ�����ʲô����,���Զ��岽��?
1)�Զ������
2)��UDF�������������ֶ�;��UDTF���������¼��ֶΡ�
�Զ���UDF:�̳�UDF,��дevaluate����
�Զ���UDTF:�̳���GenericUDTF,��д3������:initialize(�Զ������������������),process(���������forward(result)),close
ΪʲôҪ�Զ���UDF/UDTF,��Ϊ�Զ��庯��,�����Լ����Log��ӡ��־,�������������쳣,�������.
8.udf udaf udtf����
UDF���������ڵ���������,���Ҳ���һ����������Ϊ����������������������һ��(������ѧ�������ַ�������)��
UDAF ���ܶ������������,������һ����������С���COUNT��MAX�����ĺ������Ǿۼ�������
UDTF ���������ڵ���������,���Ҳ������������-------һ������Ϊ�����lateral view explore()
����˵:
UDF:���ض�Ӧֵ,һ��һ
UDAF:���ؾ���ֵ,���һ
UDTF:���ز��ֵ,һ�Զ�
9.Hive�Ż�
https://blog.csdn.net/qq_37933018/article/details/106891773(�и�)
(1����Ϣ) ������������Hive����ϵ��3:�ѿ����˻�,С��join���,Mapjoin������_�����ּ�-CSDN����
1)MapJoin
�����ָ��MapJoin���߲�����MapJoin������,��ôHive�������ὫJoin����ת����Common Join,��:��Reduce�����join��������������б��������MapJoin��С��ȫ�����ص��ڴ���map�˽���join,����reducer������
2)�����
�д���:��SELECT��,ֻ����Ҫ����,�����,����ʹ�÷�������,����SELECT *��
�д���:�ڷ���������,��ʹ�������ʱ,����������Ĺ�������д��Where����,��ô�ͻ���ȫ������,֮���ٹ��ˡ�
3)���÷�Ͱ����
4)���÷�������
5)��������Map��
(1)ͨ�������,��ҵ��ͨ��input��Ŀ¼����һ�����߶��map����
��Ҫ�ľ���������:input���ļ��ܸ���,input���ļ���С,��Ⱥ���õ��ļ����С��
(2)�Dz���map��Խ��Խ��?
���Ƿġ����һ�������кܶ�С�ļ�(ԶԶС�ڿ��С128m),��ÿ��С�ļ�Ҳ�ᱻ����һ����,��һ��map���������,��һ��map���������ͳ�ʼ����ʱ��ԶԶ������������ʱ��,�ͻ���ɺܴ����Դ�˷ѡ�����,ͬʱ��ִ�е�map�������ġ�
(3)�Dz��DZ�֤ÿ��map�����ӽ�128m���ļ���,����������?
��Ҳ�Dz�һ����������һ��127m���ļ�,��������һ��mapȥ���,������ļ�ֻ��һ����������С�ֶ�,ȴ�м�ǧ��ļ�¼,���map���������Ƚϸ���,��һ��map����ȥ��,�϶�Ҳ�ȽϺ�ʱ��
������������2��3,������Ҫ��ȡ���ַ�ʽ�����:������map��������map��;
6)С�ļ����кϲ�
��Mapִ��ǰ�ϲ�С�ļ�,����Map��:CombineHiveInputFormat���ж�С�ļ����кϲ��Ĺ���(ϵͳĬ�ϵĸ�ʽ)��HiveInputFormatû�ж�С�ļ��ϲ����ܡ�
7)��������Reduce��
Reduce����������Խ��Խ��
(1)����������ͳ�ʼ��ReduceҲ������ʱ�����Դ;
(2)����,�ж��ٸ�Reduce,�ͻ��ж��ٸ�����ļ�,��������˺ܶ��С�ļ�,��ô�����ЩС�ļ���Ϊ��һ�����������,��Ҳ�����С�ļ����������;
������Reduce������ʱ��Ҳ��Ҫ����������ԭ��:���������������ú��ʵ�Reduce��;ʹ����Reduce��������������СҪ����;
8)����
// ����ϲ�С�ļ�
SET hive.merge.mapfiles = true; -- Ĭ��true,��map-only�������ʱ�ϲ�С�ļ�
SET hive.merge.mapredfiles = true; -- Ĭ��false,��map-reduce�������ʱ�ϲ�С�ļ�
SET hive.merge.size.per.task = 268435456; -- Ĭ��256M
SET hive.merge.smallfiles.avgsize = 16777216; -- ������ļ���ƽ����СС�ڸ�ֵʱ,����һ��������map-reduce��������ļ�merge
10.���joinС������������,��ô���?
mapjoin����
join��Ϊ��ֵ���³�β(keyΪ��ֵ�������ֵ����)
join��Ϊ�ȵ�ֵ���³�β,Ҳ���Խ��ȵ����ݺͷ��ȵ����ݷֿ�����,���ϲ�
Hive��С����������(join)�����ܷ��� :
https://blog.csdn.net/niuyan666/article/details/118579181
11.hive����Щ����Ԫ���ݵķ�ʽ,�ֱ���ʲô�ص㡣
Hive Metastore���������÷�ʽ,�ֱ���:
- Embedded Metastore Database (Derby) ��Ƕģʽ
- Local Metastore Server ����Ԫ�洢
- Remote Metastore Server Զ��Ԫ�洢
Metadata��Metastore����
metadata��Ԫ���ݡ�Ԫ���ݰ�����Hive������database��tabel�ȵ�Ԫ��Ϣ��
Ԫ���ݴ洢�ڹ�ϵ�����ݿ��С���Derby��MySQL�ȡ�
Metastore��������:�ͻ�������metastore����,metastore��ȥ����MySQL���ݿ�����ȡԪ���ݡ�����metastore����,�Ϳ����ж���ͻ���ͬʱ����,������Щ�ͻ��˲���Ҫ֪��MySQL���ݿ���û���������,ֻ��Ҫ����metastore ���ɡ�
�������÷�ʽ����
��Ƕģʽʹ�õ�����Ƕ��Derby���ݿ����洢Ԫ����,Ҳ����Ҫ������Metastore���������Ĭ�ϵ�,���ü�,����һ��ֻ��һ���ͻ�������,����������ʵ��,������������������
����Ԫ�洢��Զ��Ԫ�洢�������ⲿ���ݿ����洢Ԫ����,Ŀǰ֧�ֵ����ݿ���:MySQL��Postgres��Oracle��MS SQL Server.����������ʹ��MySQL��
����Ԫ�洢��Զ��Ԫ�洢��������:����Ԫ�洢����Ҫ������metastore����,�õ��Ǹ�hive��ͬһ���������metastore����Զ��Ԫ�洢��Ҫ������metastore����,Ȼ��ÿ���ͻ��˶��������ļ����������ӵ���metastore����Զ��Ԫ�洢��metastore�����hive�����ڲ�ͬ�Ľ���
�ڴ����ݿ�derby,��װС,�������ݴ����ڴ�,���ȶ�
mysql���ݿ�,���ݴ洢ģʽ�����Լ�����,�־û���,�鿴���㡣
12.hive���жϺ�������Щ
hive �������ж�(if��coalesce��case)
13.������һ��HIVE�Ĺ���?��hive���������ַ�ʽ?hive���м���?
hive��Ҫ�������߷�����
hive���������ַ�ʽ
-
ֱ�ӽ�����
-
��ѯ������**(ͨ��AS ��ѯ�����ɽ���:���Ӳ�ѯ�Ľ�������±���,������,**һ�������м��)
-
like������(�ᴴ���ṹ��ȫ��ͬ�ı�,����û������)
hive����2��:�ڲ������ⲿ��
14.����ҵ��ÿ�������ҵ����־(ѹ����>=3G),ÿ����Ҫ���ص�hive��log����,��ÿ�������ҵ����־��ѹ��֮��load��hive��log��ʱ,���ʹ�õ�ѹ���㷨���ĸ�,��˵����ԭ��
ѡ��lzo,��Ϊ��ѹ���㷨���з�,ѹ���ʱȽϸ�,��ѹ���ٶȺܿ�,�dz��ʺ���־
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-R0L3WJIK-1628167496677)(C:/Users/67332/AppData/Roaming/Typora/typora-user-images/image-20210723232108183.png)]
15.����hive�н��������Բ����Ż���ѯЧ��,����ʱ����Ż�
�������½���Ϊ������Ͱ��
16.union all��union������
union ȥ��
union oll ��ȥ��
17.��ν��hive������б������
Hive����,���ݹ���ʦ����֮· (qq.com)
18.����delete,drop,truncate������
delet ɾ������
drop ɾ����
truncate �ݻٱ��ṹ���ؽ�
19.Hive ����ֶεķָ����õ�ʲô?Ϊʲô��\t?���������ֶ��� ����\t �������,��ô������?Ϊʲô���� Hive Ĭ�ϵķָ���,Ĭ�ϵķָ�����ʲô?
hive Ĭ�ϵ��ֶηָ���Ϊ ascii ��Ŀ��Ʒ�\001(^A),������ʱ���� fields terminated by ��\001��
�������ֶ������\t �����,�Զ��� InputFormat,�滻Ϊ�����ָ���������������
20.mapjoin��ԭ��
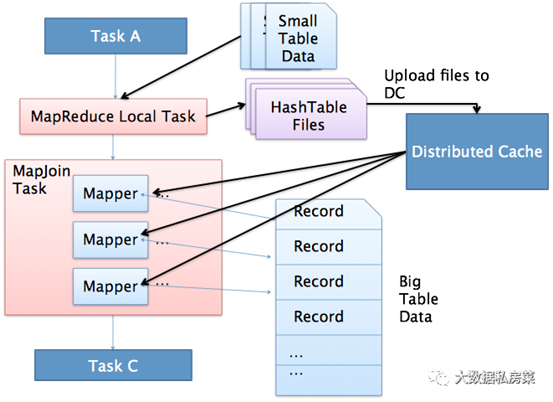
MapJoinͨ������һ����С�ı���һ���������join�ij���,����С���ж�С,�ɲ���hive.mapjoin.smalltable.filesize������,�ò�����ʾС�����ܴ�С,Ĭ��ֵΪ25000000�ֽ�,��25M��
Hive0.7֮ǰ,��Ҫʹ��hint��ʾ /*+ mapjoin(table) */�Ż�ִ��MapJoin,����ִ��Common Join,����0.7�汾֮��,Ĭ���Զ���ת��Map Join,�ɲ���hive.auto.convert.join������,Ĭ��Ϊtrue.
����a��Ϊһ�Ŵ��,bΪС��,����hive.auto.convert.join=true,��ôHive��ִ��ʱ����Զ�ת��ΪMapJoin��

21.��hive��row_number��distribute by �� partition by������
row_number() over( partition by ������ֶ� order by ������ֶ�) as rank(rank �����ⶨ���ʾ����ı�ʶ);
row_number() over( distribute by ������ֶ� sort by ������ֶ�) as rank(rank �����ⶨ���ʾ����ı�ʶ)
ע��:
partition by ֻ�ܺ�order by ���ʹ��
distribute by ֻ�ܺ� sort by ʹ��
22.hive������Щ����,��ƽ���������õ���Щ
-
��ѧ����
round(DOUBLE a)
floor(DOUBLE a)
ceil(DOUBLE a)
rand() -
���Ϻ���
size(Map<K.V>)
map_keys(Map<K.V>)
map_values(Map<K.V>)
array_contains(Array, value)
sort_array(Array) -
����ת������
cast(expr as ) -
���ں���
date_format����(���ݸ�ʽ��������)
date_add��date_sub����(�Ӽ�����)
next_day����
last_day����(�������һ������)
collect_set����
get_json_object����json����
from_unixtime(bigint unixtime, string format)
to_date(string timestamp)
year(string date)
month(string date)
hour(string date)
weekofyear(string date)
datediff(string enddate, string startdate)
add_months(string start_date, int num_months)
date_format(date/timestamp/string ts, string fmt) -
��������
if(boolean testCondition, T valueTrue, T valueFalseOrNull)
nvl(T value, T default_value)
COALESCE(T v1, T v2, ��)
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
isnull( a )
isnotnull ( a ) -
�ַ�����
concat(string|binary A, string|binary B��)
concat_ws(string SEP, string A, string B��)
get_json_object(string json_string, string path)
length(string A)
lower(string A) lcase(string A)
parse_url(string urlString, string partToExtract [, string keyToExtract])
regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT)
reverse(string A)
split(string str, string pat)
substr(string|binary A, int start) substring(string|binary A, int start) -
�ۺϺ���
count sum min max avg -
�����ɺ���
explode(array a)
explode(ARRAY)
json_tuple(jsonStr, k1, k2, ��)
parse_url_tuple(url, p1, p2, ��)
23.��дsql,������Ծ�û�
��Ƶ������-������¼���� (qq.com)
24.left semi join��left join����
-
LEFT SEMI JOIN �� IN/EXISTS �Ӳ�ѯ��һ�ָ���Ч��ʵ�֡�
-
LEFT SEMI JOIN ��������, JOIN �Ӿ����ұߵı�ֻ���� ON �Ӿ������ù�������,�� WHERE �Ӿ䡢SELECT �Ӿ�������ط������С�
-
��Ϊ left semi join �� in(keySet) �Ĺ�ϵ,�����ұ��ظ���¼,���������,�� join ���һֱ��������͵����ұ����ظ�ֵ������� left semi join ֻ����һ��,join ���������,Ҳ�ᵼ�� left semi join �����ܸ��ߡ�
-
left semi join ��ֻ���ݱ��� join key �� map ��,���left semi join ����� select �Ľ��ֻ�������������Ϊ�ұ�ֻ�� join key �������������,��left join on Ĭ����������ϵģ�Ͷ����������
25.����hive��ִ������,spark��mr������?
������mr,���ڴ��̽��м���,�Ƚ���
������spark,�����ڴ���м���,�ٶȱȽϿ�
���ڳ����������Ļ�,hiveOnSpark���ܻ����ڴ�������
26.hive��join�ײ�mr�����ʵ�ֵ�?
https://blog.csdn.net/u013668852/article/details/79768266
https://blog.csdn.net/qq_35995514/article/details/105433421
27.sql����,���������Ծ���û�?
��Ƶ������-������¼���� (qq.com)
28.Hive��ִ������?
-
�û��ύ��ѯ�������Driver��
-
��������ø��û�������Plan��
-
������Compiler�����û�����ȥMetaStore�л�ȡ��Ҫ��Hive��Ԫ������Ϣ��
-
������Compiler�õ�Ԫ������Ϣ,��������б���,�Ƚ�HiveQLת��Ϊ�������,Ȼ�������ת���ɲ�ѯ��,����ѯ��ת��Ϊ���IJ�ѯ�ƻ�,��д����ѯ�ƻ�,�����ƻ�ת��Ϊ�����ļƻ�(MapReduce), ���ѡ����ѵIJ��ԡ�
-
�����յļƻ��ύ��Driver��
-
Driver���ƻ�Planת����ExecutionEngineȥִ��,��ȡԪ������Ϣ,�ύ��JobTracker����SourceManagerִ�и�����,�����ֱ�Ӷ�ȡHDFS���ļ�������Ӧ�IJ�����
-
��ȡִ�еĽ����
-
ȡ�ò�����ִ�н����
29.sql����ִ��˳��from-where-group by-having -select-order by -limit
from-where-group by-having -select-order by -limit
from-where-group by -(select �������� �Ͽν���) -having -select-order by -limit
30.on��where������
������where������,left join �������������ݲ�ѯ����,on������������������Ӱ���ұ�������(���Ͼ���ʾ,������ȫ��Ϊnull)
-
��ƥ���,where�Ӿ�����������ᱻʹ��,����ƥ�������Ժ�,where�Ӿ������Żᱻʹ��,������ƥ��β����������м�������
-
���������ӹ�ע������ߵ���������,��Ӧ�ð�on����Ĵӱ��е������ӵ�where��,������Ӱ��ԭ�������е�����
-
where����:��������Ȼ������ʱ��ѯ���,Ȼ����ɸѡ
on����:�ȸ�����������ɸѡ,������������ʱ��ѯ���
31.hive�е������ݵ�4�ַ�ʽ
https://blog.csdn.net/niuyan666/article/details/119412890
32. Hive��ν�hsqlת����mapreduce�����
��������sql�ַ���ת���ɳ�������,�������������ִ�мƻ�,�Ż�����ִ�мƻ������Ż�,Ȼ��ִ�������Ż�������ƻ������mapreduce����