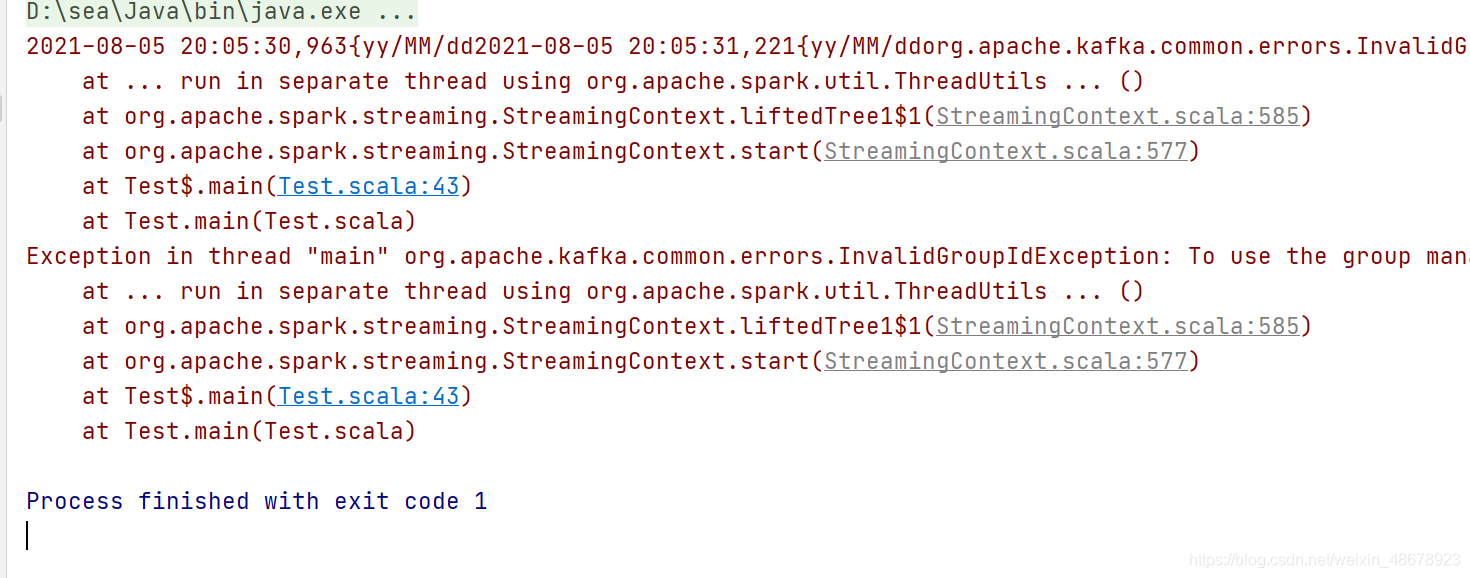
注意事项:一定要设置kafka的消费者组,不然会报错
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @author shkstart
* @create 2021-08-05 18:50
*/
object Test {
def main(args: Array[String]): Unit = {
//创建流式环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkStreming")
//设置批量处理的周期
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara:Map[String,Object] = Map[String,Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
"group.id" -> "spark", //组,没有设置组会报错
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer"->"org.apache.kafka.common.serialization.StringDeserializer"
)
val lines = KafkaUtils.createDirectStream[String, String](
ssc, LocationStrategies.PreferConsistent, //是一个采集的策略,即采集的数据该如何与计算比配,这是又框架来自行比配
ConsumerStrategies.Subscribe[String, String](Set("saprktest"), kafkaPara)
/**
* saprktest这个是一个主题,不用换自行定义即可
*
*/
)
val result = lines
.flatMap(_.value().split(" "))
.map((_,1))
.reduceByKey(_ + _)
result.print()
//采集
ssc.start()
//等待采集器关闭
ssc.awaitTermination()
}
}
结果

?
没有设置消费者组报错信息为:
?