CentOS 设置 Hadoop 单节点集群(Hadoop 单节点环境搭建)
关于Hadoop单节点环境的搭建可以参看官方文档:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
本文基于 CentOS 8 搭建 Hadoop 单节点集群。
下载Hadoop
Apache Hadoop的下载地址是:http://www.apache.org/dyn/closer.cgi/hadoop/common/ 依照自己的需求选择合适的版本,这里我选择 3.3.1 稳定版
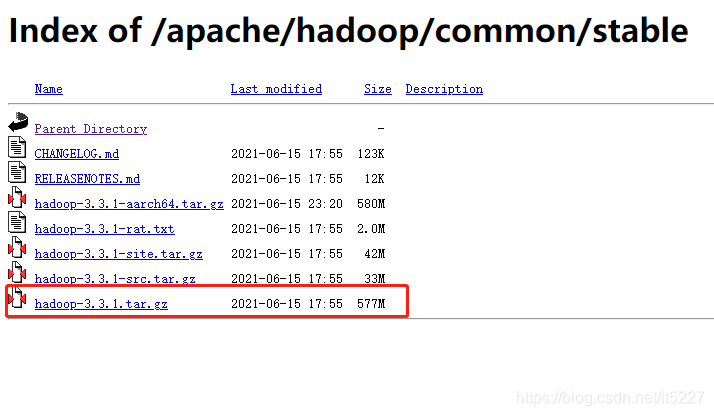
下载地址
在进行Hadoop配置之前,确保系统上安装了JDK和SSH配置无密码登陆
准备启动Hadoop集群
解压下载的Hadoop发行版。
tar -zxvf hadoop-3.3.1.tar.gz
在分发版中,编辑etc/hadoop/hadoop-env.sh文件,定义如下参数:
# 设置为Java安装的根目录
export JAVA_HOME=/opt/java/jdk1.8.0_301

我们可以在hadoop的bin目录下运行hadoop,控制台会显示hadoop脚本的使用文档。
[root@stackstone-001 bin]# ./hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--debug turn on shell script debug mode
--help usage information
hostnames list[,of,host,names] hosts to use in slave mode
hosts filename list of hosts to use in slave mode
loglevel level set the log4j level for this command
workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
Client Commands:
archive create a Hadoop archive
checknative check native Hadoop and compression libraries availability
classpath prints the class path needed to get the Hadoop jar and the required libraries
conftest validate configuration XML files
credential interact with credential providers
distch distributed metadata changer
distcp copy file or directories recursively
dtutil operations related to delegation tokens
envvars display computed Hadoop environment variables
fs run a generic filesystem user client
gridmix submit a mix of synthetic job, modeling a profiled from production load
jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN applications, not this command.
jnipath prints the java.library.path
kdiag Diagnose Kerberos Problems
kerbname show auth_to_local principal conversion
key manage keys via the KeyProvider
rumenfolder scale a rumen input trace
rumentrace convert logs into a rumen trace
s3guard manage metadata on S3
trace view and modify Hadoop tracing settings
version print the version
Daemon Commands:
kms run KMS, the Key Management Server
registrydns run the registry DNS server
SUBCOMMAND may print help when invoked w/o parameters or with -h.
配置 HADOOP_HOME 环境变量
建议将HADOOP_HOME/bin添加到系统环境变量中。
[root@stackstone-001 hadoop-3.3.1]# pwd
/opt/hadoop/hadoop-3.3.1
[root@stackstone-001 hadoop-3.3.1]# vi ~/.bash_profile
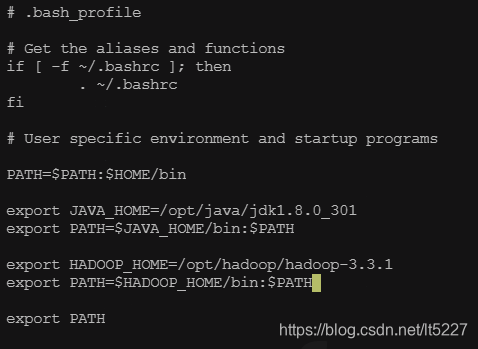
更新环境变量并进行验证
[root@stackstone-001 hadoop-3.3.1]# source ~/.bash_profile
[root@stackstone-001 hadoop-3.3.1]# echo $HADOOP_HOME
/opt/hadoop/hadoop-3.3.1
Hadoop 伪分布式模式配置
Hadoop还可以以伪分布式模式运行在单个节点上,其中每个Hadoop守护进程运行在单独的Java进程中。
配置
在 etc/hadoop/core-site.xml 中增加下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>
上面的端口可以进行修改,该配置是文件系统默认的文件系统地址。
之后在etc/hadoop/hdfs-site.xml中增加下面的配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
这里指的是文件系统的副本系数。
之后配置一下 hadoop 的文件目录,该目录默认指向 /tmp/hadoop-${user.name},由于在 /tmp 目录下,所以一旦机器重启数据会丢失。在服务器中创建数据目录存放地址,这里我创建了 /opt/hadoop_tmp_dir 目录,在 etc/hadoop/core-site.xml 中继续增加参数配置
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop_tmp_dir</value>
</property>
设置SSH免密登陆
现在检查是否可以在不使用密码的情况下ssh到本地主机:
$ ssh localhost
运行上面的命令,如果需要输入密码才能登陆到localhost的话,请执行以下命令:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
格式化文件系统
启动HDFS,在第一次执行的时候一定要格式化文件系统, 后面启动就不需要了。
$ hdfs namenode -format
在 hadoop 的 bin 目录下运行上面的语句,这个时候就会在之前我们配置的 /opt/hadoop_tmp_dir 目录下生成 dfs 目录文件信息。
启动 NameNode 守护进程和 DataNode 守护进程
$ sbin/start-dfs.sh
在 sbin 目录下运行上面的脚本,启动 HDFS 。如果出现下面的错误:
[root@stackstone-001 sbin]# ./start-dfs.sh
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [stackstone-001]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
则设置脚本 start-dfs.sh ,增加3个变量设置:

启动成功后验证一下:
[root@stackstone-001 sbin]# hadoop dfs -mkdir /test
WARNING: Use of this script to execute dfs is deprecated.
WARNING: Attempting to execute replacement "hdfs dfs" instead.
[root@stackstone-001 sbin]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2021-08-05 18:16 /test
在hdfs下创建/test目录并查看,从上面的命令行可以看出,新版的命令改为:hdfs dfs 进行操作。