Elasticsearch 7 自学记录1――ES基础
Elasticsearch7 自学记录二 进阶查询
文章目录
前言
接上一章内容,本章会以大一些的数据量来演示稍复杂的查询情况,数据是从开源数据平台kaggle 导入的tmdb的数据,就是已经上映电影的数据。
一、创建一个用于学习索引
1.1 索引字段介绍
-
text:被分析索引的字符串类型
-
keyword:不能被分析只能被精确匹配的字符串类型
-
date:日期时间类型 可以配合format一起使用,可以一次性设置多种日期格式,以兼容更多样的日期数据
{“type”:“date”,“format”:“yyyy-MM-dd”} -
数字类型:long,integer,short,double等
-
boolean类型:true,false
-
array类型:[“one”,“two”]等
-
object类型:json嵌套{“property1”:“value1”,“property2”:“value2”}
-
ip:ip类型
-
geo_point:地理位置类型
地理位置类型的字段可以以三种数据形式存放
lat 为纬度 ,lon 为经度,如下所示:
PUT /attractions/restaurant/1
{
"name": "Chipotle Mexican Grill",
"location": "40.715, -74.011" // lat, lon
}
PUT /attractions/restaurant/2
{
"name": "Pala Pizza",
"location": {
"lat": 40.722,
"lon": -73.989
}
}
PUT /attractions/restaurant/3
{
"name": "Mini Munchies Pizza",
"location": [ -73.983, 40.719 ] // lon, lat
}
1.2 用于学习的movie索引映射介绍
PUT /movie
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1
},
"mappings": {
"properties": {
"title":{"type":"text","analyzer": "english"},
"tagline":{"type":"text","analyzer": "english"},
"release_date":{"type":"date","format":"8yyyy/MM/dd||yyyy/M/dd||yyyy/d||yyyy/M/d"},
"popularity":{"type":"double"},
"overview":{"type": "text","analyzer": "english"},
"cast":{
"type": "object",
"properties": {
"character":{"type":"text","analyzer":"standard"},
"name":{"type":"text","analyzer":"standard"}
}
}
}
}
}
- title:电影标题
- tagline:电影标签
- release_date:上映日期
- popularity:电影评分
- overview:电影简介
- cast:演员信息
- cast.character:演员的姓
- cast.name: 演员的名
二、简单查询进阶
2.1 match 查询 和term 查询的区别
match 命中三条数据,match 会按照字段上定义的分词,分析后去索引内查询
GET /movie/_search
{
"query": {
"match": {
"title": "steve zissou"
}
}
}
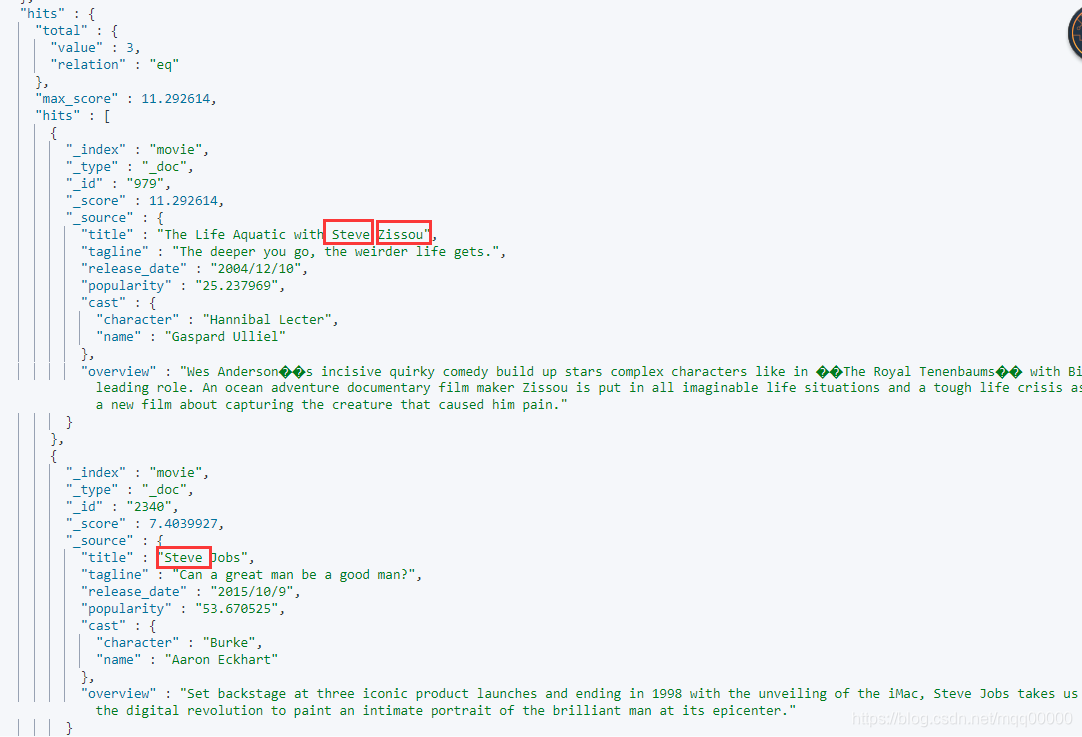
term 精确值匹配查询
命中0个文档,使用term 查询时只有和分词器分出来后的词完全相同的才会匹配到,并且会区分大小写,可以得出结论的是,term 查询时不会将查询条件里的短语进行分词处理,所以不适用于会进行分词的字段类型text ,适用于keyword 类型字段,或者是数值型的字段。
GET /movie/_search
{
"query": {
"term": {
"title": "steve zissou"
}
}
}

2.2 分词后的and 和 or 的逻辑
我们先来看看一句短语的搜索结果
GET /movie/_search
{
"query": {
"match": {
"title": "basketball with cartoom aliens"
}
}
}
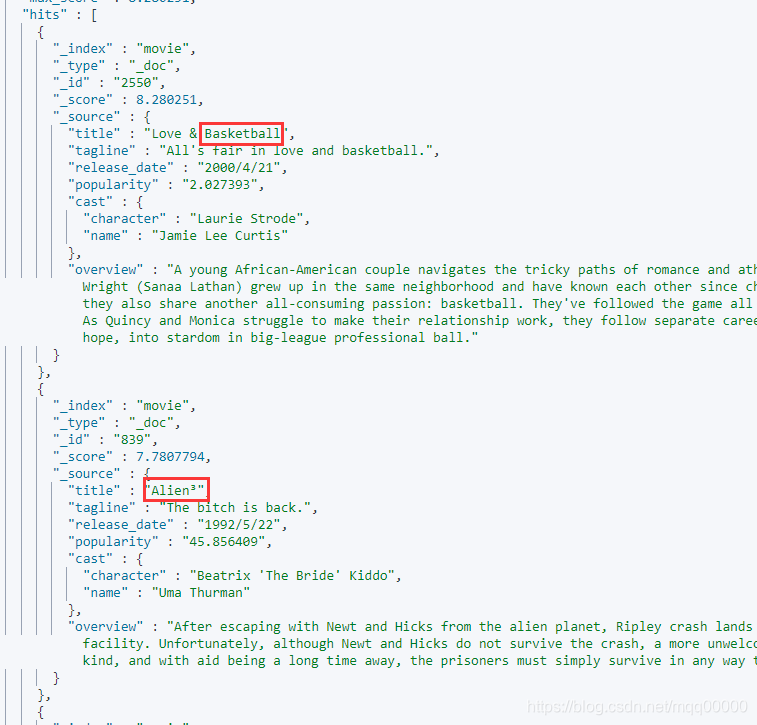
可以看到的是 只要title 中包含 basketball,cartoom,aliens 这三个单词的其中一个,那么该文档就会被命中,所以match 查询默认是or 的关系。
如果要改成and 关系,写法如下:
GET /movie/_search
{
"query": {
"match": {
"title": {
"query":"basketball with cartoom aliens",
"operator": "and"
}
}
}
}
也就是文档的title 字段分词后必须同时含有查询短语”basketball with cartoom aliens“经过分词后产生的三个单词 "basketball ","cartoom ",“alien” 那么该文档才会被命中。
2.3 最小词匹配项 minimum_should_match
这个查询语句的意思是 指定的分词内容至少被匹配中两项才会命中该文档。
GET /movie/_search
{
"query": {
"match": {
"title": {
"query":"basketball love aliens",
"operator": "or",
"minimum_should_match": 2
}
}
}
}
2.4 短语查询 match_phrase
match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那些包含 全部 搜索词项,且 位置 与搜索词项相同的文档,且中间不许夹杂其他词 。如图所示:
GET /movie/_search
{
"query": {
"match_phrase": {
"title": "steve zissou"
}
}
}
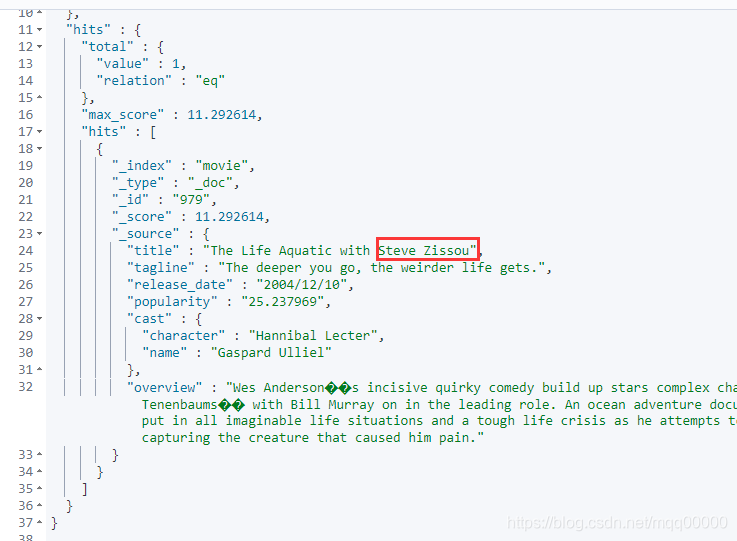
三、复杂查询
3.1 多字段查询 multi_match
场景例如我们在视频平台搜索一个关键词,那么电影的名称或者是简介中包含了那个关键词,都会被我们搜索出来,相当于搜索的关键词作用于多个字段。如下所示:
GET /movie/_search
{
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title","overview"]
}
}
}
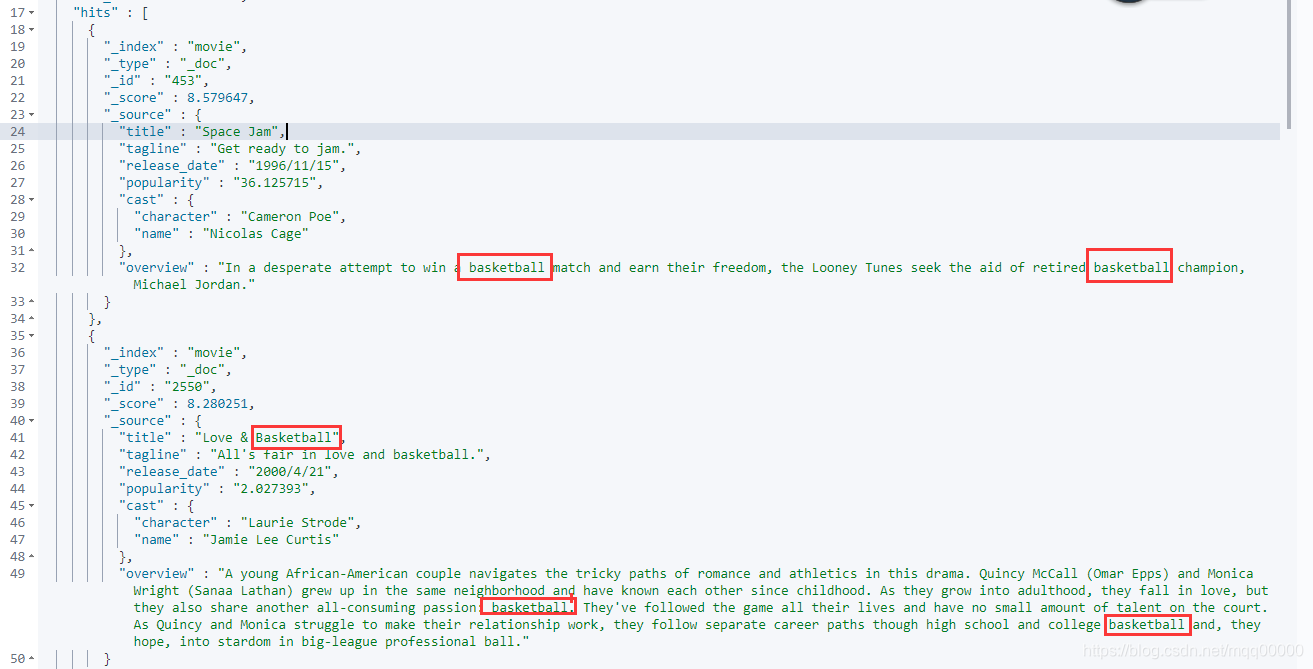
这边第一个文档的评分为啥会比第二个文档高呢,我们在这里对es的打分规则进行分析。
3.2 文档得分分析 explain
- TF:(词频):这个document文档包含了多少个这个词,包含越多表明越相关,该文档也会得分也会越高。
- IDF:(逆文档频率) :包含该词的文档总数目越多,那么该词命中的文档获取的得分也会越低。
- TFNORM: (字段长度归一化):字段内容越短,权重越大。如果一个关键词出现在较短的字段中,比如title,就比它出现在长字段(如简介)中更能表达文章的特性。
使用elasticsearch 提供的API 对文档得分进行分析:
在查询语句中加上 “explain”: true 即可对文档的得分有个解析,如下所示:
GET /movie/_search
{
"explain": true,
"query": {
"match": {
"title": "steve"
}
}
}
加上这个后文档的参数下会有相应的得分计划的解析,这边列举一个文档的。如下:
"_explanation" : {
#该文档的得分总数
"value" : 7.4039927,
#意思是 title字段值steve在文档id2197中的权重
#这个2197 似乎是es内部的一个id,不过也不重要,不需要理会
"description" : "weight(title:steve in 2197) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 7.4039927,
#字段得分的总公式:idf * tf * boost
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
#boost 是激励因子默认值为2.2,在多字段查询中,我们可以根据boost 给不同的字段赋予不同的权重,
例如,我们认为title字段比overview 字段要重要,那么我们就可以将title 的boost 值给高一点,
可以在字段创建的时候给予一个值,当然也可以在查询时我们将某个字段的boost 放大倍数。
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
# idf 部分的得分值 为7.1592917
# 计算idf 的公式:log(1 + (N - n + 0.5) / (n + 0.5))
# 有个小的注意点是 这边的对数log 是以e 为底的,不是以10为底的所以在计算器中应该使用ln函数,而不是计算器中的log函数。
# 当然我们没必要去研究这个函数的具体变化,在这里是单调递增的,我们只要知道函数内的值越大,idf的得分就越大。
# 根据小n 和 大N 的注释,并且我们根据这个公式可以得出结论:包含该词的文档总数目越多,那么该词命中的文档获取的得分也会越低。
"value" : 7.1592917,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 3,
# n:包含该词条的文档数量
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
# N:包含字段的文档总数
"value" : 4500,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
#tf部分的得分值 为0.47008157
#tf得分的公式为: freq / (freq + k1 * (1 - b + b * dl / avgdl))
# 需要知道的是这个算法叫做BM25算法,是elasticsearch6.3版本之后引入的,所以6.3版本之前的得分可能会有所差异。
"value" : 0.47008157,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
# freq 词频:指的是搜索的关键词 在文档字段中出现的次数,例如 “steve” 在分词后的title 字段中出现了一次。
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
#k1 是个默认为1.2的值,作为一个调节系数。
#官网中的原话如下:这个k值是多少?对于 BM25,k 通常设置为 1.2。大多数人不理会k。不过,更改 k 可能是一种有用的调整方法,可以修改 TF 的影响。修改 k 显然会导致渐近线移动。然而,更重要的是较高的 k 会导致 TF 需要更长的时间才能达到饱和。通过扩展饱和点,您可以扩展较高和较低词频文档之间的相关性差异!
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
#b 是个默认为0.75的值,作为一个调节系数的作用,通过BM25公式我们能发现其中有(b*dl),所以我们可以认为这个是用于调节字段长度对得分带来的影响,如果调整为0,即可消除字段长度带来的影响,所以b这个值可以调节tfnorm的概念。
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
#这里体现了tfnorm归一化的概念
# 命中字段分词后的个数,本文档中的字段"title" : "Steve Jobs", 那么分词后词数量是2,dl即为2,因为dl越大,BM25算法的得分就越低。正好验证了我们在前面对tfnorm做出的解释。
"value" : 2.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
# 等于所有文档的分词单元的(总数 / 文档个数)
# 怎么理解呢,就是把整个索引中的索引文档的title字段都拿出来分词,分词的数量相加得到一个总数,除以索引中文档的个数。
"value" : 2.1757777,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
看完了得分规则,似乎很复杂,但是具体的算法我们不需要过于去理解,只要理解了tf idf tfnorm 的概念就足够了。
3.3 多字段查询优化
分析完单字段查询的,我们再看个多字段查询的。
GET /movie/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title","overview"]
}
}
}
结果如图:
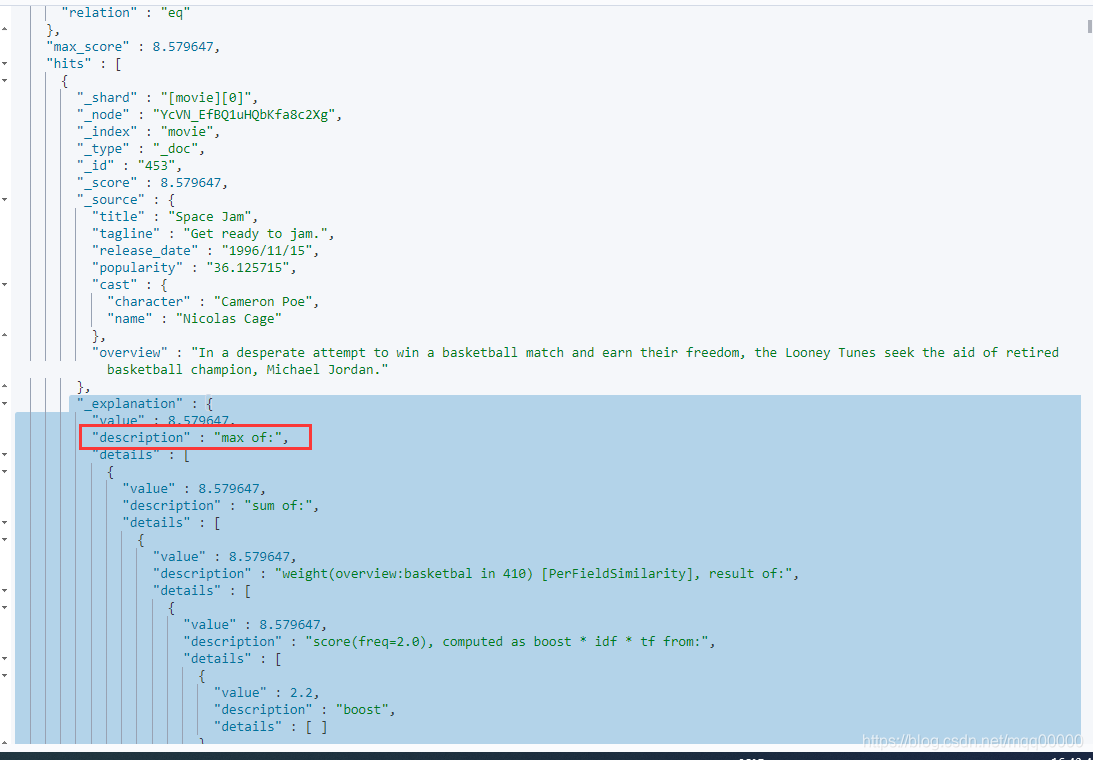
- 可以看到当查询多个字段的时候,文档的得分默认是取多个字段得分的最大值得那个, max of 表示取最大值 。
- 那么这样就有个问题了,就比如我们这个例子所示:查询的短语是“basketball with cartoom aliens”,排名第一得分为8.579647的文档 title 中根本没有命中 查询语句,但是因为overview 字段命中了,且得分比较高,所以排名第一,但这并不是我们想要的结果,我们认为title字段应该更重要的。
- 所以想要优化多字段查询,我们可以给不同的字段赋不同的权重,做法就是前面提到过的 字段的boost 激励因子,默认是2.2,可以给它放大倍数来提升字段的权重。如下:
给title字段权重放大10倍
GET /movie/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title^10","overview"]
}
}
}
如图所示:可以看到的是title 字段的boost 被放大了10倍等于22,那么title字段的得分就会比overview高的多。
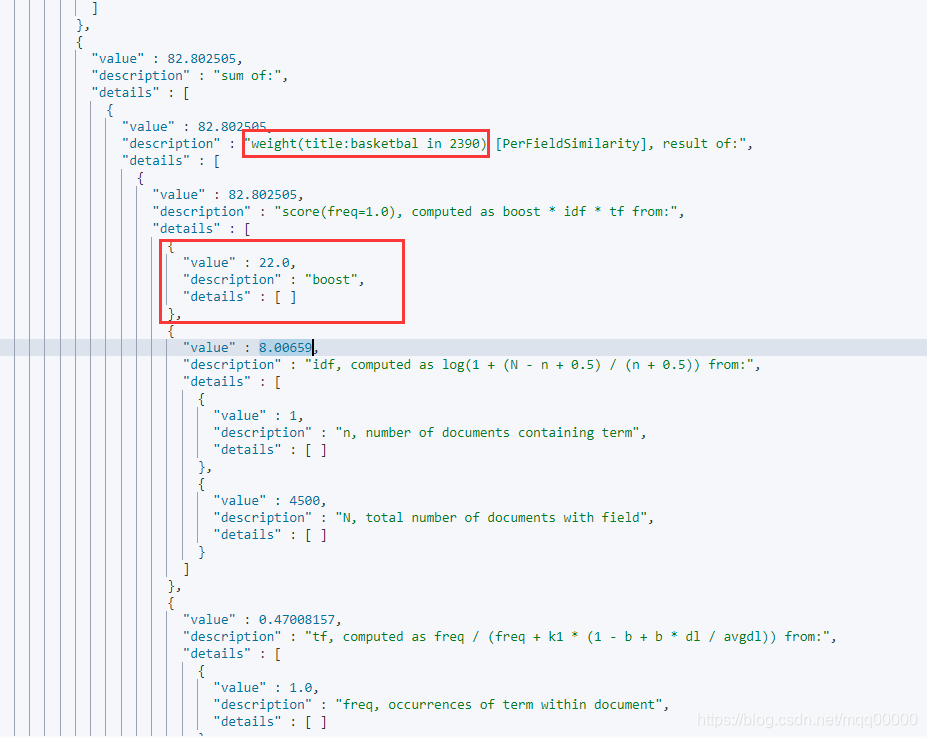
- 经常放大字段的boost属性后,查询还是有新的问题,例如一个文档在title上得分80分,在overview 字段上得分79分, 因为默认是max of 的原因,这个文档的最终得分是80分,显然这样的结果不是很符合大部分的搜索场景,因为我们希望不是得分最高的字段也能在文档的总得分上起到一点帮助,所以我们引入了 tie_breaker 的概念,如下:
GET /movie/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title^10","overview"],
"tie_breaker": 0.5
}
}
}
- 解释一下 tie_breaker:将其他字段的分数乘以tie_breaker,再与最高分数的那个字段想加,这样做除了取最高分以外,还会考虑其他的字段的分数。tie_breaker的值,设置在在0~1之间,是个小数就行,没有固定的值。这样明显更符合我们的场景了。
3.4 multi_query 的不同type
在学习bool查询之前我们还是先介绍一下多字段查询multi_match 的几种type,以帮助我们更好的学习。不同的multi_query 其实是有不同的type,这个type 指的就是我们前面所说的max of 、sum of 的得分方式。
3.4.1 best_fields:最佳字段模式
best_fields是默认的得分方式,取得最高的分数作为对应文档的对应分数。即 max of ,写法有两种,查出来的结果是一样的。如下:
GET /movie/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title","overview"],
"type": "best_fields"
}
}
}
GET /movie/_search
{
"explain": true,
"query": {
"dis_max": {
"queries": [
{"match": {
"title": "basketball with cartoom aliens"
}},
{
"match": {
"overview": "basketball with cartoom aliens"
}
}
]
}
}
}
结果如图:

我们根据api来分析一下。
GET /movie/_validate/query?explain
{
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title","overview"],
"type": "best_fields"
}
}
}
得到结果如下:
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"valid" : true,
"explanations" : [
{
"index" : "movie",
"valid" : true,
# 直接看这里
# 意思是 (分词的三个单词 “basketbal” , “cartoom” , “alien” 分别作用于overview字段,获得的打分会相加)(分词的三个单词 “basketbal” , “cartoom” , “alien” 分别作用于title字段,获得的打分会相加)
然后这两个字段取得分高的字段的分数作为最终分数。
"explanation" : "((overview:basketbal overview:cartoom overview:alien) | (title:basketbal title:cartoom title:alien))"
}
]
}
3.4.2 most_fields:多数字段模式
多个字段的得分想加,即sum of ,当然我们可以给title 更高的权重,给overview较低的权重 。如下:
GET /movie/_search
{
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title^10","overview^0.5"],
"type": "most_fields"
}
}
}
再看下得分分析
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"valid" : true,
"explanations" : [
{
"index" : "movie",
"valid" : true,
#可以看到公式后面有“~1.0” 代表的就是这两个字段得分想加的意思
"explanation" : "((overview:basketbal overview:cartoom overview:alien)^0.5 | (title:basketbal title:cartoom title:alien)^10.0)~1.0"
}
]
}
3.4.3 cross _fields:跨字段模式
用法如下:
GET /movie/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "basketball with cartoom aliens",
"fields": ["title","overview"],
"type": "cross_fields"
}
}
}
直接说说这个模式是怎么计算分数的吧,就不晒出结果了。
- 首先分词“basketball with cartoom aliens” 得到“basketball ”,“cartoom ”,“aliens”
- 计算单词 “basketball” 在overview 字段中的得分,再计算单词“basketball” 在title字段中的得分。两者取最高的得分 即max of,得到“单词basketball” 的得分。
- 计算单词 “cartoom” 在overview 字段中的得分,再计算单词“cartoom” 在title字段中的得分。两者取最高的得分,得到单词“cartoom”的得分。
- 计算单词 “aliens” 在overview 字段中的得分,再计算单词“aliens” 在title字段中的得分。两者取最高的得分,得到单词“aliens”的得分。
- 最终将三个单词的得分想加即sum of 得到这个文档的最终得分。
- 总结一下,其他模式的得分是以字段为单位,取最大值或者相加得到文档的分数,这个模式是以单词为单位,想加得到文档的分数。
3.5 bool查询 (高级组合查询)
先大概的介绍一下bool查询的几种子句,在上一篇文章也介绍过了。
- must 子句: 必须都为true。
- must not :必须都为false。
- should : 其中一个为true 即可。为true 的越多得分越高。
- filter:返回的文档必须满足filter子句的条件。但是不会像Must一样,参与计算分值。
3.5.1 should 子句
GET /movie/_search
{
"query": {
"bool": {
"should": [
{
"match": {"title": "basketball with cartoom aliens"}
},
{
"match": {"overview": "basketball with cartoom aliens"}
}
]
}
}
}
简单来看就是title 字段匹配 或者 overview 字段匹配就能命中文档,和前面刚刚介绍的 multi_match查询type为most_fields 查询的结果完全一样。
只要命中的字段,得分就会相加。如图所示:
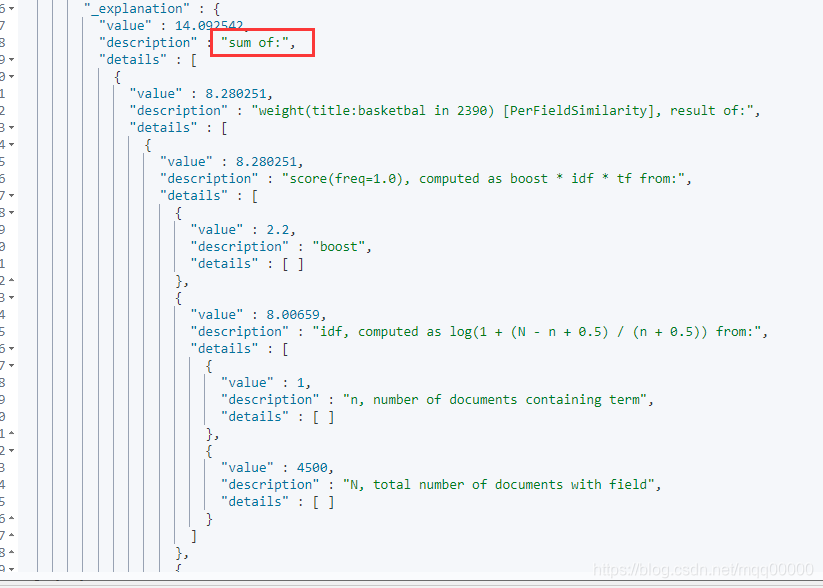
3.5.2 must 子句 和 must_not 子句
must 里面的条件必须都成立,并且为true的条件的得分想加作为文档的总得分,must_not 里面的条件必须都不成立,总得分也是想加。
GET /movie/_search
{
"explain": true,
"query": {
"bool": {
"must": [
{
"match": {"title": "basketball"}
},
{
"match": {"overview": "basketball"}
}
]
}
}
}
3.5.3 filter 子句
和must一样,所有条件必须成立,但是使用filter 文档不参于评分。
所有的查询都会影响到文档的评分及排名。如果我们需要在查询结果中进行过滤,并且不希望过滤条件影响评分,那么就不要把过滤条件作为查询条件来用。而是使用filter方式。如下:
GET /movie/_search
{
"explain": true,
"query": {
"bool": {
"must": [
{
"match": {"title": "basketball"}
}
],
"filter": [
{
"match":{"overview":"basketball"}
}
]
}
}
}
结果:
"_explanation" : {
"value" : 8.280251,
"description" : "sum of:",
"details" : [
{
"value" : 8.280251,
"description" : "weight(title:basketbal in 2390) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 8.280251,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 8.00659,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4500,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.47008157,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 2.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 2.1757777,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
#这边可以看到 overview 字段命中也没有得分。
{
"value" : 0.0,
"description" : "match on required clause, product of:",
"details" : [
{
"value" : 0.0,
"description" : "# clause",
"details" : [ ]
},
{
"value" : 1.0,
"description" : "overview:basketbal",
"details" : [ ]
}
]
}
]
}
}
总结
每一句话都是自己根据课程总结的,有错误的地方欢迎大家指出来,一起学习,下一篇会记录过滤与排序,自定义score 计算,和聚合查询等。