pyspark与原生spark(scala)比较
在学习完spark这个优秀的计算框架后,因为当时的学习使用了python api对spark进行交互,编写spark的原生语言为sacla,所以,在简单的自学完scala后,再次使用scala对spark进行交互,也可称为scala初体验~
本篇文章主要以使用python和scala分别编写spark程序实现wordcount单词计数,来对pyspark和原生spark进行比较
1.spark计算框架介绍
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
spark底层由scala和java编写,现已提供多种api供其它语言操作spark,如python、R语言
2.准备工作
- 下载scala,并在idea中创建meven工程,导入scala的SDK工具包,并导入相关依赖
- 在python中下载pyspark第三方包(注:pyspark3.×版本无法支持高版本的python,如python3.8,需降低pyspark版本或者降低python版本)
- 准备测试数据集
3.创建测试数据集
hadoop word
spark
flink spark
hive
4.scala编写wordcount
依赖包
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
##导入的依赖版本需要与自己安装的scala版本对应
import org.apache.spark.{SparkConf, SparkContext}
import java.util.Date
object wordcount {
def main(args: Array[String]): Unit = {
//获取程序开始时间
var start_time =new Date().getTime
// 程序入口
val sparkconf = new SparkConf().setMaster("local").setAppName("WordCount")
// 创建会话
val sc = new SparkContext(sparkconf)
//创建rdd
val rdd1 = sc.textFile("C:/Users/yusyu/Desktop/data.txt")
//打印 rdd内容
rdd1.foreach(println)
// 将rdd里的内容进行根据空格分割,并转换为map类型
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map(x=>(x,1))
rdd2.foreach(println)
//使用reducebykey算子对rdd里的(word,1)类型数据进行求和
val rdd3 = rdd2.reduceByKey((x,y)=>(x+y))
rdd3.foreach(println)
// 关闭会话
sc.stop()
// 获取程序结束时间
var end_time =new Date().getTime
// 打印程序运行时长
println((end_time-start_time))
}
}
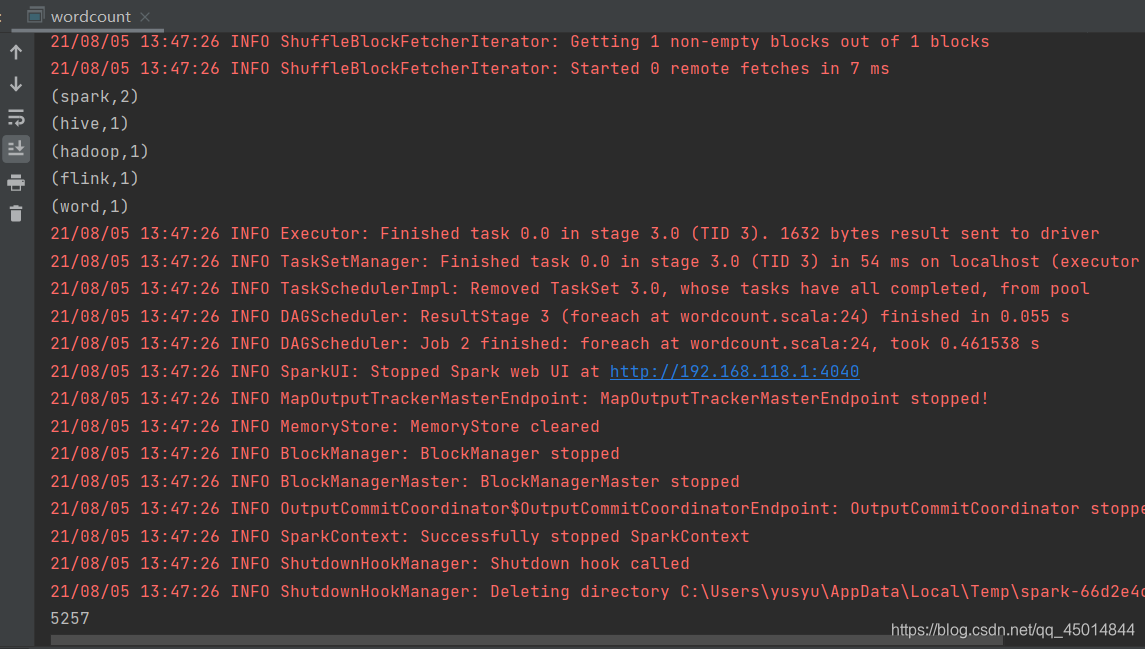
运行结果如下:
程序运行时长的单位为毫秒
5.python编写wordcount
from pyspark import SparkContext, SparkConf
import datetime
start_time = datetime.datetime.now()
conf = SparkConf().setMaster("local").setAppName("test application")
sc = SparkContext(conf=conf)
rdd1 = sc.textFile("C:/Users/yusyu/Desktop/data.txt")
rdd1.foreach(print)
rdd2 = rdd1.flatMap(lambda x:x.split(" ")).map(lambda x:(x,1))
rdd2.foreach(print)
rdd3 = rdd2.reduceByKey(lambda x,y:x+y)
rdd3.foreach(print)
sc.stop()
end_time = datetime.datetime.now()
print(end_time-start_time)
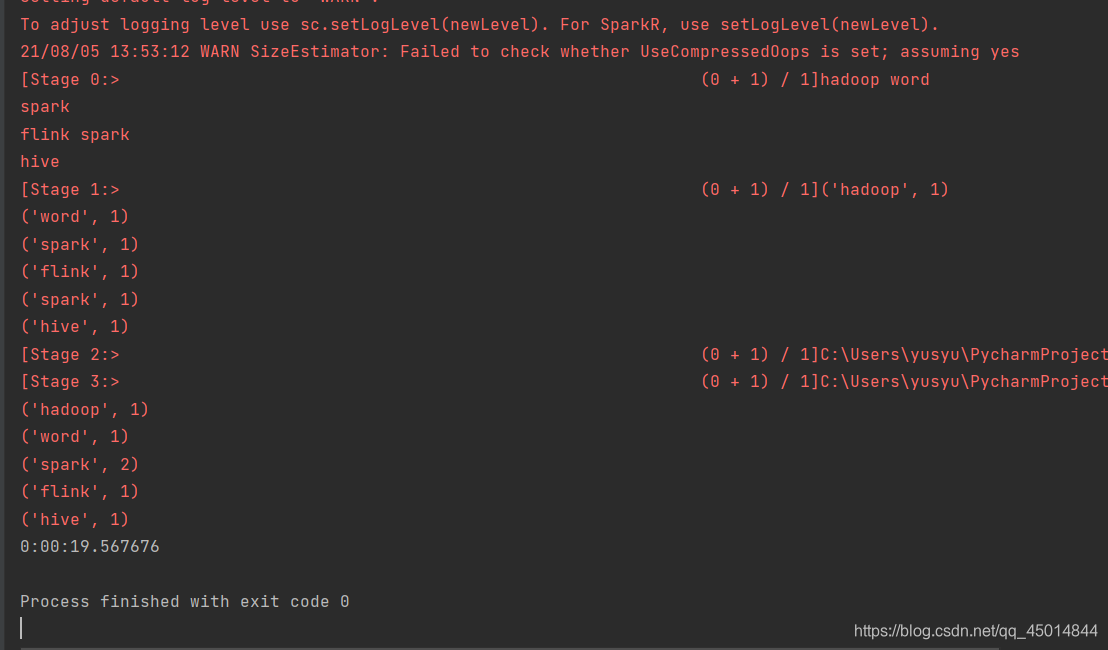
运行结果如下:
6.总结
这里用了入门案例wordcount来比较了scala与python操作spark的语法和程序运行时长,相同的程序,相比scala编写的运行了五秒多来说,pyspark运行的时长确实会比较长。
这也是在学习完scala后,使用spark的初体验,方便再次重温spark。