1、开窗函数取特定值
开窗函数中经常遇到去取出某个特定的值,具体的相关函数为
lag() : 与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL的时候,取默认值,如果不指定,则为NULL).
**lead(col,n,default)**与lag相反,统计分组内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,不填默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)。
**FIRST_VALUE()😗*取分组内排序后,截止到当前行,分组内第一个值。
**LAST_VALUE()😗*取分组内排序后,截止到当前行,最后一个值.
注意:last_value 默认窗口是 rows between unbounded preceding and current row,表示当前永远是分组内最后一个值,需要手动改成成Rows between unbounded preceding and unbounded following.
1、开窗函数值具体例子
lag 实现分组内上一行的营业额,如果没有上一行则取个默认值(1)。
select month,
shop,
money,
lag(money,1,1) over(partition by shop order by month) as before_money,
form temp_test12;
结果:
month shop money before_money
2019-01 a 1 1
2019-02 a 2 1
2019-03 a 3 2
2019-04 a 4 3
2019-05 a 5 4
2019-06 a 6 5
2019-01 b 2 1
2019-02 b 4 2
2019-03 b 6 4
2019-04 b 8 6
2019-05 b 10 8
2019-06 b 12 10
lead()实现分组内下一个月营业额需求
SELECT month
,shop
,MONEY
,LEAD(MONEY, 1, 7) OVER ( PARTITION BY shop ORDER BY month ) AS after_money
,LEAD(MONEY, 1) OVER (PARTITION BY shop ORDER BY month) AS after_money --第三个参数不写的话,如果没有下一行值,默认取null
,LEAD(MONEY, 2, 7) OVER (PARTITION BY shop ORDER BY month) AS after_2month_money --取两个月后的营业额
FROM temp_test12;
结果:
month shop money after_money after_money after_2month_money
2019-01 a 1 2 2 3
2019-02 a 2 3 3 4
2019-03 a 3 4 4 5
2019-04 a 4 5 5 6
2019-05 a 5 6 6 7
2019-06 a 6 7 NULL 7
2019-01 b 2 4 4 6
2019-02 b 4 6 6 8
2019-03 b 6 8 8 10
2019-04 b 8 10 10 12
2019-05 b 10 12 12 7
2019-06 b 12 7 NULL 7
解释说明:
shop为a时,after_money指定了往下第1行的值,如果没有下一行值,默认取null,这里指定为1。
a的第1行,往下1行值为第2行营业额值,2。
a的第2行,往下1行值为第3行营业额值,4。
a的第6行,往下1行值为NULL,指定第三个参数取7,不指定取null。
FIRST_VALUE()
select * ,first_value(s_id) over (partition by c_id order by s_score)first_show from score;

结果显示:也就是说,得到的结果是对应c_id的首个s_id的值。
LAST_VALUE()
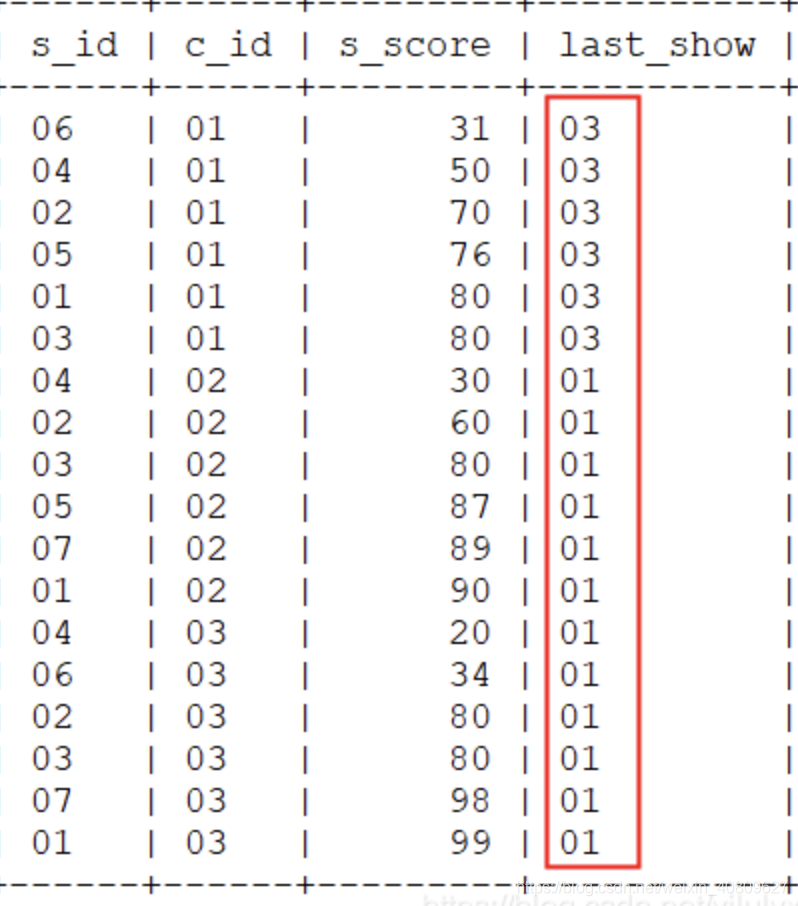
select * ,last_value(s_id) over (partition by c_id order by s_score)last_show from score;
由结果看出:last_value() 默认的统计范围是 rows between unbounded preceding and current row ,也就是去当前行数据与当前之前的数据的比较。
那么,如何像**first_value()**那样直接在每行数据中显示最后的那个数据呢?
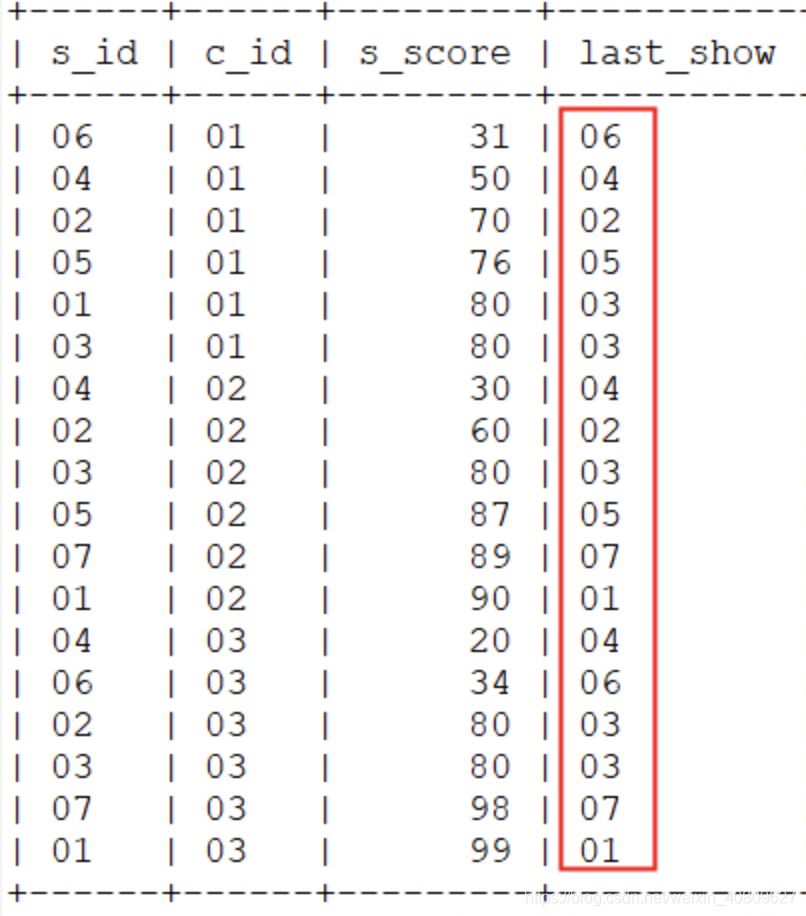
在order by 条件的后面加上语句:rows between unbounded preceding and unbounded following
即:
select * ,last_value(s_id) over(partition by c_id order by s_score rows between unbounded preceding and unbounded following ) last_show from score;
即结果达到预期,每一行结果直接返回分组内最后结果值了