本文从一段代码开始,拆解Spark背后的运行机制
Spark 架构和相关术语
在开始拆解前,我们先来看一下Spark的架构和一些术语。
Spark 遵从分布式系统的主从架构,一个 master 节点作为协调,与一系列的 worker 节点沟通,worker 节点之间也可以互相通信。
每个 worker 节点包含一个或者多个 executor,一个 executor 中又包含多个 task。task 是真正实现并行计算的最小工作单元。

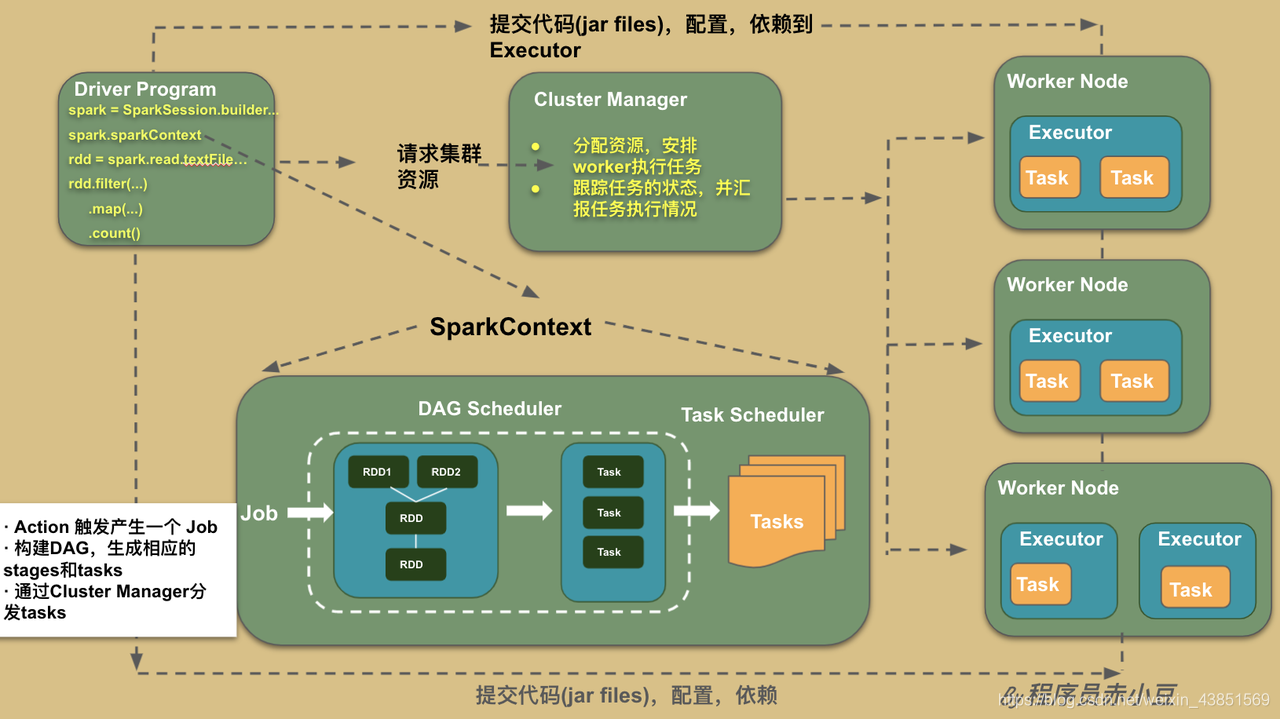
从上图可见主要有以下几个组建:
- Driver
- Spark Context/Session
- Cluster Manager
- Executor
Driver
Driver 是一个 Java 进程,负责执行 Spark 任务的 main 方法,它的职责有:
- 执行用户提交的代码,创建 SparkContext 或者 SparkSession
- 将用户代码转化为Spark任务(Jobs)
- 创建血缘(Lineage),逻辑计划(Logical Plan)和物理计划(Physical Plan)
- 在 Cluster Manager 的辅助下,把 task 任务分发调度出去
- 跟踪任务的执行情况
Spark Context/Session
它是由Spark driver创建,每个 Spark 应用对应一个。程序和集群交互的入口。可以连接到 Cluster Manager
Cluster Manager
负责部署整个Spark 集群,包括上面提到的 driver 和 executors。具有以下几种部署模式
- Standalone 模式
- YARN
- Mesos
- Kubernetes
Executor
一个创建在 worker 节点的进程。一个 Executor 有多个 slots(线程) 可以并发执行多个 tasks。
- 负责执行spark任务,把结果返回给 Driver
- 可以将数据缓存到 worker 节点的内存
- 一个 slot 就是一个线程,对应了一个 task
再来一张更详细的图将上面的各个组件交互串起来。
Spark 运行机制解剖:从一段简单的代码说起
我们多多少少都知道 Spark 有懒加载的特性,也就是说 Spark 计算按兵不动,直到遇到 action 类型的 operator 的时候才会触发一次计算。
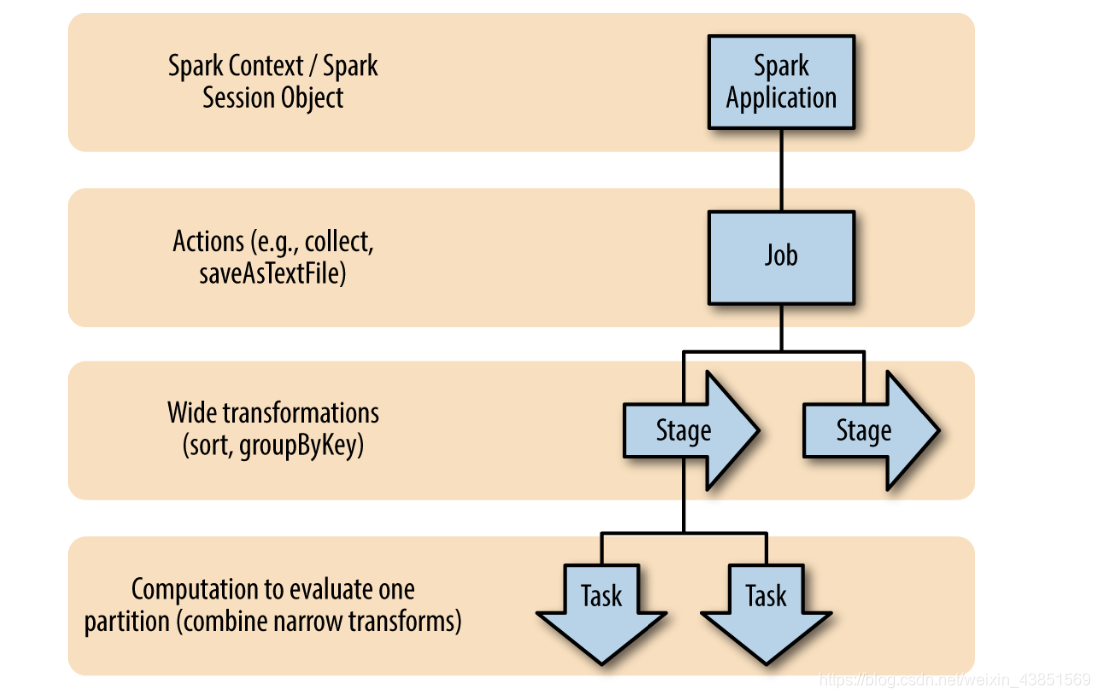
层次划分和抽象
Spark 对一次计算任务做了几个方面的划分和抽象。
DAG
- Spark Job如何执行,都是由这个 DAG 来管的,包括决定 task 运行在什么节点
Spark Job
- 每个Spark Job 对应一个action
Stages
- 每个 Spark Job 包含一系列 stages
- Stages 按照数据是否需要 shuffle 来划分(宽依赖)
- Stages 之间的执行是串行的(除非stage 间计算的RDD不同)
- 因为 Stages 是串行的,所以 shuffle 越少越好
Tasks
- 每个 stage 包含一系列的 tasks
- Tasks 是并行计算的最小单元
- 一个 stage 中的所有 tasks 执行同一段代码逻辑,只是基于不同的数据块
- 一个 task 只能在一个executor中执行,不能是多个
- 一个 stage 输出的 partition 数量等于这个 stage 执行 tasks 的数量
Partition
- Spark 中 partition(分区) 可以理解为内存中的一个数据集
- 一个 partition 对应一个 task,一个 task 对应 一个 executor 中的一个 slot,一个 slot 对应物理资源是一个线程 thread
- 1 partition = 1 task = 1 slot = 1 thread
代码与运行时拆解
有了以上的了解,让我们来看一段代码,并把这段代码的执行过程进行梳理和拆解。
val data = Seq(("Project","A", 1),
("Gutenberg’s", "X",3),
("Alice’s", "C",5),
("Alice’s", "A",3),
("Gutenberg’s", "Z",2),
("Adventures","B", 1))
//stage 1
val rawRdd = spark.sparkContext.parallelize(data)
val filteredRdd = rawRdd.filter(r => (r._3 > 1))
val mappedRdd = filteredRdd.map(x => (x._1, x._3))
// stage 2
val groupedRdd = mappedRdd.groupByKey()
val mappedRdd2 = groupedRdd.map{case(value, groups) => (groups.sum, value)}
// stage 3
val sortedRdd = mappedRdd2.sortByKey(numPartitions=1)
// 生成 job
sortedRdd.count()
在这段代码中,action算子 count() 生成一个任务。宽依赖算子 groupByKey() 和 sortByKey() 将整个任务分成 3 个stage。
- 当把这段代码提交到Spark集群后,Driver隐式地把用户代码转化成逻辑计划 DAG。
- 所有的RDD都会在 Driver 中创建好,按兵不动,直到遇到一个 action 算子才会进行调用。
- Driver会将DAG转化成物理执行计划,生成每个阶段要执行的 tasks 等
-
Cluster Manager 会给这个应用分配所需的资源,启动 executors,并把这些 executors 注册到 Driver,这样 Driver 就对全局的资源有一个了解。接下来 Driver 会把任务下发到 executors 上。
-
让我们一步步理解代码,第一步读数据,将数据转成可以并行执行的数据集 rawRdd
-
加载完原始数据后,是 filter 和 map 操作,这两步运算都会并行地执行,并行度要看数据的 partition 分区数量
-
接下来是 groupByKey() 方法,这是一个宽依赖算子,所以在这一步进行一个 stage 的划分。它将 key 相同的数据合并到一起,将数据从不同的节点中进行移动(shuffle),相同的 key 形成新的 partition 分区
-
再往后,原理相似,遇到 sortByKey() 宽依赖算子,再次拆分为新的 stage3,最后执行一个 action 算子 count(),整个任务才开始执行。
-
在整个程序执行的过程中,客户端会去收集程序执行的状态。当整个程序都跑完了,资源会随着代码的结束退出被释放。
最后,其实也可以到Spark UI 去看一下自己的任务被分成了几个stage,每个stage都包含哪些RDD操作。
Reference
- https://juejin.cn/post/6844904098047721486
- https://blog.knoldus.com/understanding-the-working-of-spark-driver-and-executor/
- https://luminousmen.com/post/spark-anatomy-of-spark-application
- https://www.alibabacloud.com/forum/read-471
- 《High performance Spark》